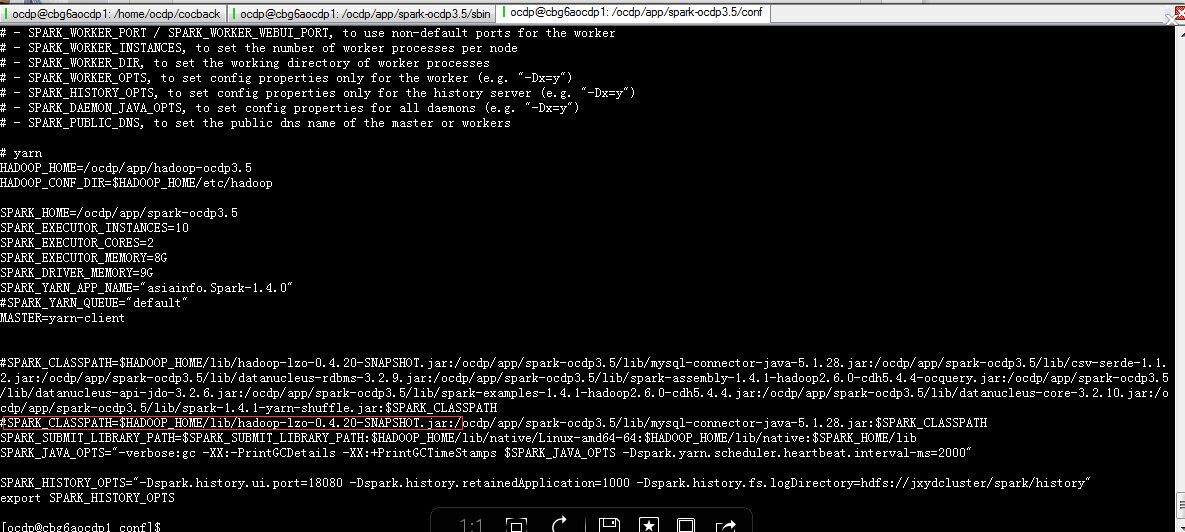
spark1.4加载mysql数据 创建Dataframe及join操作连接方法问题
首先我们使用新的API方法连接mysql加载数据 创建DF
import org.apache.spark.sql.DataFrame import org.apache.spark.{SparkContext, SparkConf} import org.apache.spark.sql.{SaveMode, DataFrame} import scala.collection.mutable.ArrayBuffer import org.apache.spark.sql.hive.HiveContext import java.sql.DriverManager import java.sql.Connection val sqlContext = new HiveContext(sc) val mySQLUrl = "jdbc:mysql://10.180.211.100:3306/appcocdb?user=appcoc&password=Asia123"
val CI_MDA_SYS_TABLE = sqlContext.jdbc(mySQLUrl,"CI_MDA_SYS_TABLE").cache()
val CI_MDA_SYS_TABLE_COLUMN = sqlContext.jdbc(mySQLUrl,"CI_MDA_SYS_TABLE_COLUMN").cache()
val CI_LABEL_EXT_INFO = sqlContext.jdbc(mySQLUrl,"CI_LABEL_EXT_INFO").cache()
val CI_LABEL_INFO = sqlContext.jdbc(mySQLUrl,"CI_LABEL_INFO").cache()
val CI_APPROVE_STATUS = sqlContext.jdbc(mySQLUrl,"CI_APPROVE_STATUS").cache()
val DIM_COC_LABEL_COUNT_RULES = sqlContext.jdbc(mySQLUrl,"DIM_COC_LABEL_COUNT_RULES").cache()
根据多表ID进行关联
val labels = CI_MDA_SYS_TABLE.join(CI_MDA_SYS_TABLE_COLUMN,CI_MDA_SYS_TABLE("TABLE_ID") === CI_MDA_SYS_TABLE_COLUMN("TABLE_ID"),"inner").cache()
labels.join(CI_LABEL_EXT_INFO,CI_MDA_SYS_TABLE_COLUMN("COLUMN_ID") === CI_LABEL_EXT_INFO("COLUMN_ID"),"inner").cache()
labels.join(CI_LABEL_INFO,CI_LABEL_EXT_INFO("LABEL_ID") === CI_LABEL_INFO("LABEL_ID"),"inner").cache()
labels.join(CI_APPROVE_STATUS,CI_LABEL_INFO("LABEL_ID") === CI_APPROVE_STATUS("RESOURCE_ID"),"inner").cache()
labels.filter(CI_APPROVE_STATUS("CURR_APPROVE_STATUS_ID") === 107 and (CI_LABEL_INFO("DATA_STATUS_ID") === 1 || CI_LABEL_INFO("DATA_STATUS_ID") === 2) and (CI_LABEL_EXT_INFO("COUNT_RULES_CODE") isNotNull) and CI_MDA_SYS_TABLE("UPDATE_CYCLE") === 1).cache()
于是噼里啪啦的报错了,在第三个join时找不到ID了,这个问题很诡异。。。:
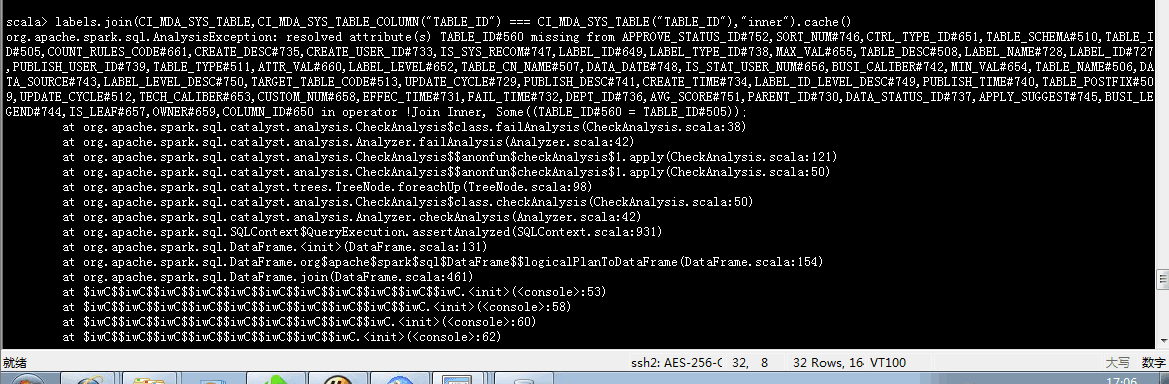
无奈了。。于是使用官网API spark1.4的指定方法尝试
