
②.kubernetes Pod控制器Deployment DeamonSet
一.Pod控制器
二.ReplicaSet
三.Deployment
四.Deployment场景实践
五.动态扩缩容实践
六.Deployment重建策略
七.Deployment滚动更新
八.Deployment滚动更新策略
-
8.1 maxSurge
-
8.2 maxUnavailable
-
8.3 maxSurge & maxUnavailable
-
8.4 minReadySeconds
-
8.5 revisionHistoryLimit
-
8.6 progressDeadlineSeconds
九.Deployment实现灰度发布
十.DaemonSet基本概述
十一. DaemonSet部署应用
十二. DaemonSet更细策略
十三. job
十四. job实践
===============================================================================================
一.Pod控制器
1.1 什么是Pod控制器
Pod控制器是用于实现管理pod的中间层,确保pod资源符合预期的状态,pod的资源出现故障时,会尝试 进行重启,当根据重启策略无效,则会重新新建pod的资源。
1.2 Pod控制器主要作用
pod的资源出现故障时,会尝试进行重启,当根据重启策略无效,则会重新新建pod的资源。
1.3 pod控制器种类
- ReplicaSet: 代用户创建指定数量的pod副本,确保pod副本数量符合预期状态,并且支持滚动式自动扩容和缩容功能。
ReplicaSet 主要三个组件组成:
1. 用户期望的pod副本数量
2. 标签选择器,判断哪个pod归自己管理
3. 当现存的pod数量不足,会根据pod资源模板进行新建
帮助用户管理无状态的pod资源,精确反应用户定义的目标数量,但是RelicaSet不是直接使用的控制器,而是使用Deployment。
- Deployment:工作在ReplicaSet之上,用于管理无状态应用,目前来说最好的控制器。支持滚动更新和回滚功能,还提供声明式配置。
ReplicaSet 与Deployment 这两个资源对象逐步替换之前RC的作用。
-
DaemonSet:用于确保集群中的每一个节点只运行特定的pod副本,通常用于实现系统级后台任务。比如ELK服务
特性:服务是无状态的
服务必须是守护进程 -
StatefulSet:管理有状态应用
-
Job:只要完成就立即退出,不需要重启或重建
-
Cronjob:周期性任务控制,不需要持续后台运行
二.ReplicaSet
2.1 传统应用集群
在传统环境中,如果要保证应用的高可用,一般都以集群方式部署,集群中的应用实例至少部署2个以上,这样即使一个应用故障了,另一台应用任然能够对外提供服务,在这种环境下,我们主要依赖前置的负载均衡Nginx,通过手动编辑配置文件的方式来实现。而一旦我们需要对应用进行扩容或缩容,也需要在Nginx上进行手动配置,过程相对繁琐也比较容易出错

2.2 什么是ReplicaSet
在 Kubernetes 环境中,通过 ReplicaSet 这种资源对象就可以来帮助我们实现集群的高可用, ReplicaSet (RS)的主要作用就是维持一组 Pod 副本的运行,保证一定数量的 Pod 在集群中正常运行,ReplicaSet 控制器会持续监听它控制的这些 Pod 的运行状态以及数量,保证应用集群的高可用;
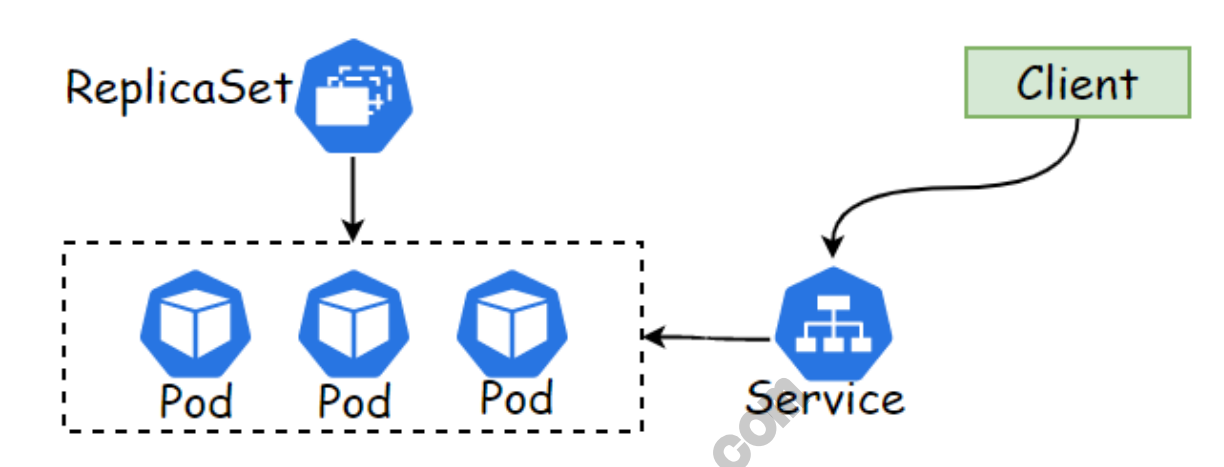
2.3 ReplicaSet组成部分
ReplicaSet控制器包含了3个基本的组成部分:
- seLector 标签选择器: 匹配并关联Pod对象,并加入控制器的管理中;
- replicas期望的副本数: 期望在集群中所运行的Pod对象数量;
- template Pod模板: 实际上就是定义的 Pod 规范,相当于把一个Pod 的描述以模板的形式嵌入到了 ReplicaSet
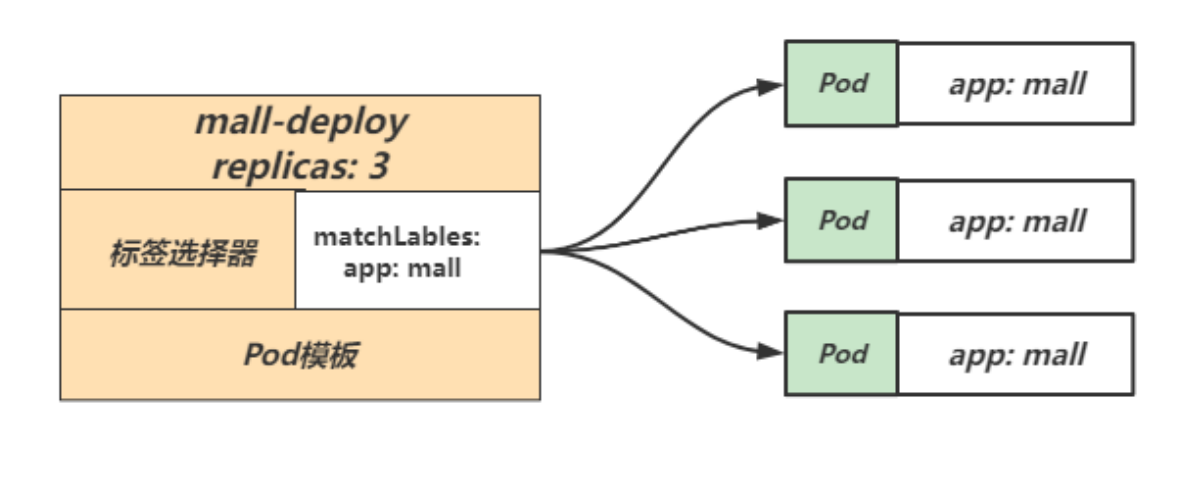
2.4 ReplicaSet示例配置
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: mall-deploy # RS控制器名称
namespace: default # 命名空间
spec :
replicas: 3 # 期望的 Pod 副本数量,默认值为1
selector: # SeLector,匹配 Pod 模板中的标签
matchLabeTs:
app: mall
template: # 定义 Pod 模板(内嵌Pod模板不需要apiVersion和kind字段)
metadata:
labels:
app: mall # 定义 Pod 标签
spec:
containers: #定义 Pod 中的容器信息
- name: mall-container
image: nginx
ports:
- containerPort: 80
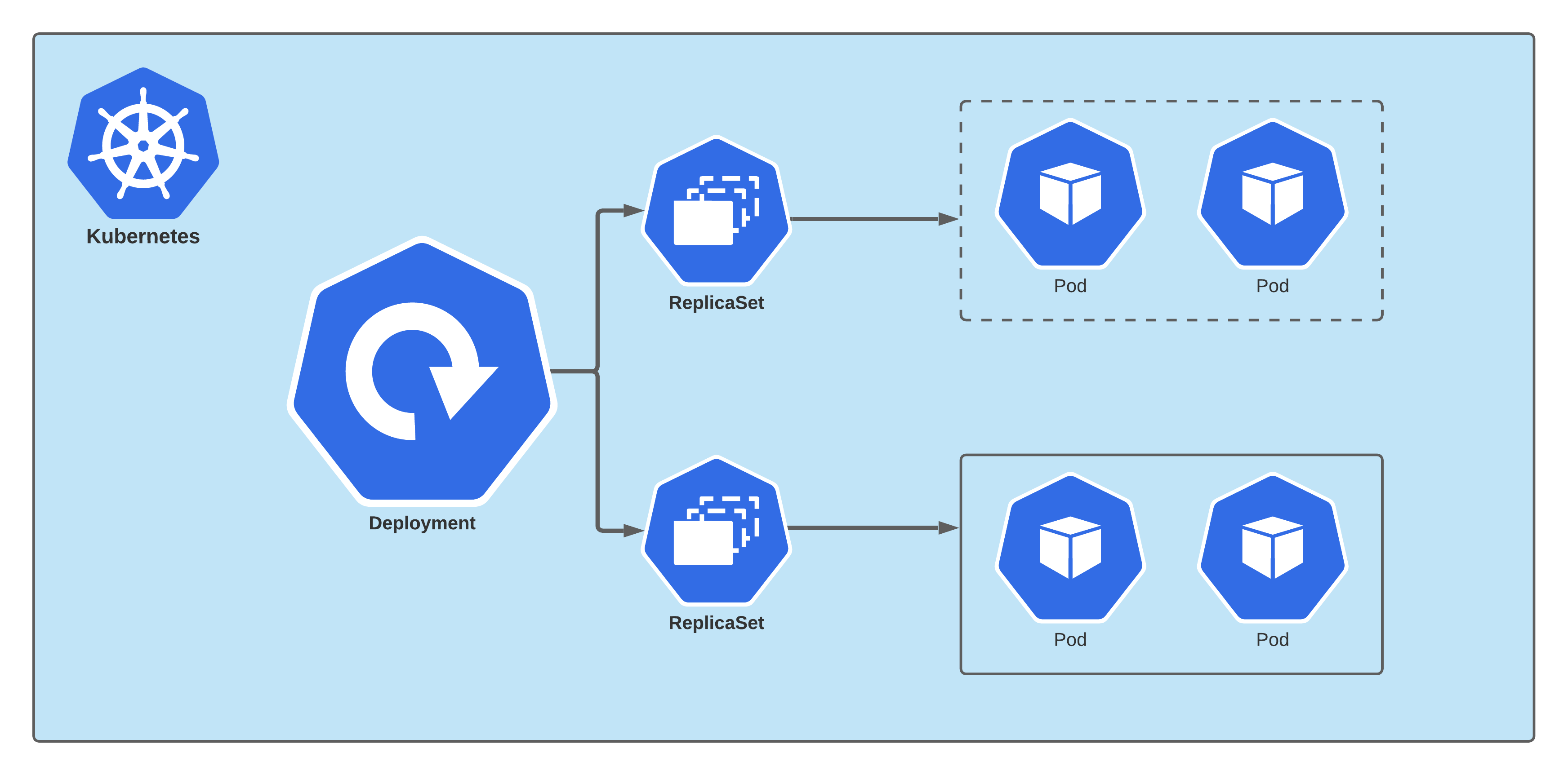
三.Deployment
3.1 什么是Deployment
Deployment (简称为deploy) 是Kubernetes控制器的一种高级别实现,他构建于ReplicaSet控制器之上.
