

③.kubernetes service
一.Service的概念
二.Kube-Proxy代理模型
三.Service资源类型
四.Service应用实践
五.Service与Endpoint
六.Service相关字段
-
6.1 sessionAffinity
-
6.2 externalTrafficPolicy
-
6.3 internalTrafficPolicy
-
6.4 publishNotReadyAddresses
七.Service深入理解
八.服务发现
九.HeadLess Service
============================================================================
一 Service的概念
1.1 什么是Service
运行在Pod中的应用是向客户端提供服务的守护进程,比如,nginx、tomcat、etcd等等,它们都是受控于控制器的资源对象,存在生命周期,我们知道Pod资源对象在自愿或非自愿终端后,只能被重构的Pod对象所替代,属于不可再生类组件。而在动态和弹性的管理模式下,Service 为该类Pod对象提供了一个固定、统一的访问接口和负载均衡能力。是不是觉得一堆话都没听明白呢????
其实,就是说Pod存在生命周期,有销毁,有重建,无法提供一个固定的访问接口给客户端。并且为了同类的Pod都能够实现工作负载的价值,由此Service资源出现了,可以为一类Pod资源对象提供一个固定的访问接口和负载均衡,类似于阿里云的负载均衡或者是LVS的功能。
但是要知道的是,Service和Pod对象的IP地址,一个是虚拟地址,一个是Pod IP地址,都仅仅在集群内部可以进行访问,无法接入集群外部流量。而为了解决该类问题的办法可以是在单一的节点上做端口暴露(hostPort)以及让Pod资源共享工作节点的网络名称空间(hostNetwork)以外,还可以使用NodePort或者是LoadBalancer类型的Service资源,或者是有7层负载均衡能力的Ingress资源。
Service是Kubernetes的核心资源类型之一,Service资源基于标签选择器将一组Pod定义成一个逻辑组合,并通过自己的IP地址和端口调度代理请求到组内的Pod对象,如下图所示,它向客户端隐藏了真是的,处理用户请求的Pod资源,使得从客户端上看,就像是由Service直接处理并响应一样,是不是很像负载均衡器呢!
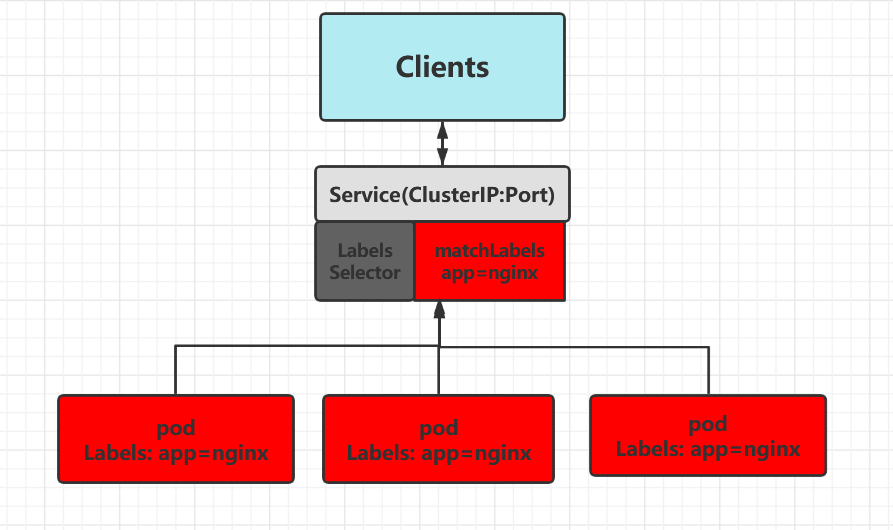
Service的作用:
- 暴露流量: 让用户可以通过ServiceIP+ServicePort访问对应后端的Pod应用;
- 负载均衡: 提供基于4层的TCP/IP负载均衡,并不提供HTTP/HTTPS等负载均衡;
- 服务发现: 当发现新增Pod则自动加入至Service的后端,如发现Pod异常则自动从Service后端删除Pod的IP
Service对象的IP地址也称为Cluster IP,它位于为Kubernetes集群配置指定专用的IP地址范围之内,是一种虚拟的IP地址,它在Service对象创建之后保持不变,并且能够被同一集群中的Pod资源所访问。Service端口用于接受客户端请求,并将请求转发至后端的Pod应用的相应端口,这样的代理机制,也称为端口代理,它是基于TCP/IP 协议栈的传输层。
1.2 Service工作逻辑
Service持续监视APIServer,监视Service标签选择器所匹配的后端Pod,并实时跟踪这些Pod对象的变动情况,例如ip地址发生变化,或Pod对象新增与减少。
