
SparkConf加载与SparkContext创建(源码阅读二)
紧接着昨天,我们继续开搞了啊。。
1、下面,开始创建BroadcastManager,就是传说中的广播变量管理器。BroadcastManager用于将配置信息和序列化后的RDD、Job以及ShuffleDependency等信息在本地存储。紧接着blockManager的创建后创建。如下:

随之我们继续深入看这个broadcastManager是怎么创建与实现的。
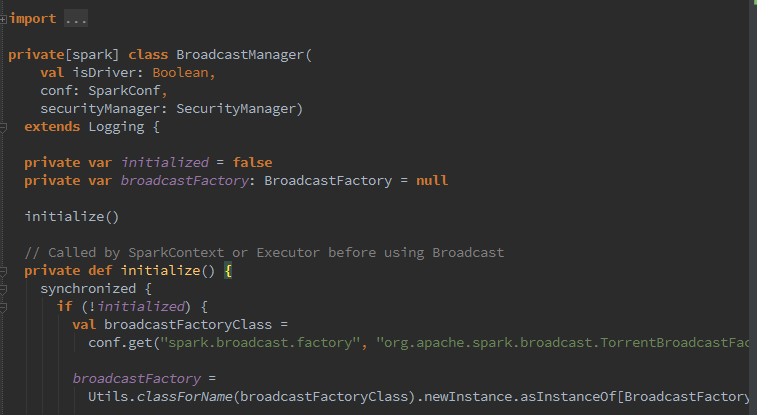
可以看到,在initialize()初始化方法调用以后,通过utils.classForName反射生成工厂实例broadcastFactory,可以配置属性spark.broadcast.factory指定,默认为org.apache.spark.broadcast.TorrentBroadcastFactory。广播变量与非广播变量都是以broadcastFactory工厂实现的。
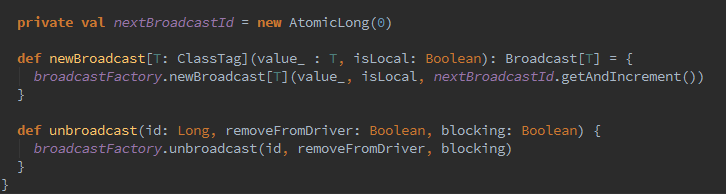
2、接下来,开始创建缓存管理器CacheManager。CacheManager用于缓存RDD某个分区计算后的中间结果,缓存计算结果发生在迭代计算的时候,那么它是怎么实现的呢。我们继续深入~

我们可以看到,在创建cacheManager对象的时候,传入了blockManager,真正的缓存对象,依旧是blockManager,cacheManager是为blockManager做了代理。当迭代计算中,如果判断使用了缓存,就会调用getOrCompute,从blockManager.get(key)获取存储的block,如果存在,则封装new InterruptibleIterator返回,否则将重新loading partition,从CheckPoint中获取数据,调用putInBlockManager方法将数据写入缓存,进行InterruptibleIterator封装。
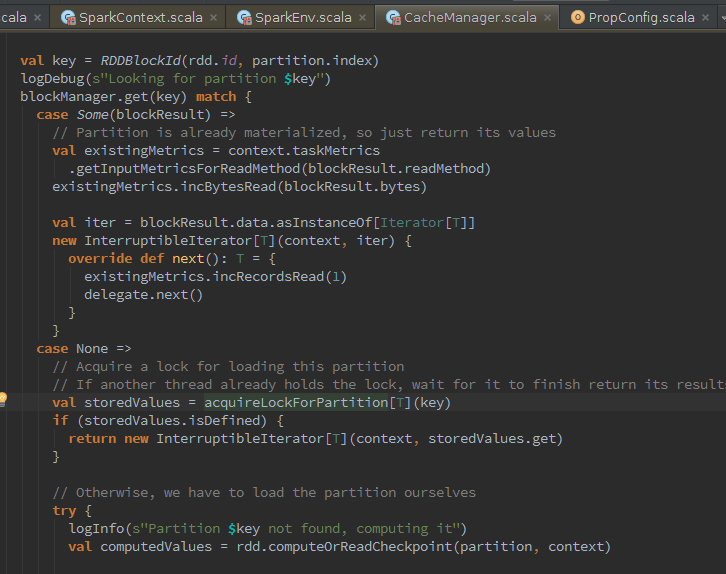
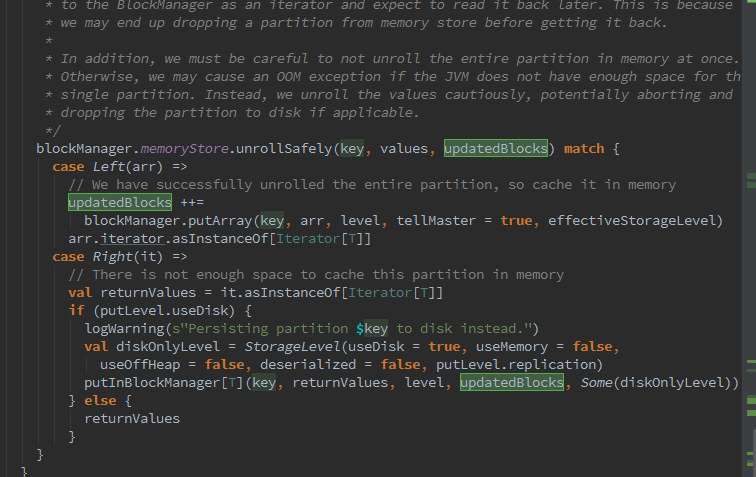
再次深入调用putInBlockManager的过程。发现传入了partition的key,computedValues,storageLevel存储等级,由BlockId,BlockStatus组成的元素。随之它里面又搞了些事情。

