
java设计模式--创建型模式
前言
创建型模式追是将对象的创建与使用分离,降低系统的耦合度
创建型模式:
单例模式:某个类只能生成一个实例,该类听过全局访问点供外部获取实例
工厂模式:定义一个用户创建产品的接口,由子类创建产品
原型模式:将一个对象作为原型,通过第七进行复制从而克隆出多个与原型类似的实例
建造者模式:将一个复杂的对象分解多个相对简单部分,然后根据不同需要进行创建,最终合成该对象
抽象工厂模式:定义一个黄建产品族的接口,每个子类可以生产相关的产品
正文
1.单例模式(Singleton)
单例模式特点:
- 保证整个软件系统中,对某个类只能存在一个对象实例
- 该类提供了一个全局访问点供外部获取该实例,其拓展就是有限多例模式
- 该类必须由单例类自行创建
优点:
- 保证内存中只有一个实例,减少了内存开销
- 避免对资源的多重占用
- 可以优化和共享资源的访问
缺点:
- 单例模式一般没有接口,扩展困难。如果需要扩展,则需要修改原来的代码,会违背开闭原则
- 单例模式功能代码一般都会写在一个类中,如果涉及不合理,容易违背单一职责原则
应用场景:
- 频繁的创建一些类,使用单例模式可以降低系统压力,减少GC
- 对于只需要一个实例的对象
- 实例创建时间较长,并且经常使用
- 某些对象需要频繁的实例化,并且频繁的销毁,例如数据库连接池或者网络连接池
- 某个对象需要被共享
单例模式的创建方式有很多种,其中懒汉式必须保证多线程引起的问题,下面几种方式都可以保证对象唯一:
- 饿汉式,静态常量创建
- 饿汉式,静态代码块创建
- 懒汉式,加锁创建
- 懒汉式,双重检查创建
- 懒汉式,静态内部类
- 枚举,这个原理可以通过查看解读字节码进行查看
饿汉式就是classLoader进行类加载的时候进行创建,这种写法比较简单,懒汉式只有在实际用的时候才会创建。枚举也是类加载的时候就会创建
public class Singleton {
// 1. 饿汉式,静态常量,这里的volatle只是为了后面懒汉式,主要是为了防止指令重排序
private static volatile Singleton INSTANCE = new Singleton();
// 2. 饿汉式,静态代码块
static {
INSTANCE = new Singleton();
}
// public static Singleton getInstance(){
// return INSTANCE;
// }
// 3. 懒汉式,加锁创建
// private static synchronized Singleton getInstance(){
// if(INSTANCE == null){
// INSTANCE = new Singleton();
// }
// return INSTANCE;
// }
// 4.双重检查,这个其实是上面的优化,在并发场景下,如果对象已经实例化了,
// 就不需要在加锁,加锁是一个比较重的操作,因此单例模式,很少会是一个线程频繁调用,所以一般也不会出现偏向锁
// private static Singleton getInstance() {
// if (INSTANCE == null) {
// synchronized (Singleton.class) {
// if (INSTANCE == null) {
// INSTANCE = new Singleton();
// }
// }
// }
// return INSTANCE;
// }
// 5. 静态内部类创建,这个SingleTonFactory里面的属性,并不会在Singleton类加载的时候创建
private static class SingleTonFactory {
public static Singleton INSTANCE = new Singleton();
}
public static Singleton getInstance() {
return SingleTonFactory.INSTANCE;
}
}
从下述截图可以看出对于enum的代码的字节码进行解析,cinit会在类装载的时候进行调用,其中getstatic看后面引用关系可以这个对象就初始化了

2.工厂模式(FactoryMethod)
定义一个创建产品对象的工厂接口,将产品对象的实际创建工作推迟到具体子工厂类当中。工厂模式有 3 种不同的实现方式,分别是简单工厂模式、工厂方法模式和抽象工厂模式。
简单工厂模式
优点:
- 工厂类中包含必要的创建逻辑,可以决定何时创建产品实例
- 客户端无需知道创建具体产品的雷鸣,只需要知道必要的参数即可
- 可以引入配置文件,在不修改客户端代码的请鲁昂下更换和添加新的具体产品类
缺点:
- 单一,负责所有产品的创建,职责过重,如果业务复杂,代码会比较臃肿,违背高内聚原则
- 系统扩展困难,引入新产品需要修改工厂逻辑,如果产品类型较多,会造成逻辑复杂
- 使用static工厂方法,工厂角色无法形成基于继承的等级结构
使用场景:
- 产品种类相对较少
举例说明,首先看一下UML类图:
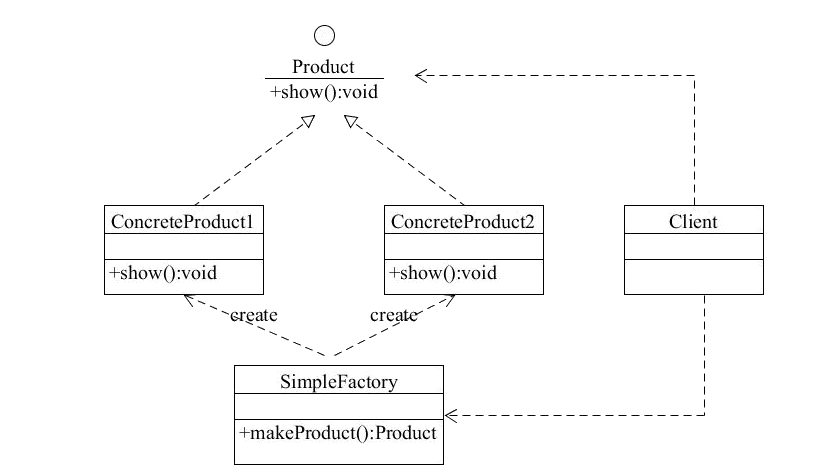
一个简单的工厂类
public class SimpleFactory {
public static Product getProduct(int type){
if(type == 1){
return new ConcreteProductA();
}else if (type ==2){
return new ConcreteProduceB();
}
throw new IllegalArgumentException();
}
}
工厂方法模式
因为对于稍微复杂一点的逻辑,简单工厂就会面临大范围修改代码,并且违反了开闭原则,二工厂发发就是对简单工厂模式的进一步抽象话
优点:
- 与简单工厂方法一样,客户端只要具体工厂的名称即可得到对应的产品
- 灵活性强,对于新增加一个产品,只需要多写一个对应的工厂类
- 高层模块只需要知道产品的抽象类,无需关心其他实现类,满足迪米特法则,依赖倒置原则以及里式替换
缺点:
- 类的个数会增多,增加复杂性
- 增加了系统的抽象以及理解难度
- 抽象产品只能生产一种产品
应用场景:
- 客户端只需要知道创建产品的工厂名
- 创建对象有多个具体字工厂中的某一个完成,抽象工厂只提供创建产品的接口
工厂方法的UML类图
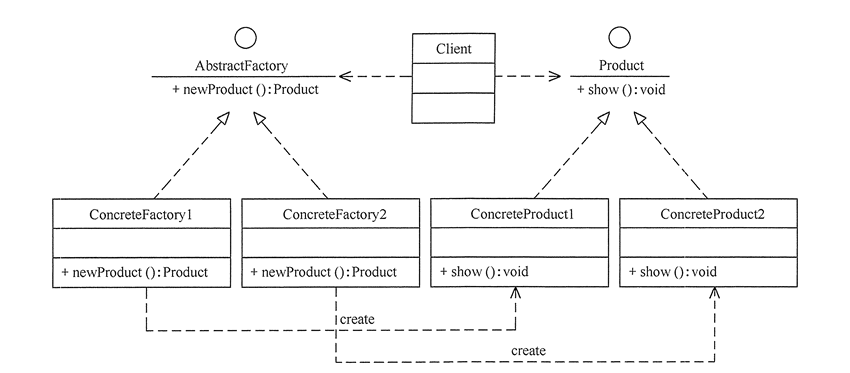
代码:
public interface Product {
void show();
}
public class ConcreteProduct1 implements Product {
@Override
public void show() {
System.out.println("i am ConcreteProduct1");
}
}
public class ConcreteProduct2 implements Product {
@Override
public void show() {
System.out.println("i am ConcreteProduct2");
}
}
public abstract class AbstractFactory {
public abstract Product newProduct();
}
public class ConcreteFactory1 extends AbstractFactory{
@Override
public Product newProduct() {
return new ConcreteProduct1();
}
}
public class ConcreteFactory2 extends AbstractFactory{
@Override
public Product newProduct() {
return new ConcreteProduct2();
}
}
客户端代码
public class Client {
public static void main(String[] args) {
// 这里也可使用配置文件读入的一个类名,通过反射获取
AbstractFactory factory = new ConcreteFactory1();
Product product = factory.newProduct();
product.show();
}
}
工厂模式小结
工厂模式就是将实例化对象的代码提取出来,放在一个类中统一管理和维护,达到与主项目的解耦,从而提升项目的扩展性以及维护性
3. 原型模式(ProtoType)
通过原型实例制定创建对象的种类,并通过拷贝这些原型,创建新的对象
优点:
- 客户端无需知道对象创建的细节,简化了对象创建的过程
- java自带的原型模式是基于内存二进制流的复制,在性能上比直接new一个对象更加优良
缺点:
- 需要为每一个类配置一个clone方法
