
hadoop3.1.3分布式安装
1. 准备3台客户机(关闭防火墙、静态IP、主机名称)
2. 安装JDK
3. 安装Hadoop
4. 配置集群分发脚本
5. 配置ssh
6. 集群启动并测试集群
7. 集群启动/停止
8. 配置lzo压缩
==========================================================
集群部署规划
注意:NameNode和SecondaryNameNode不要安装在同一台服务器
注意:ResourceManager也很消耗内存,不要和NameNode、SecondaryNameNode配置在同一台机器上。
| hadoop50 | hadoop51 | hadoop52 | |
|---|---|---|---|
| HDFS | NameNode DataNode |
DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager |
NodeManager |
1.准备虚拟机
1.1 安装工具
yum install -y epel-release
yum install -y net-tools vim
1.2 关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
1.3 创建yzfs用户,并修改yzfs用户密码
useradd yzfs
passwd yzfs
1.4 配置yzfs用户具有root权限放i博纳后期加sudo执行root权限命令
~]# vim /etc/sudoers
#修改/etc/sudoers文件,在%wheel这行下面添加一行,如下所示:
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
## Allows people in group wheel to run all commands
%wheel ALL=(ALL) ALL
yzfs ALL=(ALL) NOPASSWD:ALL
1.5 创建目录,并修改属主属组
1.5.1 在/opt目录下创建module、software文件夹
~]# mkdir /opt/module
~]# mkdir /opt/software
1.5.2 修改module、software文件夹的所有者和所属组均为atguigu用户
~]# chown yzfs.yzfs /opt/module
~]# chown yzfs.yzfs /opt/software
1.5.3 查看module、software文件夹的所有者和所属组
~]# cd /opt/
opt]# ll
drwxr-xr-x. 2 yzfs yzfs 4096 5月 28 17:18 module
drwxr-xr-x. 2 yzfs yzfs 4096 5月 28 17:18 software
2. 安装JDK
2.1 卸载虚拟机自带的JDK
注意:如果你的虚拟机是最小化安装不需要执行这一步。
~]# rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps
rpm -qa:查询所安装的所有rpm软件包
grep -i:忽略大小写
xargs -n1:表示每次只传递一个参数
rpm -e –nodeps:强制卸载软件
2.2 安装JDK
2.2.1 解压JDK
~]$ cd /opt/software/
software]$ tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/
2.2.2 配置JDK环境变量
~]$ cat /etc/profile.d/my_env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
~]$ source /etc/profile
~]$ java -version
java version "1.8.0_212"
Java(TM) SE Runtime Environment (build 1.8.0_212-b10)
Java HotSpot(TM) 64-Bit Server VM (build 25.212-b10, mixed mode)
基于这个虚拟机克隆三台虚拟机
3. 安装Hadoop
3.1 安装Hadoop
3.1.1 进入到Hadoop安装包路径下
~]$ cd /opt/software/
3.1.2 解压安装文件到/opt/module下面
software]$ tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
3.1.3 查看是否解压成功
software]$ ls /opt/module/
hadoop-3.1.3
3.2 配置hadoop环境变量
3.2.1.获取Hadoop安装路径
hadoop-3.1.3]$ pwd
/opt/module/hadoop-3.1.3
3.2.2.打开/etc/profile.d/my_env.sh文件
hadoop-3.1.3]$ sudo vim /etc/profile.d/my_env.sh
#在my_env.sh文件末尾添加如下内容:(shift+g)
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
hadoop-3.1.3]$ source /etc/profile
3.2.3 测试是否安装成功
~]$ hadoop version
Hadoop 3.1.3