不过service并不直接与Pod建立关联关系,它们之间还有一个中间层Endpoints,Endpoints对象是一个有IP地址和端口组成的列表,这些IP地址和端口则来自于service标签选择器所匹配到的Pod,默认情况下,常见Service资源时,其关联的Endpoints对象会被自动创建。
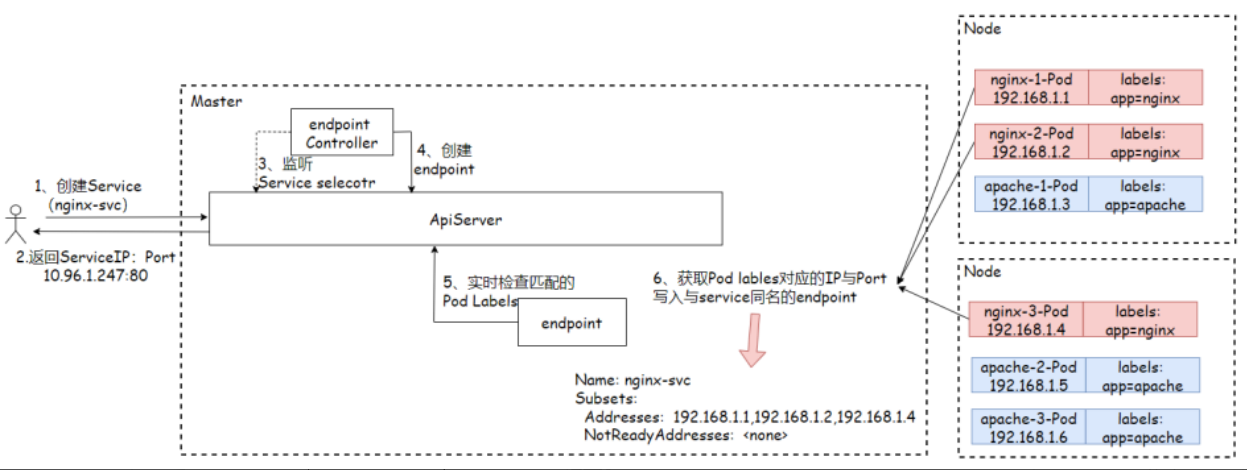
1.3 Service具体实现
在Kubernetes中,Service只是抽象的一个概念,真正起作用实现负载均衡规则的其实是Kube-Proxy这个进程。它在每一个节点上都需要运行一个Kube-Proxy,用来完成负载均衡规则的创建。
- 1.创建Service资源后,会分配一个随机的ServiceIP,返回给用户,然后写入etcd;
- 2.endpoints-controller负责生成和维护所有endpoints,它会监听Service和Pod的状态,当Pod处于running且准备就绪时,endpoints-controller会将Pod IP更新对应Service的endpoints对象中,然后写入Etcd;
- 3.kube-proxy通过API-Server监听Service,Endpoints的资源变动,一旦Service或Endpoints资源发生变化,kube-proxy会将最新的信息转换为对应的iptables,ipvs访问规则,而后在本地主机上执行;
- 4.当客户端范文Service时,会经由iptables,ipvs规则,路由到对应节点;
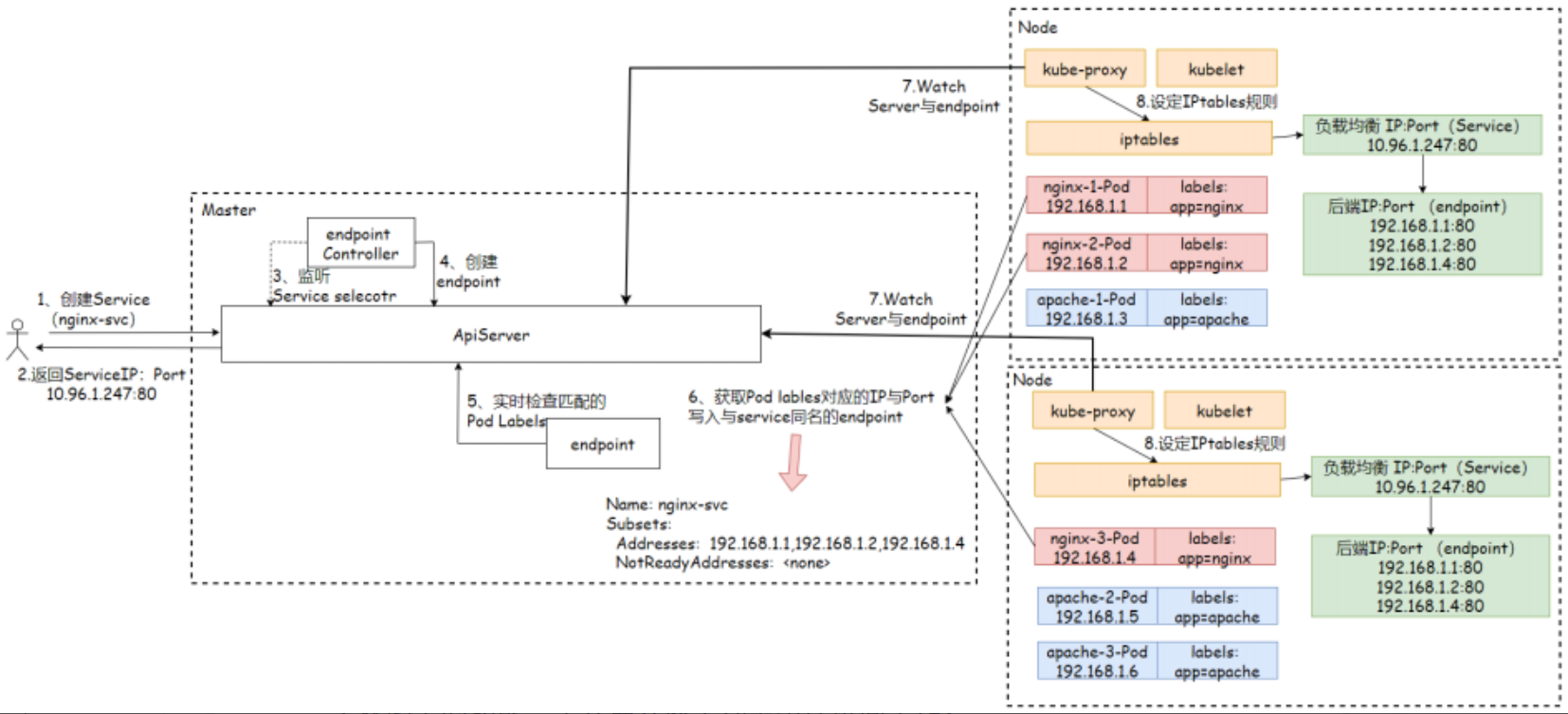
- Service:用户通过kubectl命令向APIServer发送创建Service的请求,APIServer收到后存入Etcd;
- Endpoints: 获取Servcie所有匹配的Pod地址,而后将信息写入与Service同名的endpoints资源中;
- kube-proxy: 获取service和endpoints资源的变动,而后生成iptables,ipvs规则,在本机执行;
- Iptables: 当用户请求ServiceIP时,使用iptables的DNAT技术将ServiceIP的请求调度之endpoint保存ip列表;
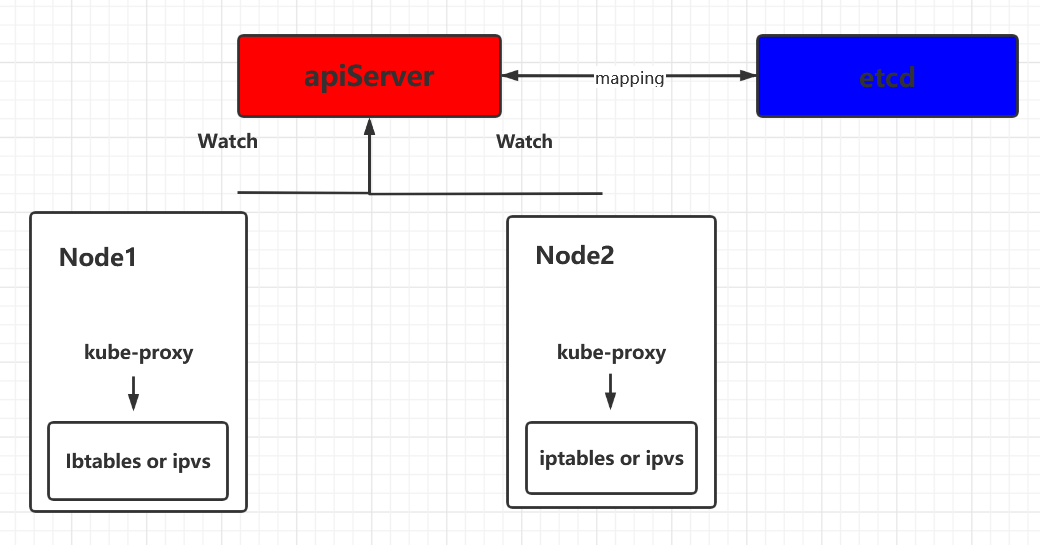
二. kube-proxy实现模型
在 Kubernetes 集群中,每个 Node 运行一个 kube-proxy 进程。kube-proxy 负责为 Service 实现了一种 VIP(虚拟 IP)的形式,而不是 ExternalName 的形式。 在 Kubernetes v1.0 版本,代理完全在 userspace。在 Kubernetes v1.1 版本,新增了 iptables 代理,但并不是默认的运行模式。 从 Kubernetes v1.2 起,默认就是 iptables 代理。在Kubernetes v1.8.0-beta.0中,添加了ipvs代理。在 Kubernetes v1.0 版本,Service 是 “4层”(TCP/UDP over IP)概念。 在 Kubernetes v1.1 版本,新增了 Ingress API(beta 版),用来表示 “7层”(HTTP)服务。
kube-proxy 这个组件始终监视着apiserver中有关Service的变动信息,获取任何一个与Service资源相关的变动状态,通过watch监视,一旦有Service资源相关的变动和创建,kube-proxy都要转换为当前节点上的能够实现资源调度规则(例如:iptables、ipvs)
kube-proxy工作原理
