
网络作业
一、TCP/IP协议栈在Linux内核中的运行时序分析
1. Linux内核任务调度机制
1. 1 任务调度
1. 什么是调度器? What ?
调度器本质是一个 软件模块,普遍存在于 资源受限 的系统中,它负责将稀缺的系统资源(CPU 时间、内存、网络等)分配给运行实体(线程、进程、任务等),已达到最大化资源利用率、提高系统吞吐量、提高系统响应速度等特定业务场景需要的目标。
2. 调度器存在的意义/目的是什么? Why ?
调度器存在的目的就是为了解决 **系统资源供需不平衡 **的问题。 系统中可能同时存在成百上千个进程,但是 CPU 时间有限,调度器必须合理的将 CPU 执行时间分配个各个进程,以保证系统正确高效运行。
3. 设计一个任务调度系统需要考虑什么呢?How ?
我们知道,业务场景不同,系统需求不同,所以第一步是做需求调研。任务调度涉及两个对象,一个是任务,另一个是资源。也即是,分析系统中的任务是什么,执行该任务需要的资源是什么,有什么特性。比如对于任务说,该任务是否紧急,是否有截止时间,是否支持被抢占,是否需要特殊的资源等等。
4. Linux 中的任务调度 🌰
我们知道任务调度系统有两个要素-任务和资源。在 Linux 中,它把任务设计成一个结构体 task_struct,该结构体既可以表示线程,也可以表示成进程,调度器会把进程和线程都看作是任务,也即是 Linux 调度器不区分进程和线程,而是统一成任务。
5. Linux 任务调度器中使用了什么算法和数据结构呢?How?
Linux 版本从 v2.6.23 至今,使用的是一个叫做 完全公平的调度器(Completely Fair Scheduler CFS)。其中使用 **红黑树 **和 运行时间 保证调度的公平性。使用红黑树的目的很明显是利用红黑树增删查改操作最坏时间复杂度为 O(logn) 这一特点,能够快速插入和删除下一个待运行的进程。使用运行时间这个变量目的也很明显,控制进程的运行时间,是为了防止其他进程长时间的不到 CPU 时间而饥饿。
1.2 中断处理
1. 中断的本质是什么?What?
是外设控制器向 cpu 引脚发送电平信号?是 CUP 某个管脚电平的变化?还是 CPU 在每个指令周期执行后去检查中断寄存器的值?如果都不是,那中断的本质是什么呢?
中断使得计算机获得交互的能力,获得实时响应外部变化的能力。我们知道 CPU 只干两件事-取指和执行指令,可以想象如果没有中断,计算机功能是多么单一,cpu 就像在一个封闭的屋子里从头到尾执行,不收外界打扰,不与外界交流。有了中断后,计算机会兼容某些外部命令,并设置服务程序,这种服务程序就是用来打断当前运行程序的。所以,中断本质就是 处理器的标准输入接口,主动接受和响应外部的输入,服务外界的需求。
2. 中断是如何实现的呢?How?
Linux 内核把中断处理整个流程分为上半部和下半部。上半部就是中断处理函数,用于快速响应中断,做一些中断响应后立即需要做的事,也即是 **紧急的事 **放在中断上半部分来做。而不紧急的事放在中断下半部来做,也即是 延后处理。这样设计的目的是尽快的响应中断,防止处理当前中断时间过长,导致系统响应速度下降。
Linux 通过三种方式实现中断下半部:软中断、tasklet和工作队列
1. 软中断 softirq
软中断即软件实现的中断,它的优先级比硬件中断低。为了有效地管理不同的softirq中断源,Linux采用的是一个名为softirq_vec[]的数组,数组的大小由NR_SOFTIRQS 表示,这是在编译时就确定了的,不能在系统运行过程中动态添加。每个软中断在内核中以softirq_action表示,在kernel/softirq.c中定义了一个包含有32个该结构体的数组。每种软中断对应数组的一项,所以软中断最多有32项。
内核目前实现了10 个软中断,定义在linux/interrupt.h中。
enum
{
HI_SOFTIRQ=0, /* 高优先级tasklet */ /* 优先级最高 */
TIMER_SOFTIRQ, /* 时钟相关的软中断 */
NET_TX_SOFTIRQ, /* 将数据包传送到网卡 */
NET_RX_SOFTIRQ, /* 从网卡接收数据包 */
BLOCK_SOFTIRQ, /* 块设备的软中断 */
BLOCK_IOPOLL_SOFTIRQ, /* 支持IO轮询的块设备软中断 */
TASKLET_SOFTIRQ, /* 常规tasklet */
SCHED_SOFTIRQ, /* 调度程序软中断 */
HRTIMER_SOFTIRQ, /* 高精度计时器软中断 */
RCU_SOFTIRQ, /* RCU锁软中断,该软中断总是最后一个软中断 */
NR_SOFTIRQS /* 软中断数,为10 */
};
通过调用open_softirq接口函数,将action函数指针指向向该软中断应该执行的函数
/* 开启软中断 */
void open_softirq(int nr, void (*action)(struct softirq_action *))
{
softirq_vec[nr].action = action;
}
在start_kernel()进行系统初始化中,就调用了softirq_init()函数对HI_SOFTIRQ和TASKLET_SOFTIRQ两个软中断进行了初始化
void __init softirq_init(void)
{
int cpu;
for_each_possible_cpu(cpu) {
per_cpu(tasklet_vec, cpu).tail =
&per_cpu(tasklet_vec, cpu).head;
per_cpu(tasklet_hi_vec, cpu).tail =
&per_cpu(tasklet_hi_vec, cpu).head;
}
/* 开启常规tasklet */
open_softirq(TASKLET_SOFTIRQ, tasklet_action);
/* 开启高优先级tasklet */
open_softirq(HI_SOFTIRQ, tasklet_hi_action);
}
调用raise_softirq这个接口函数来触发本地CPU上的softirq
void raise_softirq(unsigned int nr)
{
unsigned long flags;
local_irq_save(flags);
raise_softirq_irqoff(nr);
local_irq_restore(flags);
}
先是关闭本地cpu中断,然后调用:raise_softirq_irqoff
inline void raise_softirq_irqoff(unsigned int nr)
{
__raise_softirq_irqoff(nr);
......
