1.Prometheus监控
1.运维的主要职责
2.监控的作用
3.Prometheus优点
4.监控的范围
5.Prometheus使用
6.Prometheus介绍
7.Prometheus数据介绍
1.运维的主要职责
主要职责是维护服务器,保证线上的产品稳定的运行!出现问题能及时的处理,保证用户数据的安全!
2.监控的作用
主要是为了保证服务器及代码稳定的运行,如服务器发生故障,及时的发送信息到运维手里,运维可以及时的进行处理!事后溯源找到问题发生的原因,进行优化,从而把问题发生的的几率降到最低!
主要流程:
数据采集 --> 数据存储 --> 设定阈值 --> 发送报警
3.Prometheus优点
- 监控数据的精细程度 绝对的第⼀ 可以精确到 1~5秒的采集精度 4 5分钟 理想的状态 我们来算算
采集精度 (存储 性能) - 集群部署的速度 监控脚本的制作 (指的是熟练之后) ⾮常快速 ⼤⼤缩短监控的搭建时间成本
- 周边插件很丰富 exporter pushgateway ⼤多数都不需要⾃⼰开发了
- 本⾝基于数学计算模型,⼤量的实⽤函数 可以实现很复杂规则的业务逻辑监控(例如QPS的曲线
弯曲 凸起 下跌的 ⽐例等等模糊概念) - 可以嵌⼊很多开源⼯具的内部 进⾏监控 数据更准时 更可信(其他监控很难做到这⼀点)
- 本⾝是开源的,更新速度快,bug修复快。⽀持N多种语⾔做本⾝和插件的⼆次开发
- 图形很⾼⼤上 很美观 ⽼板特别喜欢看这种业务图 (主要是指跟Grafana的结合)
4.监控的范围
1.服务器硬件进行监控(zabbix snmp协议)
2.操作系统进行监控(cpu繁忙程度 内存使用率 磁盘使用率及io 网络带宽)
3.中间件进行监控(nginx mysql java)
4.日志进行监控
Prometheus使用
Prometheus介绍
Prometheus是一个开源的系统监控和报警系统,现在已经加入到CNCF基金会,成为继k8s之后第二个在CNCF托管的项目,在kubernetes容器管理系统中,通常会搭配prometheus进行监控,同时也支持多种exporter采集数据,还支持pushgateway进行数据上报,Prometheus性能足够支撑上万台规模的集群。有以下几个特点:
1)多维度数据模型,每一个时间序列数据都由metric度量指标名称和它的标签labels键值对集合唯一确定:这个metric度量指标名称指定监控目标系统的测量特征(如:http_requests_total- 接收http请求的总计数)。labels开启了Prometheus的多维数据模型:对于相同的度量名称,通过不同标签列表的结合, 会形成特定的度量维度实例。(例如:所有包含度量名称为/api/tracks的http请求,打上method=POST的标签,则形成了具体的http请求)。这个查询语言在这些度量和标签列表的基础上进行过滤和聚合。改变任何度量上的任何标签值,则会形成新的时间序列图。
2)灵活的查询语言(PromQL):可以对采集的metrics指标进行加法,乘法,连接等操作;
3)可以直接在本地部署,不依赖其他分布式存储;
4)通过基于HTTP的pull方式采集时序数据;
5)可以通过中间网关pushgateway的方式把时间序列数据推送到prometheus server端;
6)可通过服务发现或者静态配置来发现目标服务对象(targets)。
7)有多种可视化图像界面,如Grafana等。
8)高效的存储,每个采样数据占3.5 bytes左右,300万的时间序列,30s间隔,保留60天,消耗磁盘大概200G。
9)做高可用,可以对数据做异地备份,联邦集群,部署多套prometheus,pushgateway上报数据
Prometheus架构
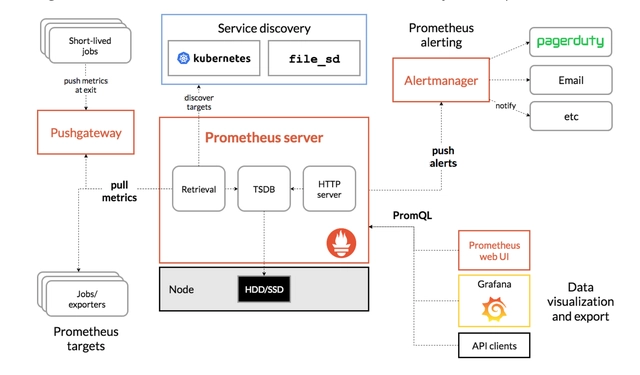
storage存储
- prometheus的本地tsdb数据库以每两个小时为间隔来分block块存储,每一个块中又分为多个chunk文件,chunk文件是用来存放采集过来的t-s
