Pytorch 4.2 多层感知机的从零开始实现
多层感知机的从零实现 (有点类似于Softmax和线性回归)
step1.读取数据
import torch
from torch import nn
from d2l import torch as d2l
%matplotlib inline
batch_size = 256
train_iter,text_iter = d2l.load_data_fashion_mnist(batch_size)
2.初始化模型参数
# 初始化模型参数
num_inputs, num_outputs, num_hiddens = 784,10,256
W1 = nn.Parameter(torch.randn(num_inputs,num_hiddens,requires_grad = True)*0.01)
b1 = nn.Parameter(torch.zeros(num_hiddens),requires_grad=True)
W2 = nn.Parameter(torch.randn(num_hiddens,num_outputs,requires_grad = True)*0.01)
b2 = nn.Parameter(torch.zeros(num_outputs),requires_grad=True)
params = [W1,b1,W2,b2]
step3.定义函数和训练
# 激活函数ReLU
def relu(x):
a = torch.zeros_like(x)
return torch.max(a,x)
# 模型net
def net(x):
x = x.reshape((-1,num_inputs)) #x∈[-1,784] w1∈[784,num_hidden] w2∈[num_hidden,num_output]
H = relu(x@W1 + b1) # 这里“@”代表矩阵乘法
return H@W2 + b2
# 损失函数loss
loss = nn.CrossEntropyLoss()
# 训练 调用d2l库中的 train_ch3()
num_epochs,lr = 10,0.1
upgrater = torch.optim.SGD(params,lr=lr)
d2l.train_ch3(net,train_iter,text_iter,loss,num_epochs,upgrater)
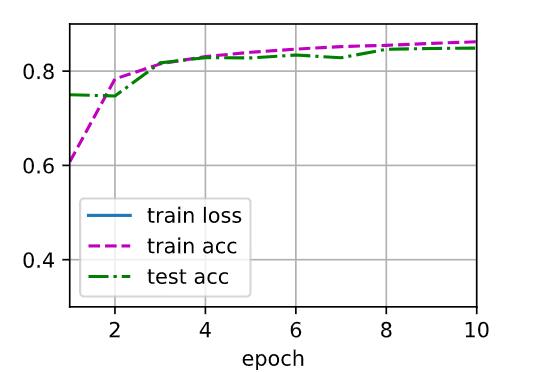
step4.评估模型
d2l.predict_ch3(net, test_iter)

章节答疑
Q1: nn.Parameter 和 torch.optim.SGD() 中传入的parameter是怎么一回事?
A1: 官网解释: CLASS torch.nn.parameter.Parameter(data=None, requires_grad=True)
A kind of Tensor that is to be considered a module parameter.
---> 一种被认为是模参数的张量。
Parameters are Tensor subclasses, that have a very special property when used with Module s - when they’re assigned as Module attributes they are automatically added to the list of its parameters, and will appear e.g. in parameters() iterator. Assigning a Tensor doesn’t have such effect. This is because one might want to cache some temporary state, like last hidden state of the RNN, in the model. If there was no such class as Parameter, these temporaries would get registered too.
---> 你可以将torch.nn.Parameter()看成是一种可迭代的容器
---> 用人话来理解: 可以把它看成是一个张量,Over
至于为什么要使用nn.Parameter这个方法,这事儿还得从torch.optim.SGD开始说起。
CLASS torch.optim.SGD(params, lr=<required parameter>, momentum=0, dampening=0, weight_decay=0, nesterov=False)
Pytorch 官网中有明确表示: params (iterable) – iterable of parameters to optimize or dicts defining parameter groups ,如果你想使用torch中的SGD,就必须传入一个可迭代的参数,其中位置还不能够错误。
参考: (1)SGD : https://pytorch.org/docs/stable/generated/torch.optim.SGD.html?highlight=torch optim sgd#torch.optim.SGD
(2)MLP:http://zh.d2l.ai/chapter_multilayer-perceptrons/mlp-concise.html
(3)Parameter:https://pytorch.org/docs/stable/generated/torch.nn.parameter.Parameter.html?highlight=torch nn para#torch.nn.parameter.Parameter
posted on 2022-01-02 12:29 YangShusen' 阅读(194) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号