if (!in_interrupt())
wakeup_softirqd();
}
通过in_interrupt判断现在是否在中断上下文中,或者软中断是否被禁止,如果都不成立,否则,我们必须要调用wakeup_softirqd函数用来唤醒本CPU上的softirqd这个内核线程
2. tasklet
内核通过 tasklet_struct 来表示一个 tasklet
struct tasklet_struct
{
struct tasklet_struct *next;
unsigned long state;
atomic_t count;
void (*func)(unsigned long); //tasklet 处理函数
unsigned long data; // 传给处理函数的参数
};
每个cpu都会维护一个链表,将本cpu需要处理的tasklet管理起来,next这个成员指向了该链表中的下一个tasklet。
func和data成员描述了该tasklet的callback函数,func是调用函数,data是传递给func的参数。
state成员表示该tasklet的状态,TASKLET_STATE_SCHED表示该tasklet已经被调度到某个CPU上执行,TASKLET_STATE_RUN表示该tasklet正在某个cpu上执行。
count成员是和tasklet的状态相关,如果count等于0那么该tasklet是处于enable的,如果大于0,表示该tasklet是disable的。
在初始化 tasklet_struct 时,需要定义 tasklet 处理函数和参数,就像我们使用 c 语言链表一样。在中断发生后调用 tasklet (tasklet_schedule/tasklet_hi_schedule),当任务完成后就删除 tasklet (tasklet_kill)。
3. 工作队 wq
同样,内核使用 work_struct 结构体来管理一个工作队列 wq 中的任务,工作队列的原理是把work(需要推迟执行的函数)交由一个内核线程来执行,它总是在进程上下文中执行。
struct work_struct {
atomic_long_t data;
struct list_head entry;
work_func_t func; // 下半部实现的处理函数指针
#ifdef CONFIG_LOCKDEP
struct lockdep_map lockdep_map;
#endif
};
当中断发生后,调度 work_struct 指定的任务到工作队列 :
void queue_work(struct workqueue_struct *wq, struct work_struct *work)
此时任务的执行时机由内核调度器决定。当等待队列中的所有任务全部执行完时,等待队列 wq 为空,此时就删除等待队列:
void destroy_workqueue(struct workqueue_struct *wq)
工作队列由struct workqueue_struct数据结构描述
struct workqueue_struct {
struct list_head pwqs; /* WR: all pwqs of this wq */ // 该workqueue所在的所有pool_workqueue链表
struct list_head list; /* PL: list of all workqueues */ // 系统所有workqueue_struct的全局链表
struct mutex mutex; /* protects this wq */
int work_color; /* WQ: current work color */
int flush_color; /* WQ: current flush color */
atomic_t nr_pwqs_to_flush; /* flush in progress */
struct wq_flusher *first_flusher; /* WQ: first flusher */
struct list_head flusher_queue; /* WQ: flush waiters */
struct list_head flusher_overflow; /* WQ: flush overflow list */
struct list_head maydays; /* MD: pwqs requesting rescue */
struct worker *rescuer; /* I: rescue worker */
int nr_drainers; /* WQ: drain in progress */
int saved_max_active; /* WQ: saved pwq max_active */
struct workqueue_attrs *unbound_attrs; /* WQ: only for unbound wqs */
struct pool_workqueue *dfl_pwq; /* WQ: only for unbound wqs */
#ifdef CONFIG_SYSFS
struct wq_device *wq_dev; /* I: for sysfs interface */
#endif
#ifdef CONFIG_LOCKDEP
struct lockdep_map lockdep_map;
#endif
char name[WQ_NAME_LEN]; /* I: workqueue name */ // 该workqueue的名字
/* hot fields used during command issue, aligned to cacheline */
unsigned int flags ____cacheline_aligned; /* WQ: WQ_* flags */ // 经常被不同CUP访问,因此要和cache line对齐
struct pool_workqueue __percpu *cpu_pwqs; /* I: per-cpu pwqs */ // 指向per-cpu类型的pool_workqueue
struct pool_workqueue __rcu *numa_pwq_tbl[]; /* FR: unbound pwqs indexed by node */
}
工作队列的优点是利用进程上下文来执行中断下半部操作,因此工作队列允许重新调度和睡眠,是异步执行的进程上下文,它还能解决软中断和tasklet执行时间过长导致系统实时性下降等问题。
运行work_struct的内核线程被称为worker,即工作线程。
/*
* The poor guys doing the actual heavy lifting. All on-duty workers are
* either serving the manager role, on idle list or on busy hash. For
* details on the locking annotation (L, I, X...), refer to workqueue.c.
*
* Only to be used in workqueue and async.
*/
struct worker {
/* on idle list while idle, on busy hash table while busy */
union {
struct list_head entry; /* L: while idle */
struct hlist_node hentry; /* L: while busy */
};
struct work_struct *current_work; /* L: work being processed */-当前正在处理的work
work_func_t current_func; /* L: current_work's fn */-当前正在执行的work回调函数
struct pool_workqueue *current_pwq; /* L: current_work's pwq */-当前work所属的pool_workqueue
bool desc_valid; /* ->desc is valid */
struct list_head scheduled; /* L: scheduled works */-所有被调度并正准备执行的work_struct都挂入该链表中
/* 64 bytes boundary on 64bit, 32 on 32bit */
struct task_struct *task; /* I: worker task */-该工作线程的task_struct数据结构
struct worker_pool *pool; /* I: the associated pool */-该工作线程所属的worker_pool
/* L: for rescuers */
struct list_head node; /* A: anchored at pool->workers */-可以把该worker挂入到worker_pool->workers链表中
/* A: runs through worker->node */
unsigned long last_active; /* L: last active timestamp */
unsigned int flags; /* X: flags */
int id; /* I: worker id */
/*
* Opaque string set with work_set_desc(). Printed out with task
* dump for debugging - WARN, BUG, panic or sysrq.
*/
char desc[WORKER_DESC_LEN];
/* used only by rescuers to point to the target workqueue */
struct workqueue_struct *rescue_wq; /* I: the workqueue to rescue */
}
CMWQ提出了工作线程池的概念,struct worker_pool数据结构用于描述工作线程池
struct worker_pool {
spinlock_t lock; /* the pool lock */-用于保护worker_pool的自旋锁
int cpu; /* I: the associated cpu */-对于unbound类型为-1;对于bound类型workqueue表示绑定的CPU ID。
int node; /* I: the associated node ID */
int id; /* I: pool ID */-该worker_pool的ID号
unsigned int flags; /* X: flags */
struct list_head worklist; /* L: list of pending works */-挂入pending状态的work_struct
int nr_workers; /* L: total number of workers */-工作线程的数量
/* nr_idle includes the ones off idle_list for rebinding */
int nr_idle; /* L: currently idle ones */-处于idle状态的工作线程的数量
struct list_head idle_list; /* X: list of idle workers */-处于idle状态的工作线程链表
struct timer_list idle_timer; /* L: worker idle timeout */
struct timer_list mayday_timer; /* L: SOS timer for workers */
/* a workers is either on busy_hash or idle_list, or the manager */
DECLARE_HASHTABLE(busy_hash, BUSY_WORKER_HASH_ORDER);
/* L: hash of busy workers */
/* see manage_workers() for details on the two manager mutexes */
struct mutex manager_arb; /* manager arbitration */
struct mutex attach_mutex; /* attach/detach exclusion */
struct list_head workers; /* A: attached workers */-该worker_pool管理的工作线程链表
struct completion *detach_completion; /* all workers detached */
struct ida worker_ida; /* worker IDs for task name */
struct workqueue_attrs *attrs; /* I: worker attributes */-工作线程属性
struct hlist_node hash_node; /* PL: unbound_pool_hash node */
int refcnt; /* PL: refcnt for unbound pools */
/*
* The current concurrency level. As it's likely to be accessed
* from other CPUs during try_to_wake_up(), put it in a separate
* cacheline.