我们只需要描述DepLoyment中的目标Pod期望状态,而DepLoyment控制器以受控速率更改实际状态,使其变为期望状态,也就是说,后期我们部署应用不直接使用Pod和ReplicaSet,而是使用Deployment控制器来调用ReplicaSet来实现,Deployment控制器在ReplicaSet原有基础上,添加了部分特性。
- 1、事件和状态查看: 可以通过特定的命令查看Deployment对象的更新进度和状态;
- 2、版本记录: 将Deployment对象的更新操作都进行保存,以便后续执行回滚操作使用;
- 3、多种更新方案: Recreate重建,可以实现单批次更新所有Pod.RolLingUpdate可以实现多批次逐步替换Pod
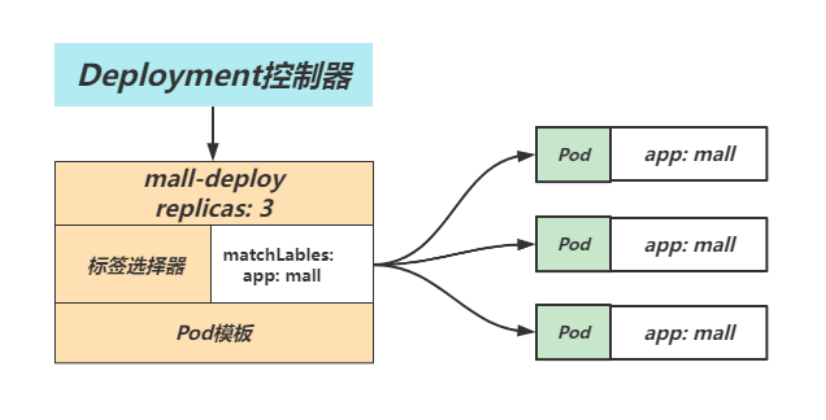
3.2 Deployment组成部分
DepLoyment 资源对象的格式和 ReplicaSet 几乎-致,Deployment 控制器也包含了3个基本的组成部分
selector标签选择器: 匹配并关联Pod对象,并对授其管控的Pod对象计数;replicas期望的副本数: 期望在集群中所运行的Pod对象数量;templatePod模板: 实际上就是定义的 Pod 内容,相当于把一个Pod 的描述以模板的形式嵌入到了ReplicaSet
3.3 Deployment示例配置
apiVersion: apps/v1
kind: Deployment
metadata:
name: mall-deploy #定义deploy资源名称
spec:
replicas: 3 #定义depLoy控制Pod的副本数
minReadySeconds:10 #Pod就绪后,多少秒内任一容器无崩溃方视为 “就绪”,默认0s
selector:
matchLabels: #标签选择器,选择 app:mall的标签
app: mall
template: #Pod 模板,申明Pod名称、使用镜像拥有哪些标签等
metadata:
labels: # Pod标签
app: mall
spec: # Pod的容器详情电明
containers:
- name: demoapp-container
image: oldxu3957/demoapp:v1.0
ports:
- containerPort: 80
四.Deployment场景实践
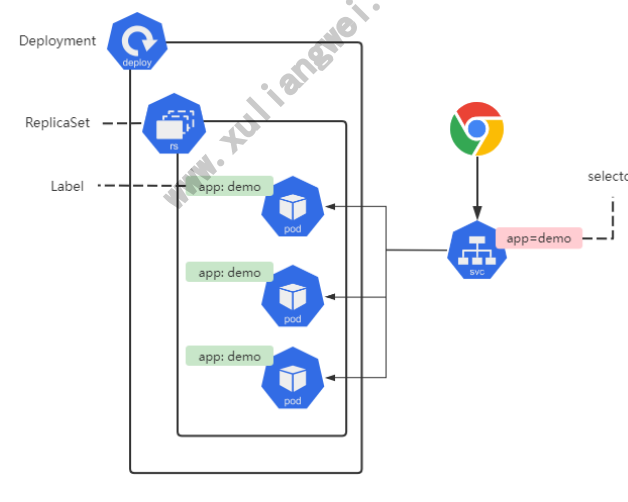
4.1 场景说明
场景说明: 运行一个demoapp的应用,部署3个副本,然后通过service来实现负载均衡;
- 1、创建 Deployment资源,部署三个副本
- 2、创建Service资源,通过标签选择器选择对应的Pod,以实现负载均衡;
- 3、使用 curl命令,或Chrome浏览器验证集群高可用
4.2 创建应用集群
apiVersion: apps/v1
kind: Deployment
metadata:
name: demoapp-deploy
spec:
replicas: 3
selector:
matchLabels:
app: demoapp
template:
metadata:
labels:
app: demoapp
spec:
containers:
- name: demoapp-container
image: oldxu3957/demoapp:v1.0
ports:
- containerPort: 80
4.3 检查集群状态
1、检查集群的 Deployment:
NAME列出了集群中DepLoyment的名称READY显示应用程序的可用的“副本"数。显示的模式是“就绪个数/期望个数"。UP-TO-DATE显示为了达到期望状态已经更新的副本数AVAILABLE显示应用可供用户使用的副本数。AGE显示应用程序运行的时间。
[root@k8s-240 deployment]# kubectl get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
demoapp-deploy 3/3 3 3 18s
[root@k8s-240 deployment]# kubectl describe deployment demoapp-deploy
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True NewReplicaSetAvailable
OldReplicaSets: <none>
NewReplicaSet: demoapp-deploy-7ddd58f7c6 (3/3 replicas created) #看到replicaSet资源
Events:
注意:期望副本数是根据.spec.replicas 字段设置 3
2、检查集群的 ReplicaSet:
NAME列出名字空间中ReplicaSet的名称;DESIRED显示应用的期望副本个数,即在创建Deployment时所定义的值。此为期望状态;CURRENT显示当前运行状态中的副本个数;READY显示应用中有多少副本可以为用户提供服务:AGE显示应用已经运行的时间长度。
注意 RepLicaSet 的名称被格式化为[Deployment名称]-[随机字符册]
[root@k8s-240 deployment]# kubectl get rs
NAME DESIRED CURRENT READY AGE
demoapp-deploy-7ddd58f7c6 3 3 3 5m56s
3.检查集群的Pod,所创建的ReplicaSet确保总是存在三个Pod
[root@k8s-240 deployment]# kubectl get pod
NAME READY STATUS RESTARTS AGE
demoapp-deploy-7ddd58f7c6-55c5n 1/1 Running 0 9m55s
demoapp-deploy-7ddd58f7c6-8bfj8 1/1 Running 0 9m55s
demoapp-deploy-7ddd58f7c6-lwtn8 1/1 Running 0 9m55s
4.4 创建Service
[root@master ~]# cat demoapp-service.yaml
apiVersion: v1
kind: Service
metadata:
name: demoapp-svc
spec:
selector: #标签选择器,选择哪些相同的Pod为一组Upstream
app: demoapp
ports:
- name: http
port: 80 # service对外提供的端口
targetPort: 80 # Pod的端口
查看对应的service地址
[root@k8s-240 deployment]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
demoapp-svc ClusterIP 10.0.0.39 <none> 80/TCP 6s
kubernetes ClusterIP 10.0.0.1 <none> 443/TCP 35d
4.5 验证集群高可用
[root@k8s-240 deployment]# curl 10.0.0.39/version
demoapp v1.0!! PodIP: 10.244.157.167!