数据,metadate和索引文件(index) - index文件是对metrics(Prometheus中一次K/V数据采集,叫做一次metrics)数据和lables(标签)进行索引之后index存储到chunk文件中,chunk文件为主要文件,metadata和index数据为子集
- prometheus采用的是time-series(时间序列)的方式,把采集的数据存储到磁盘上
- prometheus采集到数据是先放在内存中,以类似缓存的方式加快处理和查找数据
- 当prometheus宕机时,它有一种保护机制叫做wal 可以定期的把数据存入到磁盘中,以chunk的方式进行存储。当重启后会重新加载到内存中
services discovery
服务的自动发现 ,会自动的发现监控target。
如果prometheus配合了例如consul这种服务发现软件。
prometheus的配置文件就需要手动定义target,能自动发现集群中有那些新机器以及新机器上有那些服务可以被自动的进行监控
pull采集数据
pull: 指的是主动拉去的方式来拉取数据,安装各类已有的exporters在系统上之后,exporter
以守护进程的方式运行,让服务端来拉取数据
exporter本身也是一个http server可以对http请求作出响应,返回数据!
prometheus 用pull的方式 去每个exporter节点采集数据!
push采集数据
指的是在客户端或者服务端安装这个官方提供的pushgateway插件,然后使用各种脚本,吧把监控数据组织成k/v的形式,metrics形式发送给pushgateway,pushgateway把数据发送给prometheus
alertmanager
Prometheus报警组件,Prometheus设定规则,设定阈值。当触发阈值时,会把信息推送到alertmanager,alertmanager根据设定的报警模板把报警推送到email,wxchat,钉钉!
Prometheus数据介绍
Prometheus数据接口metrics介绍
prometheus监控中,对于采集过来的数据,统一称为metrics数据
当需要为某一个系统或某个服务做监控,统计,就需要使用metrics
metrics是一种对采样数据的总称,一组key-values数据接口的总称
Prometheus数据类型介绍
主要有一下几种类型
Gauges 动态数据类型
简单的度量指标,只有一个简单的返回值,或者叫瞬时状态!
例如:监控内存或磁盘的使用量 用Gauges的metrics格式来度量
因为内存或磁盘的使用量是不断的变化,所以采用这个度量类型最合适!
counters 计数数据类型
counter就是计数器,从数据量0开始累计计算,在理想状态下,只能增长不会降低
例如:对用户访问量的数据采样,数值就是不断的增长不会发生降低
histograms近似百分比估算数值类型
histograms统计数据的分布情况。比如最小值,最大值,中间值,中位数,75百分不 90百分比
这是一种特殊的metrics数据类型,代表一种‘近似的百分比估算数值’
例如:http_response_time HTTP响应时间
代表的是一次用户http请求,在系统传输和执行过程中 总共花费的时间
nginx的日志也会记录这一项数据
做一个假设
如果我们想通过监控的方式,换区当天的nginx access—log,并且想监控用户的访问时间
常规做法 把日志中的http_responese_time求和 除以访问次数即可
如果今天的访问量是100万次 把所有的http_response_time加在一起,除以次数的到的值
0.05是=50ms
这个数据只是代表当时的一天的平局值 不能检测到某一时段的http_responese_time值
如果在1:00的时候,发生了一次线上个账,系统整体的访问变电非常缓慢,大部分的用户请求时间都达到了0.5-1s的访问时间,如何在1:00到1:05的时候实现报警呢?