*/
atomic_t nr_running ____cacheline_aligned_in_smp;-用于管理worker的创建和销毁的统计计数,表示运行中的worker数量。该变量可能被多CPU同时访问,因此独占一个缓存行,避免多核读写造成“颠簸”现象。
/*
* Destruction of pool is sched-RCU protected to allow dereferences
* from get_work_pool().
*/
struct rcu_head rcu;-RCU锁
}
struct pool_workqueue用于链接workqueue和worker_pool
struct pool_workqueue {
struct worker_pool *pool; /* I: the associated pool */-指向worker_pool结构
struct workqueue_struct *wq; /* I: the owning workqueue */-指向workqueue_struct结构
int work_color; /* L: current color */
int flush_color; /* L: flushing color */
int refcnt; /* L: reference count */
int nr_in_flight[WORK_NR_COLORS];
/* L: nr of in_flight works */
int nr_active; /* L: nr of active works */-活跃的work_strcut数量
int max_active; /* L: max active works */-最大活跃work_struct数量
struct list_head delayed_works; /* L: delayed works */-延迟执行work_struct链表
struct list_head pwqs_node; /* WR: node on wq->pwqs */
struct list_head mayday_node; /* MD: node on wq->maydays */
/*
* Release of unbound pwq is punted to system_wq. See put_pwq()
* and pwq_unbound_release_workfn() for details. pool_workqueue
* itself is also sched-RCU protected so that the first pwq can be
* determined without grabbing wq->mutex.
*/
struct work_struct unbound_release_work;
struct rcu_head rcu;-RCU锁
}
2. send 和 recv 过程中的运行任务实体及相互协作的时序分析
1. OSI七层网络模型和TCP/IP网络模型
计算机网络是一个非常庞大且复杂的系统, 分层 的设计理念。分层将庞大的问题细分为了若干个局部的小问题,具有下列好处:
- 分层隔离
- 灵活性好
- 易于实现和维护
- 能促进标准化工作
其中 标准化 是促进互联网全球化的关键,在计算机网络领域,你会听说到各种各样的协议,这些都是标准化的结果。试想,如果每个网卡厂商都使用了不同的网线接口风格,那无疑是一个灾难。
主流网络分层体系结构有两种:
- OSI(Open Systems Interconnection Reference Model,开放系统互联基本参考模型),就是常说的七层网络模型。
- TCP/IP(Transmission Control Protocol/Internet Protocol,传输控制协议/因特网协议) 四层网络模型,也有人愿意归为 “五层网络模型”,以其中最重要的 TCP 协议和 IP 协议命名。

计算机网络的分层体系结构虽然是抽象的,但实现则是具体的
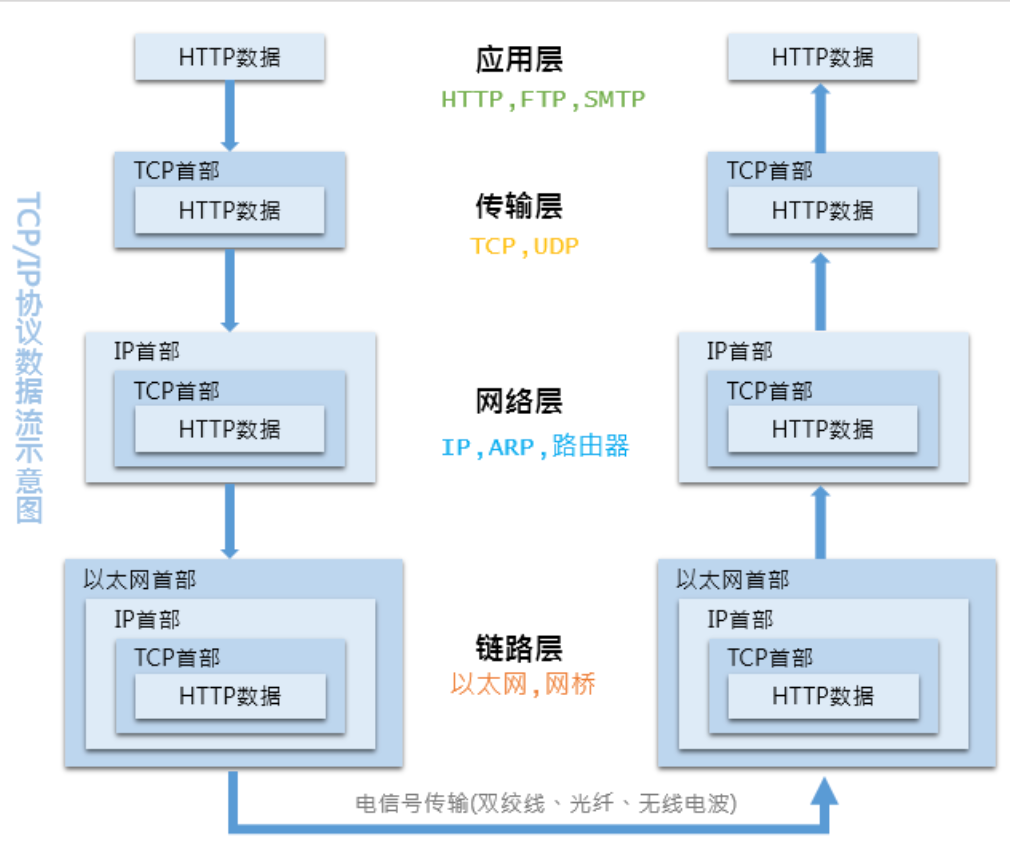
TCP/IP 的每个层级都依赖于下层支撑,越往上就离用户越近,反之则离硬件越近。从上至下,不断为应用数据附加首部的过程称为 封装 ,从下至上不断解析首部的过程则称为 解封装 。
2. 网络包类型:帧、包、段、报文
- 应用层 — 消息/报文(Message):应用层的信息分组称为数据报文,报文包含了将要发送的完整的数据信息,其长短不需一致。报文在传输过程中会不断地封装成段、包、帧来进行传输,封装的方式就是添加一些控制信息组成的首部,那些就是报文头。
- 传输层 — 报文段(TCP,Segment)/数据报(UDP,Datagram)
- 报文段:指起始点和目的地都是传输层的信息单元。
- 数据段:面向无连接的数据传输,其工作过程类似于报文交换。采用数据段方式传输时,被传输的分组称为数据段。通常指起始点和目的地都使用无连接网络服务的的网络层的信息单元。
- 网络层 — 数据包(Packet)/分组:分组/包是在网络中传输的二进制格式的单元,为了提供通信性能和可靠性,每个用户发送的数据报文会被分成多个更小的部分。在每个部分的前面加上一些必要的控制信息组成的首部,有时也会加上尾部,就构成了一个分组/包。它的起始和目的地是网络层。
- 链路层 — 帧(Frame):帧是数据链路层的传输单元。它将上层传入的数据添加一个头部和尾部,组成了帧。它的起始点和目的点都是数据链路层。
- 物理层 — P-PDU(Bit):以 01 电信号(比特数据位)的形式在物理介质中传输。
3. send 数据的收发过程
send和recv是TCP常用的发送数据和接受数据函数,在linux内核的代码通过下面两个函数实现:
ssize_t recv(int sockfd, void *buf, size_t len, int flags)
ssize_t send(int sockfd, const void *buf, size_t len, int flags)
逻辑分析
对于send函数,比较容易理解,捋一下计算机网络的知识,可以大概的到实现的方法,首先TCP是面向连接的,会有三次握手,建立连接成功,即代表两个进程可以用send和recv通信,作为发送信息的一方,肯定是接收到了从用户程序发送数据的请求,即send函数的参数之一,接收到数据后,若数据的大小超过一定长度,肯定不可能直接发送除去,因此,首先要对数据分段,将数据分成一个个的代码段。
其次,TCP协议位于传输层,有响应的头部字段,在传输时肯定要加在数据前,数据也就被准备好了。当然,TCP是没有能力直接通过物理链路发送出去的,要想数据正确传输,还需要一层一层的进行。所以,最后一步是将数据传递给网络层,网络层再封装,然后链路层、物理层,最后被发送除去。总结一下就是:
- 数据分段
- 封装头部
- 传递给下一层。
对于secv函数,有一个不太能理解的就是,作为接收方,我是否是一直在等待其他进程给我发送数据,如果是,那么就应该是不停的判断是否有数到了,如果有,就把数据保存起来,然后执行send的逆过程即可。若没有一直等,那就可能是进程被挂起了,如果有数据到达,内核通过中断唤醒进程,然后接收数据。至于具体是哪种,可以通过代码和调试得到结果。
代码分析
当调用send()函数时, 内核封装 send() 为 sendto() ,然后发起系统调用。其实也很好理解,send()就是sendto()的一种特殊情况,而sendto()在内核的系统调用服务程序为 sys_sendto。
int __sys_sendto(int fd, void __user *buff, size_t len, unsigned int flags,