val labels = CI_MDA_SYS_TABLE.join(CI_MDA_SYS_TABLE_COLUMN,"TABLE_ID") labels.join(CI_LABEL_EXT_INFO,"COLUMN_ID") labels.join(CI_LABEL_INFO,"LABEL_ID") labels.join(CI_APPROVE_STATUS).WHERE($"LABEL_ID"===$"RESOURCE_ID")
于是又噼里啪啦的,还是找不到ID。。。。
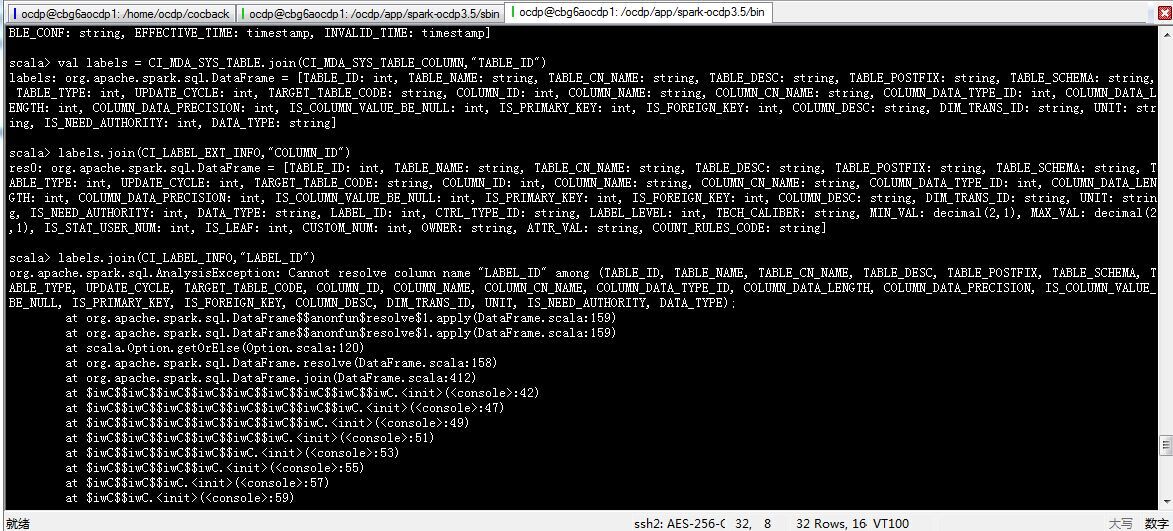
最后无奈。。就用原来的方法 创建软连接,加载数据,发现可以。。这我就不明白了。。。
val CI_MDA_SYS_TABLE_DDL = s""" CREATE TEMPORARY TABLE CI_MDA_SYS_TABLE USING org.apache.spark.sql.jdbc OPTIONS ( url '${mySQLUrl}', dbtable 'CI_MDA_SYS_TABLE' )""".stripMargin sqlContext.sql(CI_MDA_SYS_TABLE_DDL) val CI_MDA_SYS_TABLE = sql("SELECT * FROM CI_MDA_SYS_TABLE").cache() //val CI_MDA_SYS_TABLE = sqlContext.jdbc(mySQLUrl,"CI_MDA_SYS_TABLE").cache() val CI_MDA_SYS_TABLE_COLUMN_DDL = s""" CREATE TEMPORARY TABLE CI_MDA_SYS_TABLE_COLUMN USING org.apache.spark.sql.jdbc OPTIONS ( url '${mySQLUrl}', dbtable 'CI_MDA_SYS_TABLE_COLUMN' )""".stripMargin sqlContext.sql(CI_MDA_SYS_TABLE_COLUMN_DDL) val CI_MDA_SYS_TABLE_COLUMN = sql("SELECT * FROM CI_MDA_SYS_TABLE_COLUMN").cache() //val CI_MDA_SYS_TABLE_COLUMN = sqlContext.jdbc(mySQLUrl,"CI_MDA_SYS_TABLE_COLUMN").cache() .........
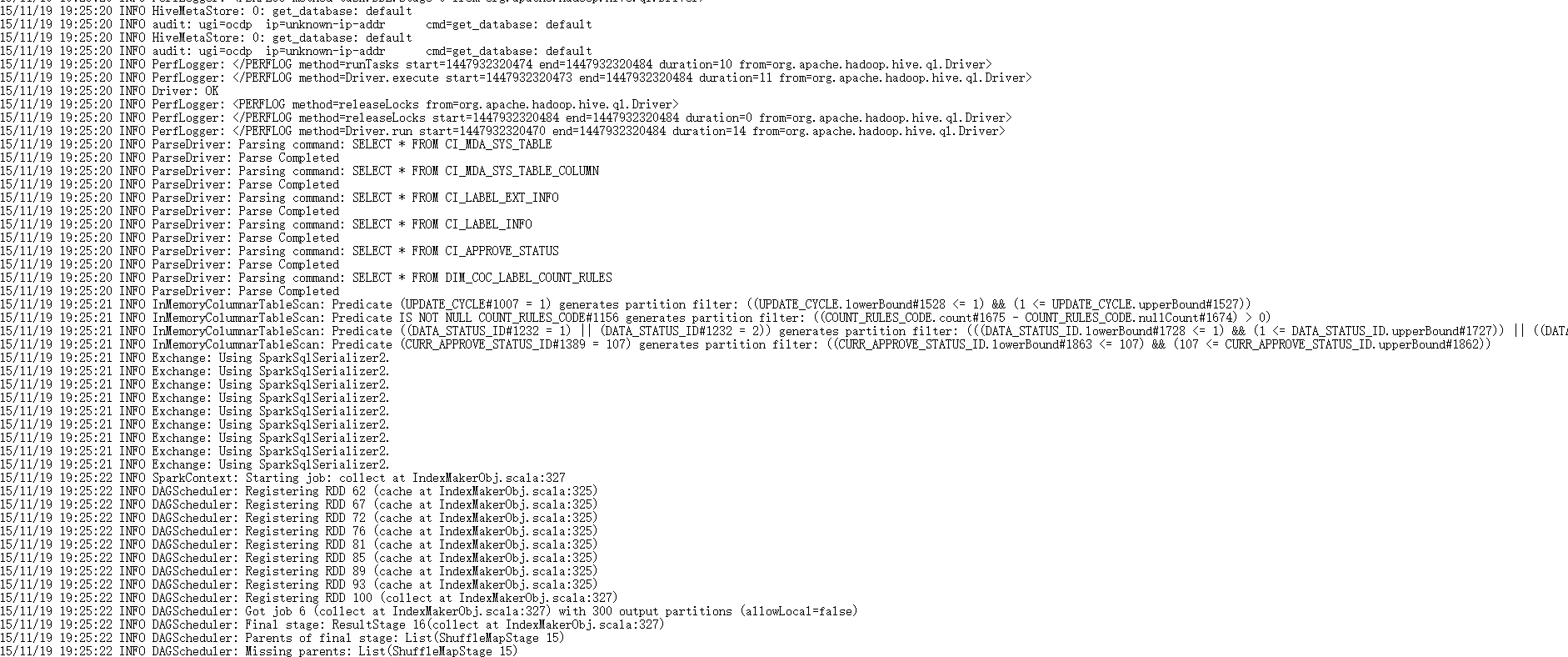
最终问题是解决了。。可是 为什么直接加载不行呢。。还有待考究。
附带一个问题的解决 如果啊报这种错误
15/11/19 10:57:12 INFO BlockManagerInfo: Removed broadcast_3_piece0 on cbg6aocdp9:49897 in memory (size: 8.4 KB, free: 1060.3 MB) 15/11/19 10:57:12 INFO BlockManagerInfo: Removed broadcast_3_piece0 on cbg6aocdp5:45978 in memory (size: 8.4 KB, free: 1060.3 MB) 15/11/19 10:57:12 INFO BlockManagerInfo: Removed broadcast_2_piece0 on 10.176.238.11:38968 in memory (size: 8.2 KB, free: 4.7 GB) 15/11/19 10:57:12 INFO BlockManagerInfo: Removed broadcast_2_piece0 on cbg6aocdp4:55199 in memory (size: 8.2 KB, free: 1060.3 MB) 15/11/19 10:57:12 INFO ContextCleaner: Cleaned shuffle 0 15/11/19 10:57:12 INFO BlockManagerInfo: Removed broadcast_1_piece0 on 10.176.238.11:38968 in memory (size: 