[root@k8s-240 deployment]# curl 10.0.0.39/version
demoapp v1.0!! PodIP: 10.244.149.158!
[root@k8s-240 deployment]# curl 10.0.0.39/version
demoapp v1.0!! PodIP: 10.244.157.168!
4.6 水平伸缩
水平扩展/收缩的功能比较简单,修改replicas对应的副本数即可。比如将 Pod 的副本调整到 5 个,那么 Deployment 所管理的ReplicaSet 则会自动创建一个新的 Pod 出来,这样就水平扩展了
1、命令方式修改
kubectl scale deployment
2、通过yaml来实现
kubectl edit deployment demoapp
4.7 模拟故障
删除Pod,看是否能自动恢复
五.动态扩缩容实践
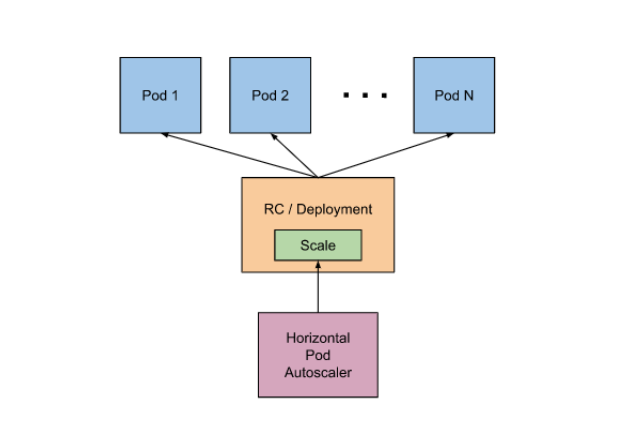
5.1 什么是HPA
Kubernetes实现Pod的扩缩容需要通过手动来实现,但线上的业务情况比较复杂,依赖于纯手动的方式,不太现实。所以希望系统能自动感知Pod的压力来完成扩缩容,比如: 当Pod的CPU达到了50%则扩容,当Pod的CPU低于50%自动缩容。
为此Kubernetes为我们提供了这样的一个资源对象HPA (horizontal-pod-autoscaler) ,专用来实现Pod的水平自动扩缩容。HPA 通过监控分析一些控制器控制的所有 Pod 的负载变化情况来确定是否需要调整Pod 的副本数量;
5.2 自动扩缩容算法
算法:
副本数 = [当前副本数 * (当前指标 / 期望指标)]
当前指标: 当前Pod已经达到了百分之多少的压力;期望指标: 当Pod达到期望的指标百分比时就要进行扩容;
例如,当前副本为1,当前当前指标值250%,而期望的指标值是50%,则副本数会翻5倍,因为 1 * (250%/50%) = 5
5.3 安装MetricServer
kubectl apply -f https:// inux.oldxu.net/metrics-server.yaml
5.4 动态扩缩容实践
apiVersion: apps/v1
kind: Deployment
metadata:
name: php-apache
spec:
selector:
matchLabels:
run: php-apache
replicas: 1
template:
metadata:
labels:
run: php-apache
spec:
containers:
- name: php-apache
image: oldxu3957/hpa-example
ports:
- containerPort: 80
resources:
requests:
cpu: 200m
limits:
cpu: 500m
2.创建负载均衡
apiVersion: v1
kind: Service
metadata:
name: php-apache
spec:
selector:
run: php-apache
ports:
- port: 80
targetPort: 80
获取负载均衡IP
[root@k8s-240 deployment]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
php-apache ClusterIP 10.0.0.164 <none> 80/TCP 3s
3.创建hpa 设定cpu超过50%,则触发自动创建Pod副本
# kubectl autoscale deployment php-apache --min=1 --max=10 --cpu-percent=50
[root@master ~]# cat php-apache-hpa.yaml
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
spec:
minReplicas: 1 # 最少启动1个Pod
maxReplicas: 10 # 最多扩展10个Pod
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
targetCPUUtilizationPercentage: 50 # cpu达到50%
4.模拟增加负载
while sleep 0.01;do curl http://10.0.0.164;done
当前副本为1,当前压力达到了250%,而CPU只要超过50%就会扩容,需要扩容5个副本来分担压力。1 * (250%/5%) = 5
六.Deployment重建策略
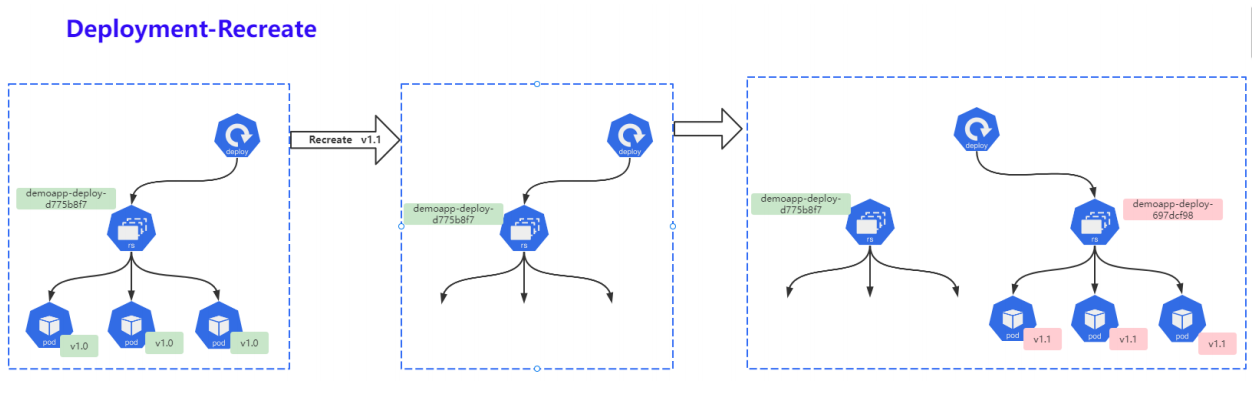
6.1 什么是Recreate
重建 (Recreate)当更新策略设定为 Recreate ,在更新镜像时它会先杀死正在运行的Pod,等彻底杀死后,重新创建新的RS,然后启动对应的Pod,那么在这个更新过程中,会造成服务一段时间无法提供服务;
- 第一步: 同时杀死所有旧版本的Pod,此时Pod无法正常对外提供服务;
- 第二步: 创建新的RS,启动新的Pod;
- 第三步: 等待Pod就绪,对外提供服务
6.2 Recreate实践
[root@master deployment]# cat demoapp-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: demoapp-deploy
spec:
replicas: 3
strategy:
type: Recreate # 重建
selector:
matchLabels:
app: demoapp
template:
metadata:
labels:
app: demoapp
spec:
containers:
- name: demoapp-container
image: oldxu3957/demoapp:v1.1# 将v1.0 修改为 v1.1 版本
ports:
- containerPort: 80
2.观察更新过程
[root@k8s-240 deployment]# kubectl get pod
NAME READY STATUS RESTARTS AGE
demoapp-deploy-5f5b6fbb97-7qlr2 1/1 Running 0 15s
demoapp-deploy-5f5b6fbb97-9wgrl 1/1 Running 0 15s
demoapp-deploy-5f5b6fbb97-flpbl 1/1 Running 0 15s
3.创建新的RS,然后期望运行Pod为3,就绪3
[root@k8s-240 deployment]# kubectl get rs
NAME DESIRED CURRENT READY AGE
demoapp-deploy-5bd8c99dc6 3 3 0 9m48s
demoapp-deploy-7ddd58f7c6 0 0 0 46h
七.Deployment滚动更新
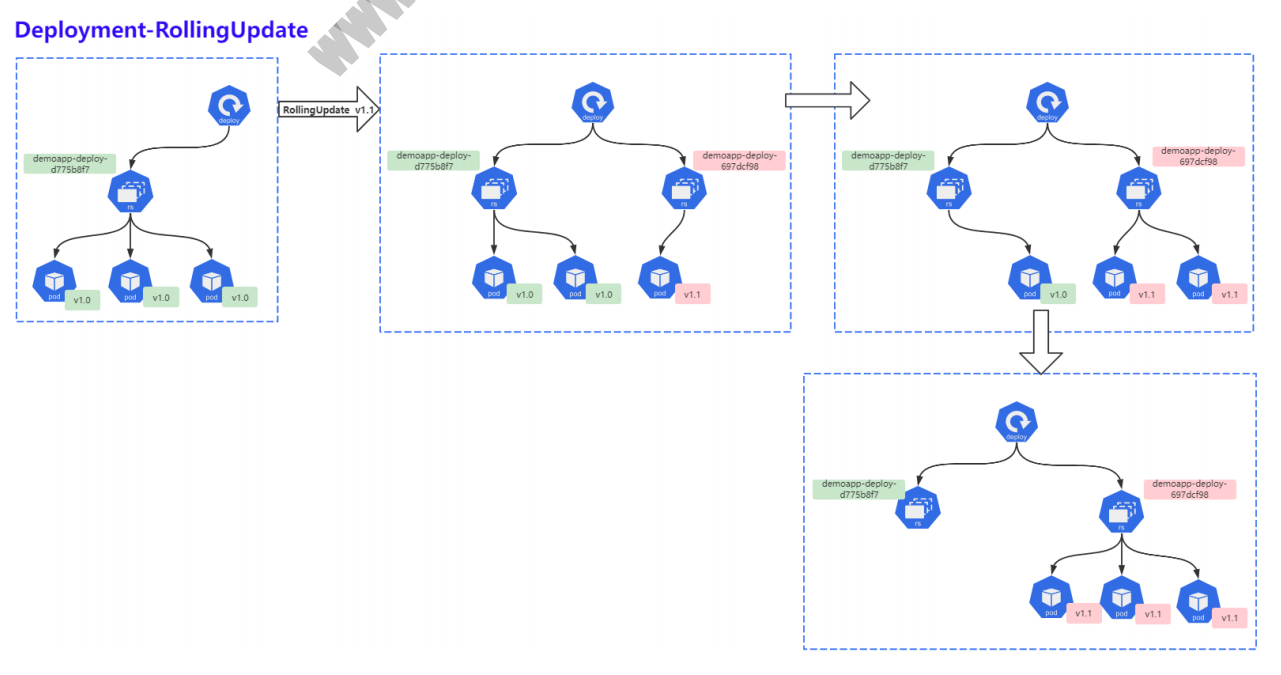
7.1 什么是滚动更新
滚动更新 (RolLingUpdate) ,一次仅更新一批Pod,当更新的Pod就绪后,在更新另一批,直到全部更新完成为止,该策略实现了不间断服务的目标,在更新过程中可能会出现不同的应用版本并存且,同时提供服务的情况。
- 第一步: 创建新的ReplicaSet,然后根据新的镜像运行新的Pod;
- 第二步:删除旧的Pod,启动新的Pod,新Pod就绪后,继续删除旧Pod,启动新Pod;
- 第三步: 持续第二步过程,一直到所有Pod都被更新成功。
7.2 滚动更新实践
1.准备yaml文件
apiVersion: apps/v1
kind: Deployment
metadata:
name: demoapp-deploy
spec:
replicas: 3
strategy:
type: RollingUpdate
selector:
matchLabels:
app: demoapp
template:
metadata:
labels:
app: demoapp
spec:
containers:
- name: demoapp-container
image: oldxu3957/demoapp:v1.1
ports:
- containerPort: 80
2.观察更新过程
[root@k8s-240 deployment]# kubectl apply -f deployment_rollout.yaml
deployment.apps/demoapp-deploy configured
[root@k8s-240 deployment]# kubectl rollout status deployment demoapp-deploy
Waiting for deployment "demoapp-deploy" rollout to finish: 1 out of 3 new replicas have been updated...