struct sockaddr __user *addr, int addr_len)
{
struct socket *sock;
struct sockaddr_storage address;
int err;
struct msghdr msg; // 下面分析
struct iovec iov; // 下面分析
int fput_needed;
err = import_single_range(WRITE, buff, len, &iov, &msg.msg_iter);
if (unlikely(err))
return err;
sock = sockfd_lookup_light(fd, &err, &fput_needed);
if (!sock)
goto out;
msg.msg_name = NULL;
msg.msg_control = NULL;
msg.msg_controllen = 0;
msg.msg_namelen = 0;
if (addr) {
err = move_addr_to_kernel(addr, addr_len, &address);
if (err < 0)
goto out_put;
msg.msg_name = (struct sockaddr *)&address;
msg.msg_namelen = addr_len;
}
if (sock->file->f_flags & O_NONBLOCK)
flags |= MSG_DONTWAIT;
msg.msg_flags = flags;
err = sock_sendmsg(sock, &msg); // 发送数据
out_put:
fput_light(sock->file, fput_needed);
out:
return err;
}
这里定义了一个 struct msghdr 是用来表示要发送的数据的一些属性:
struct msghdr {
void *msg_name; /* 接收方的struct sockaddr结构体地址 (用于udp)*/
int msg_namelen; /* 接收方的struct sockaddr结构体地址(用于udp)*/
struct iov_iter msg_iter; /* io缓冲区的地址 */
void *msg_control; /* 辅助数据的地址 */
__kernel_size_t msg_controllen; /* 辅助数据的长度 */
unsigned int msg_flags; /* 接受消息的表示 */
struct kiocb *msg_iocb; /* ptr to iocb for async requests */
};
还有 struct iovec,他被称为io向量,故名思意,用来表示io数据的一些信息。
struct iovec
{
void __user *iov_base; /* 要传输数据的用户态下的地址 */
__kernel_size_t iov_len; /* 要传输数据的长度 */
};
所以,__sys_sendto 函数其实做了3件事:
- 通过fd获取了对应的 struct socket
- 创建了用来描述要发送的数据的结构体 struct msghdr
- 调用 sock_sendmsg 来执行实际的发送
继续追踪这个函数,会看到最终调用的是 sock->ops->sendmsg(sock, msg, msg_data_left(msg)), 即socket在初始化时赋值给结构体 struct proto tcp_prot 的函数 tcp_sendmsg。
struct proto tcp_prot = {
.name = "TCP",
.owner = THIS_MODULE,
.close = tcp_close,
.pre_connect = tcp_v4_pre_connect,
.connect = tcp_v4_connect,
.disconnect = tcp_disconnect,
.accept = inet_csk_accept,
.ioctl = tcp_ioctl,
.init = tcp_v4_init_sock,
.destroy = tcp_v4_destroy_sock,
.shutdown = tcp_shutdown,
.setsockopt = tcp_setsockopt,
.getsockopt = tcp_getsockopt,
.keepalive = tcp_set_keepalive,
.recvmsg = tcp_recvmsg,
.sendmsg = tcp_sendmsg,
...
}
tcp_sendmsg 实际上调用的是 tcp_sendmsg_locked
int tcp_sendmsg_locked(struct sock *sk, struct msghdr *msg, size_t size)
{
struct tcp_sock *tp = tcp_sk(sk);/*进行了强制类型转换*/
struct sk_buff *skb;
flags = msg->msg_flags;
......
if (copied)
tcp_push(sk, flags & ~MSG_MORE, mss_now,
TCP_NAGLE_PUSH, size_goal);
}
在 tcp_sendmsg_locked 中,完成的是将所有的数据组织成发送队列,这个发送队列是struct sock结构中的一个域sk_write_queue,这个队列的每一个元素是一个skb,里面存放的就是待发送的数据。然后调用了tcp_push()函数。
struct sock{
...
struct sk_buff_head sk_write_queue;/*指向skb队列的第一个元素*/
...
struct sk_buff *sk_send_head;/*指向队列第一个还没有发送的元素*/
}
在tcp协议的头部有几个标志字段:URG、ACK、RSH、RST、SYN、FIN,tcp_push 中会判断这个skb的元素是否需要push,如果需要就将tcp头部字段的push置一,置一的过程如下:
static void tcp_push(struct sock *sk, int flags, int mss_now,
int nonagle, int size_goal)
{
struct tcp_sock *tp = tcp_sk(sk);
struct sk_buff *skb;
skb = tcp_write_queue_tail(sk);
if (!skb)
return;
if (!(flags & MSG_MORE) || forced_push(tp))
tcp_mark_push(tp, skb);
tcp_mark_urg(tp, flags);
if (tcp_should_autocork(sk, skb, size_goal)) {
/* avoid atomic op if TSQ_THROTTLED bit is already set */
if (!test_bit(TSQ_THROTTLED, &sk->sk_tsq_flags)) {
NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPAUTOCORKING);
set_bit(TSQ_THROTTLED, &sk->sk_tsq_flags);
}
/* It is possible TX completion already happened
* before we set TSQ_THROTTLED.
