Spark常用函数(源码阅读六)
源码层面整理下我们常用的操作RDD数据处理与分析的函数,从而能更好的应用于工作中。
连接Hbase,读取hbase的过程,首先代码如下:
def tableInitByTime(sc : SparkContext,tableName : String,columns : String,fromdate: Date,todate : Date) : RDD[(ImmutableBytesWritable,Result)] = { val configuration = HBaseConfiguration.create() configuration.addResource("hbase-site.xml ") configuration.set(TableInputFormat.INPUT_TABLE,tableName ) val scan = new Scan //scan.setTimeRange(fromdate.getTime,todate.getTime) val column = columns.split(",") for(columnName <- column){ scan.addColumn("f1".getBytes(),columnName.getBytes()) } val hbaseRDD = sc.newAPIHadoopRDD(configuration,classOf[TableInputFormat],classOf[org.apache.hadoop.hbase.io.ImmutableBytesWritable],classOf[org.apache.hadoop.hbase.client.Result]) System.out.println(hbaseRDD.count()) hbaseRDD }
我们来一点一点解析整个过程。
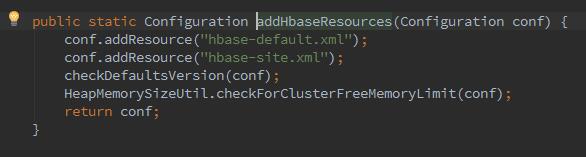
1、val configuration = HBaseConfiguration.create()
这个用过hbase的伙伴们都知道,加载配置文件,其实调用的是HBase的API,返回的RDD是个Configuration。加载的配置文件信息包含core-default.xml,core-site.xml,mapred-default.xml等。加载源码如下:
2、随之设置表名信息,并声明scan对象,并且set读取的列有哪些,随后调用newAPIHadoopRDD,加载指定hbase的数据,当然你可以加上各种filter。那么下来 我们看看newAPIHadoopRDD是干了什么呢?我们来阅读下里面的实现。
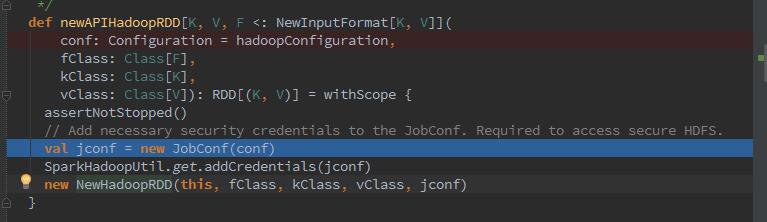
可以看到我们调用API,其实就是一个input过程,创建了一个newHadoopRDD对象,那么后台是一个input数据随后转化为RDD的过程。节点之间的数据传输是通过序列化数据,通过broadCast传输的conf信息。