所以这个时候histogram的metrics数据类型就派出用场了
通过histongram类型,可以分别统计出 全部用户的响应时间
<0.05s的访问量有多少
0.05s的访问量有多少
0.2s的访问量有多少
可以清晰的看到 当前的系统中访问量正常的用户百分比有多少 多少处于异常状态
Prometheus数据格式介绍
Prometheus 会将所有采集到的样本数据以时间序列的形式保存在内存数据库中,并定时刷新到硬盘上,时间序列是按照时间戳和值的序列方式存放的,我们可以称之为向量(vector),每一条时间序列都由一个指标名称和一组标签(键值对)来唯一标识。
指标名称反映了被监控样本的含义(如 http_request_total 表示的是对应服务器处理的 HTTP 请求总数)。
标签可以用来区分不同的维度(比如 method="GET" 与 method="POST" 就可以用来区分这两种不同的 HTTP 请求指标数据)。
如下所示,可以将时间序列理解为一个以时间为 Y 轴的数字矩阵:
^
│ . . . . . . . . . . . . . . . . . . . http_request_total{method="GET",status="200"}
│ . . . . . . . . . . . . . . . . . . . http_request_total{method="POST",status="500"}
│ . . . . . . . . . . . . . . . . . .
│ . . . . . . . . . . . . . . . . . .
v
<------------------ 时间 ---------------->
需要注意的是指标名称只能由 ASCII 字符、数字、下划线以及冒号组成,同时必须匹配正则表达式 [a-zA-Z_:][a-zA-Z0-9_:](冒号不能用来定义指标名称,是用来表示用户自定义的记录规则)。标签的名称只能由 ASCII 字符、数字以及下划线组成并满足正则表达式 [a-zA-Z_][a-zA-Z0-9_],其中以 __ 作为前缀的标签,是系统保留的关键字,只能在系统内部使用,标签的值则可以包含任何 Unicode 编码的字符。
样本
时间序列中的每一个点就称为一个样本(sample),样本由以下 3 个部分组成:
- 指标:指标名称和描述当前样本特征的标签集
- 时间戳:精确到毫秒的时间戳数
- 样本值:一个 64 位浮点数
指标
想要暴露 Prometheus 指标服务只需要暴露一个 HTTP 端点,并提供 Prometheus 基于文本格式的指标数据即可。这种指标格式是非常友好的,基本上的格式看起来类似于下面的这段代码:
# HELP http_requests_total The total number of processed HTTP requests.
# TYPE http_requests_total counter
http_requests_total{status="200"} 8556
http_requests_total{status="404"} 20
http_requests_total{status="500"} 68
其中 # 开头的行是注释信息,用来描述下面提供的指标含义,其他未注释行代表一个样本(带有指标名、标签和样本值),使其非常容易从系统和服务中暴露指标出来。
事实上所有的指标也都是通过如下所示的格式来标识的:
<metric name>{<label name>=<label value>, ...}
例如,指标名称是 http_request_total,标签集为 method="POST", endpoint="/messages",那么我们可以用下面的方式来标识这个指标:
http_request_total{method="POST", endpoint="/messages"}
而事实上 Prometheus 的底层实现中指标名称实际上是以 __name__=<metric name> 的形式保存在数据库中的,所以上面的指标也等同与下面的指标:
{__name__="http_request_total", method="POST", endpoint="/messages"}
所以也可以认为一个指标就是一个标签集,只是这个标签集里面一定包含一个 __name__ 的标签来定义这个指标的名称。
Prometheus安装
Prometheus二进制部署
安装Prometheus Server
Prometheus基于Golang编写,编译后的软件包,不依赖于任何的第三方依赖。用户只需要下载对应平台的二进制包,解压并且添加基本的配置即可正常启Prometheus Server。
8.1.1 下载并解压二进制安装包
通过prometheus的官网,我们下载的prometheus是在2019年的版本。
#下载、解压、创建软链接
wget https://github.com/prometheus/prometheus/releases/download/v2.13.0/prometheus-2.13.0.linux-amd64.tar.gz
tar -xf prometheus-2.13.0.linux-amd64.tar.gz
mv prometheus-2.13.0.linux-amd64 /usr/local/
ln -s /usr/local/prometheus-2.13.0.linux-amd64/ /usr/local/prometheus
8.1.2 配置说明
解压后当前目录会包含默认的Prometheus配置文件promethes.yml,下面配置文件做下简略的解析:
# 全局配置
global:
scrape_interval: 15s # 设置抓取间隔,默认为1分钟
evaluation_interval: 15s #估算规则的默认周期,每15秒计算一次规则。默认1分钟
# scrape_timeout #默认抓取超时,默认为10s
# Alertmanager相关配置
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# 规则文件列表,使用'evaluation_interval' 参数去抓取
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# 抓取配置列表
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
8.1.3 创建prometheus的用户及数据存储目录
为了安全,我们使用普通用户来启动prometheus服务。作为一个时序型的数据库产品,prometheus的数据默认会存放在应用所在目录下,我们需要修改为 /data/prometheus下。
useradd -s /sbin/nologin -M prometheus
mkdir /data/prometheus -p
#修改目录属主
chown -R prometheus:prometheus /usr/local/prometheus/
chown -R prometheus:prometheus /data/prometheus/
8.1.4 创建Systemd服务启动prometheus
prometheus的启动很简单,只需要直接启动解压目录的二进制文件prometheus即可,但是为了更加方便对prometheus进行管理,这里使用systemd来启停prometheus
vim /etc/systemd/system/prometheus.service
[Unit]
Description=Prometheus
Documentation=https://prometheus.io/
After=network.target
[Service]
Type=simple
User=prometheus
ExecStart=/usr/local/prometheus/prometheus --config.file=/usr/local/prometheus/prometheus.yml --storage.tsdb.path=/data/prometheus
Restart=on-failure
[Install]
WantedBy=multi-user.target
备注:在service文件里面,我们定义了启动的命令,定义了数据存储在/data/prometheus路径下,否则默认会在prometheus二进制的目录的data下。
启动服务
systemctl start prometheus
systemctl status prometheus
systemctl enable prometheus
Prometheus 启动参数
--config.file="prometheus.yml":启动时,指定Prometheus读取配置文件的路径。
--web.listen-address="0.0.0.0:9090" :指定网页打开Prometheus的ip和端口,默认为"0.0.0.0:9090"。
--web.read-timeout=5m:页面读取请求最大超时时间 。
--web.max-connections=512:同时访问Prometheus页面的最大连接数,默认为512。
--web.enable-lifecycle:通过HTTP请求启用关闭和重新加载。
--storage.tsdb.path="data/":存储的基本路径。
--storage.tsdb.retention=15d:存储采样的保存时间。
--query.timeout=2m: 一个查询在终止之前可以执行的最长时间(如果超过2min,就会自动kill掉)。
--query.max-concurrency=20:并发执行的最大查询数,默认为20。
--log.level=info: 开启打印日志级别(debug,info,warn,error,fatal)。默认为info。
--query.lookback-delta=10m
参数用法:
eg:
未设置参数 `--web.enable-lifecycle` 时,执行 `curl -X POST http://localhost:9090/-/reload` 会报错:
启动设置参数 `--web.enable-lifecycle` 就可以用命令 `curl -X POST http://localhost:9090/-/reload` 重新加载配置文件了。
docker部署Prometheus
8.2.1 准备配置文件
cat /opt/prometheus/prometheus.yml
global:
scrape_interval: 60s
evaluation_interval: 60s
scrape_timeout: 10s
scrape_configs:
- job_name: prometheus
static_configs:
- targets: ['localhost:9090']
labels:
instance: prometheus
relabel_configs:
- action: replace
source_labels: ['job']
regex: (.*)
replacement: $1