Waiting for deployment "demoapp-deploy" rollout to finish: 1 out of 3 new replicas have been updated...
Waiting for deployment "demoapp-deploy" rollout to finish: 1 out of 3 new replicas have been updated...
Waiting for deployment "demoapp-deploy" rollout to finish: 2 out of 3 new replicas have been updated...
Waiting for deployment "demoapp-deploy" rollout to finish: 2 out of 3 new replicas have been updated...
Waiting for deployment "demoapp-deploy" rollout to finish: 1 old replicas are pending termination...
Waiting for deployment "demoapp-deploy" rollout to finish: 1 old replicas are pending termination...
deployment "demoapp-deploy" successfully rolled out
3.通过浏览器访问,会发现新老版本存在交替,但并不会初心服务不可用状态
7.3 应用回退实践
有时,你可能想要回滚 Deployment; 例如,当 Deployment 不稳定进入反复崩溃状态。 默认情况下,Deployment 的所有上线记录都保留在系统中,以便可以随时回滚。 (你可以通过修改 revisionHistoryLimit 调整保留的数量,默认10条)
1.首先,检查 Deployment 上线的历史版本
[root@master deployment]# kubectl rollout history deployment demoapp-deploy
deployment.apps/demoapp-deploy
REVISION CHANGE-CAUSE
1 <none> # 历史版本,demoapp:v1.0<none>
2 <none> # 当前正在使用的版本,demoapp:v1.1
2.也可以查看每个REVISION对应的具体信息
[root@master deployment]# kubectl rollout historydeployment demoapp-deploy --revision=1
deployment.apps/demoapp-deploy with revision #2
Pod Template:
Labels: app=demoapp
pod-template-hash=697dcf98
Containers:
demoapp-container:
Image: oldxu3957/demoapp:v1.0 # 可以看到当前的镜像版本
Port: 80/TCP
Host Port: 0/TCP
Environment:<none>
Mounts: <none>
Volumes :<none>
3.确认要回退的REVISION,然后执行回退命令即可。
按照下面的步骤将 Deployment 从当前版本 (即版本2) 回滚到以前的版本 (即版本 1)。
3.1.通过使用 --to-revision 来回滚到特定修订版本:
[rootmaster ~]# kubectl rollout undo deployment demoapp-deploy --to-revision=1
deployment.apps/demoapp-deploy rolled back
3.2.测试访问站点
# 访问站点
[root@master ~]# cur 10.96.8.44:8888
iKubernetes demoapp v1.1 !!
[root@master ~]# cur 10.96.8.44:8888
iKubernetes demoapp v1.0 !!
[root@master ~]# curl 10.96.80.44:8888
iKubernetes demoapp v1.1 !!
[root@master ~]# cur 10.96.8.44:8888
iKubernetes demoapp v1.0 !!
[root@master ~]# curl 10.96.80.44:8888
iKubernetes demoapp v1.0 !!
八.Deployment滚动更新策略
Deployment 会在 .spec .strategy.type=RollingUpdate 时采取滚动更新的方式更新 Pods。可以指定 maxUnavailable 和maxSurge 来控制滚动更新过程。
- maxSurge 最大可用Pod
- 用来指定可以创建超出期望Pod个数的 Pod数量。可以是数字也可以是百分比 (例如10%) 此字段的默认值为25%.
- 例如,当此值为 20% 时,启动滚动更新后,会立即对新的RepLicaSet 扩容,同时保证新旧 Pod 的总数不超过所需Pod 总数的 120%。一旦日 Pods 被杀死,新的RepLicaSet 可以进一步扩容,同时确保更新期间的任何时候运行中的 Pods 总数最多为所需 Pods 总数的 120%。 计算公式: 10+(10x20%)=12
- maxUnavailable 最大不可用Pod
- 用来指定更新过程中不可用的 Pod 的个数上限。可以是数字也可以是百分比 例如10%) 此字段的默认值为25%。
- 例如,当此值设置为 20% 时,滚动更新开始时会立即将旧RepLicaSet 缩容到期望 Pod 个数的70%。新 Pod 准备就绪后,继续缩容旧有的 ReplicaSet,然后对新的ReplicaSet 扩容,确保在更新期间可用的 Pods 总数在任何时候都是所需的 Pod 个数的 70%。 计算公式: 1-(10x20%)=8
- maxSurge 和 maxUnavailable 两个属性协同工作,可组合定义出3中不同的策略完成多批次的应用更新。
- 先增新,后减旧: 将maxSurge设置为30%,将maxUnavailable的值设为0;
- 先减日,后增新: 将maxUnavailable设置为30%,将maxSurge的值设为0;
- 同时增减,将maxSurge和maxUnavailable分别设定为2%;期望是12Pod,至少就绪8个Pod
8.1 maxSurge
指定升级期间存在的总Pod对象数量最多可超出期望值的个数,可以是0,也可以是整数,也可以是一个百分比。例如: 期望的的值为10,maxSurge属性为2,则表示Pod对象总数不能超过12个。 计算公式: 10+(10x2%)=12
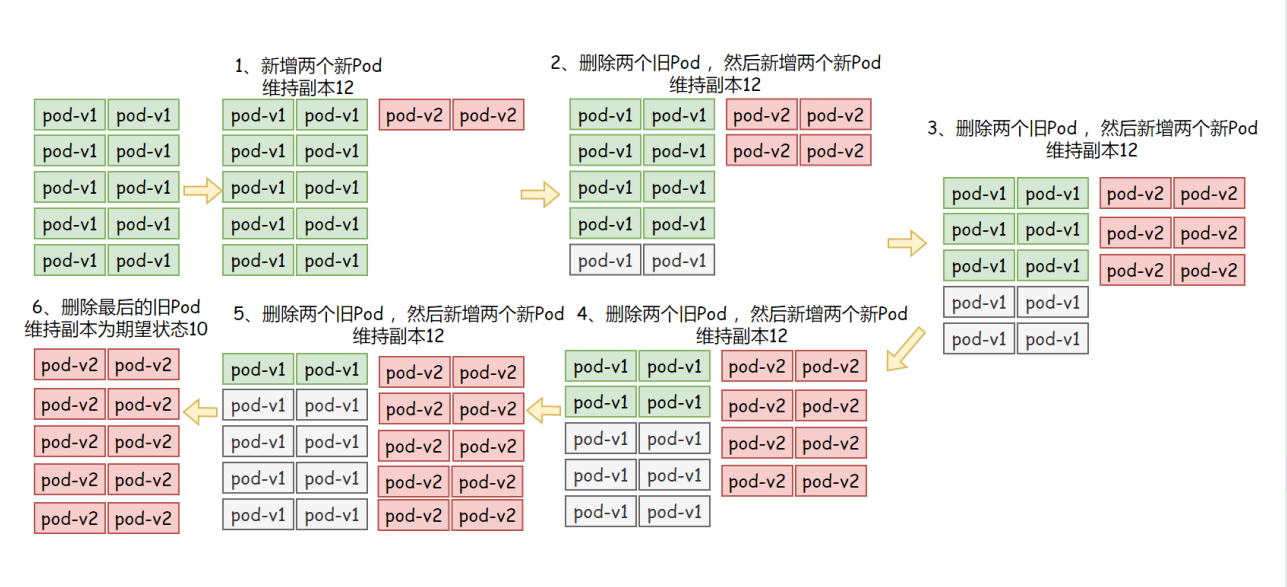
示例配置:
apiVersion: apps/v1
kind: Deployment
metadata:
name: demoapp-deploy
spec:
replicas: 10
strategy:
rollingUpdate:
maxSurge: 20% #最大可用20%
maxUnavailable: 0 #不可用状态设定为0
selector:
matchLabels:
app: demoapp
template:
metadata:
labels:
app: demoapp
spec:
containers:
- name: demoapp-container
image: registry.cnhuhehaote.aliyuncs.com/oldxu3957/demoapp:v1.0 #调整版本触发更新
ports:
- containerPort: 80
#可以通过如下命令实时查看更新策略是否与图中一致:
watch -n 1 kubectl get rs
8.2 maxUnavailable
升级期间不可用的Pod副本数 (包括新版本),最多不能低于期望的个数,默认为1。
例如: 期望的值为10,maxunavailable属性为2,则表示Pod处于正常状态至少 有8个。计算公式: 10-(10x20%)=8
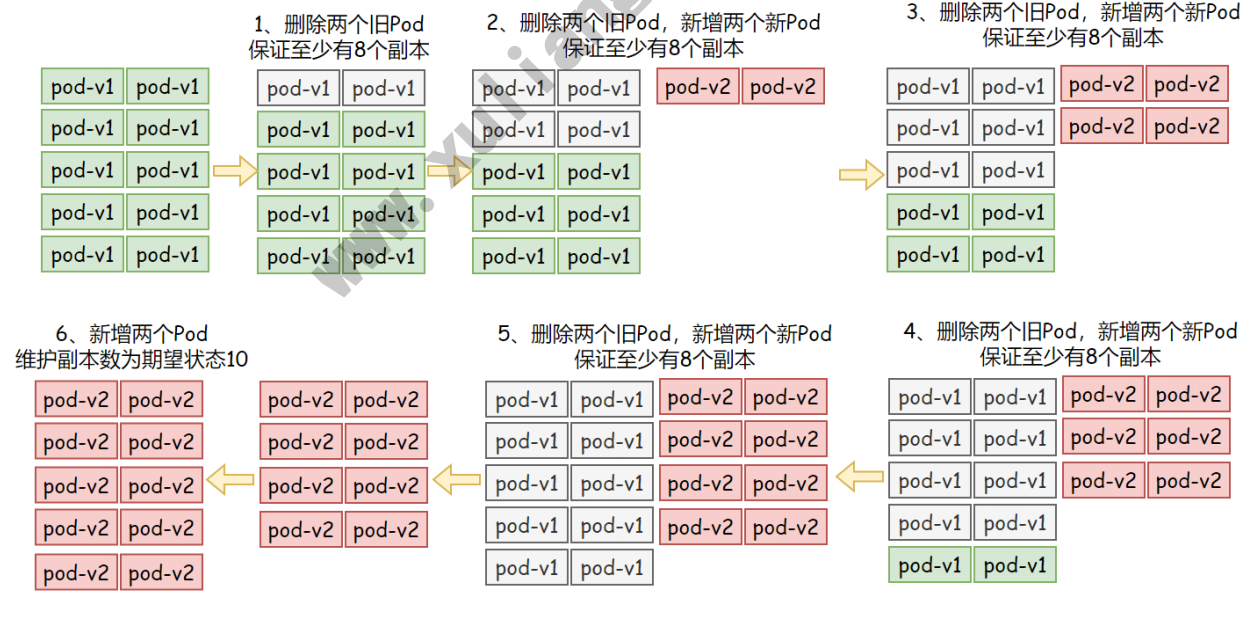
示例配置:
[root@master deployment]# cat demoapp-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata :
name: demoapp-deploy
spec:
replicas: 5
strategy:
rollingUpdate:
maxSurge: 0 # 最大可用0
maxUnavailable: 20% # 不可用Pod副本最低20%
selector:
matchLabels:
app: demoapp
template:
metadata:
labels:
app: demoapp
spec:
containers:
- name: demoapp-container
