使用gradle + idea 构建 spring boot + Spring Data JPA,学习spring data jpa语法
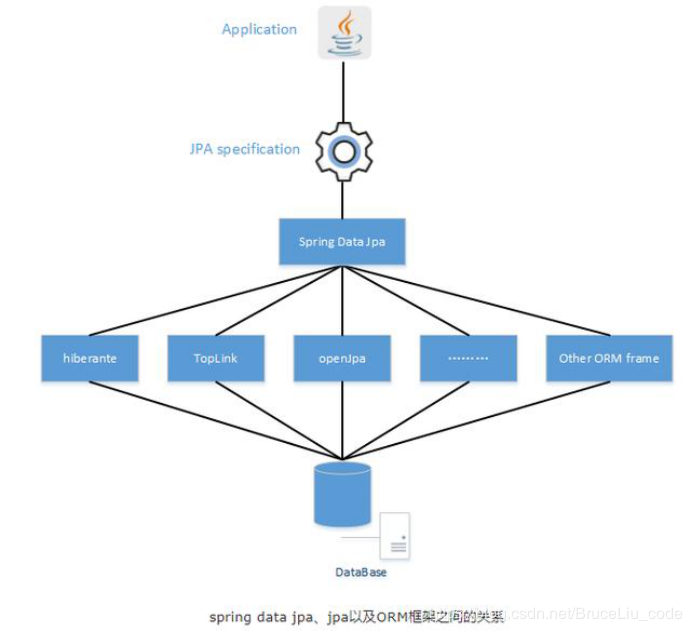
我们这里使用idea + gradle构建项目,使用spring boot + spring data jpa
接下来看一下spring Data JPA的一些注解;
@Entity 标注用于实体类声明语句之前,指出该Java 类为实体类,将映射到指定的数据库表。如声明一个实体类 Customer,它将映射到数据库中的 customer 表上。
@Table 当实体类与其映射的数据库表名不同名时需要使用 @Table 标注说明,该标注与 @Entity 标注并列使用,置于实体类声明语句之前,可写于单独语句行,也可与声明语句同行。@Table 标注的常用选项是 name,用于指明数据库的表名,catalog属性用于指定数据库实例名,shema作用与catalog一样,uniqueContraints选项用于设置约束条件
@Id 标注用于声明一个实体类的属性映射为数据库的主键列。该属性通常置于属性声明语句之前,可与声明语句同行,也可写在单独行上。
@GeneratedValue 用于标注主键的生成策略,通过 strategy 属性指定。默认情况下,JPA 自动选择一个最适合底层数据库的主键生成策略:SqlServer 对应 identity,MySQL 对应 auto increment。 在 javax.persistence.GenerationType 中定义了以下几种可供选择的策略:
IDENTITY:采用数据库 ID自增长的方式来自增主键字段,Oracle 不支持这种方式;适用于MySQL和SQLServer AUTO:JPA自动选择合适的策略,是默认选项, 会自动生成一个序列表,通用性比较强。但是MySQL有自增,所以用的比较少 SEQUENCE(序列,适用于Oracle数据库):通过序列产生主键,通过 @SequenceGenerator注解指定序列名,MySql 不支持这种方式 TABLE:通过表产生主键,框架借由表模拟序列产生主键,使用该策略可以使应用更易于数据库移植。
@Column 当实体的属性与其映射的数据库表的列不同名时需要使用@Column 标注说明,该属性通常置于实体的属性声明语句之前,还可与 @Id 标注一起使用。
-
@Column 标注的常用属性是 name,用于设置映射数据库表的列名。此外,该标注还包含其它多个属性,如:unique 、nullable、length 等。
-
@Column 标注的 columnDefinition 属性: 表示该字段在数据库中的实际类型.通常 ORM 框架可以根据属性类型自动判断数据库中字段的类型,但是对于Date类型仍无法确定数据库中字段类型究竟是DATE,TIME还是TIMESTAMP.此外,String的默认映射类型为VARCHAR, 如果要将 String 类型映射到特定数据库的 BLOB 或TEXT 字段类型.
