
数据结构与算法基础学习(一)
基本概念和术语
1、数据(Data)
数据是外部世界信息的载体,它能够被计算机识别、存储和加工处理,是计算机程序加工的原料。计算机程序处理各种各样的数据,可以是数值数据,如整数、实数或复数;也可以是非数值数据,如字符、文字、图形、图像、声音等。
2、数据元素(Data Element)和数(DataItem) 数据元素是数据的基本单位,在计算机程序中通常被作为一个整体进行考虑和处理。数据元素有时也被称为元素、结点、顶点、记录等。一个数据元素可由若干个数据项(Data Item)组成。数据项是不可分割的、含有独立意义的最小数据单位,数据项有时也称为字段(Field)或域(Domain)。例如,在数据库信息处理系统中,数据表中的一条记录就是一个数据元素。这条记录中的学生学号、姓名、性别、籍贯、出生年月、成绩等字段就是数据项。数据项分为两种,一种叫做初等项,如学生的性别、籍贯等,在处理时不能再进行分割;另一种叫做组合项,如学生的成绩,它可以再分为数学、物理、化学等更小的项。
3、数据对象(Data Object)数据对象是性质相同的数据元素的集合,是数据的一个子集。例如,整数数据对象是{0,±1,±2,±3,…},字符数据对象是{a,b,c,…}。
4、数据类型(Data Type)
数据类型是高级程序设计语言中的概念,是数据的取值范围和对数据进行操作的总和。数据类型规定了程序中对象的特性。程序中的每个变量、常量或表达式的结果都应该属于某种确定的数据类型。例如,C#语言中的字符串类型(String,经常写为string)。一个String表示一个恒定不变的字符序列集合,所有的字符序列集合构成String的取值范围。我们可以对String进行求长度、复制、连接两个字符串等操作。
数据类型可分为两类:一类是非结构的原子类型,如C#语言中的基本类型(整型、实型、字符型等);另一类是结构类型,它的成分可以由多个结构类型组成,并可以分解。结构类型的成分可以是非结构的,也可以是结构的。例如,C#语言中数组的成分可以是整型等基本类型,也可以是数组等结构类型。
5、数据结构(Data Structure)
数据结构是相互之间存在一种或多种特定关系的数据元素的集合。在任何问题中,数据元素之间都不是孤立的,而是存在着一定的关系,这种关系称为结构(Structure)。根据数据元素之间关系的不同特性,通常有4类基本数据结构:
(1) 集合(Set):如图1.1(a)所示,该结构中的数据元素除了存在“同属于一个集合”的关系外,不存在任何其它关系。
(2) 线性结构(Linear Structure):如图1.1(b)所示,该结构中的数据元素存在着一对一的关系。
(3) 树形结构(Tree Structure):如图1.1(c)所示,该结构中的数据元素存在着一对多的关系。
(4) 图状结构(Graphic Structure):如图1.1(d)所示,该结构中的数据元素存在着多对多的关系。
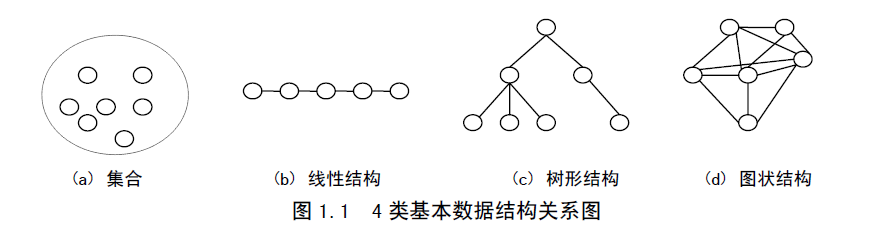
由于集合中的元素的关系极为松散,可用其它数据结构来表示,所以本书不做专门介绍。关于集合的概念在1.3.1小节中有介绍。
数据结构的形式化定义为:数据结构(Data Structure)简记为DS,是一个二元组,
DS = (D,R)
其中:D是数据元素的有限集合,
R是数据元素之间关系的有限集合。
下面通过例题来进一步理解后3类数据结构。
【例1-1】 学生信息表(如表1.1所示.)是一个线性的数据结构,表中的每一行是一个记录(在数据库信息处理系统中,表中的一个数据元素称为一个记录)。一条记录由学号、姓名、行政班级、性别和出生年月等数据项组成。表中数据元素之间的关系是一对一的关系。
