1.机器学习介绍
机器学习简介
机器学习技术不断进步,应用广泛,例如,推荐引擎,定向广告,需求预测,垃圾邮件过滤,医学诊断,自然语言处理,搜索引擎,欺诈检测,证券分析,视觉识别,语音识别,手写识别等
机器学习架构
机器学习是指通过算法,使用历史数据进行训练,训练完成后会产生模型,未来有新的数据提供时,我们可以使用训练产生的模型进行预测。
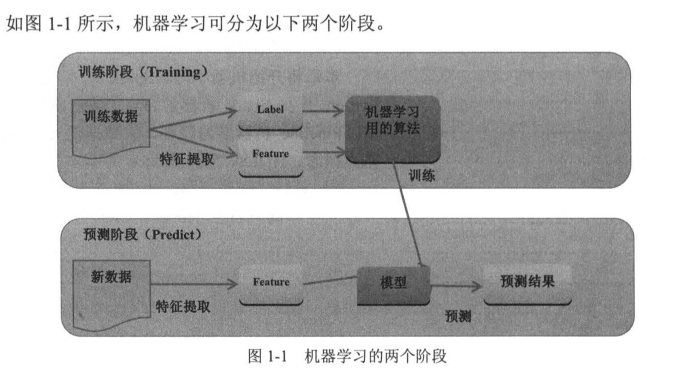
· 训练阶段数据组成 : Feature 、Label
训练数据是过去积累的历史数据,可能是文本文件,数据库或其他来源,经过Feature Extraction 特征提取,产生Feature和Label,然后经过机器学习算法的训练后产生模型。
Feature:数据特征,
Label: 数据的标签,也是我们希望预测的目标答案
· 预测阶段:
新输入数据,经过Feature Extraction特征提取 产生Feature,使用训练完成的模型进行预测,最后产生预测结果。
机器学习分类
机器学习分类分为 有监督的学习和无监督的学习两大类。

机器学习分类图

机器学习程序运行流程图

数据准备阶段
原始数据经过数据转换,提取特征字段与标签字段,产生机器学习所需要的格式,然后将数据以随机方式分为3部分(trainData,validationData, testData)并返回数据,提供给下一阶段训练评估使用
trainData: 用于训练,通过机器学习算法产生模型。
validationData: 用于对模型进行准确率的验证,进行反复多次的验证,从而产生bestmodel。
testData :用于对最佳模型bestmodel进行再次测试。
训练评估阶段
使用traindata数据进行训练并产生模型,然后使用validationdata 验证模型的准确率。这个过程要重复很多次才能找出最佳的参数组合,评估方式:二元分类使用AUC , 多元分类使用accuracy , 回归分析使用RMSE,训练评估完成后, 会产生最佳模型 bestModel
测试阶段
之前阶段产生了最佳模型bestmodel 我们会使用另外一组数据testdata再次测试,以避免 overfitting 问题,如果训练评估阶段准确度很高,但是测试阶段准确度很低,代表可能存在 overfitting 问题,如果测试与训练评估阶段的结果准确度差异不大,代表无 overfitting 问题
预测阶段
新输入数据,经过Feature Extraction 特征提取 产生 Feature,使用训练完成的最佳模型bestmodel 进行预测, 最后产生预测结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号