3.3 hadoop目录结构
3.3.1 查看hadoop目录结构
hadoop-3.1.3]$ ll |grep '^d'
drwxr-xr-x 2 ovo ovo 183 Sep 12 2019 bin
drwxrwxr-x 4 ovo ovo 37 Mar 14 21:24 data
drwxr-xr-x 3 ovo ovo 20 Sep 12 2019 etc
drwxr-xr-x 2 ovo ovo 106 Sep 12 2019 include
drwxr-xr-x 3 ovo ovo 20 Sep 12 2019 lib
drwxr-xr-x 4 ovo ovo 288 Sep 12 2019 libexec
drwxrwxr-x 3 ovo ovo 4096 Mar 15 13:55 logs
drwxr-xr-x 3 ovo ovo 4096 Sep 12 2019 sbin
drwxr-xr-x 4 ovo ovo 31 Sep 12 2019 share
drwxrwxr-x 2 ovo ovo 22 Mar 15 10:04 wcinput
3.3.2 重要目录
- bin目录:存放对Hadoop相关服务(hdfs,yarn,mapred)进行操作的脚本
- etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件
- lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能)
- sbin目录:存放启动或停止Hadoop相关服务的脚本
- share目录:存放Hadoop的依赖jar包、文档、和官方案例
4.配置集群
4.1配置集群分发脚本
opt]$ cd /home/ovo
~]$ mkdir bin
~]$ cd bin
配置脚本
bin]$ vim xsync
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in hadoop50 hadoop51 hadoop52
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
修改脚本 xsync 具有执行权限
bin]$ chmod +x xsync
分发脚本
~]$ sudo xsync /home/ovo/bin
配置环境变量
hadoop-3.1.3]$ cat /etc/profile.d/my_env.sh
export PATH=$PATH:/home/ovo/bin
分发环境变量
~]$ sudo ./bin/xsync /etc/profile.d/my_env.sh
bin]$ source /etc/profile
5. 配置ssh
5.1 生成密钥(所有节点都执行)
.ssh]$ ssh-keygen -t rsa
5.2 把公钥拷到免密登录的目标服务器上
.ssh]$ ssh-copy-id hadoop50
.ssh]$ ssh-copy-id hadoop51
.ssh]$ ssh-copy-id hadoop52
ps:
- 还需要在hadoop51上采用yzfs账号配置一下无密登录到hadoop50、hadoop51、hadoop52服务器上。
- 还需要在hadoop52上采用yzfs账号配置一下无密登录到hadoop50、hadoop51、hadoop52服务器上。
- 还需要在hadoop50上采用root账号,配置一下无密登录到hadoop50、hadoop51、hadoop52;
6.启动集群并测试集群
6.1 集群部署规划
注意:
- NameNode和SecondaryNameNode不要安装在同一台服务器
- ResourceManager也很消耗内存,不要和NameNode、SecondaryNameNode配置在同一台机器上。
| hadoop50 | hadoop51 | hadoop52 | |
|---|---|---|---|
| HDFS | NameNode DataNode |
DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager |
NodeManager |
6.2 配置文件说明
Hadoop配置文件分两类:默认配置文件和自定义配置文件,只有用户想修改某一默认配置值时,才需要修改自定义配置文件,更改相应属性值。
(1)默认配置文件:
| 要获取的默认文件 | 文件存放在Hadoop的jar包中的位置 |
|---|---|
| [core-default.xml] | hadoop-common-3.1.3.jar/core-default.xml |
| [hdfs-default.xml] | hadoop-hdfs-3.1.3.jar/hdfs-default.xml |
| [yarn-default.xml] | hadoop-yarn-common-3.1.3.jar/yarn-default.xml |
| [mapred-default.xml] | hadoop-mapreduce-client-core-3.1.3.jar/mapred-default.xml |
(2)自定义配置文件:
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml四个配置文件存放在$HADOOP_HOME/etc/hadoop这个路径上,用户可以根据项目需求重新进行修改配置。
6.3 配置集群
(1)核心配置文件
配置core-site.xml