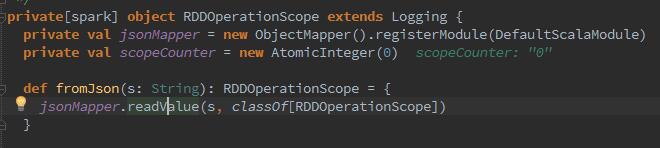
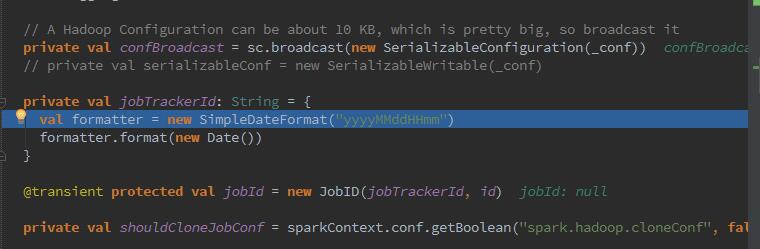
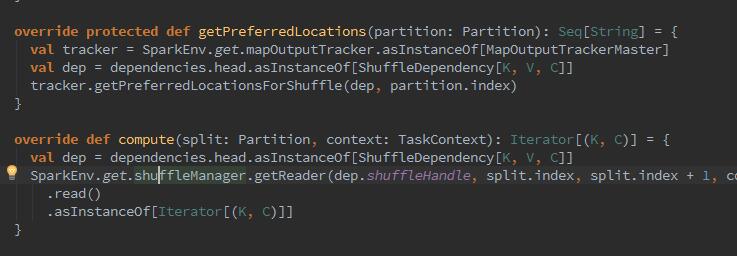
3、随之进行count验证操作,查找数据的partition个数,hbase的数据当然是以block块的形式存储于HDFS。

4、下来开始map遍历,取出之前我们设置的字段,存入新的transRDD中,那么这个map函数干了什么呢?它其实是将原RDD所做的操作组织成一个function,创建一个MapPartitionsRDD。
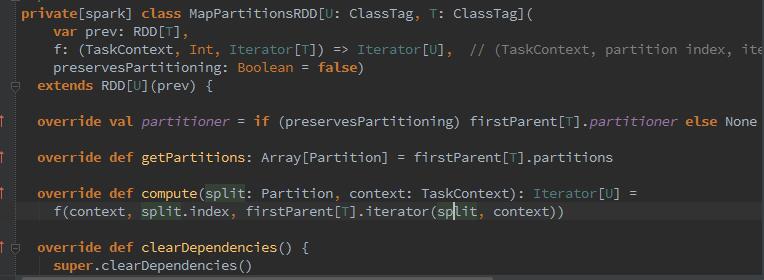
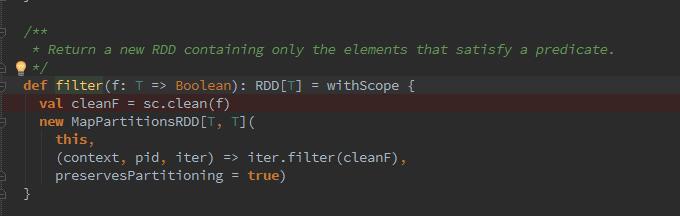
5、下来我们看下filter函数干了什么呢?
val calculateRDD = transRDD.filter(_._1 != null).filter(_._2 != null).filter(_._3 != null).filter(_._4 !=null) //map转换为字段((身份证号,经度(保留两位小数),纬度(保留两位小数),电话号码,时间段标志),1),最后的1代表出现一次,用于后边做累加 .map(data => { val locsp = data._2.split(",").take(2) val df = new DecimalFormat("######0.000") val hour = data._4.split(":")(0).toInt val datarange = if(hour >= 9 && hour <= 18) 1 else 0 ((data._1,df.format(locsp(0).toDouble),df.format(locsp(1).toDouble),data._3,datarange),1) })
这里的filter是进行为空判断,我们从源码中可以看到传入的是一个布尔类型的变量,与map相同通过MapPartitionsRDD进行function的条件过滤,那么也就是说,其实我们可以在map中直接提取我们需要的数据,或者用filter进行为空过滤,条件过滤。
6、随后我们要进行相同key值的合并,那么,我们开始使用reduceByKey:
//按key做reduce,value做累加 .reduceByKey(_ + _)

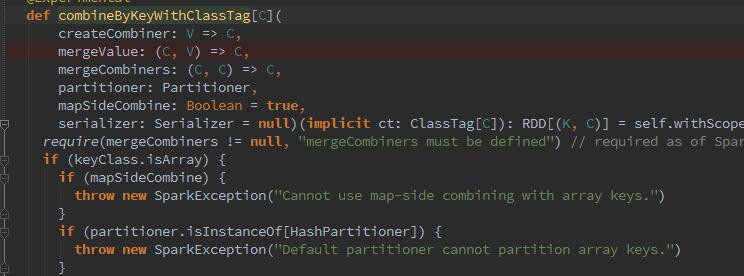
底层调用了combineByKeyWithClassTag,这里的Partitioner参数我们之所以没有传入,是因为在map的RDD中已包含该RDD的partitioner的信息。它内部的实现将map的结果调用了require先进行merge,随后创建shuffleRDD.shuffleRDD就是最终reduce后的RDD。然后看不懂了。。。因为需要与整个流程相结合。所以后续继续深入~