*/
if (refcount_read(&sk->sk_wmem_alloc) > skb->truesize)
return;
}
if (flags & MSG_MORE)
nonagle = TCP_NAGLE_CORK;
__tcp_push_pending_frames(sk, mss_now, nonagle);
}
整个过程会有点绕,首先 struct tcp_skb_cb结构体存放的就是tcp的头部,头部的控制位为tcp_flags,通过tcp_mark_push 会将skb中的cb,也就是48个字节的数组,类型转换为 struct tcp_skb_cb,这样位于skb的cb就成了tcp的头部。
static inline void tcp_mark_push(struct tcp_sock *tp, struct sk_buff *skb)
{
TCP_SKB_CB(skb)->tcp_flags |= TCPHDR_PSH;
tp->pushed_seq = tp->write_seq;
}
...
#define TCP_SKB_CB(__skb) ((struct tcp_skb_cb *)&((__skb)->cb[0]))
...
struct sk_buff {
...
char cb[48] __aligned(8);
...
};
struct tcp_skb_cb {
__u32 seq; /* Starting sequence number */
__u32 end_seq; /* SEQ + FIN + SYN + datalen */
__u8 tcp_flags; /* tcp头部标志,位于第13个字节tcp[13]) */
......
};
然后,tcp_push调用了__tcp_push_pending_frames(sk, mss_now, nonagle) 函数发送数据:
void __tcp_push_pending_frames(struct sock *sk, unsigned int cur_mss,
int nonagle)
{
if (tcp_write_xmit(sk, cur_mss, nonagle, 0,
sk_gfp_mask(sk, GFP_ATOMIC)))
tcp_check_probe_timer(sk);
}
其中又调用了tcp_write_xmit来发送数据:
static bool tcp_write_xmit(struct sock *sk, unsigned int mss_now, int nonagle,
int push_one, gfp_t gfp)
{
struct tcp_sock *tp = tcp_sk(sk);
struct sk_buff *skb;
unsigned int tso_segs, sent_pkts;
int cwnd_quota;
int result;
bool is_cwnd_limited = false, is_rwnd_limited = false;
u32 max_segs;
/*统计已发送的报文总数*/
sent_pkts = 0;
......
/*若发送队列未满,则准备发送报文*/
while ((skb = tcp_send_head(sk))) {
unsigned int limit;
if (unlikely(tp->repair) && tp->repair_queue == TCP_SEND_QUEUE) {
/* "skb_mstamp_ns" is used as a start point for the retransmit timer */
skb->skb_mstamp_ns = tp->tcp_wstamp_ns = tp->tcp_clock_cache;
list_move_tail(&skb->tcp_tsorted_anchor, &tp->tsorted_sent_queue);
tcp_init_tso_segs(skb, mss_now);
goto repair; /* Skip network transmission */
}
if (tcp_pacing_check(sk))
break;
tso_segs = tcp_init_tso_segs(skb, mss_now);
BUG_ON(!tso_segs);
/*检查发送窗口的大小*/
cwnd_quota = tcp_cwnd_test(tp, skb);
if (!cwnd_quota) {
if (push_one == 2)
/* Force out a loss probe pkt. */
cwnd_quota = 1;
else
break;
}
if (unlikely(!tcp_snd_wnd_test(tp, skb, mss_now))) {
is_rwnd_limited = true;
break;
......
limit = mss_now;
if (tso_segs > 1 && !tcp_urg_mode(tp))
limit = tcp_mss_split_point(sk, skb, mss_now,
min_t(unsigned int,
cwnd_quota,
max_segs),
nonagle);
if (skb->len > limit &&
unlikely(tso_fragment(sk, TCP_FRAG_IN_WRITE_QUEUE,
skb, limit, mss_now, gfp)))
break;
if (tcp_small_queue_check(sk, skb, 0))
break;
if (unlikely(tcp_transmit_skb(sk, skb, 1, gfp)))
break;
......
}
tcp_write_xmit 位于 tcpoutput.c中,它实现了tcp的拥塞控制,然后调用了 tcp_transmit_skb(sk, skb, 1, gfp)传输数据,实际上调用的是 __tcp_transmit_skb :
static int __tcp_transmit_skb(struct sock *sk, struct sk_buff *skb,
int clone_it, gfp_t gfp_mask, u32 rcv_nxt)
{
skb_push(skb, tcp_header_size);
skb_reset_transport_header(skb);
......
/* 构建TCP头部和校验和 */
th = (struct tcphdr *)skb->data;
th->source = inet->inet_sport;
th->dest = inet->inet_dport;
th->seq = htonl(tcb->seq);
th->ack_seq = htonl(rcv_nxt);
tcp_options_write((__be32 *)(th + 1), tp, &opts);
skb_shinfo(skb)->gso_type = sk->sk_gso_type;
if (likely(!(tcb->tcp_flags & TCPHDR_SYN))) {
th->window = htons(tcp_select_window(sk));
tcp_ecn_send(sk, skb, th, tcp_header_size);
} else {
/* RFC1323: The window in SYN & SYN/ACK segments
* is never scaled.
*/
th->window = htons(min(tp->rcv_wnd, 65535U));
}
......
icsk->icsk_af_ops->send_check(sk, skb);
if (likely(tcb->tcp_flags & TCPHDR_ACK))
tcp_event_ack_sent(sk, tcp_skb_pcount(skb), rcv_nxt);
if (skb->len != tcp_header_size) {
tcp_event_data_sent(tp, sk);
tp->data_segs_out += tcp_skb_pcount(skb);
tp->bytes_sent += skb->len - tcp_header_size;
}
if (after(tcb->end_seq, tp->snd_nxt) || tcb->seq == tcb->end_seq)
TCP_ADD_STATS(sock_net(sk), TCP_MIB_OUTSEGS,
tcp_skb_pcount(skb));
tp->segs_out += tcp_skb_pcount(skb);
/* OK, its time to fill skb_shinfo(skb)->gso_{segs|size} */
skb_shinfo(skb)->gso_segs = tcp_skb_pcount(skb);
skb_shinfo(skb)->gso_size = tcp_skb_mss(skb);
/* Leave earliest departure time in skb->tstamp (skb->skb_mstamp_ns) */
/* Cleanup our debris for IP stacks */
memset(skb->cb, 0, max(sizeof(struct inet_skb_parm),
sizeof(struct inet6_skb_parm)));
err = icsk->icsk_af_ops->queue_xmit(sk, skb, &inet->cork.fl);
......
