

SparkStreaming(源码阅读十二)
要完整去学习spark源码是一件非常不容易的事情,但是咱可以积少成多嘛~那么,Spark Streaming是怎么搞的呢?
本质上,SparkStreaming接收实时输入数据流并将它们按批次划分,然后交给Spark引擎处理生成按照批次划分的结果流:

SparkStreaming提供了表示连续数据流的、高度抽象的被称为离散流的Dstream,可以使用kafka、Flume和Kiness这些数据源的输入数据流创建Dstream,也可以在其他Dstream上使用map、reduce、join、window等操作创建Dsteram。Dstream本质上呢,是表示RDD的序列。
Spark Streaming首先将数据切分为一定时间范围(Duration)的数据集,然后积累一批(Batch)Duration数据集后单独启动一个任务线程处理。Spark核心提供的从DAG重新调度任务和并行执行,能够快速完成数据从故障中恢复的工作。
那么下来就从SparkStreaming 的StreamingContext初始化开始:
StreamingContext传入的参数:1、SparkContext也就是说Spark Streaming的最终处理实际是交给SparkContext。2、Checkpoint:检查点.3、Duration:设定streaming每个批次的积累时间。当然,也可以不用设置检查点。

Dstream是Spark Streaming中所有数据流的抽象,这里对抽象类Dstream定义的一些主要方法:
1、dependencies:Dstream依赖的父级Dstream列表。
2、comput(validTime:Time):指定时间生成一个RDD。
3、isInitialized:Dstream是否已经初始化。
4、persist(level:StorageLevel):使用指定的存储级别持久化Dstream的RDD。
5、persist:存储到内存
6、cache:缓存到内存,与persisit方法一样。
(这里详细说下cache与persist的不同点:cache只有一个默认的缓存级别MEMORY_ONLY ,而persist可以根据情况设置其它的缓存级别。)
7、checkpoint(interval:Duration):设置Dstream及祖宗Dstream的DstreamGraph;
8、getOrCompute(time:Time):从缓存generatedRDDs = new HashMap[Time,RDD[T]]中获取RDD,如果缓存不存在,则生成RDD并持久化、设置检查点放入缓存。
9、generateJob(time:Time):给指定的Time对象生成Job.
10、window(windowDuration:Duration):基于原有的Dstream,返回一个包含了所有在时间滑动窗口中可见元素的新的Dstream.
......
Dsteam本质上是表示连续的一些列的RDD,Dstream中的每个RDD包含了一定间隔的数据,任何对Dstream的操作都会转化为底层RDD的操作。在Spark Streaming中,Dstream提供的接口与RDD提供的接口非常相似。构建完ReciverInputDStream后,会调用各种Dstream的接口方法,对Dstream进行各种转换,最后各个Dstream之间的依赖关系就形成了一张DStream Graph:
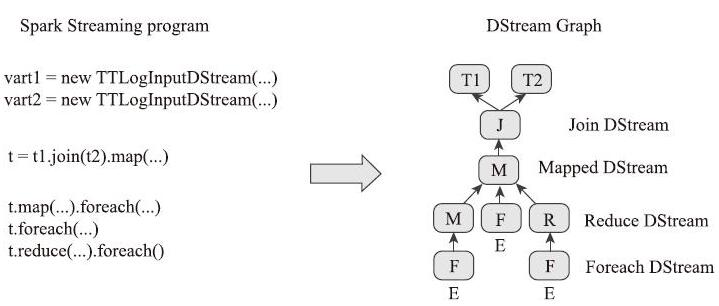
整个流程所涉及的组件为:
1、Reciever:Spark Streaming内置的输入流接收器或用户自定义的接收器,用于从数据源接收源源不断的数据流。
2、currentBuffer:用于缓存输入流接收器接收的数据流。
3、blockIntervalTimer:一个定时器,用于将CurrentBuffer中缓存的数据流封装为Block后放入blocksForPushing。
4、blockForPushing:用于缓存将要使用的Block。
5、blockPushingThread:此线程每隔100毫秒从blocksForPushing中取出一个Block存入存储体系,并缓存到ReceivedBlockQueue。
6、Block Batch:Block批次,按照批次时间间隔,从RecievedBlockQueue中获取一批Block。
7、JobGenerator:Job生成器,用于给每一批Blcok生成一个Job。
下来继续回到StreamingContext,在StreamingContext中new了一个JobScheduler,它里面创了EventLoop,对这个名字是不是很熟悉?没错,就是在Netty通信交互时创建的对象,主要用于处理JobSchedular的事件。然后启动StrreamingListenerBus,用于更新Spark UI中的StreamTab的内容。 那么最重要的就是下来创建ReceiverTracker,它用于处理数据接收、数据缓存、Block生成等工作。最后启动JobGenerator,负责对DstreamGraph的初始化、Dstream与RDD的转换、生成JOB、提交执行等工作。
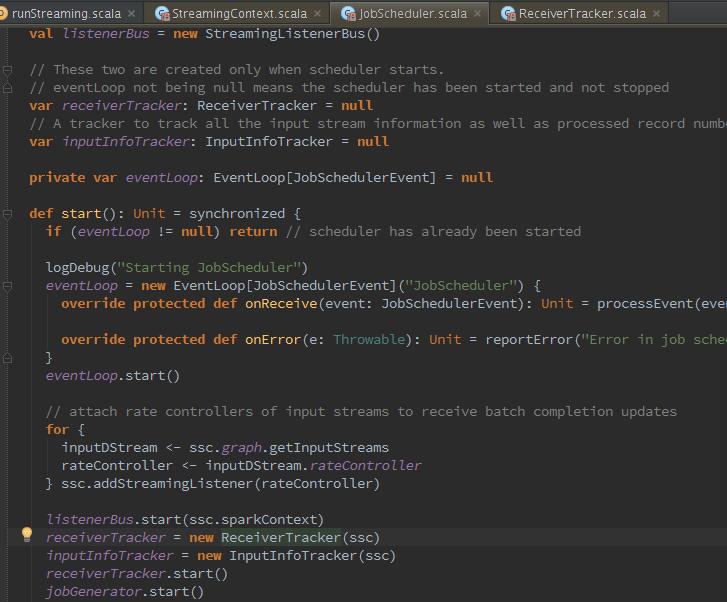
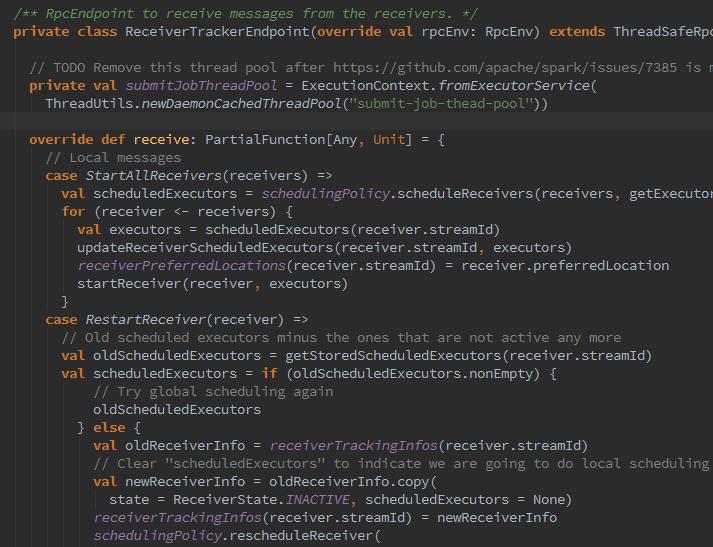
曾经是用ReciverTrackerActor接收来自Reciver的消息,包括RegisterReceiver、AddBlock、ReportError、DeregisterReceiver等,现在不再使用Akka进行通信,而是使用RPC。
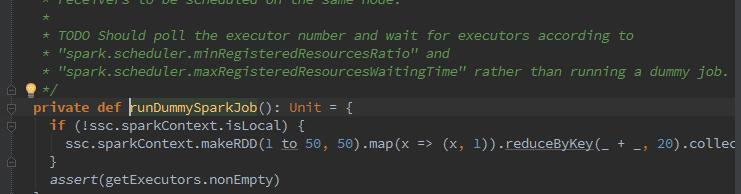
 回到launchReceivers,调用了SparkContext的makeRDD方法,将所有Receiver封装为ParallelCollectionRDD,并行度是receivers的数量,makeRDD方法实际调用了parallelize:
回到launchReceivers,调用了SparkContext的makeRDD方法,将所有Receiver封装为ParallelCollectionRDD,并行度是receivers的数量,makeRDD方法实际调用了parallelize:
今天到此为止。。明天再来会你这磨人的小妖精,玩别的去啦~~~
参考文献:《深入理解Spark:核心思想与源码分析》