- clone方法位于对象内部,对已有类进行改造石,需要修改代码,违反开闭原则
- 当实现深克隆时,需要编写较为复杂的代码,并且所有的方法都需要实现深克隆,实现较为复杂
应用场景:
- 对象之间相同或者类似
- 创建对象成本大
- 创建一个对象需要繁琐的数据准备
- 系统中大量使用该对象,并且需要给这个对象重新赋值
实现:
- 浅克隆:创建一个对象,新对象的竖向与原来的对象完全相同,并且引用类型也会转向该对象的内存地址
- 深克隆:创建一个对象,属性中的引用对象也会被克隆,创建一个新的对象,不再使用原有的地址
结构图如下
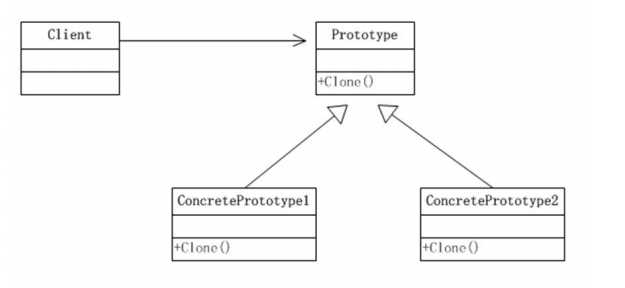
在进行深克隆时,有两种方式,一种就是使用clone,然后自己处理判断逻辑,确实是否需要继续调用克隆,还有一种就是序列化方式,这两种后者会损耗性能,但是维护简单,前者逻辑处理复杂,但是性能较好,因此在继续宁选择是,可以根据业务场景选择。技术没有绝对的好坏,只有最适合的
public class ConcreteProtoType1 implements ProtoType, Serializable, Cloneable {
private static final long serialVersionUID = 1L;
String name;
private ProtoType protoType;
public ConcreteProtoType1(String name, ProtoType protoType) {
this.name = name;
this.protoType = protoType;
}
@Override
public ProtoType clone() {
Object clone = null;
try {
// 调用Object的克隆方法
clone = super.clone();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
return (ProtoType) clone;
}
@Override
public ProtoType deepClone1() {
// 方案一:所有引用的属性都实现深拷贝,然后引用属性统一调用深拷贝方法即可
ConcreteProtoType1 clone = null;
try {
// 调用Object的克隆方法
clone = (ConcreteProtoType1)super.clone();
if(Objects.nonNull(protoType))
clone.setProtoType(protoType.deepClone1());
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
return (ProtoType) clone;
}
@Override
public ProtoType deepClone2() {
// 在这里使用的时序列化,把对象进行序列化,然后再反序列化,也同样可以得到一个新的对象
ByteArrayOutputStream outputStream = null;
ByteArrayInputStream inputStream = null;
ObjectOutputStream objectOutputStream = null;
ObjectInputStream objectInputStream = null;
try {
outputStream = new ByteArrayOutputStream();
objectOutputStream = new ObjectOutputStream(outputStream);
objectOutputStream.writeObject(this);
inputStream = new ByteArrayInputStream(outputStream.toByteArray());
objectInputStream = new ObjectInputStream(inputStream);
return (ProtoType) objectInputStream.readObject();
} catch (Exception e) {
e.printStackTrace();
return null;
} finally {
try {
if (Objects.nonNull(outputStream))
outputStream.close();
if (Objects.nonNull(inputStream))
inputStream.close();
if (Objects.nonNull(objectOutputStream))
objectOutputStream.close();
if (Objects.nonNull(objectInputStream))
objectInputStream.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
@Override
public ProtoType getProtoType() {
return this.protoType;
}
public void setProtoType(ProtoType protoType) {
this.protoType = protoType;
}
@Override
public String toString() {
return "ConcreteProtoType1{" +
"name='" + name + '\'' +
'}';
}
}
调用
public class Client {
public static void main(String[] args) {
ProtoType origin = new ConcreteProtoType1("1", new ConcreteProtoType1("2", null));
ProtoType clone = origin.clone();
long start = System.nanoTime();
ProtoType deepClone1 = origin.deepClone1();
long cloneEnd = System.nanoTime();
ProtoType deepClone2 = origin.deepClone2();
long deepCloneEnd = System.nanoTime();
System.out.println("first clone use time, nano: " + (cloneEnd - start));
System.out.println("second clone use time, nano: " + (deepCloneEnd - cloneEnd));
System.out.println("origin.getProtoType().hashCode() = " + origin.getProtoType().hashCode());
System.out.println("clone.getProtoType().hashCode() = " + clone.getProtoType().hashCode());
System.out.println("deepClone1.getProtoType().hashCode() = " + deepClone1.getProtoType().hashCode());
System.out.println("deepClone2.getProtoType().hashCode() = " + deepClone2.getProtoType().hashCode());
System.out.println("origin reference== clone reference==> " + (origin.getProtoType() == clone.getProtoType()));
System.out.println("origin reference == deepClone1 reference==>" + (origin.getProtoType() == deepClone1.getProtoType()));
System.out.println("origin reference == deepClone2 reference==>" + (origin.getProtoType() == deepClone2.getProtoType()));
}
}
first clone use time, nano: 12100
second clone use time, nano: 9364900
origin.getProtoType().hashCode() = 127618319
clone.getProtoType().hashCode() = 127618319
deepClone1.getProtoType().hashCode() = 1556595366
deepClone2.getProtoType().hashCode() = 194494468
origin reference== clone reference==> true
origin reference == deepClone1 reference==>false
origin reference == deepClone2 reference==>false
设计模式只是提供思想,并非拘泥于代码,我在做无门业务是,由于一个树关系的构建比较复杂,预计未来会有很多个实例都会跟这个树关系是一致的,于是便将树关系提取出来,构建完成之后,基于已经创建的树关系,再进行构建下一个实例。
4. 抽象工厂模式(AbstractFactory)
抽象工厂是一种为访问类提供一个创建一组相关或相互依赖对象的接口,且访问类无需指定所要的产品的具体类就能得到同组的不同等级的产品的模式结构
工厂方法一个实现工厂只有一个产品,但是抽象工厂一个工厂可以有多个产品,因此如果只有一个产品时,抽象工厂就会退化到工厂方法模式
优点:
- 包含上述抽象工厂的优点
- 类内部对产品族中相关联的多等级产品共同管理,而不必专门引入多个新的类进行管理
- 抽象工厂可以保证客户端只是用一个产品的产品组
- 增加程序的可扩展性,当增加一个产品族时,也就是一个具体的工厂,不需要修改源代码,满足开闭原则
缺点
- 当产品族增加一个新的产品的,所有的工厂类都需要修改
应用场景:
- 需要创建的对象时一系列相互关联的或相互依赖的产品族时
- 有多个产品族,但是每次只是用其中一个产品族
根据农场的特点构建UML图
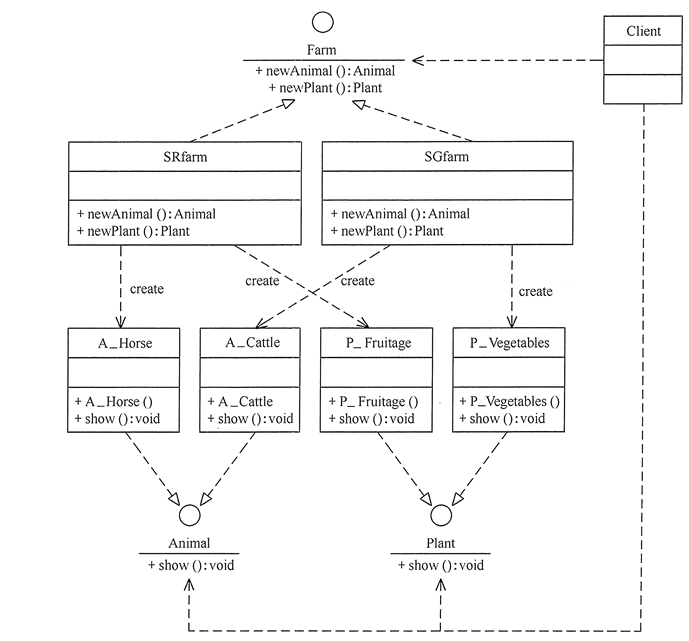
我们可以通过类的名称动态加载对应的实现工厂,这样可以增加一个新的产品族,可以通过配置文件导入解耦
public class Client {
public static void main(String[] args) throws Exception {
String sgFarm = "factory.abs.SGFarm";
Farm farm = (Farm) Class.forName(sgFarm).getDeclaredConstructor().newInstance();
Animal animal = farm.newAnimal();
animal.show();
Plant plant = farm.newPlant();
plant.show();
}
}
展示一下其中一个抽象工厂
public class SRFarm implements Farm {
@Override
public Animal newAnimal() {
return new Horse();
}
@Override
public Plant newPlant() {
return new Fruit();
}
}
5. 建造者模式(Builder)
将一个复杂对象的构造与他的表示分离,是同样的构建过程可以创建不同的表示。也就是将一个复杂的对象分解为多个简单的对象,然后进行一步一步构建。将变与不变相分离。也就是产品的组成部分是不变的,但是每一部分可以灵活选择。
举个例子:建造一辆车。我们会有一张图纸表示,需要一个轮胎,一个发动机,一个车厢,那么我们可以对这三个产品进行抽象化,然后有一个指挥者通过接口进行构建,轮胎可以选择宝马的,发动机选择劳斯莱斯的,车厢 选择五菱的。这样就构建出一个车,其实本质上,这些模块一个都不少。
优点:
- 封装性好,构建与表示分离
- 扩展性好,各个具体建造者相互独立,有利于系统解耦
- 客户端不必知道产品内部细节,建造者可以对创建过程逐步细化,控制细节风险
缺点
- 产品的组成部分必须相同
- 产品内部如果发生变化,则建造者也需要同步修改,增加后期维护成本
使用场景:
- 相同的方法,不同的执行顺序,产生不同的结构
- 多个产品装配到一个对象,产生的结果不同
- 产品类比较复杂,初始化一个对象很复杂,参数较多,并且参数很多有默认值
建造者的UML,当然产品也可以进行抽象化,然后具体建造者持有产品(接口)
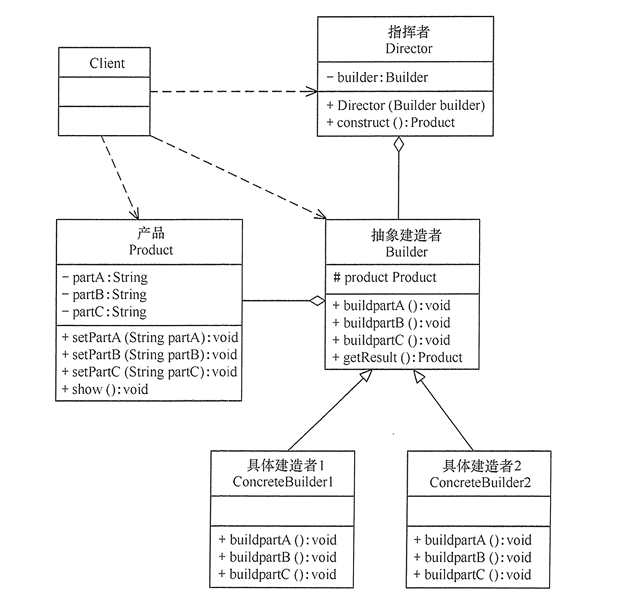
产品代码如下:
public interface Product {
void setPartA(String partA);
void setPartB(String partB);
void setPartC(String partC);
void show();
}
public class ProductA implements Product {
private String partA;
private String partB;
private String partC;
@Override
public void setPartA(String partA) {
this.partA = partA;
}
@Override
public void setPartB(String partB) {
this.partB = partB;
}
@Override
public void setPartC(String partC) {
this.partC = partC;
}
@Override
public void show() {
System.out.println("ProductA{" +
"partA='" + partA + '\'' +
", partB='" + partB + '\'' +
", partC='" + partC + '\'' +
'}');
}
}
建造者代码:
public abstract class Builder {
protected Product product;
public Builder(Product product) {
this.product = product;
}
protected abstract void setPartA();
protected abstract void setPartB();
protected abstract void setPartC();
public Product getResult() {
return product;
}
}
// 其中一个实现
public class ConcreteBuild2 extends Builder {
public ConcreteBuild2(Product product) {
super(product);
}
@Override
protected void setPartA() {
product.setPartA("ConcreteBuild2 setA");
}
@Override
protected void setPartB() {
product.setPartA("ConcreteBuild2 setB");
}
@Override
protected void setPartC() {
product.setPartA("ConcreteBuild3 setC");
}
}
指挥者
public class Director {
private Builder builder;
public Director(Builder builder) {
this.builder = builder;
}
public Product construct(){
// 进行拼装的逻辑放在了这里
builder.setPartA();
builder.setPartB();
builder.setPartC();
return builder.getResult();
}
}
客户端
public class Client {
public static void main(String[] args) {
Builder build = new ConcreteBuild1(new ProductA());
Director director = new Director(build);
Product product = director.construct();
product.show(); // ProductA{partA='ConcreteBuild1 setC', partB='null', partC='null'}
}
}
小结:
其实建造者模式与工厂模式很像,唯一不同就是对复杂对象的创建。如果是简单对象,直接工厂模式创建。如果是需要使用不同的对象来构建一个产品,可以考虑使用建造者模式。
我在业务的编解码服务中,就使用到建造者模式,会基于配置信息,分析接收到的消息类型,来使用不同的建造者。通过结合不同的编解码器最终构造成一个codec,然后对收到的信息进行解码,复杂的逻辑全部放入指挥者,扩展起来就非常容易。
当然也可以使用工厂模式,但修改逻辑就需要修改使用方,为了让使用方无感知,因此采用了建造者模式。这个可以基于业务场景进行选择。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号