}
tcp_transmit_skb是tcp发送数据位于传输层的最后一步,这里首先对TCP数据段的头部进行了处理,然后调用了网络层提供的发送接口 icsk->icsk_af_ops->queue_xmit(sk, skb, &inet->cork.fl);实现了数据的发送,自此,数据离开了传输层,传输层的任务也就结束了。
4. recv 数据的收发过程
对于recv函数,与send类似,自然也是recvfrom的特殊情况,调用的也就是 __sys_recvfrom,整个函数的调用路径与send非常类似:
int __sys_recvfrom(int fd, void __user *ubuf, size_t size, unsigned int flags,
struct sockaddr __user *addr, int __user *addr_len)
{
......
err = import_single_range(READ, ubuf, size, &iov, &msg.msg_iter);
if (unlikely(err))
return err;
sock = sockfd_lookup_light(fd, &err, &fput_needed);
.....
msg.msg_control = NULL;
msg.msg_controllen = 0;
/* Save some cycles and don't copy the address if not needed */
msg.msg_name = addr ? (struct sockaddr *)&address : NULL;
/* We assume all kernel code knows the size of sockaddr_storage */
msg.msg_namelen = 0;
msg.msg_iocb = NULL;
msg.msg_flags = 0;
if (sock->file->f_flags & O_NONBLOCK)
flags |= MSG_DONTWAIT;
err = sock_recvmsg(sock, &msg, flags); // 实际调用的函数,接受数据
if (err >= 0 && addr != NULL) {
err2 = move_addr_to_user(&address,
msg.msg_namelen, addr, addr_len);
...
}
__sys_recvfrom 调用了 sock_recvmsg 来接收数据,sock_recvmgs 实际调用的是 sock->ops->recvmsg,同样,根据tcp_prot结构的初始化,最终调用的其实是 tcp_rcvmsg。
接受函数比发送函数要复杂得多,因为数据接收不仅仅只是接收,tcp的三次握手也是在接收函数实现的,所以收到数据后要判断当前的状态,是否正在建立连接等,根据发来的信息考虑状态是否要改变,在这里,我们仅仅考虑在连接建立后数据的接收。
int tcp_recvmsg(struct sock *sk, struct msghdr *msg, size_t len, int nonblock,
int flags, int *addr_len)
{
