

Hadoop数据读写原理
数据流
MapReduce作业(job)是客户端执行的单位:它包括输入数据、MapReduce程序和配置信息。Hadoop把输入数据划分成等长的小数据发送到MapReduce,称之为输入分片。Hadoop为每个分片创建一个map任务,由它来运行用户自定义的map函数来分析每个分片中的记录。
这里分片的大小,如果分片太小,那么管理分片的总时间和map任务创建的总时间将决定作业的执行的总时间。对于大数据作业来说,一个理想的分片大小往往是一个HDFS块的大小,默认是64MB(可以通过配置文件指定)
map任务的执行节点和输入数据的存储节点是同一节点时,Hadoop的性能达到最佳。这就是为什么最佳分片的大小与块大小相同,它是最大的可保证存储在单个节点上的数据量如果分区跨越两个块,那么对于任何一个HDFS节点而言,基本不可能同时存储着两数据块,因此此分布的某部分必须通过网络传输到节点,这与使用本地数据运行map任务相比,显然效率很低。
reduce任务并不具备数据本地读取的优势,一个单一的reduce的任务的输入往往来自于所有mapper的输出。因此,有序map的输出必须通过网络传输到reduce任务运行的节点,并在哪里进行合并,然后传递到用户自定义的reduce函数中。 一般情况下,多个reduce任务的数据流成为"shuffle",因为每个reduce任务的输入都由许多map任务来提供。
Hadoop流
流适用于文字处理,在文本模式下使用时,它有一个面向行的数据视图。map的输入数据把标准输入流传输到map函数,其中是一行一行的传输,然后再把行写入标准输出。该框架调用mapper的map()方法来处理读入的每条记录,然而map程序可以决定如何处理输入流,可以轻松地读取和同一时间处理多行,用户的java map实现是压栈记录,但它仍可以考虑处理多行,具体做法是将mapper中实例变量中之前的行汇聚在一起(可用其他语言实现)。
HDFS的设计
HDFS是为以流式数据访问模式存储超大文件而设计的文件系统,在商用硬件的集群上运行。
流式数据访问:一次写入、多次读取模式是最高效的,一个数据集通常由数据源生成或复制,接着在此基础上进行各种各样的分析。
低延迟数据访问:需要低延迟访问数据在毫秒范围内的应用不适用于HDFS,HDFS是为达到高数据吞吐量而优化的,这有可能会以延迟为代价。(低延迟访问可以参考HBASE)
大量的小文件:namenode存储着文件系统的元数据,文件数量的限制也由namenode的内存量决定。每个文件,索引目录以及块占大约150个字节,因此,如果有一百万文件,每个文件占一个块,就至少需要300MB的内存。
多用户写入,任意修改文件:HDFS中的文件只有一个写入者。
HDFS的块比磁盘的块大,目的是为了减少寻址的开销。通过让一个块足够大,从磁盘转移数据的时间能够远远大于定位这个开始端的时间。因此,传送一个由多个块组成的文件的时间就取决于磁盘传送率。
文件读取与写入
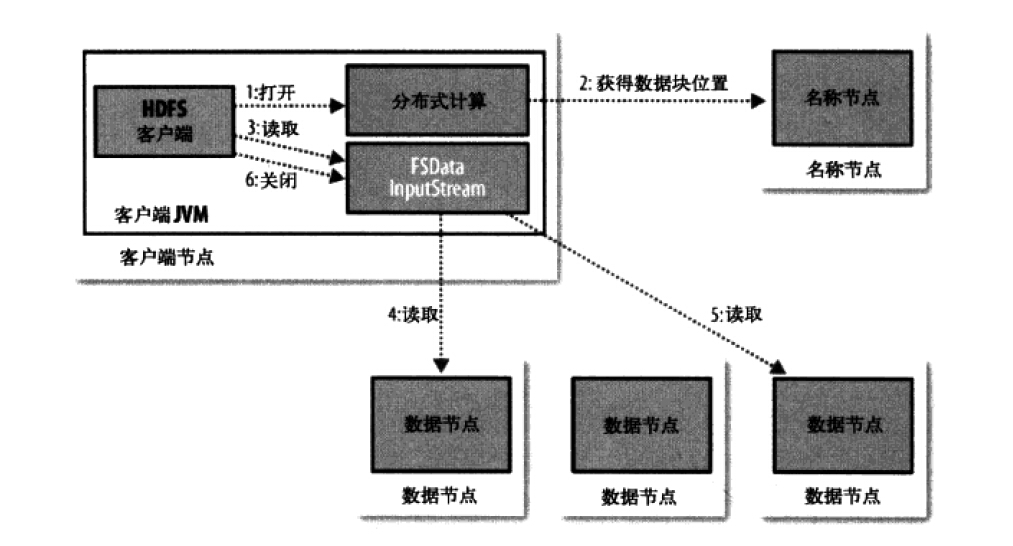
HDFS中读取数据
客户端是通过调用fileSystem对象的open()来读取希望打开的文件的。对于HDFS,这个对象是分布式文件系统的一个实例。