image: registry.cn-huhehaote.aliyuncs.com/oldxu3957/demoapp:v1.0 # 调整版本触发更新
ports
- containerPort: 80
可以通过如下命令实时查看更新策略是否与描述的一致
watch -n 1 kubectl get rs
8.3 maxSurge & maxUnavailable
同时设定 maxSurge 以及 maxUnavailable
[root@master deployment]# cat demoapp-deploy .yaml
apiVersion: apps/1
kind: Deployment
metadata :
name: demoapp-deploy
spec:
replicas: 5
strategy:
rollingUpdate :
maxSurge: 20% # 最大可用0
maxUnavailable: 20% # 不可用Pod副本最低20%
selector:
matchLabels:
app: demoapp
template:
metadata :
labels:
app: demoapp
spec :
containers:
- name: demoapp-container
image: registry.cn-huhehaote.aliyuncs.com/oldxu3957/demoapp:v1.0 # 调整版本触发更新
ports:
- containerPort: 80
8.4 minReadySeconds
Deployment支持使用 spec.minReadySeconds 字段来控制滚动更新的速度,默认值为0,表示新建的Pod对象一旦“就绪”将立即被视作可用,随后即可开始下一轮更新过程。如果设定了spec.minReadySeconds: 3 及表示新建的Pod对象至少要成功运行多久才会被视作可用,即就绪之后还要等待指定的 3s 才能开始下一批次的更新。在一个批次内新建的所有Pod就绪后在转为可用状态前,更新操作会被阻塞,并且任何一个Pod就绪探测失败,都会导致滚动更新被终止。
因此,为minReadySeconds设定一个合理的值,不仅能够减缓更新的速度,还能够让Deployment提前发现一部分程序因为Bug导致的升级故障
8.5 revisionHistoryLimit
Deployment保留一部分更新历史中旧版本的 ReplicaSet 对象,当我们执行回滚操作的时候,就直接使用旧版本的 ReplicaSet,在Deployment 资源保存历史版本数量有spec.revisionHistoryLimit 属性进行定义

kubectl rollout history deployment
8.6 progressDeadlineSeconds
滚动更新故障超时时长,默认为600秒,k8s 在升级过程中有可能由于各种原因升级卡住(这个时候还没有明确的升级失败) ,比如在拉取被墙的镜像,权限不够等错误。如果配置 progressDeadlineSeconds,当达到了时间如果还卡着,则会上报这个异常情况,这个时候这个Deployment 状态就被标记为 False,并且注明原因。但是它并不会阻止 Deployment 继续进行卡住后面的升级操作。
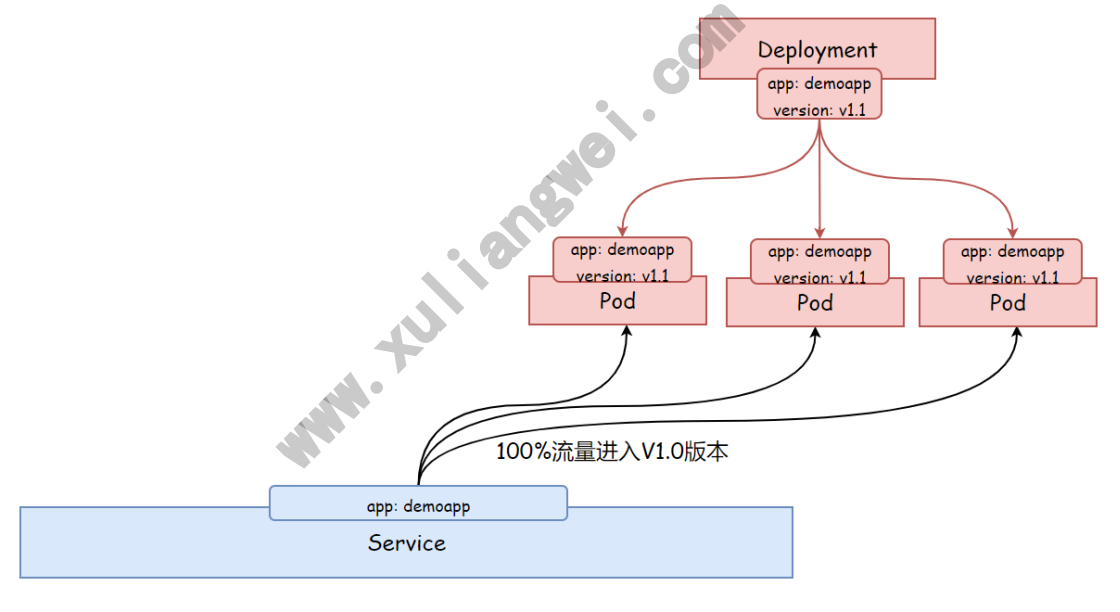
九.Deployment实现灰度发布
灰度发布 (又名金丝雀发布) 是指黑与白之前,能够平滑过度的一种发布方式,在上面可以进行A/B Testing
- 1、首先: 让一部分用户继续使用产品特性A (旧版本)
- 2、其次: 让一部分用户开始使用产品特性B (新版本)
- 3、最后: 如果用户对产品特性B没有反对意见,那么逐步扩大反问将用户的流量迁移到B上面来。
使用灰度发布的模式,可以及时发现问题,调整问题,以减少影响的速度,保证整体系统的稳定运行。
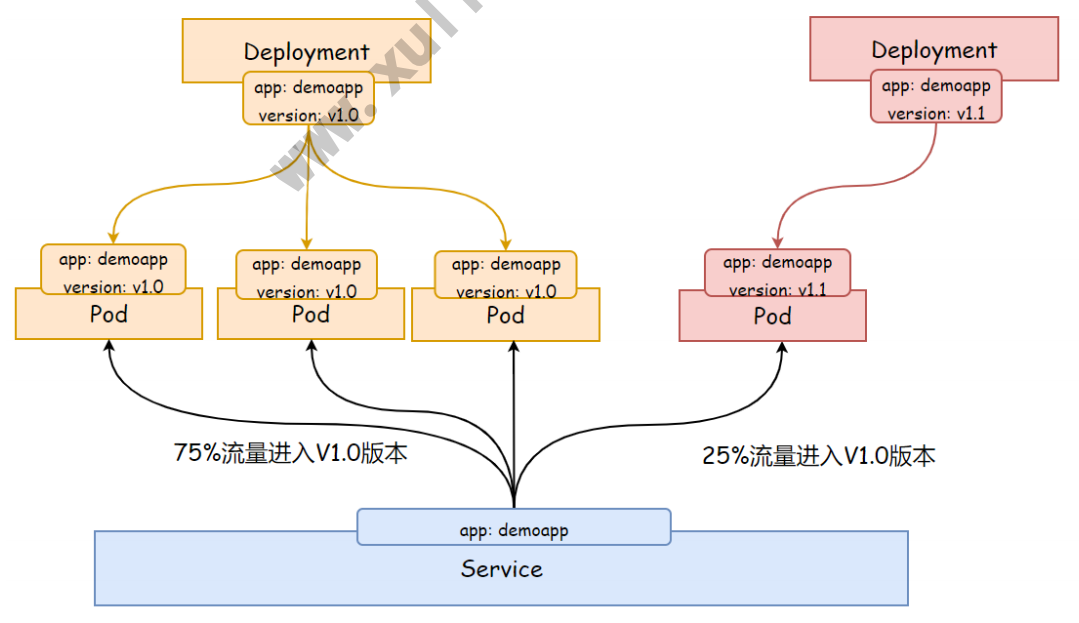
如果新版本没有问题,那么逐步扩大新版本的访问流量,然后减少就版本的访问流量。
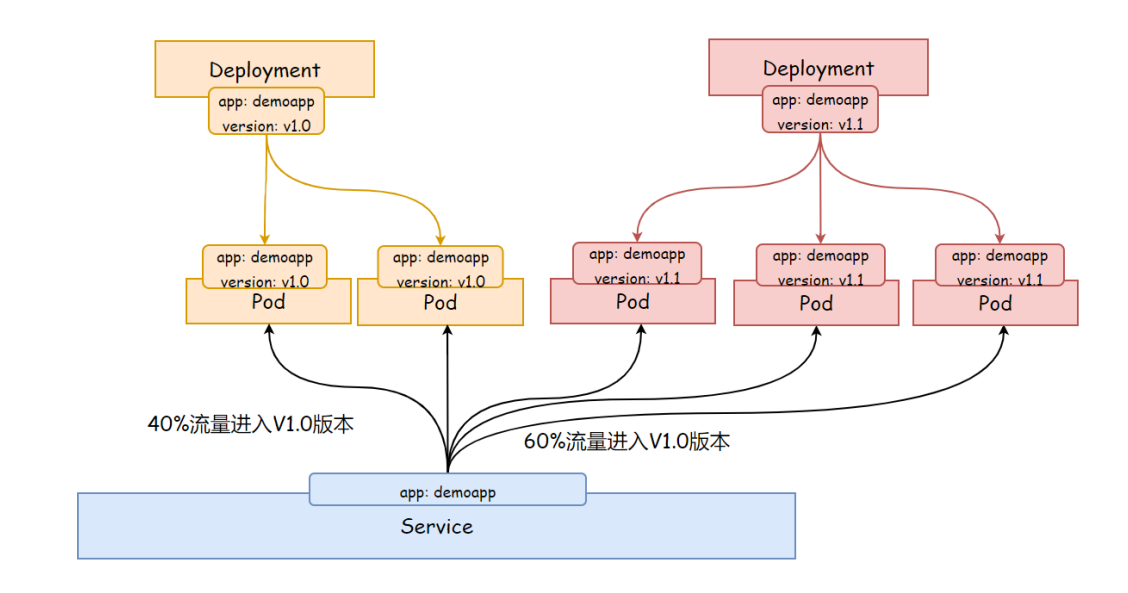
最后删除旧版本的Deployment,或者讲replicaset副本数设定为0,至此所有的流量都进入新版本
9.1 部署1.0版本应用
1.编写yaml
[root@master tmp]# cat demoapp-version10.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: demoapp-version-10-prod
spec:
replicas: 3
selector:
matchLabels:
app: demoapp
version: V1.
template:
metadata:
labels:
app: demoapp
version: V1.0
spec:
containers:
- name: demoapp
image: oldxu3957/demoapp:v1.0
2.检查部署结果
[root@master tmp]# kubectl get pod
NAME READY STATUS RESTARTS AGE
demoapp-version-10-prod-5499c6ddc7-q84z8 1/1 Running 0 5s
demoapp-version-10-prod-5499c6ddc7-t7qk7 1/1 Running 0 5S
demoapp-version-10-prod-5499c6ddc7-vdpvs 1/1 Running 0 5s
9.2 部署service实现负载均衡
1.编写负载均衡yaml,它会通过标签选择留选择app=demoapp的Pod
[rootomaster ~]# cat demoapp-service .yaml
apiversion: V1
kind: Service
metadata:
name : demoapp-service
spec:
selector:
app: demoapp
ports:
- name: http
port: 80
targetPort: 80
2.获取Service的IP
[root@master tmp]# kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
demoapp-service ClusterIp 10.96.54.90 <none> 88/TCP 4S
3.访问v1.日应用
[rootmaster *]# curl 18.96.54.90/version
demoapp V1.8 !!
[rootomaster *]# curl 18.96.54.98/version
demoapp V1.8 !!
[rootomaster *]# curl 10.96.54.90/version
demoapp v1.8 !!
9.3 部署1.1版本应用
[root@master tmp]# cat demoapp-version11.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: demoapp-version-11-prod
spec:
replicas: 1 # 部署一个副本作为灰度应用
selector:
matchLabels:
app: demoapp
version: V1.1
template:
metadata:
labels:
app: demoapp
version: v1.1
spec :
containers:
- name: demoapp
image: oldxu3957/demoapp:v1.1
9.4 测试新老版本共存
[root@master ~]# curl 10.96.54.90/version
demoapp v1.0 !!
[root@master ~]# curl 10.96.54.90/version
demoapp v1.0 !!
[root@master ~]# curl 10.96.54.90/version
demoapp v1.1 !!
[root@master ~]# curl 10.96.54.90/version
demoapp v1.0 !!
[root@master ~]# curl 10.96.54.90/version
demoapp v1.1 !!
9.5 控制新老版本流量
1、逐步增加1.1版本的流量
[root@master tmp]# vim demoapp-version11.yaml
spec:
replicas: 3# 增加副本数量,这样就能接收更大比例的流量
2、逐步减少1.0版本的流量
[root@master tmp]# vim demoapp-version10.yaml
spec:
replicas: 0# 副本数调为0,或者删除Deployment
十.DaemonSet基本概述
10.1 什么是DaemonSet
DaemonSet 控制器是用来保证在所有节点上运行一个Pod的副本。当有节点加入集群中,也会为新节点增加一个DaemonSet类型Pod,当有系欸但从集群种一出时,改Pod也会被回收。删除DaemonSet将会删除它创建的所有Pod。