6.5 KB, free: 4.7 GB) 15/11/19 10:57:12 INFO BlockManagerInfo: Removed broadcast_1_piece0 on cbg6aocdp8:55706 in memory (size: 6.5 KB, free: 1060.3 MB) TARGET_TABLE_CODE:========================IT03 Exception in thread "main" java.lang.RuntimeException: Error in configuring object at org.apache.hadoop.util.ReflectionUtils.setJobConf(ReflectionUtils.java:109) at org.apache.hadoop.util.ReflectionUtils.setConf(ReflectionUtils.java:75) at org.apache.hadoop.util.ReflectionUtils.newInstance(ReflectionUtils.java:133) at org.apache.spark.rdd.HadoopRDD.getInputFormat(HadoopRDD.scala:190) at org.apache.spark.rdd.HadoopRDD.getPartitions(HadoopRDD.scala:203) at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:219) at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:217) at scala.Option.getOrElse(Option.scala:120) at org.apache.spark.rdd.RDD.partitions(RDD.scala:217) at org.apache.spark.rdd.MapPartitionsRDD.getPartitions(MapPartitionsRDD.scala:32) at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:219) at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:217) at scala.Option.getOrElse(Option.scala:120) at org.apache.spark.rdd.RDD.partitions(RDD.scala:217) at org.apache.spark.rdd.MapPartitionsRDD.getPartitions(MapPartitionsRDD.scala:32) at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:219) at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:217) at scala.Option.getOrElse(Option.scala:120) at org.apache.spark.rdd.RDD.partitions(RDD.scala:217) at org.apache.spark.rdd.MapPartitionsRDD.getPartitions(MapPartitionsRDD.scala:32) at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:219) at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:217) at scala.Option.getOrElse(Option.scala:120) at org.apache.spark.rdd.RDD.partitions(RDD.scala:217) at