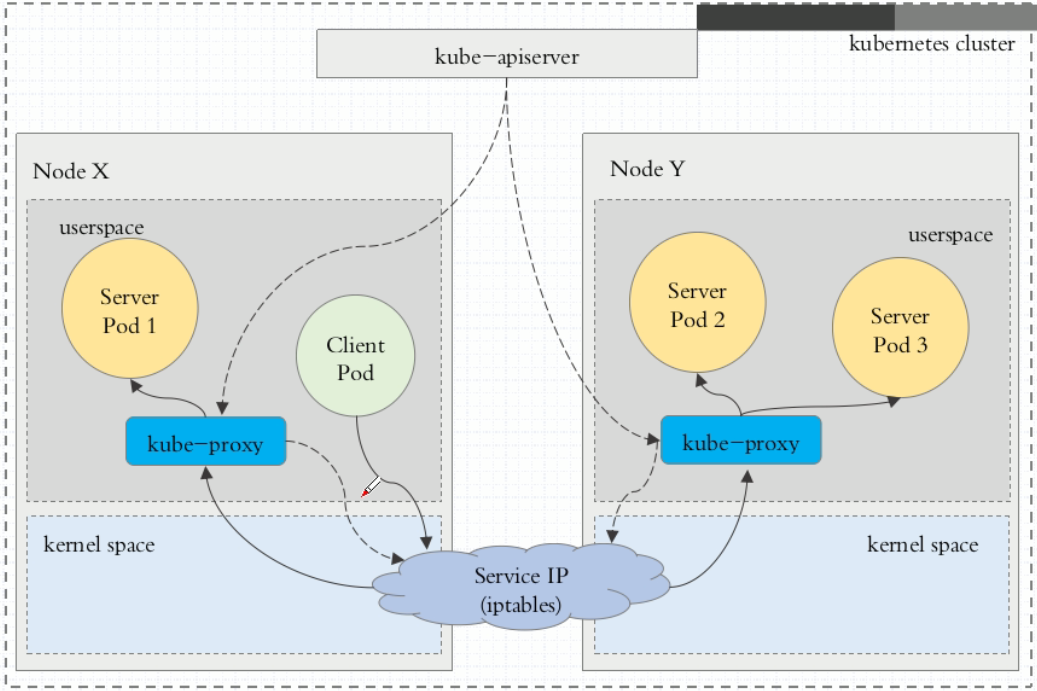
2.1、userspace代理模式
这种模式,当客户端Pod请求内核空间的Service iptables后,把请求转到给用户空间监听的kube-proxy 的端口,由kube-proxy来处理后,再由kube-proxy将请求转给内核空间的 Service ip,再由Service iptalbes根据请求转给各节点中的的Service pod。
由此可见这个模式有很大的问题,由客户端请求先进入内核空间的,又进去用户空间访问kube-proxy,由kube-proxy封装完成后再进去内核空间的iptables,再根据iptables的规则分发给各节点的用户空间的pod。这样流量从用户空间进出内核带来的性能损耗是不可接受的。在Kubernetes 1.1版本之前,userspace是默认的代理模型。
2.2、iptables代理模式
iptables模式下,kube-proxy为service后端的所有pod创建对应的iptables规则,当用户向serviceio发送请求
- 1.首先iptables会拦截用户请求
- 2.然后直接将请求调度到后端的Pod
总结:Pod请求serviceIp时,Iptables将请求拦截并且直接完成调度,然后路由到对应的Pod,所以效率比userspace高
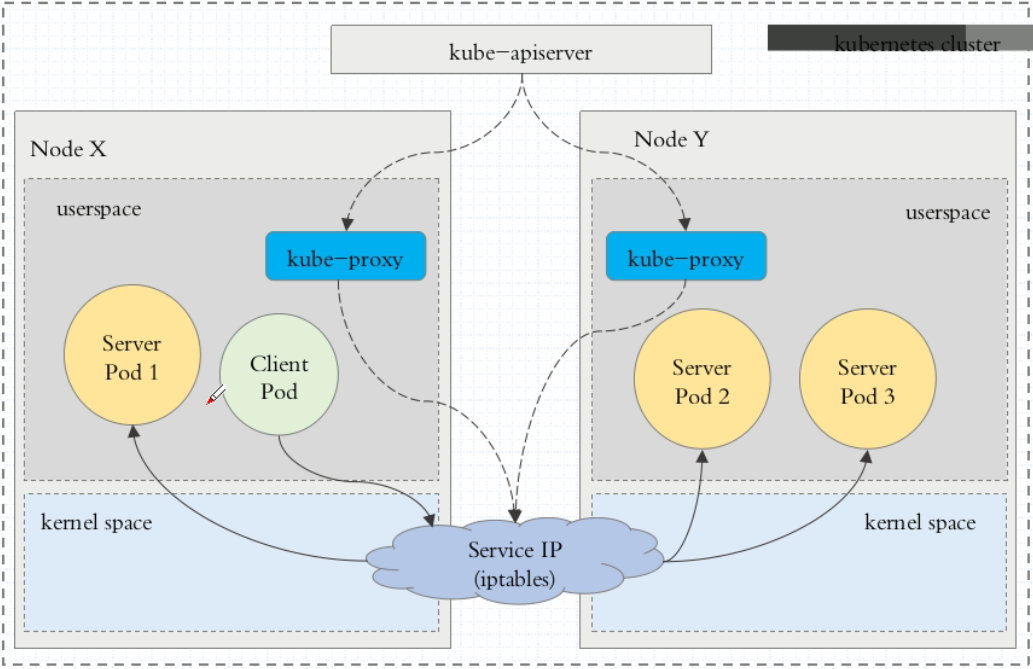
问题: 一个Service会创建出大量的规则,且不支持更高级的调度算法,当Pod不可用也无法重试
2.3、ipvs代理模式
Kubernetes自1.9-alpha版本引入了ipvs代理模式,自1.11版本开始成为默认设置。客户端IP请求时到达内核空间时,根据ipvs的规则直接分发到各pod上。kube-proxy会监视Kubernetes Service对象和Endpoints,调用netlink接口以相应地创建ipvs规则并定期与Kubernetes Service对象和Endpoints对象同步ipvs规则,以确保ipvs状态与期望一致。访问服务时,流量将被重定向到其中一个后端Pod。
与iptables类似,ipvs基于netfilter 的 hook 功能,但使用哈希表作为底层数据结构并在内核空间中工作。这意味着ipvs可以更快地重定向流量,并且在同步代理规则时具有更好的性能。此外,ipvs为负载均衡算法提供了更多选项,例如:
rr:轮询调度
lc:最小连接数
dh:目标哈希
sh:源哈希
sed:最短期望延迟
nq:不排队调度
注意: ipvs模式假定在运行kube-proxy之前在节点上都已经安装了IPVS内核模块。当kube-proxy以ipvs代理模式启动时,kube-proxy将验证节点上是否安装了IPVS模块,如果未安装,则kube-proxy将回退到iptables代理模式。
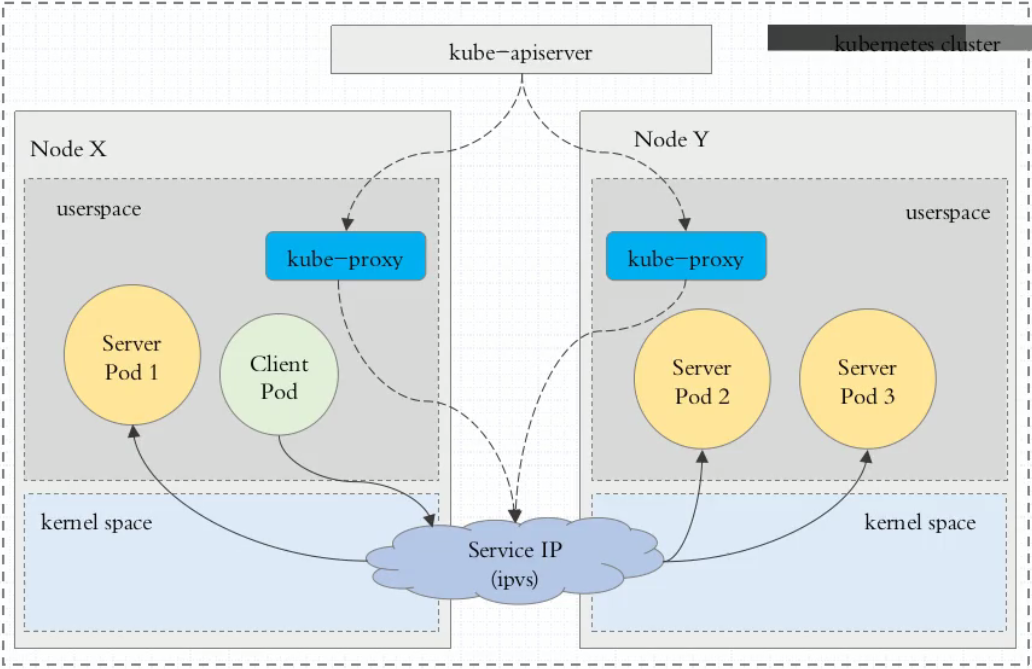
如果某个服务后端pod发生变化,标签选择器适应的pod有多一个,适应的信息会立即反映到apiserver上,而kube-proxy一定可以watch到etc中的信息变化,而将它立即转为ipvs或者iptables中的规则,这一切都是动态和实时的,删除一个pod也是同样的原理。如图:

三.Service资源类型
无论使用哪一种代理模型,Service资源分为一下四种类型 ClusterIP NodePort LoadBalance ExternalName
3.1 ClusterIP
CluserIP: 通过集群的内部IP暴露服务,选择ServiceIP只能在集群内部访问。这也是默认的ServiceType.