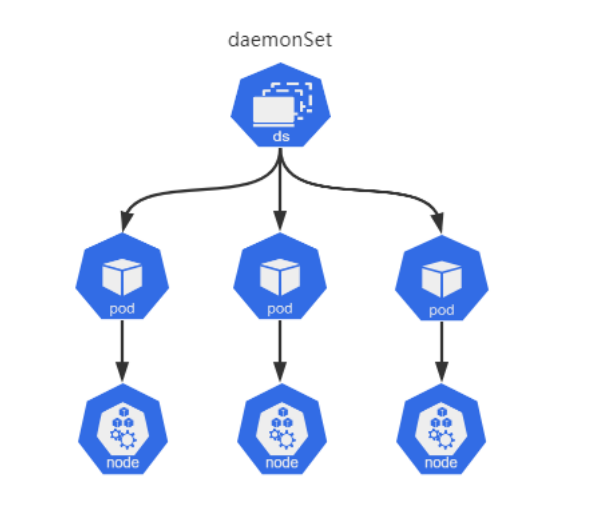
10.2 DaemonSet使用场景
- 在每个节点上运行集群存储守护进程,如:Gluster、Ceph
- 在每个节点上运行日志收集守护进程,如: fluentd、Filebeat.Logstash
- 在每个节点上运行监控守护进程,如: Prometheus NodeExporter、
- 在每个节点上运行网络插件为Pod提供网络服务,如: fanneL、calico
10.3 DaemonSet编写示例
DaemonSet是标准的API资源类型,它在spec字段中嵌套字段有seLector、tempalte,与DepLoyment用法基本相同,但DaemonSet 不管理 Replicas,因为 DaemonSet不是基于期望的副本数,而是 基于节点数量来控制Pod数量
apiVersion: apps/v1 # API群组及版本
kind: DaemonSet # 资源类型表示
metadata:
name: <string> # 资源名称
namespace: <string> # 名称空间: DaemonSet资源隶属于名称空间级别
spec :
minReadySeconds: <integer> # Pod就绪后多少秒内任容器无崩溃方视为“就绪”
selector: <object> # 标签选择器,必须匹配template字段中Pod模板的标签
revisionHistoryLimit: <integer> # 滚动更新历史记录数量,默认为10
updateStrategy: <Object> # 滚动更新策略
type: <string> # 滚动更新类型,可用值有OnDelete和RollingUpdate
rollingUpdate: <Object> # 滚动更新参数,专用于RollingUpdate类型
maxSurge: <string> # 滚动更新参数,更新期间存在的总Pod对象数量最多可超出期望值的个数
maxUnavailable : <string> # 滚动更新参数,升级期间不可用的Pod副本数
template: <0bject> # Pod模板
metadata: <0bject> # Pod名称
spec: <0bject> # Pod详情
十一. DaemonSet部署应用
11.1 DaemonSet部署实例
cat nginx-DaemonSet.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: nginx-ds
namespace: default
spec:
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.16
ports:
- name: http
containerPort: 80
livenessProbe:
tcpSocket:
port: 80
initialDelaySeconds: 3
readinessProbe:
httpGet:
path: "/u"
port: 80
scheme: HTTP
initialDelaySeconds: 5
11.2 DaemonSet部署node_exporter
1.为每个节点都运行一份node_exporter,采集当前节点的信息:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: node-exporter-ds
namespace: default
spec:
selector:
matchLabels:
app: node-exporter
template:
metadata:
labels:
app: node-exporter
spec:
containers:
- name: prometheus-node-exporter
image: prom/node-exporter:v0.18.8
ports:
- name: node-ex-http
containerPort: 9188
hostPort: 9100
livenessProbe:
tcpSocket:
port: node-ex-http
initialDelaySeconds: 3
readinessProbe:
httpGet:
path: "/metrics"
port: node-ex-http
scheme: HTTP
initialDelaySeconds: 5
hostNetwork: true # 共享主机网络
hostPID: true # 获取主机 PID
#nodeSelector: #节点选择器 选择那些节点部署Ingress,默认所有
#type: ssd #如果节点有type=ssd 标签则部署
2.输出Pod对象状态
[root@master ~]# kubectl describe daemonsets.appsnode-exports-ds
Desired Number of Nodes Scheduled: 3
Current Number of Nodes Scheduled: 3
Number of Nodes Scheduled with Up-to-date Pods: 3
Number of Nodes Scheduled with Available Pods: 3
Number of Nodes Misscheduled: 0
Pods Status: 3 Running / 0 Waiting / 0 Succeeded / 0 Failed
3.node_exporter默认监听在TCP的9100端口上,我们可以向任何一台节点IP发起访问,进行验证。
[root@master ~]# curl -s 10..0.204:9100/metrics |grep Toad15
# HELP node_Load15 15m Load average.# TYPE node_load15 gaugenode load15 0.27
[root@master ~]# curl -s 10.0.0.205:910/metrics |grep load15
# HELP node_load15 15m Toad average.# TYPE node_load15 gaugenode load15 0.18
十二. DaemonSet更细策略
DaemonSet也支持更新策略,它支持 OnDelete 和 RollingUpdate两种
- OnDeLete: 是在相应节点的Pod资源被删除后重建为新版本,从而允许用户手动编排更新过程。
- RollingUpdate: 滚动更新,工作逻辑和Deployment滚动更新类似;
12.1 RollingUpdate
1.将此前创建的node-expoter中的pod模板镜像修改为 prom/nodeexporter:v0.18.1,便能测试其更新过程.
cat node_exporter.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: node-exporter-ds
namespace: default
spec:
minReadySeconds: 3
revisionHistoryLimit: 20
updateStrategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1
selector:
matchLabels:
app: node-exporter
template:
metadata:
labels:
app: node-exporter
spec:
containers:
- name: prometheus-node-exporter
image: prom/node-exporter:v0.18.1
ports:
- name: node-ex-http
containerPort: 910
hostPort: 910
livenessProbe:
tcpSocket:
port: node-ex-http
initialDelaySeconds: 5
readinessProbe:
httpGet:
path: '/metrics'
port: node-ex-http
scheme: HTTP
initialDelaySeconds: 5
hostNetwork: true
hostPID: true
2.安装默认的 RollingUpdate 策略, node-exports-ds 资源将采用一次更新一个Pod对象,待新建Pod的对象就绪后,在更新下一个Pod对象,直到全部完成。
[rootmaster daemonset]# kubectl describedaemonsets.apps node-exports-ds
Events:
Type Reason Age From
Message
------------------
Normal SuccessfulDelete 96s daemonset-controller Deleted pod: node-exports-ds-p9w52
Normal SuccessfulCreate 95s daemonset-controller Created pod: node-exports-ds-hcbfn