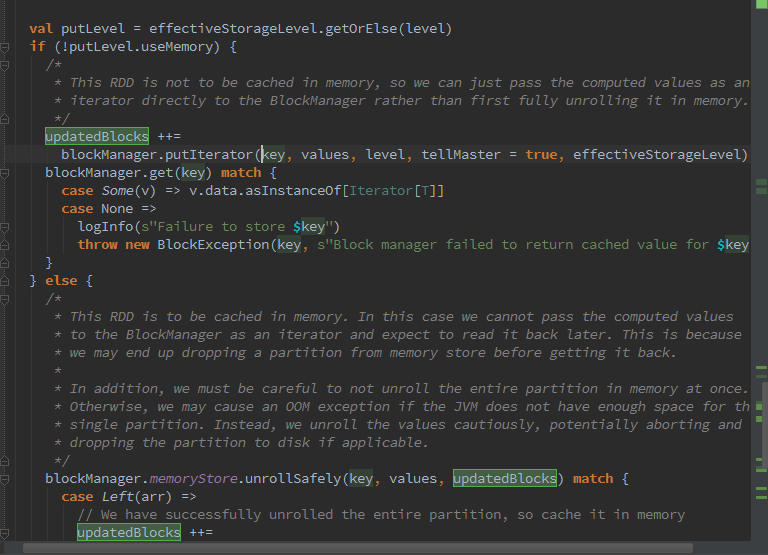
如果存储级别不允许使用内存,那么直接调用BlockManager的putIterator方法。通过判断putLevel.useMemory,也就是存储级别允许存储,那么就进行展开,如果展开成功则将数据存入内存,否则则写入磁盘。
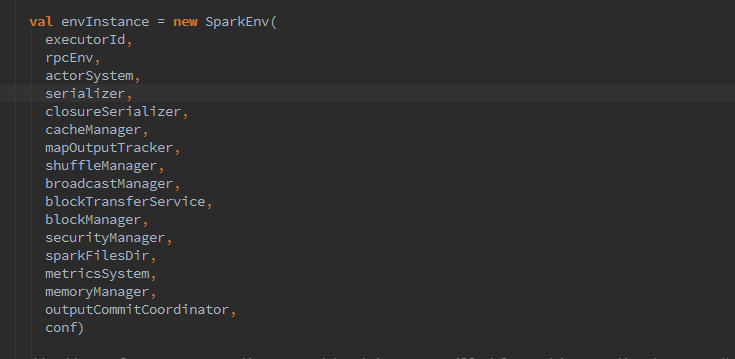
然后继续,我们看下,开始创建metricsSystem,主要是用于加载metrics.properties文件中的属性配置,当所有的基本组件准备好后,开始创建SparkEnv.
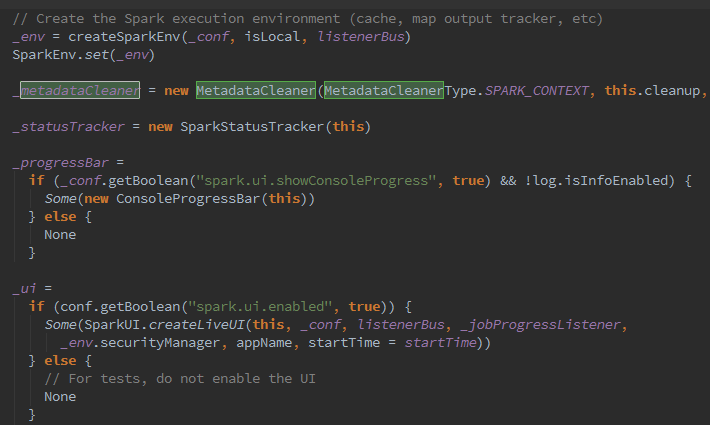
最后,创建MetadataCleaner,它的实质是一个用TimeTask实现的定时器,用于清理persistentRdds中的过期内容,最后的最后创建SparkUI.
好了~今天就到这里,明日继续,我去敲代码咯~~~~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号