org.apache.spark.rdd.MapPartitionsRDD.getPartitions(MapPartitionsRDD.scala:32) at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:219) at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:217) at scala.Option.getOrElse(Option.scala:120) at org.apache.spark.rdd.RDD.partitions(RDD.scala:217) at org.apache.spark.rdd.MapPartitionsRDD.getPartitions(MapPartitionsRDD.scala:32) at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:219) at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:217) at scala.Option.getOrElse(Option.scala:120) at org.apache.spark.rdd.RDD.partitions(RDD.scala:217) at org.apache.spark.rdd.MapPartitionsRDD.getPartitions(MapPartitionsRDD.scala:32) at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:219) at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:217) at scala.Option.getOrElse(Option.scala:120) at org.apache.spark.rdd.RDD.partitions(RDD.scala:217) at org.apache.spark.rdd.MapPartitionsRDD.getPartitions(MapPartitionsRDD.scala:32) at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:219) at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:217) at scala.Option.getOrElse(Option.scala:120) at org.apache.spark.rdd.RDD.partitions(RDD.scala:217) at org.apache.spark.rdd.MapPartitionsRDD.getPartitions(MapPartitionsRDD.scala:32) at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:219) at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:217) at scala.Option.getOrElse(Option.scala:120) at org.apache.spark.rdd.RDD.partitions(RDD.scala:217) at org.apache.spark.sql.execution.SparkPlan.executeTake(SparkPlan.scala:121) at org.apache.spark.sql.execution.Limit.executeCollect(basicOperators.scala:125) at org.apache.spark.sql.DataFrame.collect(DataFrame.scala:1269) at org.apache.spark.sql.DataFrame.head(DataFrame.scala:1203) at org.apache.spark.sql.DataFrame.take(DataFrame.scala:1262) at org.apache.spark.sql.DataFrame.showString(DataFrame.scala:176) at org.apache.spark.sql.DataFrame.show(DataFrame.scala:331) at