表1.1 学生信息表

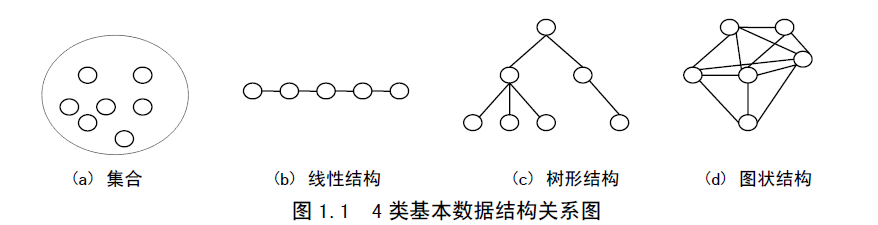
【例1-2】 家族关系是典型的树形结构,图1.2是一个三代的家族关系。在图中,爷爷、儿子、女儿、孙子、孙女或外孙女是一个结点(在树形结构中,数据元素称为结点),他们之间是一对多的关系。其中,爷爷有两个儿子和一个女儿,这是一对三的关系;一个儿子有两个儿子(爷爷的孙子),这是一对二的关系;另一个儿子有一个儿子(爷爷的孙子)和一个女儿(爷爷的孙女),这是一对二的关系;女儿有三个女儿(爷爷的外孙女),这是一对三的关系。树形结构具有严格的层次关系,爷爷在树形结构的最上层,中间层是儿子和女儿,最下层是孙子、孙女和外孙女。不能把这种关系倒过来,因为绝对不会先有儿子或女儿再有爷爷,也不会先有孙子或孙女再有儿子、先有外孙女再有女儿。
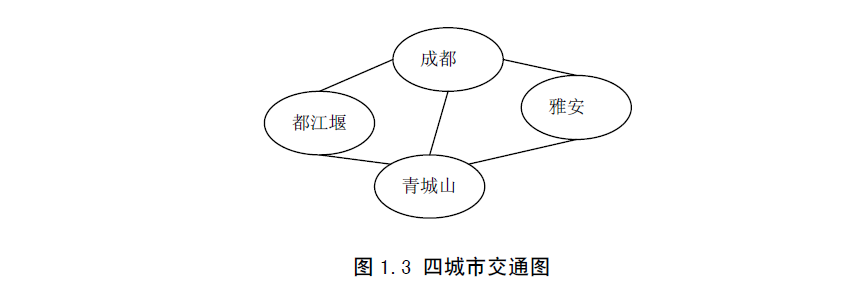
【例1-3】 图1.3是四个城市的公路交通图,这是一个典型的图状结构。在图中,每个城市是一个顶点(在图状结构中,数据元素称为顶点),它们之间是多对多的关系。成都与都江堰、雅安直接通公路,都江堰与成都、青城山直接通公路,青城山与都江堰、成都及雅安直接通公路,雅安与成都、青城山直接通公路。这些公路构成了一个公路交通网,所以,又把图状结构称为网状结构(Network Structure)
从数据类型和数据结构的概念可知,二者的关系非常密切。数据类型可以看作是简单的数据结构。数据的取值范围可以看作是数据元素的有限集合,而对数据进行操作的集合可以看作是数据元素之间关系的集合。
数据结构包括数据的逻辑结构和物理结构。上述数据结构的定义就是数据的逻辑结构(Logic Structure),数据的逻辑结构是从具体问题抽象出来的数学模型,是为了讨论问题的方便,与数据在计算机中的具体存储没有关系。然而,我们讨论数据结构的目的是为了在计算机中实现对它的操作,因此还需要研究在计算机中如何表示和存储数据结构,即数据的物理结构(Physical Structure)。数据的物理结构又称为存储结构(Storage Structure),是数据在计算机中的表示(又叫映像)和存储,包括数据元素的表示和存储以及数据元素之间关系的表示和存储。
数据的存储结构包括顺序存储结构和链式存储结构两种。顺序存储结构(Sequence Storage Structure)是通过数据元素在计算机存储器中的相对位置来表示出数据元素的逻辑关系,一般把逻辑上相邻的数据元素存储在物理位置相邻的存储单元中。在C#语言中用数组来实现顺序存储结构。因为数组所分配的存储空间是连续的,所以数组天生就具有实现数据顺序存储结构的能力。链式存储结构(Linked Storage Structure)对逻辑上相邻的数据元素不要求其存储位置必须相邻。链式存储结构中的数据元素称为结点(Node),在结点中附设地址域(Address Domain)来存储与该结点相邻的结点的地址来实现结点间的逻辑关系。这个地址称为引用(Reference),这个地址域称为引用域(Reference Domain)。
从20世纪60年代末到70年代初,出现了大型程序,软件也相对独立,人们越来越重视数据结构,认为程序设计的实质是确定数据结构,加上设计一个好的算法,这就是人们常说的“程序=数据结构+算法”。下一节谈谈算法的问题。
算法的特性
算法(Algorithm)是对某一特定类型的问题的求解步骤的一种描述,是指令的有限序列。其中的每条指令表示一个或多个操作。一个算法应该具备以下5个特性:
1、有穷性(Finity):一个算法总是在执行有穷步之后结束,即算法的执行时间是有限的。
2、确定性(Unambiguousness):算法的每一个步骤都必须有确切的含义,即无二义,并且对于相同的输入只能有相同的输出。
3、输入(Input):一个算法具有零个或多个输入。它即是在算法开始之前给出的量。这些输入是某数据结构中的数据对象。
4、 输出(Output):一个算法具有一个或多个输出,并且这些输出与输入之间存在着某种特定的关系。
5、 能行性(realizability):算法中的每一步都可以通过已经实现的基本运算的有限次运行来实现。
算法的含义与程序非常相似,但二者有区别。一个程序不一定满足有穷性。例如操作系统,只要整个系统不遭破坏,它将永远不会停止。还有,一个程序只能用计算机语言来描述,也就是说,程序中的指令必须是机器可执行的,而算法不一定用计算机语言来描述,自然语言、框图、伪代码都可以描述算法。
对于一个特定的问题,采用的数据结构不同,其设计的算法一般也不同,即使在同一种数据结构下,也可以采用不同的算法。那么,对于解决同一问题的不同算法,选择哪一种算法比较合适,以及如何对现有的算法进行改进,从而设计出更适合于数据结构的算法,这就是算法评价的问题。评价一个算法优劣的主要标准如下:
1、正确性(Correctness)。算法的执行结果应当满足预先规定的功能和性能的要求,这是评价一个算法的最重要也是最基本的标准。算法的正确性还包括对于输入、输出处理的明确而无歧义的描述。
2、可读性(Readability)。算法主要是为了人阅读和交流,其次才是机器的执行。所以,一个算法应当思路清晰、层次分明、简单明了、易读易懂。即使算法已转变成机器可执行的程序,也需要考虑人能较好地阅读理解。同时,一个可读性强的算法也有助于对算法中隐藏错误的排除和算法的移植。
3、健壮性(Robustness)。一个算法应该具有很强的容错能力,当输入不合法的数据时,算法应当能做适当的处理,使得不至于引起严重的后果。健壮性要求表明算法要全面细致地考虑所有可能出现的边界情况和异常情况,并对这些边界情况和异常情况做出妥善的处理,尽可能使算法没有意外的情况发生。
4、运行时间(Running Time)。运行时间是指算法在计算机上运行所花费的时间,它等于算法中每条语句执行时间的总和。对于同一个问题如果有多个算法可供选择,应尽可能选择执行时间短的算法。一般来说,执行时间越短,性能越好。
5、占用空间(Storage Space)。占用空间是指算法在计算机上存储所占用的存储空间,包括存储算法本身所占用的存储空间、算法的输入及输出数据所占用的存储空间和算法在运行过程中临时占用的存储空间。算法占用的存储空间是指算法执行过程中所需要的最大存储空间,对于一个问题如果有多个算法可供选择,应尽可能选择存储量需求低的算法。实际上,算法的时间效率和空间效率经常是一对矛盾,相互抵触。我们要根据问题的实际需要进行灵活的处理,有时需要牺牲空间来换取时间,有时需要牺牲时间来换取空间。
通常把算法在运行过程中临时占用的存储空间的大小叫算法的空间复杂度(Space Complexity)。算法的空间复杂度比较容易计算,它主要包括局部变量所占用的存储空间和系统为实现递归所使用的堆栈占用的存储空间。
如果算法是用计算机语言来描述的,还要看程序代码量的大小。对于同一个问题,在用上面5条标准评价的结果相同的情况下,代码量越少越好。实际上,代码量越大,占用的存储空间会越多,程序的运行时间也可能越长,出错的可能性也越大,阅读起来也越麻烦。
在以上标准中,本书主要考虑程序的运行时间,也考虑执行程序所占用的空间。影响程序运行时间的因素很多,包括算法本身、输入的数据以及运行程序的计算机系统等。计算机的性能由以下因素决定:
1、硬件条件。包括所使用的处理器的类型和速度(比如,使用双核处理器还是单核处理器)、可使用的内存(缓存和RAM)以及可使用的外存等。
2、实现算法所使用的计算机语言。实现算法的语言级别越高,其执行效率相对越低。
3、所使用的语言的编译器/解释器。一般而言,编译的执行效率高于解释,但解释具有更大的灵活性。
4、所使用的操作系统软件。操作系统的功能主要是管理计算机系统的软件和硬件资源,为计算机用户方便使用计算机提供一个接口。各种语言处理程序如编译程序、解释程序等和应用程序都在操作系统的控制下运行。
算法的时间复杂度
一个算法的时间复杂度(Time Complexity)是指该算法的运行时间与问题规模的对应关系。一个算法是由控制结构和原操作构成的,其执行的时间取决于二者的综合效果。为了便于比较同一问题的不同算法,通常把算法中基本操作重复执行的次数(频度)作为算法的时间复杂度。算法中的基本操作一般是指算法中最深层循环内的语句,因此,算法中基本操作语句的频度是问题规模n的某个函数f(n),记作:T(n)=O(f(n))。其中“O”表示随问题规模n的增大,算法执行时间的增长率和f(n)的增长率相同,或者说,用“O”符号表示数量级的概念。例如,如)1n(n21)n(T−=,则 )1n(n21−的数量级与n2相同,所以T(n)=O(n2)。
using System; using System.Collections.Generic; using System.Linq; using System.Text; namespace ConsoleApplication1 { class Program { static void Main(string[] args) { int n = 4; int x = n; int y = 0; while (y < x) { y = y + 1; // 频度是n,则程序段的时间复杂度是T(n)=O(4)。 } Console.WriteLine("运行结果:x={0},y={1},循环{2}次", x, y, n); Console.Read(); int n = 4; int a = 0; for (int i = 0; i < n; i++) { for (int j = 0; j < n; j++) { a = i * j; //频度为4*4,则程序段的时间复杂度为T(n)=O(16)。 } } Console.WriteLine("{0}", a); Console.Read(); int n = 4; int x = n; int y = 0; while (x >= (y + 1) * (y + 1)) { y = y + 1; //频度是√4,则程序段的时间复杂度是T(n)=O(2)。 } Console.WriteLine("{0}", y); Console.Read(); //for(i=0;i<m;i++) //{ // for(j=0;j<t;j++) // { // for(k=0;k<n;k++) // { // c[i][j]=c[i][j]+a[i][k]*b[k][j]; ① // } // } //} //解:这是三重循环的程序,最外层for循环的循环次数为m,中间层for循环的循环次数为t,最里层for循环的循环次数为t,所以,该程序段中语句①的频度是m*n*t,则程序段的时间复杂度是T(n)=O(m*n*t)。 } } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号