~]$ cd $HADOOP_HOME/etc/hadoop
hadoop]$ vim core-site.xml
文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop50:8020</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户为yzfs -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>yzfs</value>
</property>
</configuration>
(2)HDFS配置文件
配置hdfs-site.xml
hadoop]$ vim hdfs-site.xml
文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop50:9870</value>
</property>
<!-- 2nn web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop52:9868</value>
</property>
</configuration>
(3)YARN配置文件
配置yarn-site.xml
hadoop]$ vim yarn-site.xml
文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop51</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!-- yarn容器允许分配的最大最小内存 -->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property>
<!-- yarn容器允许管理的物理内存大小 -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>
<!-- 关闭yarn对虚拟内存的限制检查 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
(4)MapReduce配置文件
配置mapred-site.xml
hadoop]$ vim mapred-site.xml
文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
(5)分发配置好的hadoop配置文件
@hadoop50 hadoop]$ xsync /opt/module/hadoop-3.1.3/etc/hadoop/
@hadoop51 ~]$ cat /opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml
@hadoop52 ~]$ cat /opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml
(6)配置workers
hadoop]$ vim /opt/module/hadoop-3.1.3/etc/hadoop/workers
在该文件中增加如下内容:
hadoop50
hadoop51
hadoop52
注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
同步所有节点配置文件
@hadoop50 hadoop]$ xsync /opt/module/hadoop-3.1.3/etc
6.4 启动集群
(1)如果集群是第一次启动,需要在hadoop50节点格式化NameNode(注意:格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。如果集群在运行过程中报错,需要重新格式化NameNode的话,一定要先停止namenode和datanode进程,并且要删除所有机器的data和logs目录,然后再进行格式化。)
[atguigu@hadoop50 hadoop-3.1.3]$ hdfs namenode -format
(2)启动HDFS
hadoop-3.1.3]$ sbin/start-dfs.sh
(3)在配置了ResourceManager的节点(hadoop51)启动YARN
hadoop-3.1.3]$ sbin/start-yarn.sh
(4)Web端查看HDFS的NameNode
(a)浏览器中输入:http://hadoop50:9870
(b)查看HDFS上存储的数据信息
(5)Web端查看YARN的ResourceManager
(a)浏览器中输入:http://hadoop51:8088
(b)查看YARN上运行的Job信息
6.5 集群基本测试
(1)上传文件到集群
上传小文件
~]$ hadoop fs -mkdir /input
~]$ hadoop fs -put $HADOOP_HOME/wcinput/word.txt /input
上传大文件
~]$ hadoop fs -put /opt/software/jdk-8u212-linux-x64.tar.gz /
(2)上传文件后查看文件存放在什么位置
- 查看HDFS文件存储路径
subdir0]$ pwd
/opt/module/hadoop-3.1.3/data/dfs/data/current/BP-1436128598-192.168.1.50-1610603650062/current/finalized/subdir0/subdir0
- 查看HDFS在磁盘存储文件内容