target_label: yzfs
8.2.2 运行容器
docker run -itd --name prometheus -p 9090:9090 \
-v /opt/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml \
-v /etc/localtime:/etc/localtime:ro \
prom/prometheus
8.2.3 配置文件详解
# 配置文件中的全局配置
global:
scrape_interval: 15s # 多久 收集 一次数据
evaluation_interval: 30s # 多久评估一次 规则 根据rule定义的规则 来抓取值进行评估
scrape_timeout: 10s # 每次 收集数据的 超时时间
# 当Prometheus和外部系统(联邦, 远程存储, Alertmanager)通信的时候,添加标签到任意的时间序列或者报警
external_labels:
monitor: codelab
foo: bar
# 加载规则文件, 可以使用通配符
# 规则文件指定全局变量列表。从所有匹配的文件中读取规则和警报。
rule_files:
- "first.rules"
- "my/*.rules"
# 远程写入功能相关的设置
remote_write:
- url: http://remote1/push
write_relabel_configs:
- source_labels: [__name__]
regex: expensive.*
action: drop
- url: http://remote2/push
# 远程读取相关功能的设置
remote_read:
- url: http://remote1/read
read_recent: true
- url: http://remote3/read
read_recent: false
required_matchers:
job: special
# 收集数据-配置列表
# scrape_config部分指定了一组目标和参数,描述了如何抓取它们。
# 在一般情况下,一个抓取资源配置指定一个作业。在高级配置中,这可能会改变。
# 可以通过static_configs参数静态配置目标,也可以使用支持的服务发现机制之一动态发现目标。
# 此外,relabel_configs 允许在抓取之前对任何目标及其标签进行高级修改。
scrape_configs:
- job_name: prometheus # 必须配置, 自动附加的job labels, 必须唯一
honor_labels: true # 标签冲突, true 为以抓取的数据为准并忽略服务器中的,
# false 为 通过重命名来解决冲突
# scrape_interval is defined by the configured global (15s).
# scrape_timeout is defined by the global default (10s).
metrics_path: '/metrics'
# scheme defaults to 'http'.
# 文件服务发现配置 列表
#基于文件的服务发现提供了一种更通用的方法来配置静态目标,并用作插入自定义服务发现机制的接口。
#它读取一组包含零个或多个<static_config>列表的文件。
#对所有定义文件的更改都会通过磁盘监视检测到并立即应用。
#文件可以yaml或json格式提供。仅应用形成良好目标组的更改。
file_sd_configs:
- files: # 从这些文件中提取目标
- foo/*.slow.json
- single/file.yml
refresh_interval: 10m # 刷新文件的 时间间隔
# 使用job名作为label的 静态配置目录的列表
static_configs:
- targets: ['localhost:9090', 'localhost:9191']
labels:
my: label
your: label
# 目标节点 重新打标签的配置列表。
#重新标记是一个功能强大的工具,可以在抓取目标之前动态重写目标的标签集。
#可以配置多个,按照先后顺序应用
relabel_configs:
- source_labels: [job, __meta_dns_name]
#从现有的标签中选择源标签, 最后会被替换,保持,丢弃
regex: (.*)some-[regex]
# 正则表达式, 将会提取source_labels中匹配的值
target_label: job # 在替换动作中将结果值写入的标签.
replacement: foo-${1}
# 如果正则表达匹配, 那么替换值. 可以使用正则表达中的 捕获组
# action defaults to 'replace'
- source_labels: [abc] # 将abc标签的内容复制到cde标签中
target_label: cde
- replacement: static
target_label: abc
- regex:
replacement: static
target_label: abc
bearer_token_file: valid_token_file # 可选的, bearer token 文件的信息
# Alertmanager相关的配置
alerting:
alertmanagers:
- scheme: https
static_configs:
- targets:
- "1.2.3.4:9093"
- "1.2.3.5:9093"

