机械学习----KNN算法
引言:
最近在了解机器学习,学到KNN算法,想写一遍博客总结一下
正文:
KNN算法(邻近算法),或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。
kNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 kNN方法在类别决策时,只与极少量的相邻样本有关。由于kNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,kNN方法较其他方法更为适合。
举个简单的例子:表格下面是关于电影的数据,KNN算法就是通过算所求电影与这些电影距离最近,从而来判断这个电影的类型
距离公式有欧式距离和曼哈顿距离,记住,我们所求的距离,都是通过数据的特征值来求得。如电影接吻和打斗次数就是它得特征值。
欧式:就是我们数学学的两点距离公式;
曼哈顿:按下面电影来说,a b得距离就是|ka-kb|+|pa-pb|
那么我们就可以通过距离公式,根据所选的k值,来判断它的类型。比如我们选k=1,那么就找离它最近的电影,从而来判断它的类型。我们通过计算发现,e电影离g电影最近,所以我猜测g的电影类型为爱情片。
但是KNN的弊端很明显:
样本不均衡:如果我们的K值比较大,比如我们取5,那么我就们选择离g电影最近的5个电影来判断,由于只有5个电影,而且动作片多,所以我们判断g的类型是动作片。但是我们通过数据发现这肯定是错的。所以当k值过大时,就容易分错。此时有人也许会说一直取k=1,这个也是不一定的。万一最近的是一个异常点,那这个就是错误的数据。我们得选择合适的k值
| 电影名字 | 接吻次数k | 打斗次数p | 电影类型 |
| a | 100 | 10 | 爱情片 |
| b | 10 | 110 | 动作片 |
| c | 15 | 120 | 动作片 |
| e | 99 | 10 | 爱情片 |
| f | 5 | 99 | 动作片 |
| g | 90 | 5 | ? |
下面通过我的代码来了解knn算法:我们采用的是iris(鸢尾花)的数据()
iris有四个属性:sepal length萼片长度(厘米)、sepal width萼片宽度(厘米)、petal length花瓣长度(厘米)、petal width花瓣宽度(厘米),三种类别:Iris-Setosa 山鸢尾、Iris-Versicolour 变色鸢尾、Iris-Virginica 维吉尼亚鸢尾。我们通过一些iris的一些数据,来进行预测是否正确。
思路:首先我们获取iris数据,然后将它分成训练集和测试集。通过训练集来建立我们的模型,最后通过模型来验证测试集的正确性。
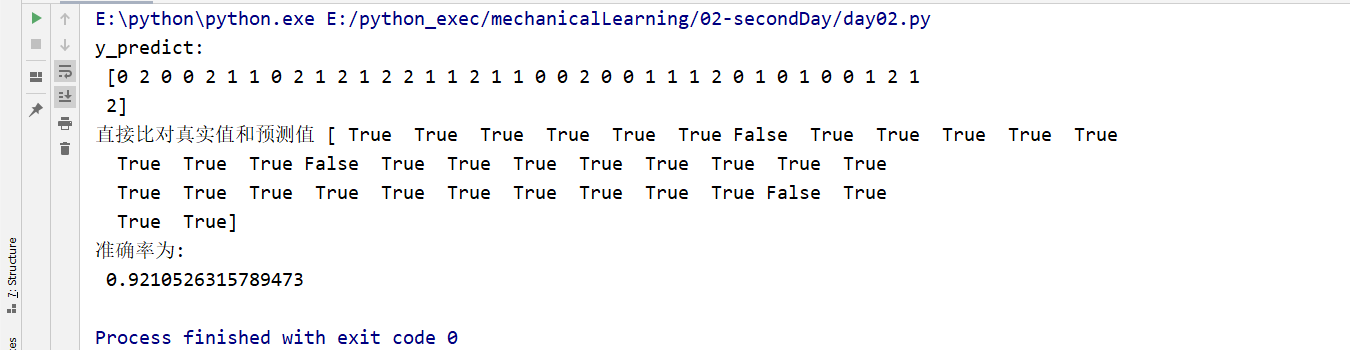
from sklearn.datasets import load_iris #导入鸢尾花数据 from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler #导入标准模块 from sklearn.neighbors import KNeighborsClassifier ''' 流程分析: ''' def iris_knn(): # 1)获取数据,从数据中获得模型 iris = load_iris(); # 2)数据集划分:一部分用于训练,一部分用于测试 #依次返回的是训练集特征值,测试集特征值,训练集目标值,测试集目标值 x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=6) # 3)特征工程:标准化,防止一些特征值太大,影响结果 transfer = StandardScaler() x_train = transfer.fit_transform(x_train) # fit_transform---》fit()---->transform() x_test = transfer.transform(x_test) # 保证二者进行的同一操作,他们的平均值和标准差得一样 # 4)KNN算法预估器 estimator = KNeighborsClassifier(n_neighbors=3) # n_neighbors 表示k值 传入训练集的特征值和目标值 estimator.fit(x_train, y_train) # KNN:计算距离,通过特征值计算距离 # 5)模型评估 # 方法1:直接比对真实值和预测值 y_predict = estimator.predict(x_test) print("y_predict:\n", y_predict) print("直接比对真实值和预测值", y_predict == y_test) # 计算准确率 #estimator是已经建立的模型,我们需要用测试数据检验这个模型好不好。 print("准确率为:\n", estimator.score(x_test, y_test)) if __name__ == '__main__': iris_knn()
运行结果:我们发现有一些我们预测的是对的,有的预测的是错的。0、1、2就是鸢尾花的三种类型。建议先把数据集的划分和数据预处理搞懂,要不很难看懂代码写的是什么。
总结:
●优点:
。简单,易于理解,易于实现,无需训练
●缺点:
。懒惰算法,对测试样本分类时的计算量大,内存开销大
。必须指定K值,K值选择不当则分类精度不能保证
●使用场景:小数据场景,几千~几万样本,具体场景具体业务去测试