subdir0]$ cat blk_1073741825
hadoop yarn
hadoop mapreduce
atguigu
atguigu
(3)拼接
-rw-rw-r--. 1 yzfs yzfs 134217728 5月 23 16:01 blk_1073741836
-rw-rw-r--. 1 yzfs yzfs 1048583 5月 23 16:01 blk_1073741836_1012.meta
-rw-rw-r--. 1 yzfs yzfs 63439959 5月 23 16:01 blk_1073741837
-rw-rw-r--. 1 yzfs yzfs 495635 5月 23 16:01 blk_1073741837_1013.meta
subdir0]$ cat blk_1073741836>>tmp.tar.gz
subdir0]$ cat blk_1073741837>>tmp.tar.gz
subdir0]$ tar -zxvf tmp.tar.gz
(4)下载
software]$ hadoop fs -get /jdk-8u212-linux-x64.tar.gz ./
(5)执行wordcount程序
hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output
6.6 配置历史服务器
为了查看程序的历史运行情况,需要配置一下历史服务器。具体配置步骤如下:
(1)配置mapred-site.xml
hadoop]$ vim mapred-site.xml
#在该文件里面增加如下配置。
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop50:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop50:19888</value>
</property>
(2)分发配置
hadoop]$ xsync $HADOOP_HOME/etc/hadoop/mapred-site.xml
(3)在hadoop50启动历史服务器
hadoop]$ mapred --daemon start historyserver
(4)查看历史服务器是否启动
hadoop]$ jps
(5)查看JobHistory
http://hadoop50:19888/jobhistory
6.7 配置日志聚集
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到HDFS系统上。
日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。
注意:开启日志聚集功能,需要重新启动NodeManager 、ResourceManager和HistoryServer。
开启日志聚集功能具体步骤如下:
1)配置yarn-site.xml
hadoop]$ vim yarn-site.xml
在该文件里面增加如下配置。
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop50:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
(2)分发配置
hadoop]$ xsync $HADOOP_HOME/etc/hadoop/yarn-site.xml
(3)关闭NodeManager 、ResourceManager和HistoryServer
@hadoop51 hadoop-3.1.3]$ sbin/stop-yarn.sh
@hadoop50 hadoop-3.1.3]$ mapred --daemon stop historyserver
(4)启动NodeManager 、ResourceManage和HistoryServer
@hadoop51 ~]$ start-yarn.sh
@hadoop50 ~]$ mapred --daemon start historyserver
(5)删除HDFS上已经存在的输出文件
@hadoop50 ~]$ hadoop fs -rm -r /output
(6)执行WordCount程序
@hadoop50 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output
(7)查看日志
历史服务器地址
http://hadoop50:19888/jobhistory
历史任务列表
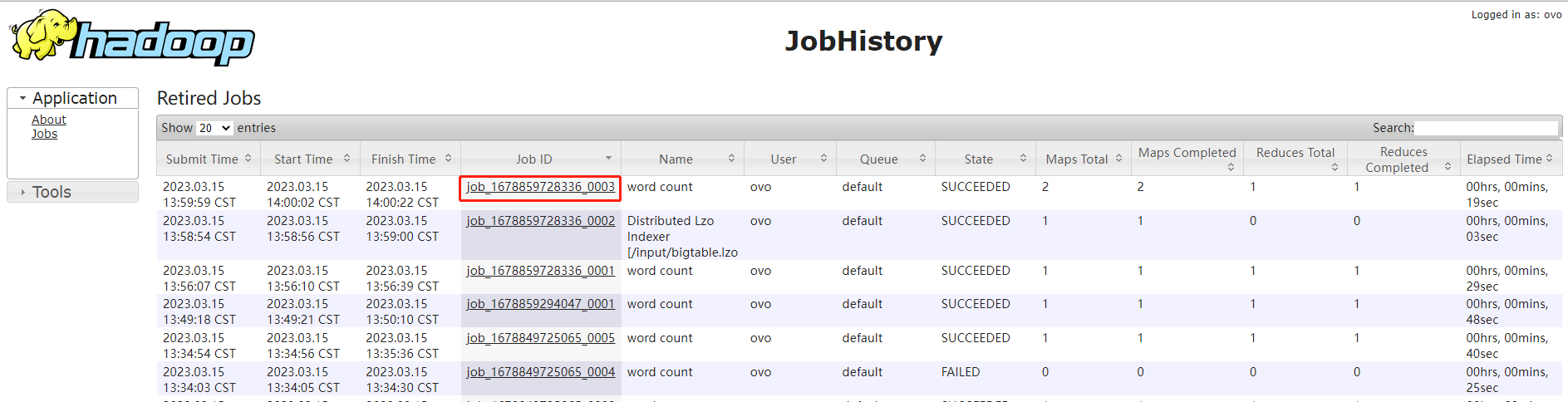
查看任务运行日志
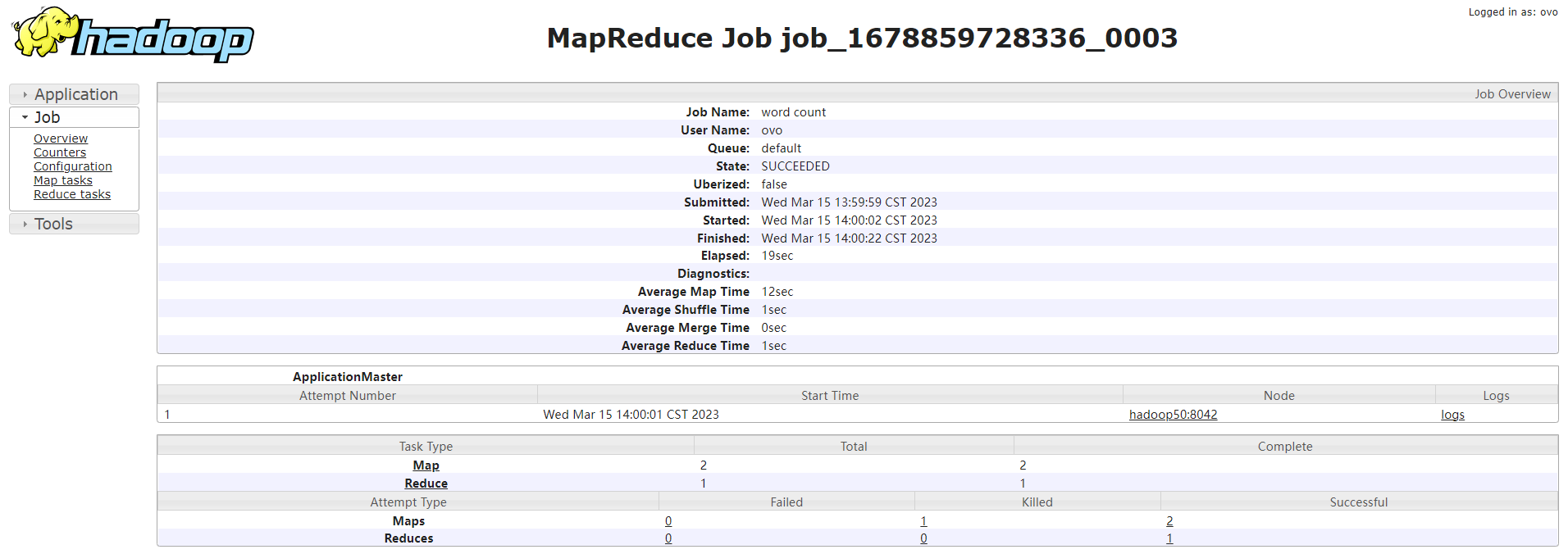
运行日志详情

7. 集群启动/停止
(1)各个模块分开启动/停止(配置ssh是前提)常用
- 整体启动/停止HDFS
start-dfs.sh/stop-dfs.sh
- 整体启动/停止YARN
start-yarn.sh/stop-yarn.sh
(2)各个服务组件逐一启动/停止
- 分别启动/停止HDFS组件
hdfs --daemon start/stop namenode/datanode/secondarynamenode
- 启动/停止YARN
yarn --daemon start/stop resourcemanager/nodemanager
(3)编写hadoop集群常用脚本
1)Hadoop集群启停脚本(包含HDFS,Yarn,Historyserver):myhadoop.sh