3.2 NodePort
NodePort; NodePort类型是对ClusterIP类型Service资源的扩展。它通过每个节点上的IP和端口接入集群外部流量,并分发给后端的Pod处理和响应。因此通过<节点IP>:<节点端口>,可以从集群外部访问服务。
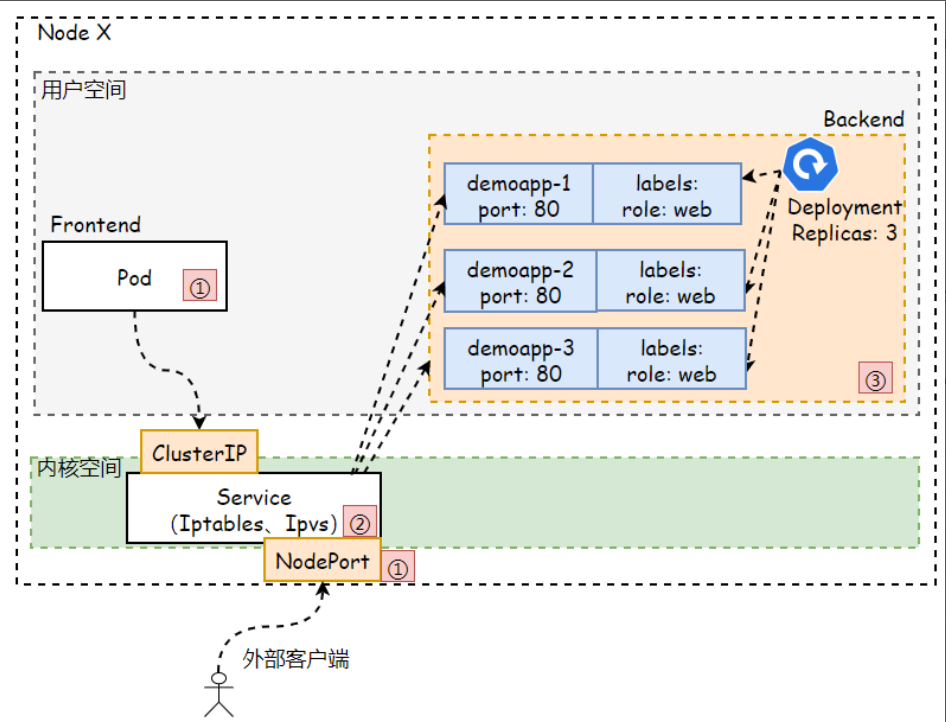
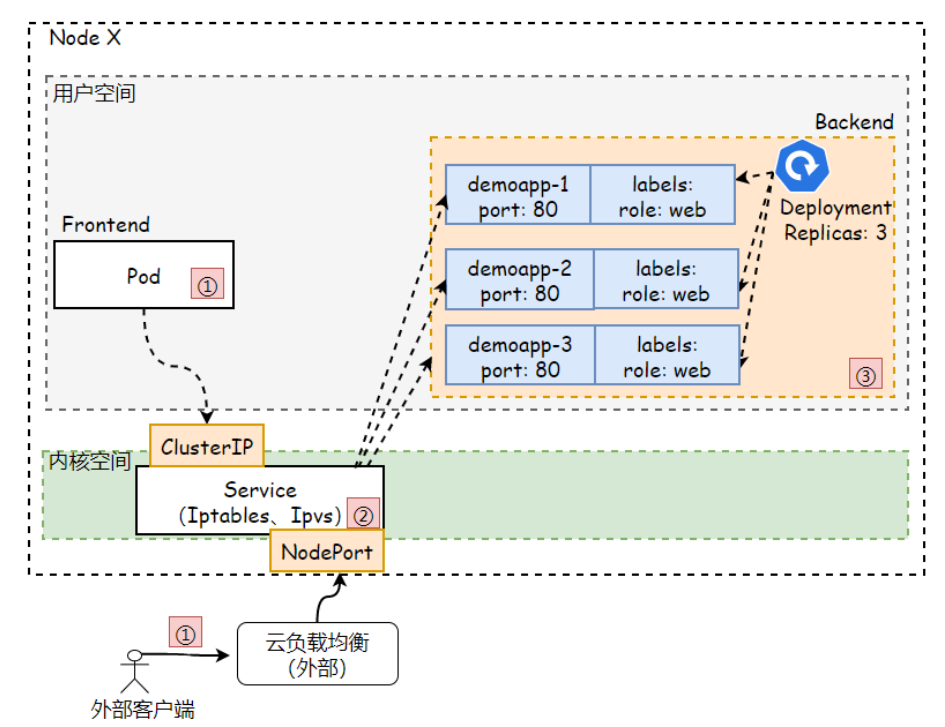
3.3 LoadBalance
LoadBalancer: 这类Service依赖云厂商,需要通过云厂商调用API接口创建软件负载均衡将服务暴露到集群外部。当创建LoadBalance类型的Service对象时,它会在集群上自动创建一个NodePort类型的Service。集群外部的请求流量会先路由至该负载均衡,并由该负载均衡调度至各个节点的NodePort。
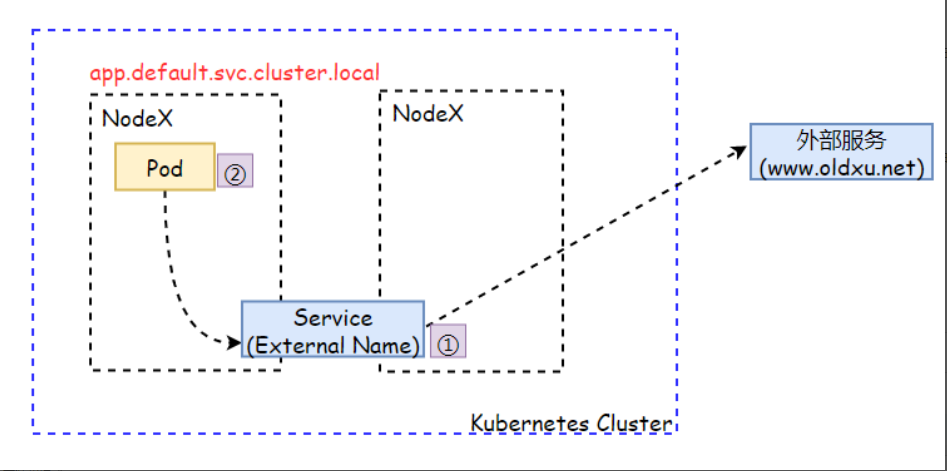
3.4 ExternalName
ExternalName: 此类型不是用来定义如何访问集群内服务的,而是把集群外部的某些服务以DNS CNAME方式映射到集群内,从而让集群内的Pod资源能够访问外部服务的一种实现方式
四.Service应用实践
4.1 Service配置示例
[root@master ~]# kubectl explain svc
KIND: Service
VERSION: v1
DESCRIPTION:
Service is a named abstraction of software service (for example, mysql)
consisting of local port (for example 3306) that the proxy listens on, and
the selector that determines which pods will answer requests sent through
the proxy.
FIELDS:
apiVersion <string>
APIVersion defines the versioned schema of this representation of an
object. Servers should convert recognized schemas to the latest internal
value, and may reject unrecognized values. More info:
https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#resources
kind <string>
Kind is a string value representing the REST resource this object
represents. Servers may infer this from the endpoint the client submits
requests to. Cannot be updated. In CamelCase. More info:
https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#types-kinds
metadata <Object>
Standard object's metadata. More info:
https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#metadata
spec <Object>
Spec defines the behavior of a service.
https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#spec-and-status
status <Object>
Most recently observed status of the service. Populated by the system.
