

Lucene的中文分词器
1 什么是中文分词器
学过英文的都知道,英文是以单词为单位的,单词与单词之间以空格或者逗号句号隔开。
而中文的语义比较特殊,很难像英文那样,一个汉字一个汉字来划分。
所以需要一个能自动识别中文语义的分词器。
2. Lucene自带的中文分词器
StandardAnalyzer
单字分词:就是按照中文一个字一个字地进行分词。如:“我爱中国”,
效果:“我”、“爱”、“中”、“国”。
CJKAnalyzer
二分法分词:按两个字进行切分。如:“我是中国人”,效果:“我是”、“是中”、“中国”“国人”。
上边两个分词器无法满足对中文的需求。
3. 使用中文分词器IKAnalyzer
IKAnalyzer继承Lucene的Analyzer抽象类,使用IKAnalyzer和Lucene自带的分析器方法一样,将Analyzer测试代码改为IKAnalyzer测试中文分词效果。
如果使用中文分词器ik-analyzer,就在索引和搜索程序中使用一致的分词器ik-analyzer。
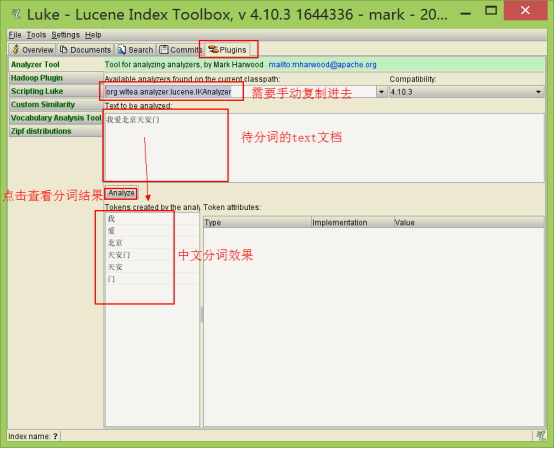
1. 使用luke测试IK中文分词
(1)打开Luke,不要指定Lucene目录。否则看不到效果
(2)在分词器栏,手动输入IkAnalyzer的全路径org.wltea.analyzer.lucene.IKAnalyzer
2. 改造代码,使用IkAnalyzer做分词器
添加jar包
修改分词器代码
|
// 创建中文分词器 Analyzer analyzer = new IKAnalyzer(); |
扩展中文词库
拓展词库的作用:在分词的过程中,保留定义的这些词
①在src或其他source目录下建立自己的拓展词库,mydict.dic文件,里面写入自定义的词
②在src或其他source目录下建立自己的停用词库,ext_stopword.dic文件停用词的作用:在分词的过程中,分词器会忽略这些词。
③在src或其他source目录下建立IKAnalyzer.cfg.xml,内容如下(注意路径对应):
|
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer 扩展配置</comment> <!-- 用户可以在这里配置自己的扩展字典 --> <entry key="ext_dict">mydict.dic</entry> <!-- 用户可以在这里配置自己的扩展停用词字典 --> <entry key="ext_stopwords">ext_stopword.dic</entry> </properties>
|
如果想配置扩展词和停用词,就创建扩展词的文件和停用词的文件,文件的编码要是utf-8。
注意:不要用记事本保存扩展词文件和停用词文件,那样的话,格式中是含有bom的。