Normal SuccessfulDelete 62s daemonset-controller Deleted pod: node-exports-ds-fjc6x
Normal SuccessfulCreate 61s daemonset-controller Created pod: node-exports-ds-Igtsc
12.2 OnDelete
1.将此前创建的node-expoter中的pod模板镜像更新为 prom/nodeexporter:v1.3.1,由于升级版本跨度过大,无法确保升级过程中的科定性,我们就不得不使用 0nDeLete 策略来替换默认的RolTingUpdate 策略.
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: node-exporter-ds
namespace: default
spec:
minReadySeconds: 3
revisionHistoryLimit: 20
updateStrategy:
type: OnDelete
selector:
matchLabels:
app: node-exporter
template:
metadata:
labels:
app: node-exporter
spec:
containers:
- name: prometheus-node-exporter
image: prom/mode exporter:v1.3.1
ports:
- name: node-ex-http
containerPort: 9100
hostPort: 9100
livenessProbe:
tcpSocket:
port: node-ex-http
initialDelaySeconds: 3
readinessProbe:
httpGet:
path: "/metrics"
port: node-ex-http
scheme: HTTP
initialDelaySeconds: 5
hostNetwork: true
hostPID: true
2.由于 0nDelete 并非自动完成升级,它需要管理员手动删除Pod,然后重新拉起新的Pod,才能完成更新。 (对于升级有着先后顺序的软件这种方法就非常的有用,)
[root@master ~]# kubectl delete pod node-exports-ds-sg756 node-exports-ds-lgtsc
pod "node-exports-ds-sg756" deleted
pod "node-exports-ds-lgtsc" deleted
3.检查Pod是否正常运行
[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
node-exports-ds-8bx4j 1/1 Running 0 68s
node-exports-ds-mdm2s 1/1 Running 0 68s
4.检查Pod中使用的镜像是否更新为新版本
[root@master ~]# kubectl get pod node-exports-ds-8bx4j -o yam
containers:
- image: prom/node-exporter:v1.3.1
十三. job
13.1 job控制器特性
Job 控制器常用于管理那些运行一段时间就能够“完成” 的任务,例如离线数据分析,数据备份等,当任务完成后,由Job控制器将该Pod对象置于 Complete 完成状态,在完成一定时间后,当达到了用户指定的生存周期,由系统自动删除该任务。
如果,容器中的进程因 “错误” 而终止,则需要依赖 RestartPoticy配置来确定是否重启,如果是因为 节点故障造成 Pod意外终止的话,会被重新创建起来继续运行。
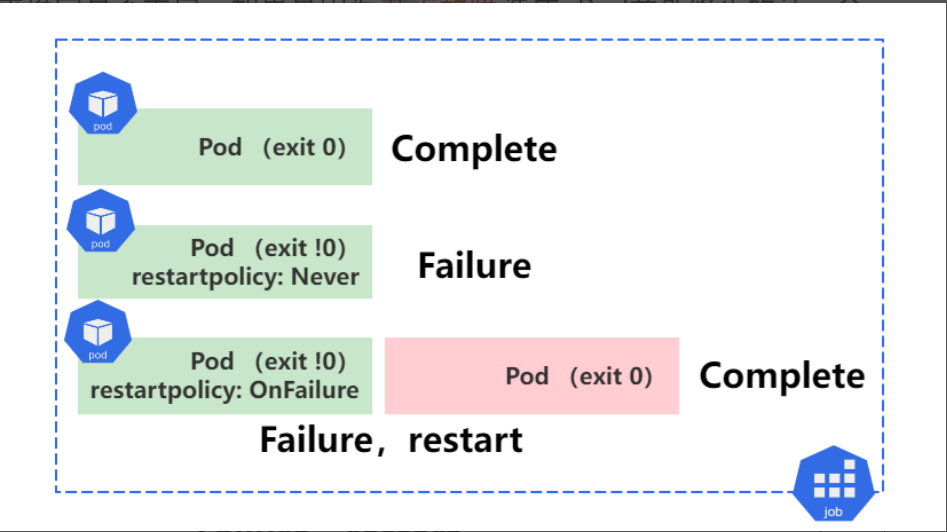
- 1、Pod执行,退出状态码为0,则表示执行成功,而后将该Pod状态置于Complete;
- 2、Pod执行,退出状态码为非0,检查restartpolicy为Never,表示永不重启,而后将该Pod状态置于Failure;
- 3、Pod执行,退出状态码为非0,检查restartpolicy为OnFailure表示退出状态码如果不为@时重启该Pod,所以会尝试重新拉取Pod,直到执行成功为止;
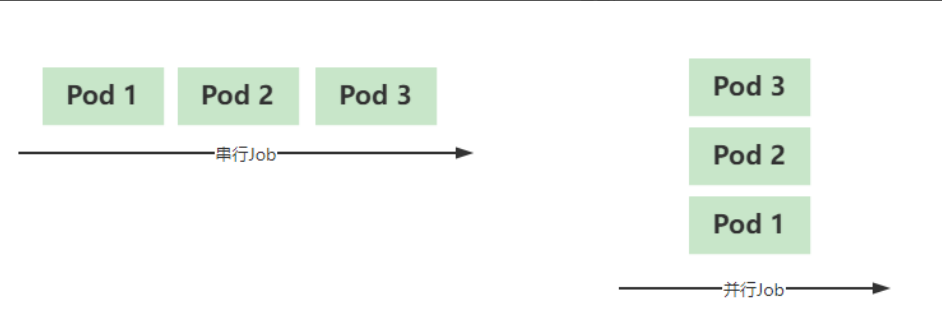
13.2 job工作方式
在实际生产环境中,有些任务可能需要运行不止一次,用户可以配置他们以串行或并行方式运行起来。
- 串行Job: 将一个作业串行执行多次直到满足期望的次数;
- 并行Job: 设定工作队列数,同时运行,而每个队列仅运行一个作业;
注意: 对于有严格次序要求的作业,只能选择串行执行,而没有严格次序要求的可以选择并行来提升运行的效率和速度;
13.3 job基础资源
apiVersion: batch/v1 # API群组及版本
kind: Job # 资源类型
metadata:
name: <string> # 源名称
namespace: <string> # 名称空间
spec:
selector: <0bject> # 标签选择器
completions: <integer> # 期望成功完成作业的次数
parallelism: <integer> # 作业的最大并行度,默认为1
backoffLimit: <integer> # 将作业标记为Failed之前的重试次数,默认为6
activeDeadlineSeconds: <integer> # 作业启动后可处于活动状态的时长,超出则会被标记为Faited
ttlSecondsAfterFinished: <integer> # 作业的最大生存时长,超期将被删除,@表示立即删除
template: <0bject> # Pod模板
spec: <Object>
container: <0bject> # Pod容器详情
restartpolicy: <string> #Pod重启策略,默认的ALways并不适应,因此必须单独指定
13.4 job示例代码
[root@master job]# cat job-demo.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: job-demo
spec:
completions: 5 # 需要成功运行5次
parallelism: 1 # 并行执行为1
backoffLimit: 2 # 失败后,允许重试 2 次
activeDeadlineSeconds: 120 # 总活跃时间为120s,包含运行Pod时间+异常重试次数时间
ttlSecondsAfterFinished: 100 # Job-demo在结束100秒之后,会被系统自动删除 (无论执行成功或失败)
template:
spec:
containers:
- name: myjob
image: alpine:latest
command: ["/bin/sh","-c","sleep 3"]
restartPolicy: OnFailure
十四. job实践
本例中,我们会运行包含多个并行工作进程的 Kubernetes Job。文档
本例中,每个Pod一旦被创建,会立即从任务队列中取走一个消息,然后将消息从队列中删除并退出本次任务
下面是本次示例的主要步骤:
- 1、启动一个消息队列服务: 我们使用 RabbitMQ。
- 2、创建一个队列,放上消息数据: 每个消息表示一个要执行的任务。
- 3、启动一个Job,该Job启动多个 Pod : 每个Pod从消息队列中取走一个任务,处理它,然后重复执行,直到队列的队尾。
14.1 创建Rabbitmq服务
1.部署rabbitmq消息队列服务
cat rabbitmq-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: rabbitmq-controller
spec:
replicas: 1
selector:
matchLabels:
app: mq
template:
metadata:
labels:
app: mq
spec:
containers:
- name: rabbitmq-server
image: rabbitmq
ports:
- containerPort: 5672
resources:
limits:
cpu: 100m
2.部署service,使得集群内Pod可以通过servicename访问该服务
[root@master ~]# cat rabbitmg-service.yaml
apiVersion: v1
kind: Service
metadata:
name: rabbitmq-service
spec:
selector:
app: mq
ports:
- port: 5672
14.2 消息发布者User
1.启动临时容器测试
# 启动ubuntu18:04镜像,然后安装一些工具
[root@master ~]# kubectl run -i --tty temp --imageubuntu:18 .04
[root@temp-Loe07:/# apt-get update