......
if (sk_can_busy_loop(sk) && skb_queue_empty(&sk->sk_receive_queue) &&
(sk->sk_state == TCP_ESTABLISHED))
sk_busy_loop(sk, nonblock);
lock_sock(sk);
.....
if (unlikely(tp->repair)) {
err = -EPERM;
if (!(flags & MSG_PEEK))
goto out;
if (tp->repair_queue == TCP_SEND_QUEUE)
goto recv_sndq;
err = -EINVAL;
if (tp->repair_queue == TCP_NO_QUEUE)
goto out;
......
last = skb_peek_tail(&sk->sk_receive_queue);
skb_queue_walk(&sk->sk_receive_queue, skb) {
last = skb;
......
if (!(flags & MSG_TRUNC)) {
err = skb_copy_datagram_msg(skb, offset, msg, used);
if (err) {
/* Exception. Bailout! */
if (!copied)
copied = -EFAULT;
break;
}
}
*seq += used;
copied += used;
len -= used;
tcp_rcv_space_adjust(sk);
...
}
这里共维护了三个队列:
- prequeue 预处理队列
- backlog 后备队列
- receive_queue 接收队列
若没有数据到来,接收队列为空,进程会在 sk_busy_loop 数内循环等待,知道接收队列不为空,并调用函数数skb_copy_datagram_msg 将接收到的数据拷贝到用户态,实际调用的是 __skb_datagram_iter,这里同样用了struct msghdr *msg来实现。
int __skb_datagram_iter(const struct sk_buff *skb, int offset,
struct iov_iter *to, int len, bool fault_short,
size_t (*cb)(const void *, size_t, void *, struct iov_iter *),
void *data)
{
int start = skb_headlen(skb);
int i, copy = start - offset, start_off = offset, n;
struct sk_buff *frag_iter;
/* 拷贝tcp头部 */
if (copy > 0) {
if (copy > len)
copy = len;
n = cb(skb->data + offset, copy, data, to);
offset += n;
if (n != copy)
goto short_copy;
if ((len -= copy) == 0)
return 0;
}
/* 拷贝数据部分 */