@Column标注也可置于属性的getter方法之前
@Basic 表示一个简单的属性到数据库表的字段的映射,对于没有任何标注的 getXxxx() 方法,默认即为
@Basic fetch: 表示该属性的读取策略,有 EAGER 和 LAZY 两种,分别表示主支抓取和延迟加载,默认为 EAGER.
optional:表示该属性是否允许为null, 默认为true
@Transient
在核心的 Java API 中并没有定义 Date 类型的精度(temporal precision).而在数据库中,表示 Date 类型的数据有 DATE, TIME, 和 TIMESTAMP 三种精度(即单纯的日期,时间,或者两者 兼备). 在进行属性映射时可使用@Temporal注解来调整精度。
项目构建直接使用idea + gradle构建项目
build.gradle文件
plugins {
id 'org.springframework.boot' version '2.2.5.RELEASE'
id 'io.spring.dependency-management' version '1.0.9.RELEASE'
id 'java'
}
group = 'com.yang'
version = '0.0.1-SNAPSHOT'
sourceCompatibility = '13'
repositories {
maven { url 'http://maven.aliyun.com/nexus/content/groups/public/' }
maven{ url 'http://maven.aliyun.com/nexus/content/repositories/jcenter'}
mavenCentral()
}
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
compile('mysql:mysql-connector-java')
compile('org.springframework.boot:spring-boot-starter-web')
testImplementation('org.springframework.boot:spring-boot-starter-test') {
exclude group: 'org.junit.vintage', module: 'junit-vintage-engine'
}
}
test {
useJUnitPlatform()
}
首先看一下application.yml
spring: datasource: # mysql 8.0+ 需要使用带cj的驱动 driverClassName: com.mysql.cj.jdbc.Driver url: jdbc:mysql://localhost:3306/jpa?useUnicode=true&characterEncoding=utf8 username: root password: mysql jpa: hibernate: # 这个就是更新表,如果字段变化就更新,没有就不更新,create 就是不管什么情况都会删除原来的表并新建 ddlAuto: update showSql: true server: port: 8090
package com.yang.demo.entity; import javax.persistence.*; import java.util.Date; /** * User表 */ @Entity @Table(name = "user") public class User { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) // 设置自增 private Long id; // 映射字段如果跟数据库一致可以不用写 private String username; // name 指定与数据库中字段的映射关系,unique是否唯一,nullable是否可为空, 可以指定长度,string默认字符串长度是255 // columnDefinition 指定类型 String映射到数据库中字段就是varchar @Column(name = "u_sex", unique = false, nullable = true, length = 20, columnDefinition = "text") private String sex; // 时间精确到天,默认格式是datetime,时间精确到秒,也可以修改为时间戳 @Temporal(TemporalType.DATE) private Date createTime; // 这个字段就是不与数据库进行映射 @Transient private String noUse; public Long getId() { return id; } public void setId(Long id) { this.id = id; } public String getUsername() { return username; } public void setUsername(String username) { this.username = username; } public String getSex() { return sex; } public void setSex(String sex) { this.sex = sex; } public Date getCreateTime() { return createTime; } public void setCreateTime(Date createTime) { this.createTime = createTime; } public String getNoUse() { return noUse; } public void setNoUse(String noUse) { this.noUse = noUse; } @Override public String toString() { return "User{" + "id=" + id + ", username='" + username + '\'' + ", sex='" + sex + '\'' + ", createTime=" + createTime + ", noUse='" + noUse + '\'' + '}'; } }
接下来,看一下这些实现方法,首先,spring data jpa 已经为我们封装好sql,我们只需要在dao层继承接口,就可以进行使用
package com.yang.demo.dao; import com.yang.demo.entity.User; import org.springframework.data.jpa.repository.JpaRepository; import org.springframework.data.jpa.repository.JpaSpecificationExecutor; public interface UserDao extends JpaRepository<User, Long>, JpaSpecificationExecutor<User> { }
JpaRepository中,User是实体类,Long是主键ID的类型,我们首先看一下JpaRepository的继承关系图,接下来看一下这些接口,并测试一下。
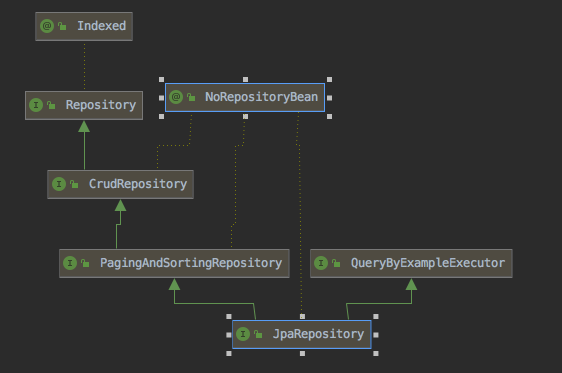
@NoRepositoryBean public interface JpaRepository<T, ID> extends PagingAndSortingRepository<T, ID>, QueryByExampleExecutor<T> { /* * 获取所有 */ @Override List<T> findAll(); /* * 获取所有,可以进行排序 */ @Override List<T> findAll(Sort sort); /* * 获取所有传入ID的对象 */ @Override List<T> findAllById(Iterable<ID> ids); /* * 保存所有 */ @Override <S extends T> List<S> saveAll(Iterable<S> entities); /** * 刷新 */ void flush(); /** * Saves an entity and flushes changes instantly. * * 当发生改变我们没有提交,可以帮助刷新*/ <S extends T> S saveAndFlush(S entity); /** * * @param entities 根据传入的对象删除 */ void deleteInBatch(Iterable<T> entities); /** * 删除数据库中这个实体对应表的所有数据. */ void deleteAllInBatch(); /** * 根据id查询出来的对象不为null,但是对象里面的所有属性全部为null*/ T getOne(ID id); /* * 根据条件查询 */ @Override <S extends T> List<S> findAll(Example<S> example); /* * 根据条件以及排序规则进行查询 */ @Override <S extends T> List<S> findAll(Example<S> example, Sort sort); }