Read-only. More info:
https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#spec-and-status
其中重要的4个字段:
apiVersion:
kind:
metadata:
spec:
clusterIP: 可以自定义,也可以动态分配
ports:(与后端容器端口关联)
selector:(关联到哪些pod资源上)
type:服务类型
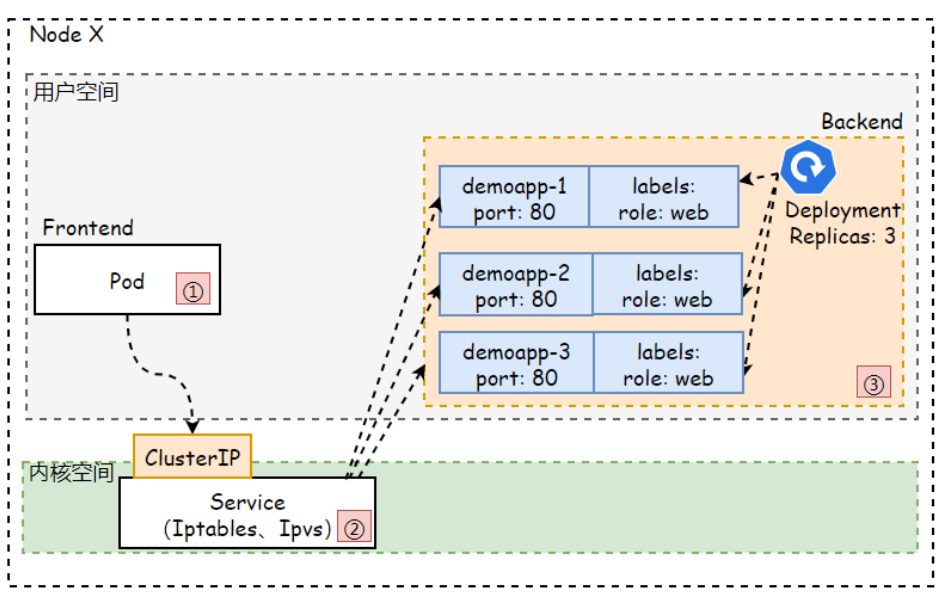
4.2 ClusterIP实践
1.使用deployment运行多个副本的web应用
2.使用service提供web应用负载均衡
3.使用Pod或Node访问Service的ClusterIP及端口,验证负载均衡
1.编写yaml
cat demoapp-service.yaml
apiVersion: v1
kind: Service
metadata:
name: demoapp-svc
spec:
selector:
role: web
#clusterIP: 10.96.1.1 # 自定指定IP,建议还是由Service自行分配
ports:
- protocol: TCP
port: 8888
targetPort: 80
#deploy部署多副本demoapp应用
cat demoapp-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: demoapp
spec:
replicas: 3
selector:
matchLabels:
role: web
template:
metadata:
labels:
role: web
spec:
containers:
- name: demoapp-container
image: oldxu3957/demoapp:v1.0
ports:
- name: http
containerPort: 80
2.描述Service对象自身的端口与目标后端口的映射关系
[root@master service]# kubectl describe service demoapp-svc
Name: demoapp-svc
Namespace: default
Labels: <none>
Annotations: <none>
Selector: role=web
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.96.145.78
IPs: 10.96.145.78
Port: <unset> 8888/TCP
TargetPort: 80/TCP
Endpoints: 192.168.2.65:80, 192.168.1.138:80, 192.168.1.137:80
Session Affinity: None
Events: <none>
3.访问ServiceIP,默认采用iptables模式,因此取样次数越多,其调度效果越好;
[root@master ~]# while true; do curl 10.96.145.78:8888/version; done
demoapp v1.!! PodIP: 192.168.2.65!
demoapp v1.0!! PodIP: 192.168.2.65!
demoapp v1.0!! PodIP: 192.168.1.138!
demoapp v1.0!! PodIp: 192.168.2.65!
demoapp v1.0!! PodIP: 192.168.1.138!
demoapp v1.0!! PodIP: 192.168.1.137!
demoapp v1.0!! PodIP: 192.168.1.138!
demoapp v1.0!! PodIP: 192.168.1.137!
4.如果Pod新增,则会自动加入Service的负载均衡,如果Pod删减,则会自动从负载均衡中移除;
4.3 NodePort实践
1.使用deployment运行多个副本的web应用。
2.使用service提供web应用负载均衡。
3.使用集群外部客户端,访问任意Node节点的IP+端口,验证负载均衡
1.编写yaml
cat demoapp-service-nodeport.yaml
apiVersion: v1
kind: Service
metadata:
name: demoapp-svc-nodeport
spec:
type: NodePort
selector:
role: web
ports:
- protocol: TCP
port: 8888
targetPort: 80
nodePort: 32000
2.描述Service对象自身的端口与目标后端端口的映射关系
kubectl describe service demoapp-svc-nodeport
Name: demoapp-svc-nodeport
Namespace: default
Labels: <none>
Annotations: <none>
Selector: role=web
Type: NodePort
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.96.145.78
IPs: 10.96.145.78
Port: <unset> 8888/TCP
TargetPort: 80/TCP
NodePort: 32000/TCP
Endpoints: 192.168.2.65:80, 192.168.1.138:80, 192.168.1.137:80
Session Affinity: None
External Traffic Policy: Cluster
Events: <none>
3.通过节点IP+节点端口访问服务,默认还是使用的iptables代理模式,因此取样次数越多,其调度效果越好;
[root@master ~]# while true; do curl http://10.0.0.201:32000/version;done
demoapp v1.0!! PodIP: 192.168.2.65!
demoapp v1.0!! PodIP: 192.168.2.65!
demoapp v1.0!! PodIP: 192.168.1.137!
demoapp v1.0!! PodIP: 192.168.1.137!
demoapp v1.0!! PodIP: 192.168.1.138!
demoapp v1.0!! PodIP: 192.168.1.138!
NodePort类型的Service会对请求报文同时进行源地址替换SNAT和目标地址替换DNAT;
4.4 ExternalName实践
当查询主机 my-service.default.svc.cluster.Local 时,集群的DNS服务将返回一个值为 docs.xuliangwei.com 的 CNAME 记录访问这个服务的工作方式与其它的相同,唯一不同的是重定向发生在DNS 层面。
1.编写yaml文件
cat my-service.yaml
kind: Service
apiVersion: v1
metadata:
name: my-service
namespace: prod
spec:
type: ExternalName
externalName: docs.xuliangwei.com
2.检查Service
[root@master ~]# kubectl get service
NAME TYPE CLUSTER-IP PORT(S) AGE
my-service ExternalName <none> <none> 45s
3.通过dig,然后使用集群CoreDNS测试域名解析;
[root@master ~]# dig myservice.default.svc.cluster.local @10.96.0.10 +short docs.xuliangwei.com
39.104.16.126
五.Service与Endpoint
5.1 Endpoint与容器探针
Service对象借助endpoint资源来跟踪其关联的后端端点,endpoint对象会更具service标签选择器筛选出的后端端点的IP地址分别保存在subsets.address字段和subsets.notReadyAddress字段中,它通过APIServer持续,动态跟踪每个端点的状态变化,并即使反应到端点IP所属的字段中。
- subsets.address: 保存就绪的Pod IP,也就意味着service可以直接将请求调度至该地址段。
- subsets.notReadyAddress: 保存未就绪容器IP,也就意味着Service不会将请求调度至该地址段。
1.创建一个资源清单,会自动创建出同名的endpoints对象
#先创建service,而后同时创建deployment
cat demoapp-readiness.yaml
apiVersion: v1
kind: Service
metadata:
name: demoapp-readiness-service
spec:
selector:
role: web-readiness
ports:
- protocol: TCP
port: 8888
targetPort: 80
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: demoapp2
spec:
replicas: 2
selector:
matchLabels:
role: web-readiness
template:
metadata:
labels:
role: web-readiness
spec:
containers:
- name: demoapp2
image: oldxu3957/demoapp:v1.0
readinessProbe:
httpGet:
path: "/readyz"
port: 80
initialDelaySeconds: 15 #初始化检测延长时长
periodSeconds: 10 #检测周期
2.容器初次启动延迟15s,也就意味着至少15s以后才能转换为就绪状态,对外提供服务
[root@k8s-240 service]# kubectl get ep demoapp-readiness-service -o wide
NAME ENDPOINTS AGE
demoapp-readiness-service 10.244.157.181:80,10.244.232.236:80 4m4s
3.因任何原因导致后端的端点就绪状态检测失败,都会出发endpoint对象将该端点的IP地址从subset.address字段一直subsets.netReadyAddress字段
#模拟一个Pod故障