[root@temp-loe07:/# apt-get install -y curl ca-certificates amqp-tools python dnsutils
# 如果觉得安装过于耗时,可以启动我已安装好工具的镜像
[root@master ~]# kubectl run -i --tty temp --image oldxu3957/mgtoos:latest
2.验证rabbitmg服务
# rabbitmg-service 可以通过dns解析到对应的serviceIP
[root@temp-loe07:/# export BROKER_URL=amqp://guest:guest@rabbitmq-service:5672
# 创建队列:
[root@temp-Toe07:/# /usr/bin/amqp-declare-queue --url=$BROKER_URL -q foo
# 向它推送一条消息:
[root@temp-loe07:/# /usr/bin/amqp-publish --url=$BROKER_URL -r foo -p -b oldxu
# 然后取回它
[root@temp-loe07:/# /usr/bin/amgp-consume --url=$BROKER_URL -q foo -c 1 cat && echo
oldxu
3.为队列增加任务,创建一个job1的队列,然后给队列中填充了8个消息
export BROKER_URL=amqp://guest:guest@rabbitmq-service:5672
/usr/bin/amqp-declare-queue --urL=$BROKER_URL -q job1
for f in aa bb cc dd ee ff gg hh
do
/usr/bin/amqp-publish --url=$BROKER_URL -r job1 -p -b $f
done
14.3 消息订阅者(job)
现在我们可以创建镜像,获取数据,然后以Job方式运行起来。
14.3.1 编写获取队列程序
# 获取队列数据,然后等待10S,结束
[root@node1 work-queue]# cat worker.py
#!/usr/bin/env python
# Just prints standard out and sleeps for 10seconds .
import sys
import time
print("Processing "+ sys.stdin.readlines()[0])time.sleep(10)
14.3.2 编写Dockerfile
编写Dockerfile文件,制作为镜像,然后推送到自己的仓库; (注意镜像中需要传递的变量)
[root@node1 work-queue]# cat Dockerfile
# Specify BROKER_URL and QUEUE when running
FROM ubuntu:18.04
RUN apt-get update &&
apt-get install -y curl ca-certificates amqp-tools python --no-install-recommends && rm -rf /var/lib/apt/lists/*
COPY ./worker.py /worker.py
RUN chmod +x /worker.py
CMD /usr/bin/amqp-consume --urL=$BROKER_URL -q $QUEUE -c 1 /worker.py
14.3.3 编写Job任务
编写Job任务,每个 Pod 使用队列中的一个消息然后退出。这样,Job的完成计数就代表了完成的工作项的数量。
[root@master job]# cat rabbitmg-consumer.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: rabbitmg-consumer
spec:
completions: 8 # 总共运行8次,因为队列中有8条消息
parallelism: 2 # 并行执行2个任务
ttTSecondsAfterFinished: 100 # 结束后1000s删除
template:
spec:
containers:
- name : mq-consumer-work
image: oldxu3957/rabbit-mg-consumer-job
env:
- name: BROKER URL
value: amqp://guest:guest@rabbitmq-service:5672
- name: QUEUE
value : job1
restartPolicy: OnFailure
14.3.4 检查Job
[root@master job]#kubectl describe jobs rabbitmq-consumer
Name : rabbitmq-consumer
Namespace : default
Selector: controller-uid=efc03e23-cfcf-4197-9f5a-273962524b3a
Labels: controller-uid=efc03e23-cfcf-4197-9f5a-273962524b3a
job-name=rabbitmq-consumer
Annotations: <none>
Parallelism: 2
Completions: 8
Completion : Mode:NonIndexed
Start Time: Sat, 16 Apr 2022 20:04:22 +0800
Completed At: Sat, 16 Apr 2022 20:04:22 +0800
Duration: 50s
Pods Statuses: 0 Running / 8 Succeeded / 0 Failed
Pod Template:
Labels: controller-uid=efc03e23-cfcf-4197-9f5a-273962524b3a
job-name=rabbitmg-consumer
Containers:
mg-consumer-work:
Image: registry.cn-huhehaote.aliyuncs.com/oldxu3957/rabbit-mq-consumerjob
Port: <none>
Host Port: <none>
Environment:
BROKER_URL: amqp://guest:guest@rabbitmq-service:5672
QUEUE: job1
Mounts: <none>
Volumes: <none>
Events:
Type Reason Age From Message
------------------------------------------------------------------------------------
SuccessfulCreate 2m4s job-controllerNormaTCreated pod: rabbitmg-consumer--1-vk2c9Normal SuccessfulCreate 2m4s job-controllerCreated pod: rabbitmg-consumer--1-b78f8
Normal SuccessfulCreate 112s job-controllerCreated pod: rabbitmg-consumer--1-9mxc4
Normal SuccessfulCreate 112s job-controllerCreated pod: rabbitmg-consumer--1-s4sz5
Normal SuccessfulCreate 99s job-controllerCreated pod: rabbitmg-consumer--1-5nxb9
Normal SuccessfulCreate 98s job-controllerCreated pod: rabbitmg-consumer--1-bf9xs
14.3.5 检查Pod
# 通过检查Pod的Logs,可以看到消息被取走了
[root@master job]# kubectl logs rabbitmg-consumer--1-28pkc
Processing aa
[root@master job]# kubectl logs rabbitmq-consumer-1-5nxb9
Processing ff
[root@master job]# kubectl logs rabbitmq-consumer--1-8tk9j
xuliang
Processing dd
......
14.3.6 注意事项
如果设置的完成数量小于队列中的消息数量,会导致一部分消息项不会被执行。
如果设置的完成数量大于队列中的消息数量,当队列中所有的消息都处理完成后, Job 也会显示为未完成。Job 将创建 Pod 并阻塞等待消息输入。
当发生下面两种情况时,即使队列中所有的消息都处理完了,Job 也不会显示为完成状态:
- 在 amqp-consume 命令拿到消息和容器成功退出之间的时间段内,执行杀死容器操作;
- 在 kubelet 向 api-server 传回 Pod 成功运行之前,发生节点崩