接下来进行测试
package com.yang.demo; import com.yang.demo.dao.UserDao; import com.yang.demo.entity.User; import org.junit.jupiter.api.Test; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.test.context.SpringBootTest; import org.springframework.data.domain.Example; import org.springframework.data.domain.Sort; import java.util.ArrayList; import java.util.Date; import java.util.List; @SpringBootTest class DemoApplicationTests { @Autowired UserDao userDao; @Test public void testJpaRepository() { // 查找所有 // Hibernate: select user0_.id as id1_0_, user0_.create_time as create_t2_0_, user0_.u_sex as u_sex3_0_, user0_.username as username4_0_ // from user user0_ List<User> users = userDao.findAll(); for (User user : users) { System.out.println(user); // User{id=7, username='xiao ming', sex='男', createTime=2020-02-29, noUse='null'} // User{id=8, username='小红', sex='女', createTime=2020-02-29, noUse='null'} } // 获取所有,根据id降序 Sort.Order order = new Sort.Order(Sort.Direction.DESC, "id"); ArrayList<Sort.Order> orders = new ArrayList<>(); orders.add(order); Sort sort = Sort.by(orders); // Hibernate: select user0_.id as id1_0_, user0_.create_time as create_t2_0_, user0_.u_sex as u_sex3_0_, user0_.username as username4_0_ // from user user0_ order by user0_.id desc List<User> userSorts = userDao.findAll(sort); for (User userSort : userSorts) { System.out.println(userSort); //User{id=8, username='小红', sex='女', createTime=2020-02-29, noUse='null'} //User{id=7, username='xiao ming', sex='男', createTime=2020-02-29, noUse='null'} } // 根据ID查询 List<Long> ids = new ArrayList<>(); ids.add(1L); ids.add(2L); // Hibernate: select user0_.id as id1_0_, user0_.create_time as create_t2_0_, user0_.u_sex as u_sex3_0_, user0_.username as username4_0_ // from user user0_ where user0_.id in (? , ?) List<User> allById = userDao.findAllById(ids); for (User userById : allById) { System.out.println(userById); // none } // 保存所有 User user2 = new User(); user2.setUsername("xiao ming"); user2.setCreateTime(new Date()); user2.setSex("男"); User user3 = new User(); user3.setUsername("小红"); user3.setCreateTime(new Date()); user3.setSex("女"); List<User> userList = new ArrayList<>(); userList.add(user2); userList.add(user3); // Hibernate: insert into user (create_time, u_sex, username) values (?, ?, ?) // Hibernate: insert into user (create_time, u_sex, username) values (?, ?, ?) List<User> users1 = userDao.saveAll(userList); for (User user1 : users1) { System.out.println(user1); //User{id=9, username='xiao ming', sex='男', createTime=Sun Mar 01 10:58:08 CST 2020, noUse='null'} //User{id=10, username='小红', sex='女', createTime=Sun Mar 01 10:58:08 CST 2020, noUse='null'} } // 根据传入对象删除,无返回对象 // userDao.deleteInBatch(users1); // 根据ID查询,如果查询不到就会报错 // User one = userDao.getOne(10L); // System.out.println(one); // 查询,根据对象的示例 // 设置实例 User user = new User(); // 设置查询条件 user.setUsername("xiao ming"); // 定义example Example<User> example = Example.of(user); // select user0_.id as id1_0_, user0_.create_time as create_t2_0_, user0_.u_sex as u_sex3_0_, user0_.username as username4_0_ // from user user0_ where user0_.username=? List<User> all = userDao.findAll(example); for (User user4 : all) { System.out.println(user4); // User{id=7, username='xiao ming', sex='男', createTime=2020-02-29, noUse='null'} // User{id=9, username='xiao ming', sex='男', createTime=2020-02-29, noUse='null'} } } }
接下来看一下PagingAndSortingRepository