[root@k8s-240 service]# curl -s -X POST -d 'readyz=Err' 10.244.232.236/readyz
#大约等待30s之后再检查endpoints资源
[root@k8s-240 service]# kubectl describe ep demoapp-readiness-service
Name: demoapp-readiness-service
Namespace: default
Labels: <none>
Annotations: endpoints.kubernetes.io/last-change-trigger-time: 2023-06-08T02:55:07Z
Subsets:
Addresses: 10.244.157.181
NotReadyAddresses: 10.244.232.236
Ports:
Name Port Protocol
---- ---- --------
<unset> 80 TCP
Events: <none>
[root@k8s-240 service]# kubectl get ep demoapp-readiness-service -o wide
NAME ENDPOINTS AGE
demoapp-readiness-service 10.244.157.181:80 8m17s
4.将故障端点重新转为就绪状态后,Endpoints对象会将其移回subsets.address字段,这种处理机制确保了Service对象不会将客户端请求流量调度给那些处于 运行状态但服务未就绪 的端点。
#恢复故障
[root@k8s-240 service]# curl -s -X POST -d 'readyz=OK' 10.244.232.236/readyz
#查看endpoints
[root@k8s-240 service]# kubectl describe ep demoapp-readiness-service
Name: demoapp-readiness-service
Namespace: default
Labels: <none>
Annotations: endpoints.kubernetes.io/last-change-trigger-time: 2023-06-08T02:57:30Z
Subsets:
Addresses: 10.244.157.181,10.244.232.236
NotReadyAddresses: <none>
Ports:
Name Port Protocol
---- ---- --------
<unset> 80 TCP
Events: <none>
5.2 自定义endpoint实践
service通过selector和pod建立关联关系,k8s会更具service关联到的PodIP信息组合成一个endpoint,若service定义中没有selector字段,service被创建时,endpoint contorller不会自动创建endpoint。
我们可以通过配置清单创建Service,而无需使用标签选择器,而后自行创建一个同名的endpoint对象,指定对应的IP。这种一般用于将外部MYSQL\READIS等应用引入kubernetes集群内部,让通过Service的方式访问外部资源
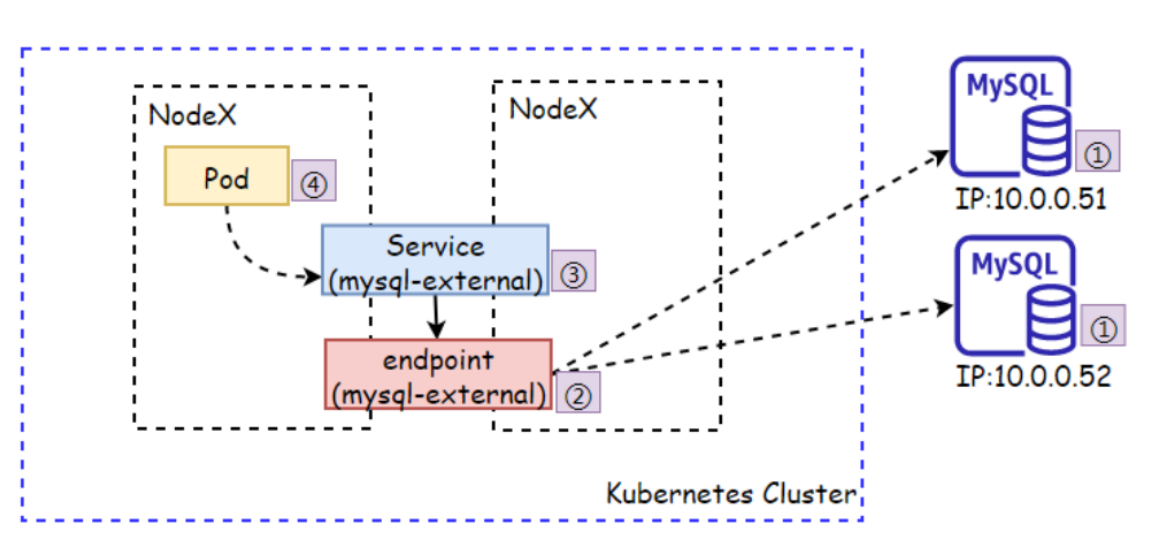
1.准备外部MySQL服务
[root@db ~]# yum install mariadb mariadb-server -y
[root@db ~]# systemctl enable mariadb --now
# 创建一个远程用户
[root@db ~]# mysgl
MariaDB [(none)]> grant all privileges on *.* to'oldxu' identified by 'oldxu3957';
MariaDB [(none)]> flush privileges;
2.创建endpoints资源清单
cat mysql-external-endpoint.yaml
apiVersion: v1
kind: Endpoints
metadata:
name: mysql-external
namespace: default
subsets:
- addresses:
- ip: 10.0.0.51
- ip: 10.0.0.52
ports:
- protocol: TCP
port: 3306
#检查endpoints
# 检查endpoints
[root@master ~]# kubectl get endpoints mysql-external
NAME ENDPOINTS AGE
mysql-external 10.0.0.51:3306,10.0.0.52:3306 29s
3.创建与enpoint同名的Service资源清单
cat mysql-external-service.yaml
apiVersion: v1
kind: Service
metadata:
name: mysql-external
namespace: default
spec:
type: ClusterIP
ports:
- protocol: TCP
port: 3366
targetPort: 3306
#检查Service
kubectl describe service mysql-external
Name: mysql-external
Namespace: default
Labels: <none>
Annotations: <none>
Selector: <none>
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: <none>
IPs: <none>
Port: <unset> 3366/TCP
TargetPort: 3306/TCP
Endpoints: 10.0.0.51:3306,10.0.0.52:3306
Session Affinity: None
Events: <none>
4.使用Pod访问Service,验证能否正常访问Mysql服务
# 启动一个mysql客户端
[root@master endpoint]# kubectl run tools --image=oldxu3957/tooTs
# 通过ServiceIP,或ServiceName (mysql-external) 都可以访问到外部数据库
[root@tools /]# mysql -h 10.96.176.225 -P 3366 -u oldxu -p oldxu3957
MariaDB [(none)]> create database hello_service;
MariaDB [(none)]> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| hello_service |
| mysql |
| performance_schema |
| sys |
+--------------------+
5 rows in set (0.00 sec)
六.Service相关字段
6.1 sessionAffinity
如果要将来自于特定客户端的来凝结调度至同一Pod,可以使用sessionAffinity 基于客户端的IP地址进行绘画保持。
还可以通过sessionAffinityConfig.clientIP.timeoutSeconds来设置最大绘画停留时间.(默认10800秒,即3小时)
1.编写yaml
cat session-service.yaml
apiVersion: v1
kind: Service
metadata:
name: session-svc
spec:
type: NodePort
selector:
role: web
ports:
- protocol: TCP
port: 80
targetPort: 80
sessionAffinity: ClientIP
sessionAffinityConfig:
clientIP:
timeoutSeconds: 60
2.测试能否实现会话保持
[root@master service]# curl 10.96.244.169/version
demoapp v1.0!! PodIP: 192.168.1.137!
[root@master service]# curl 10.96.244.169/version
demoapp v1.0!! PodIP: 192.168.1.137!
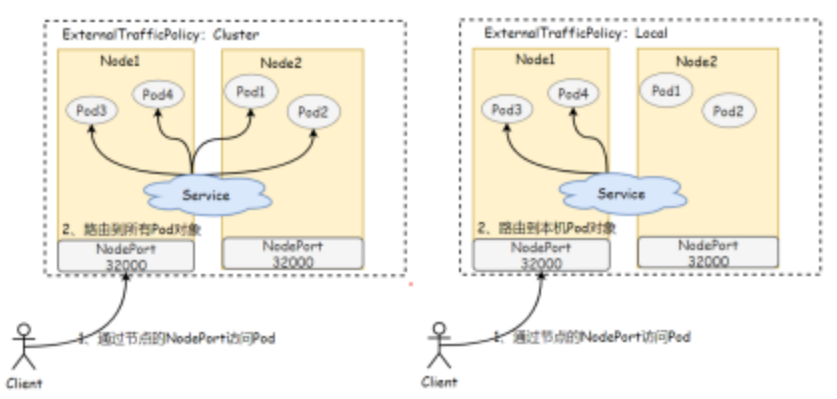
6.2 externalTrafficPolicy
外部流量策略: 当外部用户通过NodePort请求Service,是将外部流量路由到本地节点上的Pod,还是路由到集群范围的Pod:
- cluster (默认) : 将用户请求路由到集群范围的所有Pod节点,具有良好的整体负载均衡。
- Local: 仅会将流量调度至请求的目标节点本地运行的Pod对象之上,以减少网络跳跃,降低网络延迟,但当请求指向的节点本地不存在目标Service相关的Pod对象时直接丢弃该报文。
1.编写yaml
cat demoapp-service-external.yaml
apiVersion: v1
kind: Service
metadata:
name: demoapp-svc-external
spec:
selector:
app: demoapp
type: NodePort
ports:
- protocol: TCP
port: 80
targetPort: 80
nodePort: 32001
externalTrafficPolicy: Local
2.检查Service匹配的Pod,会发现在Node1节点运行了1个Pod,Node2运行了两个Pod
kubectl get pod -l app=demoapp -o wide
NAME READY STATUS RESTARTS AGE IP NODE
demoapp-6b8dcfb5b4-qsf521 1/1 Running 0 31m 192.168.1.141 node1
demoapp-6b8dcfb5b4-pm97s1 1/1 Running 0 31m 192.168.2.102 node2
demoapp-6b8dcfb5b4-sxw4w1 1/1 Running 0 31m 192.168.2.103 node2
3.访问Service对应的NodePort
# 访问Node1
[root@master service]# curl 10.0.0.204:32001/version
demoapp v1.0!! PodIP: 192.168.1.141!