(1)DistributedFileSystem通过使用RPC来调用namenode,以确定文件开头部分的块的位置,对于每一个块,namenode返回具有该块副本的数据节点地址。随后这些数据节点根据它们与客户端的距离来排序,如果该客户端本身就是一个数据节点,便从本地数据节点读取。(Distributed FileSystem返回一个FSData InputStream转而包装了一个DFSInputStream对象)
(2)存储着文件开头部分的块的数据节点地址的DFSInputStream随机与这些块的最近的数据节点相连接,通过在数据流中重复调用read(),数据就会从数据节点返回客户端。到达块的末端时,DFSInputSteam会关闭与数据节点间的连接,然后为下一个块找到最佳的数据节点。
(3)客户端从流中读取数据时,块是按照DFSInputStream打开与数据节点的新连接的顺序读取的。它也会调用namenode来检索下一组需要的块的数据节点的位置。一旦客户端完成读取,就对文件系统数据输入调用close()。
这个设计的重点是,客户端直接联系数据节点去检索数据,通过namenode指引到每个块中最好的数据节点。因为数据流动在此集群中是在所有数据节点分散进行的,因此这种设计能使HDFS可扩展到最大的并发客户端数量。namenode提供块位置请求,其数据是存储在内存,非常的高效。
文件写入

客户端是通过在DistributedFilesystem中调用create()来创建文件,DistributedFilesystem一个RPC去调用namenode,在文件系统的命名空间中创建一个新文件。namenode执行各种不同的检查以确保这个文件不会已经存在,并且客户端有创建文件的权限。文件系统数据输出流控制一个DFSoutPutstream,负责datanode与namenode之间的通信。
客户端完成数据的写入后,会在流中调用clouse(),在向namenode发送完信息之前,此方法会将余下的所有包放入datanode管线并等待确认,namenode节点已经知道文件由哪些块组成(通过Data streamer询问块分配),所以它值需在返回成功前等待块进行最小量的复制。
一旦写入的数据超过一个块的数据,新的读取者就能看见第一个块,对于之后的块也是这样。总之,它始终是当前正在被写入的块,其他读取者是看不见的。HDFS提供一个方法来强制所有的缓存与datanode同步,即在文件系统数据输出流调用sync()方法,在syno()返回成功后,HDFS能保证文件中直至写入的最后的数据对所有新的读取者而言,都是可见且一致的。万一发生冲突(与客户端或HDFS),也不会造成数据丢失。
应用设计的重要性:如果不调用sync(),那么一旦客户端或系统发生故障,就可能失去一个块的数据,应该在适当的地方调用sync().
通过distcp进行并行复制:Hadoop有一个叫distcp(分布式复制)的有用程序,能从Hadoop的文件系统并行复制大量数据。如果集群在Hadoop的同一版本上运行,就适合使用hdfs方案:
hadoop distcp hdfs://namenode1/foo hdfs://namenode2/bar
将从第一个集群中复制/foo目录到第二个集群中的/bar目录下
参考:《Hadoop权威指南-第四版》