for (i = 0; i < skb_shinfo(skb)->nr_frags; i++) {
int end;
const skb_frag_t *frag = &skb_shinfo(skb)->frags[i];
WARN_ON(start > offset + len);
end = start + skb_frag_size(frag);
if ((copy = end - offset) > 0) {
struct page *page = skb_frag_page(frag);
u8 *vaddr = kmap(page);
if (copy > len)
copy = len;
n = cb(vaddr + frag->page_offset +
offset - start, copy, data, to);
kunmap(page);
offset += n;
if (n != copy)
goto short_copy;
if (!(len -= copy))
return 0;
}
start = end;
}
拷贝完成后,函数返回,整个接收的过程也就完成了。
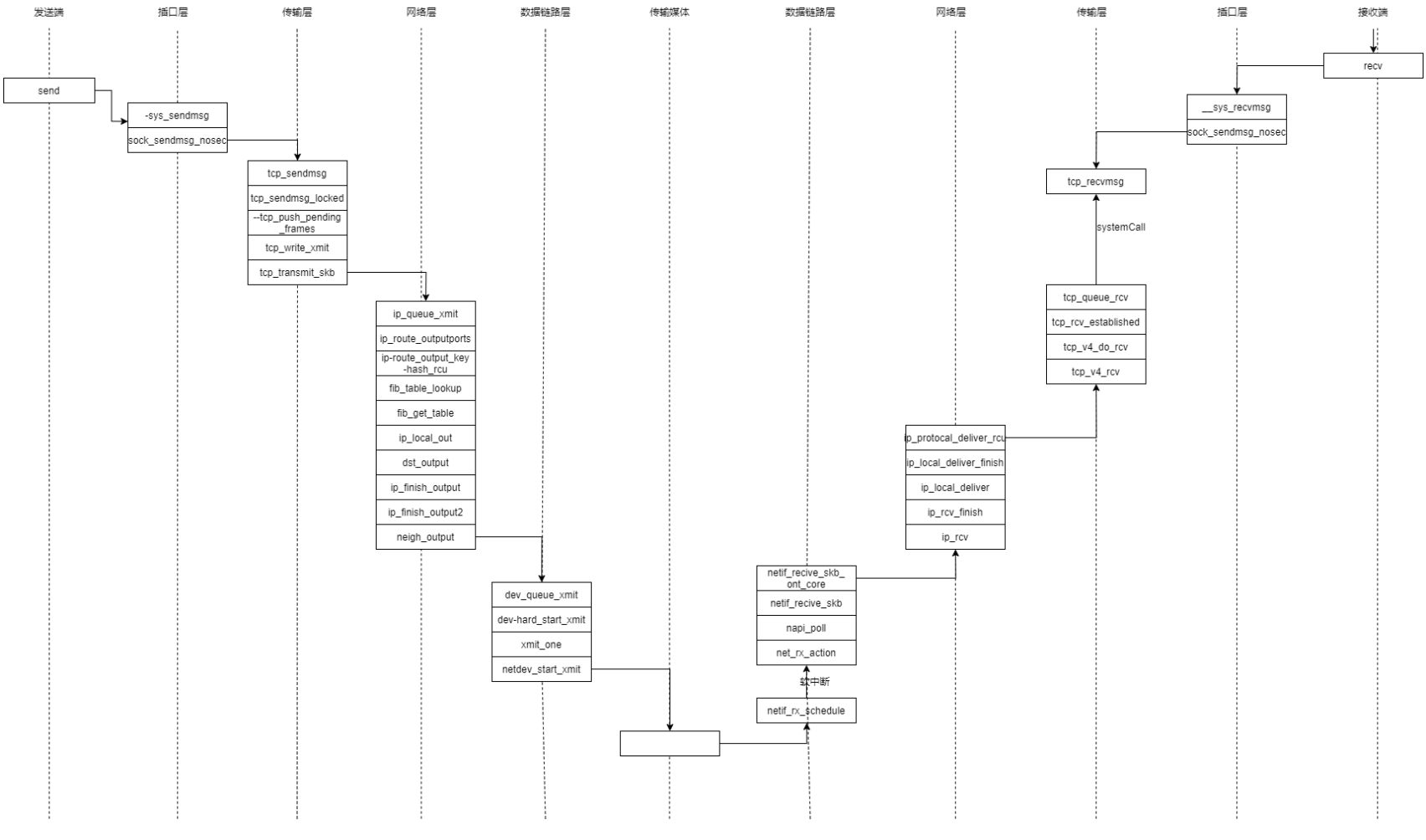
整体来讲与我们的分析并不大,用一张函数间的相互调用图可以表示:

4. gdb 调试
首先看send的调用关系,分别将断点打在
- __sys_sendto
- __tcp_sendmsg_locked
- __tcp_push
- tcp_push_pending_frames
- tcp_write_xmit
- __tcp_transmit_skb , 观察函数的调用顺序,与我们的分析是否一致。
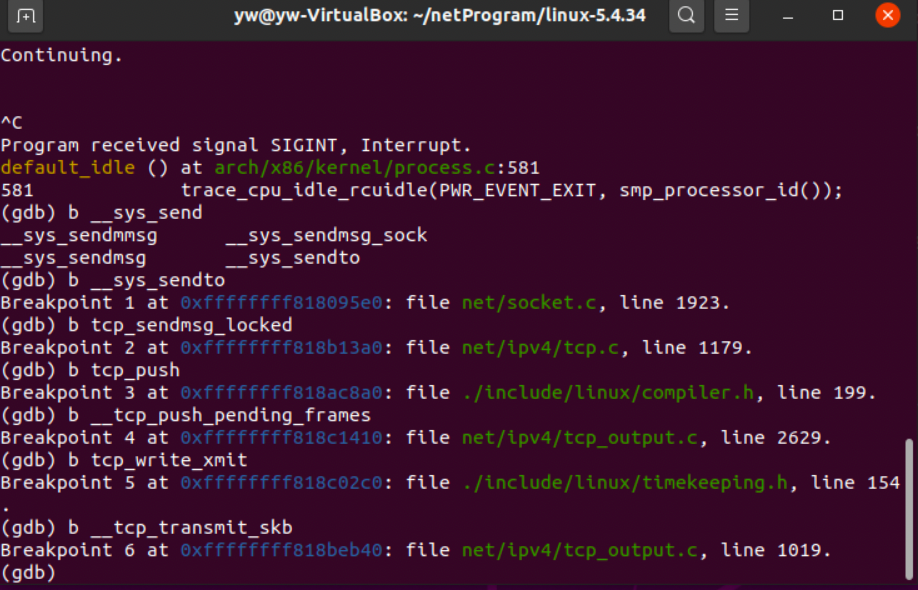
执行client命令,观察程序暂停的位置:

这应该是三次握手的过程,继续调试:
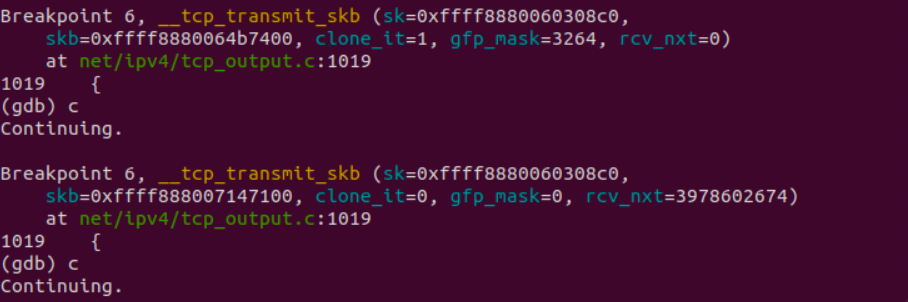
又有两次停在了这里,恰恰验证了猜想,因为这个程序的服务端和客户端都在同一台主机上,共用了同一个TCP协议栈,在TCP三次握手时,客户端发送两次,服务端发送一次,恰好三次。下面我们用客户端向服务器端发送,分析程序的调用过程:
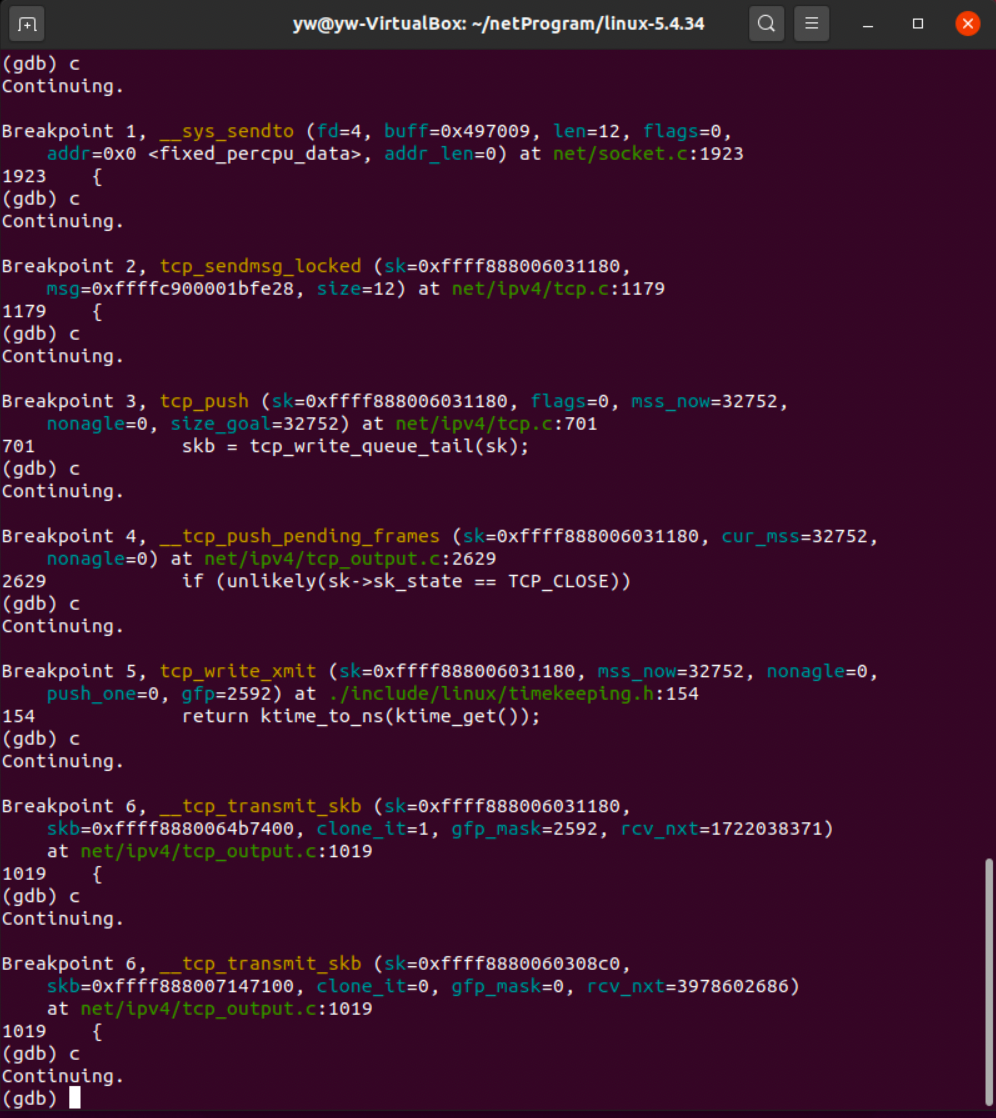
可以看到,与我们分析的顺序是一致的,但是最后__tcp_transmit_skb调用了两次,经过仔细分析,终于找到原因——这是接收方接收到数据后发送ACK使用的。
验证完send,来验证一下recv,将断点分别设在:
- __sys_recvfrom
- sock_recvmsg
- tcp_rcvmsg
- __skb_datagram_iter
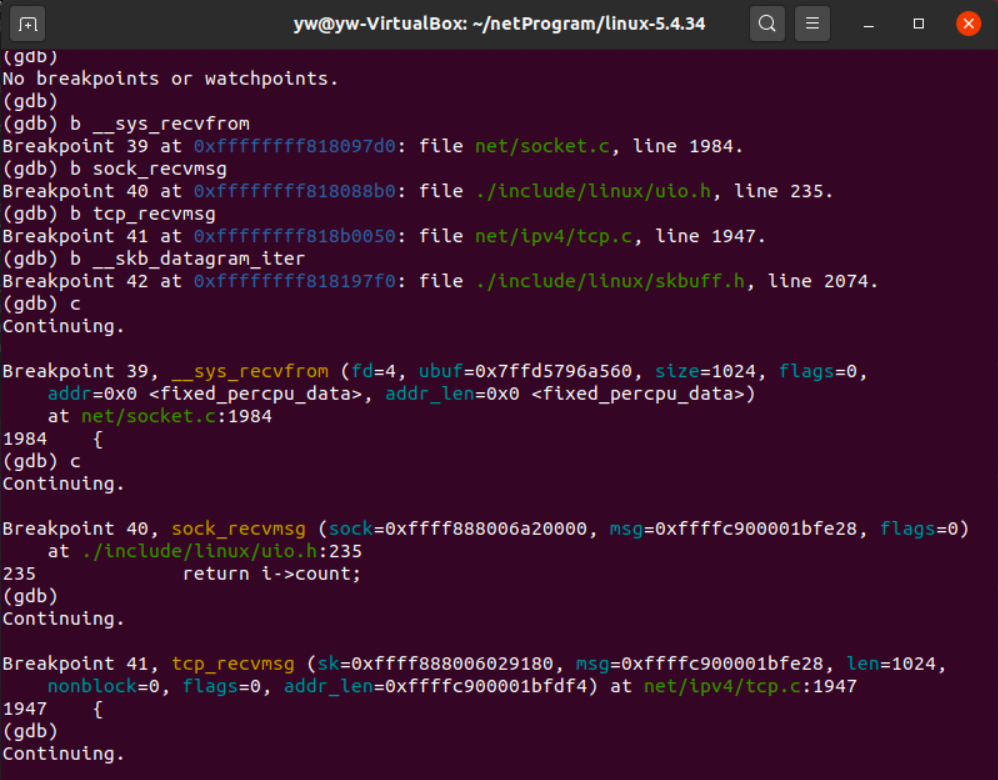
在未发送之前,程序也会暂停在断点处,根据之前的分析,这也是三次握手的过程,没有__skb_datagram_iter,是因为三次握手时,并没有发送数据过来,所以并没有数据被拷贝到用户空间。
同样,尝试发送数据观察调用过程。
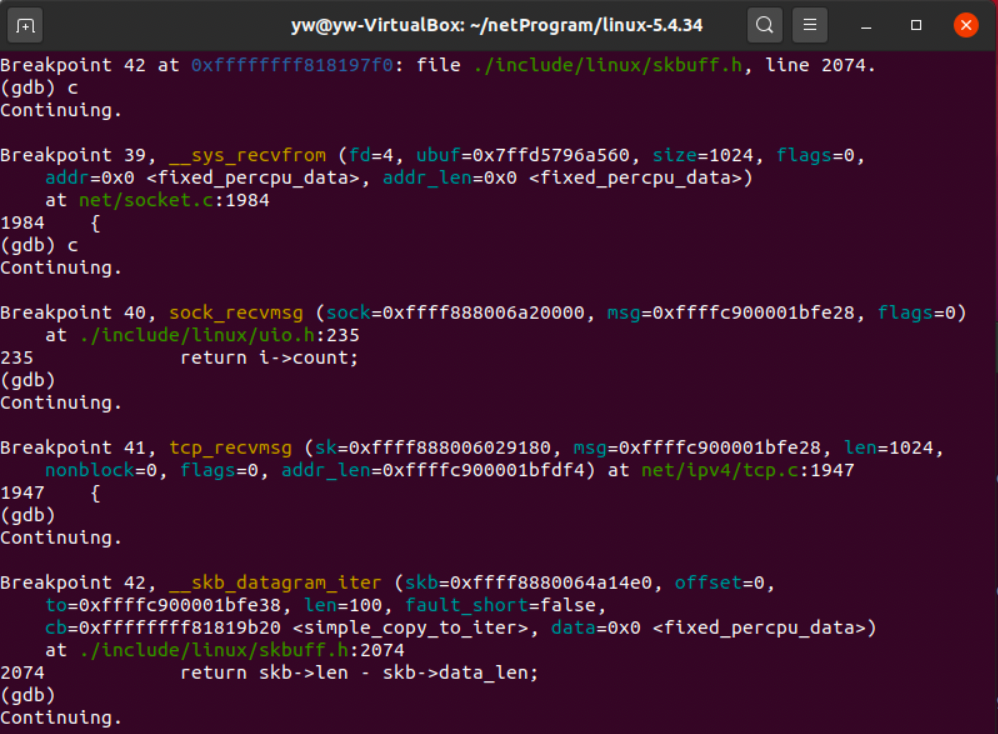
调试分析完毕
5. 时序图
参考链接:

