JVM突击-基础篇
把自己理解的JVM知识点进行整理,方便回顾.
1. JVM 运行时区域有哪些,作用分别是什么
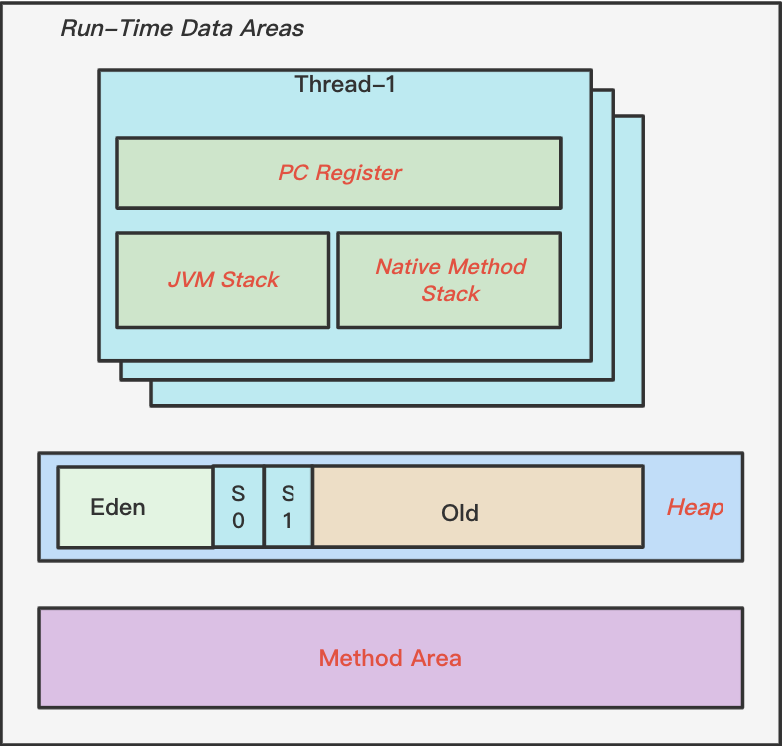
JVM运行时区域分为五个部分,分别为:方法区(Method Area)、堆(Heap)、程序计数器(Program Counter Register)、Java虚拟机栈(JVM Stack)、本地方法栈(Native Method Stack)。
其中方法区和堆是所有线程共享的,而程序计数器、Java虚拟机栈、和本地方法栈是线程私有的。
1.1 方法区存的是什么
方法区是线程共享区域,它存储已加载的Class类信息,比如字符串常量、字段、方法数据和JIT编辑后的代码。
1.2 为什么字符串常量池要由方法区移到堆中
运行时常量池保存一堆的符号引用和常量。
字符串常量池在JDK1.7由方法区移到了堆中,因为方法区可能会由于大量的字符串常量导致方法区被占满,从而导致FullGC.
1.3 JDK1.8之后为什么用元空间来作为方法区的实现
方法区在JDK1.7之前的版本中,用永久带(Perm)来实现, JDK1.8之后用元空间(MetaSpace)来实现。因为方法区的大小不好评估,评估的大了浪费空间,因为当JVM启动时永久带就会占用你设置好的内存大小,尽管你没用到那么多。评估的小了容易造成方法区OOM。 所以1.8以后采用元空间来实现,元空间用的是本地内存,它的大小受限于你整个机器的内存,不过JVM提供了参数 (-XX:MaxMetaspaceSize) 来控制最大可使用的内存空间大小,防止异常情况下耗尽机器内存。
1.4 JIT是什么
Just-in-Time Compiler 即时编译,对于热点代码,JVM会把热点代码的字节码编译成机器码放到方法区,下次执行时直接执行对应的机器码来提高执行效率。 默认执行10000次后,JVM会对它进行JIT优化。如果没有开启JIT编译优化的话,执行代码时则需要先把字节码转换成机器码交由系统去执行。 为什么不把所有代码全直接编译称机器码,一是因为你项目中的代码并不全是热点代码,二是编译后的机器码存在方法区也会占用方法区的内存。
1.5 程序计数器的作用
线程私有, 记录当前线程执行到哪儿了,如果执行的是本地方法,则为空。比如在发生线程上下文切换时,记录切换时线程执行的指令位置。
2. 堆为什么要进行分代设计
2.1 堆分代设计
由于大部分对象的存活时间比较短,方法执行完就不用了,只有少量对象的存活时间比较长。根据这种特性,把堆进行划分为年轻代、老年代。
老年代和年轻代的默认大小比例为2:1,同时老年代作为年轻代的一个担保,年轻代放不下的对象可以转移到老年代中。由于没有区域为老年代做担保,为了防止新生代存活对象过早进入老年代,JVM在新生代又划分出Eden区和2个Survivor区(S0和S1),当新生代发生YoungGC时把Eden区存活对象复制到S0区,等下次再进行YoungGC时把Eden区和S0存活的对象复制到S1区,然后重复整个过程。 对象有一个age属性,对象每经过一次GC,它的age就会加一,当存活对象的age到达15次时,这些存活对象会被转移到老年代。
2.2 对象的创建过程是怎样的
创建对象时大体上分这么几个步骤:类加载、为对象分配内存、对象的初始化。
下面分析各个步骤:
2.2.1 类加载
如果类没有加载过,先执行类加载,类加载过程分为7个步骤:加载、验证、准备、解析、初始化、使用、卸载。
2.2.2.1 请说一下类加载的过程
首先把Class字节码文件从磁盘加载进内存,同时验证字节码文件是否符合JVM规范,并生成对应的Class对象。
准备是给类的静态变量分配内存空间并赋默认值,
解析是把符号引用转换为直接引用, 因为在字节码文件中,字段,方法,类都是用符号表示的,需要把符号转换为对应字段、方法、类在内存中的直接引用。
初始化指的是静态变量赋值,或者执行代码块语句
2.2.2.2 双亲委派机制是什么意思?
在类加载过程中会有双亲委派机制,当要加载一个类时,当前类加载器不会自己去加载,而是交由父类加载器去加载,父类加载器重复这个过程,最终会委托到BootstrapClassLoader,如果父类加载器加载到了就用加载到的这个Class,如果父类加载器说它找不到要加载的类,子类加载器再尝试加载,如果都加载不到则报ClassNotFoundException.这么做的目的是防止类被重复加载、保证Java核心类由默认加载器去加载,不然随便写一个Object类在里面搞点儿事情会导致JVM不安全。
2.2.2.3 可以破坏双亲委派机制吗,能举例说一下吗
可以破坏双亲委派模型,JDK的SPI、tomcat的类加载、热部署等场景破坏双亲委派。
- Java的 SPI
SPI全称是 Service Provider Interface, 可以根据一个接口,去加载它对应的实现类。SPI去加载某个类时直接指定了由哪个类加载去加载,这个地方破坏了双亲委派模型。SPI默认用的类加载器是当前线程上下文类加载(Thread.currentThread().getContextClassLoader()), 默认是sun.misc.Launcher.AppClassLoader,你可以可以通过Thread.currentThread().setContextClassLoader(classLoader);手动设置线程上线文类加载器.
SPI加载类时默认用的是当前线程上线文类加载器源码:
public static <S> ServiceLoader<S> load(Class<S> service) {
ClassLoader cl = Thread.currentThread().getContextClassLoader();
return ServiceLoader.load(service, cl);
}
注意: 当 ClassLoader loader = Thread.currentThread().getContextClassLoader(),当loader去加载类时,还是走的loadClass的方法,它是满足双亲委派模型的,只不过SPI上来就指定了classloader,少了向父类去委托的过程。另外由于我们可以自己设置classloader所以自定义classloader如果重写了loadClass方法不往上委托,则肯定就破坏了双亲委派。
JDK中用到SPI的地方
-
JDK中的Driver接口,它提供了操作数据库的规范,但是不同的数据库内部操作逻辑不一样,JDK不可能把所有数据库的逻辑全实现一遍。可以由不同厂商自己实现自己的数据库操作逻辑,数据库实现类我们一般是通过引入三方Jar包放到classpath上,通过SPI机制动态获取实现类。
-
Tomcat
每个webapp有自己的ClassLoader,每个webapp下面的类由当前webapp对应的ClassLoader去加载,以实现每个webapp加载不同版本的Class;对于Java核心类交由父类加载器加载,保证核心类的安全。 -
热部署
热部署的话当收到类加载请求时,不往父类去委托。
2.2.3 对象分配内存
经过了上一步的类加载后,下面就需要为对象申请内存空间,默认在Eden区分配,但是要考虑不同线程进行内存分配时的线程安全问题。JVM通过TLAB(线程本地分配缓冲区)来避免多线程内存资源竞争问题,每个线程在创建的时候会在堆中给它分配一小块内存区域,线程私有。 每个线程需要申请内存时先从自己的TLAB上去分配,如果TLAB空间不够了,再通过CAS的方式申请共享区域的内存。
根据内存的规整情况,内存分配有2种分配方式:指针碰撞、空闲列表
-
指针碰撞
适用于内存空间是连续的情况,用一个指针指示下次从哪儿开始分配内存,分配时直接把指针往后移动即可。 -
空闲列表
适用于内存空间不连续,有内存碎片的情况,系统记录了哪部分的空间是可用的,分配时从可用空间找一个即可。
内存是否规整取决于使用那种垃圾回收算法,复制算法和标记整理算法内存空间是连续的,标记清除算法内存空间是不连续的
2.2.3.1 了解逃逸分析吗(标量替换、栈上分配)
逃逸分析指分析对象的作用域有没有逃逸出当前方法,比如我创建了一个类,它作为其他方法的入参或者方法返回值,那就表示对象逃逸出去了。如果没有对象逃逸的话JVM可能会对这个对象进行一些优化,比如同步消除,标量替换和栈上分配。
同步消除:如果对象有同步方法,但是它又不会被其他线程访问,那就可以进行锁消除
标量替换:如果对象的属性都是一些基础类型,则JVM不会在堆中创建该对象,直接在栈上创建若干变量来替代对象。 当方法执行完时,栈上的变量随着销毁。 优点是减轻JVM GC的压力,缺点是分析对象的逃逸分析可能耗费性能。
栈上分配:JVM使用标量替换来实现栈上分配对象。
2.2.3.2 新创建的对象一定在Eden区吗
不一定,比如大对象可能直接分配到老年代,大对象指的是需要大量连续内存空间的对象。JVM有个参数-XX:PreTureneSize=1m可以设置多大的对象直接分配到老年代,要避免少创建大对象,减少老年代的内存占用,减轻老年代GC的频率。
2.2.3.3 哪些情况下对象会进入老年代
- 上面说的大对象的情况
- Eden区可用空间放不下了
- Survivor区相同年龄对象的大小总和中超过Survivor区空间一半大小的,大于该年龄的对象直接进入老年代
2.2.4 对象初始化
分配完内存后,对象的各字段值都是默认值, 通过构造器、静态代码块等执行对象的初始化。
2.2.5 把引用指向内存地址
对象初始化完后,把对象的地址赋值给引用变量。
访问内存对象的方式一般有2种:句柄池、引用
-
句柄池
栈中的引用变量指向一个堆中的句柄池中,句柄池中再引用内存中的对象。
优点是当内存中的对象内存地址发生变化时,线程栈中的引用变量的指向值不需要变化,只需要更新句柄池中的地址。
缺点是定位对象的性能低,要经过句柄池的转换。 -
直接引用
栈中的引用变量直接指向对象的内存地址。JVM默认采用直接引用的方式
优点是定位对象的性能高。
缺点是当对象内存地址发生变化时,需要更新线程栈中引用变量的指向。
3. Java虚拟机栈 JVM Stack 里面存的是什么
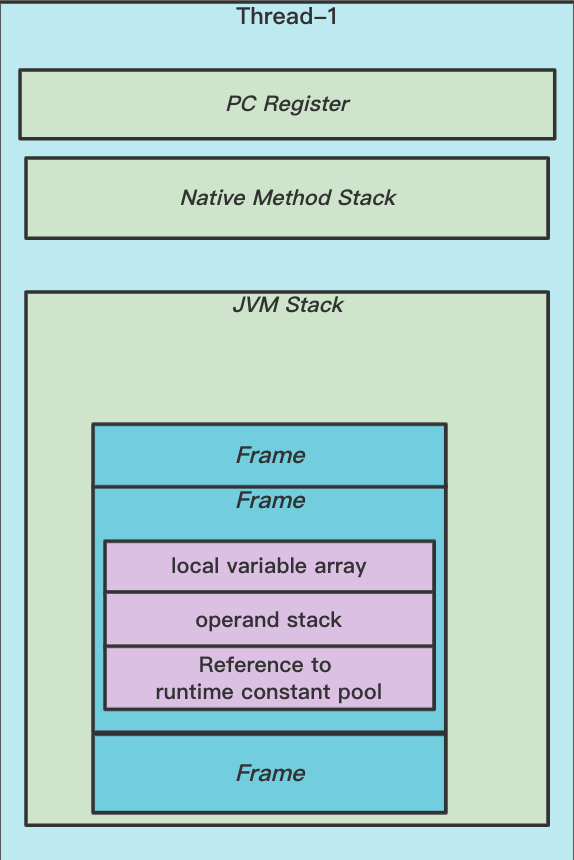
线程私有,JVM Stack的生命周期和线程相同。当线程被创建时会创建对应的JVM Stack,当线程被销毁时它也随着销毁。JVM Stack里面存放着一个一个的栈帧(Frame), 当调用一个方法时就会创建一个栈帧,并把栈帧压入Stack,当方法执行完成后从虚拟机栈弹出当前栈帧。
3.1 栈帧 Frame
栈帧里面存放局部变量表、操作数栈、指向运行时常量池中当前方法的引用。
-
局部变量表
存放方法入参、局部变量、方法返回地址等信息 -
操作数栈
利用操作数栈的压栈和出栈来操作我们的变量,比如变量计算 -
指向运行时常量池中当前方法的引用
用来支持当前方法动态链接
3.2 动态链接是什么
动态链接的作用是把要调用的符号方法引用转换成具体的方法引用。当我一个方法中要调用其他类的方法时,或者进行多态调用时,需要对应的方法符号引用转换成直接引用。因为当JVM启动时并不会把所有Class文件全加载进内存,可以理解为是按需加载。
持续更新~~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号