main.asiainfo.coc.impl.IndexMakerObj$$anonfun$makeIndexsAndLabels$1.apply(IndexMakerObj.scala:218) at main.asiainfo.coc.impl.IndexMakerObj$$anonfun$makeIndexsAndLabels$1.apply(IndexMakerObj.scala:137) at scala.collection.IndexedSeqOptimized$class.foreach(IndexedSeqOptimized.scala:33) at scala.collection.mutable.ArrayOps$ofRef.foreach(ArrayOps.scala:108) at main.asiainfo.coc.impl.IndexMakerObj$.makeIndexsAndLabels(IndexMakerObj.scala:137) at main.asiainfo.coc.CocDss$.main(CocDss.scala:23) at main.asiainfo.coc.CocDss.main(CocDss.scala) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:606) at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:665) at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:170) at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:193) at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:112) at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala) Caused by: java.lang.reflect.InvocationTargetException at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:606) at org.apache.hadoop.util.ReflectionUtils.setJobConf(ReflectionUtils.java:106) ... 71 more Caused by: java.lang.IllegalArgumentException: Compression codec com.hadoop.compression.lzo.LzoCodec not found. at org.apache.hadoop.io.compress.CompressionCodecFactory.getCodecClasses(CompressionCodecFactory.java:135) at org.apache.hadoop.io.compress.CompressionCodecFactory.<init>(CompressionCodecFactory.java:175) at org.apache.hadoop.mapred.TextInputFormat.configure(TextInputFormat.java:45) ... 76 more Caused by: java.lang.ClassNotFoundException: Class com.hadoop.compression.lzo.LzoCodec not found at org.apache.hadoop.conf.Configuration.getClassByName(Configuration.java:2018) at org.apache.hadoop.io.compress.CompressionCodecFactory.getCodecClasses(CompressionCodecFactory.java:128) ... 78 more
一看最后就知道 是hadoop数据压缩格式为lzo spark要想读取 必须引入hadoop lzo的jar包