[root@master service]# curl 10.0.0.204:32001/version
demoapp v1.0!! PodIP: 192.168.1.141!
# 访问Node2
[root@master service]# curl 10.0..212:32001/version
demoapp v1.0!! PodIP: 192.168.2.103!
[root@master service]# curl 10.0.0.212:32001/version
demoapp v1.0!! PodIP: 192.168.2.102!
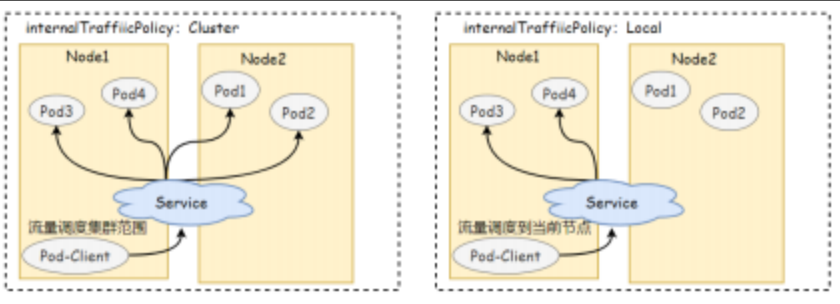
6.3 internalTrafficPolicy
本地流量策略:当本地Pod对Service发起访问时,是将流量路由到本地节点上的Pod,还是路由到集群范围的Pod:
- cluster (默认) : 将Pod的请求路由到集群范围的所有Pod节点具有良好的整体负载均衡。
- Local: 将请求路由到与发起方处于相同节点的端点,这种机制有助于节省开销,提升效率。但当请求指向的节点本地不存在目标Service相关的Pod对象时直接丢弃该报文。
注意: 在一个Service上,当externalTrafficPolicy 已设置为 Local 时,internalTrafficPolicy则无法使用。 换句话说在一个集群的不同 Service 上可以同时使用这两个特性,但在一个Service 上不行
1.编写yaml
cat demoapp-service-internal.yaml
apiVersion: v1
kind: Service
metadata:
name: demoapp-svc-internal
spec:
type: ClusterIP
selector:
app: demoapp
ports:
- protocol: TCP
port: 80
targetPort: 80
internalTrafficPolicy: Local #默认Cluster
2.运行两个Pod,获取Pod所在节点
kubectl run -it tools1 --image=oldxu3957/tools
kubectl run -it tools2 --image=oldxu3957/tools
kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE
demoapp-6b8dcfb5b4-pm97s 1/1 Running 0 70m 192.168.2.102 node2
demoapp-6b8dcfb5b4-qsf52 1/1 Running 0 70m 192.168.1.141 node1
demoapp-6b8dcfb5b4-sxw4w 1/1 Running 0 70m 192.168.2.103 node2
tools1 1/1 Running 0 70m 192.168.1.140 node1
tools2 1/1 Running 0 23m 192.168.2.104 node2
3.登录tools1容器和tools2容器访问service测试
# tooLs1容器
[root@master ~]# kubectl exec -it tools1 --/bin/bash
[roottools1 /]# curl 10.96.141.198/version
demoapp v1.0!! PodIP: 192.168.1.141!
[root@tools1 /]# curl 10.96.141.198/version
demoapp v1.0!! PodIP: 192.168.1.141!
# tooLs2容器
[root@master ~]# kubectl exec -it tools2 -- /bin/bash
[root@tools2 /]# curl 10.96.141.198/version
demoapp v1.0!! PodIP: 192.168.2.102!
[root@tools2 /]# curl 10.96.141.198/version
demoapp v1.0!! PodIP: 192.168.2.103!
6.4 publishNotReadyAddresses
publishNotReadyAddresses: 表示Pod就绪探针探测失败,也不会将失败的PodIP加入service的notReadyAddress列表中
1、检查当前Service对应的后端列表
kubectl describe endpoints demoapp-readiness-service
Name: demoapp-readiness-service
Namespace: default
Labels: <none>
Annotations: <none>
Subsets:
Addresses: <none>
NotReadyAddresses: 192.168.2.106,192.168.2.107
Ports:
Name: <unset>
Port: 80
Protocol: TCP
2.将其中的某个Pod设定为不就绪,看看是否会将该PodIP加入到NotReadAddress字段中
[root@master ~]# curl -s -X POST -d 'readyz=Err' 192.168.2.107/readyz
[root@master service]# kubectl describe endpoints demoapp-readiness-service
Name : demoapp-readiness-servicedefault
Namespace: default
Labels: <none>
Annotations: endpoints.kubernetes.io/last-change
trigger-time: 2022-05-31T13:58:09Z
Subsets:
Addresses: 192.168.2.106
NotReadyAddresses: 192.168.2.107
3、为对应的Service文件添加publishNotReadyAddresses: true字段
spec:
.....
publishNotReadyAddresses: true
.....
4.再次检查endpoints
[root@master service]# kubectl describe endpointsdemoapp-readiness-service
Name : demoapp-readiness-servicedefault
Namespace: default
Labels: <none>
Annotations: <none>
Subsets:
Addresses: 192.168.2.106,192.168.2.107
# 自动将不就绪的PodIP加入集群
七.Service深入理解
访问Service会出现如下4中情况
- 1、Pod-A --> Service --> 调度 --> Pod-B/Pod-C
- 2、Pod-A --> Service --> 调度 --> Pod-A
- 3、Docker --> Service --> 调度 --> Pod-B/Pod-C
- 4、NodePort --> Service --> 调度 --> Pod-B/Pod-C
7.1 Iptables模型分析
7.2 IPVS模型分析
八.服务发现
当Pod需要访问Service时,通过Service提供的ClusterIP就可以实现了,当时有几个问题
- 1.Service的IP不稳定,删除重建会发生变化
- 2.ServiceIP难以记忆,如果通过一个固定的名称访问就好
为了解决这样的问题,kubernetes引入环境变量和dns两种方案来解决这样的问题 - 1.环境变量方式: 通过特定的名称将环境变量注入到Pod内部
- 2.dns方式: 通过APISERVER来监视Service变动,而后动态创建对应Service名称与ServiceIP的域名解析记录
8.1 环境变量
每个 Pod 启动的时候,会通过环境变量的方式将Service的IP以及Port信息注入进去,这样 Pod 中的应用可以通过读取环境变量来获取对应Service服务的地址信息,这种方法使用起来相对简单,但是也存在一定的问题。就是Pod所依赖的Service必须优Pod启动,否则无法注入到环境变量中。
1.创建Service资源
[root@master ~]# cat env-service.yaml
apiVersion: v1
kind: Service
metadata:
name: my-demoapp
spec:
ports:
- port: 80
targetPort: 80
2.创建容器,然后验证对应的环境变量
[root@master ~]# kubectl run pod-env --image=oldxu3957/tools
[root@master ~]# kubectl exec -it pod-env -- /bin/bash
# 执行env拿到的环境变量内容
......