~]$ cd /home/atguigu/bin
bin]$ vim myhadoop.sh
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动 hadoop集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh hadoop50 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh hadoop51 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh hadoop50 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== 关闭 hadoop集群 ==================="
echo " --------------- 关闭 historyserver ---------------"
ssh hadoop50 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver"
echo " --------------- 关闭 yarn ---------------"
ssh hadoop51 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh hadoop50 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac
保存后退出,然后赋予脚本执行权限
bin]$ chmod +x myhadoop.sh
bin]$ xsync myhadoop.sh
(2)查看三台服务器Java进程脚本:jpsall
~]$ cd /home/atguigu/bin
bin]$ vim jpsall
#!/bin/bash
for host in hadoop50 hadoop51 hadoop52
do
echo =============== $host ===============
ssh $host jps
done
保存后退出,然后赋予脚本执行权限
bin]$ chmod +x jpsall
bin]$ xsync jpsall
8. 配置lzo压缩
8.1 hadoop-lzo编译
hadoop本身并不支持lzo压缩,故需要使用twitter提供的hadoop-lzo开源组件。hadoop-lzo需依赖hadoop和lzo进行编译,编译步骤如下。
(1)环境准备
maven(下载安装,配置环境变量,修改sitting.xml加阿里云镜像)
gcc-c++
zlib-devel
autoconf
automake
libtool
通过yum安装即可
yum -y install gcc-c++ lzo-devel zlib-devel autoconf automake libtool
yum -y install java-1.8.0-openjdk maven
(2) 下载、安装并编译LZO
wget http://www.oberhumer.com/opensource/lzo/download/lzo-2.10.tar.gz
tar -zxvf lzo-2.10.tar.gz
cd lzo-2.10
./configure -prefix=/usr/local/hadoop/lzo/
make
make install
(3) 编译hadoop-lzo源码
下载hadoop-lzo的源码,下载地址:
https://github.com/twitter/hadoop-lzo/archive/master.zip
解压之后,修改pom.xml
<hadoop.current.version>3.1.3</hadoop.current.version>
声明两个临时环境变量
export C_INCLUDE_PATH=/usr/local/hadoop/lzo/include
export LIBRARY_PATH=/usr/local/hadoop/lzo/lib
编译
进入hadoop-lzo-master,执行maven编译命令
mvn package -Dmaven.test.skip=true
进入target,hadoop-lzo-0.4.21-SNAPSHOT.jar 即编译成功的hadoop-lzo组件
8.2 hadoop集成lzo
(1)将编译好后的hadoop-lzo-0.4.20.jar 放入hadoop-3.1.3/share/hadoop/common/
common]$ pwd
/opt/module/hadoop-3.1.3/share/hadoop/common
common]$ ls
hadoop-lzo-0.4.20.jar
(2)同步hadoop-lzo-0.4.20.jar到hadoop51、hadoop52
common]$ xsync hadoop-lzo-0.4.20.jar
(3)core-site.xml增加配置支持lzo压缩
<configuration>
<property>
<name>io.compression.codecs</name>
<value>
org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.DefaultCodec,
org.apache.hadoop.io.compress.BZip2Codec,
org.apache.hadoop.io.compress.SnappyCodec,
com.hadoop.compression.lzo.LzoCodec,
com.hadoop.compression.lzo.LzopCodec
</value>
</property>
<property>
<name>io.compression.codec.lzo.class</name>
<value>com.hadoop.compression.lzo.LzoCodec</value>
</property>
</configuration>
(4)同步core-site.xml到hadoop51、hadoop52
hadoop]$ xsync core-site.xml
(5)启动及查看集群
@hadoop50 hadoop-3.1.3]$ sbin/start-dfs.sh
@hadoop51 hadoop-3.1.3]$ sbin/start-yarn.sh
(6)测试-数据准备
@hadoop50 hadoop-3.1.3]$ hadoop fs -mkdir /input
@hadoop50 hadoop-3.1.3]$ hadoop fs -put README.txt /input
(7)测试压缩
@hadoop50 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount -Dmapreduce.output.fileoutputformat.compress=true -Dmapreduce.output.fileoutputformat.compress.codec=com.hadoop.compression.lzo.LzopCodec /input /output
8.3 项目经验之LZO创建索引
1)创建LZO文件的索引
LZO压缩文件的可切片特性依赖于其索引,故我们需要手动为LZO压缩文件创建索引。若无索引,则LZO文件的切片只有一个。
hadoop jar /path/to/your/hadoop-lzo.jar com.hadoop.compression.lzo.DistributedLzoIndexer big_file.lzo
2)测试
(2.1)将bigtable.lzo(200M)上传到集群的根目录
@hadoop50 module]$ hadoop fs -mkdir /input
@hadoop50 module]$ hadoop fs -put bigtable.lzo /input
(2.2)执行wordcount程序
@hadoop50 module]$ hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount -Dmapreduce.job.inputformat.class=com.hadoop.mapreduce.LzoTextInputFormat /input /output1

(2.3)对上传的LZO文件建索引
@hadoop50 module]$ hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/common/hadoop-lzo-0.4.20.jar com.hadoop.compression.lzo.DistributedLzoIndexer /input/bigtable.lzo
(2.4)再次执行WordCount程序
@hadoop50 module]$ hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount -Dmapreduce.job.inputformat.class=com.hadoop.mapreduce.LzoTextInputFormat /input /output2
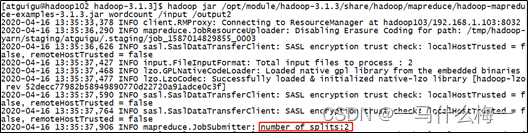
ps:如果以上任务,在运行过程中报如下异常
Container [pid=8468,containerID=container_1594198338753_0001_01_000002] is running 318740992B beyond the 'VIRTUAL' memory limit. Current usage: 111.5 MB of 1 GB physical memory used; 2.4 GB of 2.1 GB virtual memory used. Killing container.
Dump of the process-tree for container_1594198338753_0001_01_000002 :
解决办法:在hadoop50的/opt/module/hadoop-3.1.3/etc/hadoop/yarn-site.xml文件中增加
如下配置,然后分发到hadoop51、hadoop52服务器上,并重新启动集群。
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
参考文档:
https://blog.csdn.net/weixin_44616592/article/details/128020724
https://blog.csdn.net/yuan2019035055/article/details/120901926


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律
2021-03-16 iptables nat地址转换