MY_DEMOAPP_SERVICE_HOST=10.96.141.198
MY_DEMOAPP_SERVICE_PORT=80
.......
8.2 CoreDNS
在安装Kubernetes集群时,CoreDNS作为附加组件,用来为Pod提供DNS域名解析。CoreDNS监视 Kubernetes API 中的新Service,并为每个Service名称创建一组 DNS 记录。这样我们就可以通过固定的Service名称来转换出不固定的ServiceIP
1.了解CoreDNS的配置
apiVersion: v1
kind: ConfigMap
data:
Corefile: |
.:53 {
errors # 错误记录
health { # 健康检查
lameduck 5s
}
ready
kubernetes cluster.local in-addr.arpa ip6.arpa { # 用于解析Kubernetes集群内域名
pods insecure
fallthrough in-addr.arpa ip6.arpa
ttl 30
}
prometheus :9153 # 监控的端口
forward . /etc/resolv.conf { # 如果请求非Kubernetes域名,则由节点的resolv.conf中dns解析
max_concurrent 1000
}
cache 30 # 缓存所有内容
loop
reload # 支持热更新
loadbalance # 负载均衡,默认轮询
}
2、CoreDNS只所以是固定的IP以及固定的搜索域。是因为kubelet将--cluster-dns=
[root@master ~]# cat /var/lib/kubelet/config.yaml
........
clusterDNS:
- 10.96.0.10
# DNS的固定ServiceIP
clusterDomain: cluster.local # 域名
.....
3、进入任意Pod中,验证/etc/resolv.conf以及域名解析
[root@master dns]# kubectl exec -it tools -- /bin/bash
[root@tools /]# cat /etc/resolv.conf
nameserver 10.96.0.10
search default.svc.cluster.local svc.cluster.localcluster.local
options ndots:5
# 通过域名解析对应的ServiceIP
[root@tools /]# dig @10.96.0.10 my-demoapp .default.svc.cluster.local +short
10.96.234.27
8.3 CoreDNS策略
DNS策略可以单独对Pod进行设定,在创建Pod时可以为其指定DNS的策略,最终配置会落在Pod的/etc/resolv.conf文件中,可以通过Pod.spec.dnsPolicy字段设置DNS的策略。
1.ClusterFirst(默认DNS策略)
表示Pod内的DNS使用集群中配置的DNS服务,简单来说就是使用Kubernetes中的coredns服务进行域名解析,如果解析不成功,会使用当前Pod所在的宿主机dns进行解析
[root@master dns]# cat dns-example-1.yaml
apiVersion: v1
kind: Pod
metadata :
name: dns-example-1
spec:
dnsPolicy: ClusterFirst
containers:
- name: tools
image: oldxu3957/tools
ports:
- containerPort: 8899
2、ClusterFirstWithHostNet
在某些场景下,我们的 Pod 是用 HostNetwork 模式启动的,一旦使用 HostNetwork 模式,那该Pod则会使用当前宿主机的/etc/resolv.conf 来进行 DNS 查询,但如果任然想继续使用Kubernetes 的DNS服务,那就将 dnsPolicy 设置为ClusterFirstWithHostNet.
[root@master dns]# cat dns-example-2.yaml
apiVersion: V1
kind: Pod
metadata:
name: dns-example-2
spec:
hostNetwork: true # 与节点共享网络
dnsPolicy: cLusterFirstWithHostNet # 如果没配置则使用当前Pod所在宿主机的DNS
containers:
- name: tools
image: oldxu3957/tools
ports:
- containerPort: 8899
3、Default
默认使用宿主机的 /etc/resolv.conf但可以使用 kubelet 的 --resoLv-conf=/etc/resolv.conf 来指定 DNS 解析文件地址。
4、None
空的DNS设置,这种方式一般用于自定义 DNS 配置的场景,往往需要和dnsConfig一起使用才可以达到自定义DNS的目的。
apiVersion: v1
kind: Pod
metadata :
name: dns-example-3
spec:
containers:
- name: tools
image: oldxu3957/tools
ports:
- containerPort: 8899
dnsPolicy: "None"
dnsConfig:
nameservers :
- 10.96.0.10
- 114.114.114.114
searches:
- cluster.local
- svc.cluster.local
- default .svc.cluster.local
- odxu.net
options:
- name: ndots
value: "5"
# 检查/etc/resolv.conf配置
[root@master ~]# kubectl exec -it dns-example-3 -- cat /etc/resolv.conf
nameserver 10.96.0.10
nameserver 114.114.114.114
search cluster.local svc.cluster.local
default.svc.cluster.local oldxu .net
options ndots:5
九.HeadLess Service
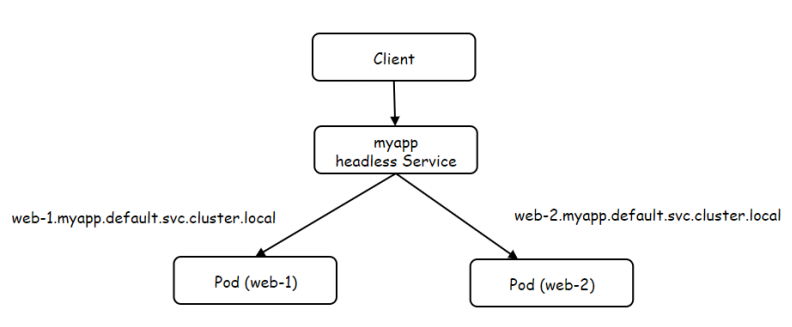
9.1 什么是HeadLess
HeadlessService也叫无头服务,就是创建的Service没有ClusterIP,而是为Service所匹配的每个Pod都创建一条DNS的解析记录,这样每个Pod都有一个唯一的DNS名称标识身份,访问的格式如下
$(service_name).$(namespace).svc.cluster.local
9.2 HeadLess的作用
像 elasticsearch,mongodb,kafka 等分布式服务,在做集群初始化时,配置文件中要写上集群中所有节点的IP(或是域名)但Pod是没有固定IP的,所以配置文件里写DNS名称是最合适的。
那为什么不用Service,因为 Service 作为 Pod 前置的负载均衡一般是为一组相同的后端 Pod 提供访问入口,而且 Service的seLector也没有办法区分同一组Pod的不同身份。
但是我们可以使用 Statefulset控制器,它在创建每个Pod的时候,能为每个 Pod 做一个编号,就是为了能区分这一组Pod的不同角色,各个节点的角色不会变得混乱,然后再创建 headless service 资源,集群内的节点通过Pod名称+序号。Service名称,来进行彼此间通信的只要序号不变,访问就不会出错。
当 statefulSet.spec.serviceName 配置与headless service相同时,可以通过 {hostName}.{theadless service}.{namespace}.svc.cluster.local 解析出节点IP。hostName 由{statefulSet name}-{编号} 组成。
{statefulSet name}-{编号].{headless service}{namespace}.svc.cluster.local
# 放在当前es中,对应的DNS子域名分别是
es-0.elastic.default.svc.cluster.local
es-1.elastic.default.svc.cluster.local
es-2.elastic.default.svc.cluster.local
9.3 HeadLess示例
1、创建HeadLess Service
[root@master dns]# cat headless.yaml
apiVersion: v1
kind: Service
metadata:
name: myapp
spec :
clusterIP: "None" #设置为None,表示无头服务
selector:
app: nginx
ports:
- port: 80
protocol: TCP
targetPort: 80
2、通过StatefulSet创建Pod
[root@master dns]# cat sts.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
serviceName: "myapp" #要与Headless名称保持一致
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.16
ports:
- containerPort:80
3.检查Pod
[root@master ~]# kubectl get pod -l app=nginx
NAME READYAGE STATUS RESTARTS AGE
web-0 1/1 Running 0 20s
web-1 1/1 Running 0 19s
4.测试域名解析
# 解析 headless service,会发现能解析出两个PodIP
[root@master ~]# dig @10.96.0.10
myapp .default.svc .cluster.Tocal +short
192.168.1.150
192.168.2.128
# 单独解析每一个pods的DNS域名
[root@master ~]# dig @10.96.0.10 web-0.myapp.default.svc.cluster.local +short
192.168.2.128
[root@master ~]# dig @10.96.0.10 web-1.myapp.default.svc.cluster.local +short
192.168.1.150