@NoRepositoryBean public interface PagingAndSortingRepository<T, ID> extends CrudRepository<T, ID> { /** * 这个JpaRepository重写了这个方法,就会根据排序规则查询所有 */ Iterable<T> findAll(Sort sort); /** * 分页查询*/ Page<T> findAll(Pageable pageable); }
接下来,我们看一下分页查询
@Test public void testPagingAndSort() { // 这个翻页需要设定排序规则,注意字段需要与entity的类一致 Sort.Order order = new Sort.Order(Sort.Direction.DESC, "createTime"); List<Sort.Order> orders = new ArrayList<>(); orders.add(order); // sort需要传入的是集合 Sort sort = Sort.by(orders); // 查询需求 // 第2页 int pageIndex = 2; // 每页大小 int pageSize = 2; Pageable pageable = PageRequest.of(pageIndex - 1, pageSize, sort); Page<User> all = userDao.findAll(pageable); System.out.println("总记录: " + all.getTotalElements()); // 4 System.out.println("总页数: " + all.getTotalPages()); // 2 System.out.println("当前第几页: : " + all.getNumber()); // 1 从0开始 System.out.println("当前页条数: : " + all.getNumberOfElements()); // 2 for (User user : all) { System.out.println(user); // User{id=9, username='xiao ming', sex='男', createTime=2020-02-29, noUse='null'} // User{id=10, username='小红', sex='女', createTime=2020-02-29, noUse='null'} } }
接下来看一下CrudRepository里面的方法
@NoRepositoryBean public interface CrudRepository<T, ID> extends Repository<T, ID> { /** * 保存 */ <S extends T> S save(S entity); /** * 保存所有,跟JPARespository中一样 */ <S extends T> Iterable<S> saveAll(Iterable<S> entities); /** * 根据ID查询,查不到不会报错 */ Optional<T> findById(ID id); /** * 根据ID查询是否存在 */ boolean existsById(ID id); /** * 查询所有 */ Iterable<T> findAll(); /** * 根据ID可迭代对象查询 */ Iterable<T> findAllById(Iterable<ID> ids); /** * 查询这个表中一共多少条 */ long count(); /** * 根据ID删除 */ void deleteById(ID id); /** * 根据对象删除 */ void delete(T entity); /** * 根据传入的对象删除 */ void deleteAll(Iterable<? extends T> entities); /** * 删除整个表数据 */ void deleteAll(); }
这些都是一些基础的方法,比较简单,来看一下
@Test public void testCurdRepository() { // 保存 User user = new User(); user.setUsername("小明1"); user.setSex("男"); user.setCreateTime(new Date()); // Hibernate: insert into user (create_time, u_sex, username) values (?, ?, ?) User user1 = userDao.save(user); // User{id=12, username='小明1', sex='男', createTime=Sun Mar 01 12:01:35 CST 2020, noUse='null'} System.out.println(user1); // 保存所有 user1.setUsername("小明2"); User user2 = new User(); user2.setUsername("小明3"); user2.setSex("男"); user2.setCreateTime(new Date()); List<User> userList = new ArrayList<>(); userList.add(user1); userList.add(user1); // 连续添加两个user1 List<User> userList1 = userDao.saveAll(userList); // 从输出结果可以看出,逐条保存,如果有ID就只是更新,不是保存 for (User user3 : userList1) { System.out.println(user3); // User{id=12, username='小明2', sex='男', createTime=Sun Mar 01 12:01:35 CST 2020, noUse='null'} //User{id=12, username='小明2', sex='男', createTime=Sun Mar 01 12:01:35 CST 2020, noUse='null'} } // 根据ID查询 // Hibernate: select user0_.id as id1_0_0_, user0_.create_time as create_t2_0_0_, user0_.u_sex as u_sex3_0_0_, user0_.username as username4_0_0_ // from user user0_ where user0_.id=? Optional<User> user4 = userDao.findById(100L); // Optional.empty System.out.println(user4); // 根据Id判断是否存在 // Hibernate: select count(*) as col_0_0_ from user user0_ where user0_.id=? System.out.println(userDao.existsById(100L)); // false // 查询所有 // Hibernate: select user0_.id as id1_0_, user0_.create_time as create_t2_0_, user0_.u_sex as u_sex3_0_, user0_.username as username4_0_ // from user user0_ List<User> users = userDao.findAll(); for (User user3 : users) { System.out.println(user3); //User{id=7, username='xiao ming', sex='男', createTime=2020-02-29, noUse='null'} //User{id=8, username='小红', sex='女', createTime=2020-02-29, noUse='null'} //User{id=9, username='xiao ming', sex='男', createTime=2020-02-29, noUse='null'} //User{id=10, username='小红', sex='女', createTime=2020-02-29, noUse='null'} //User{id=11, username='小明2', sex='男', createTime=2020-02-29, noUse='null'} //User{id=12, username='小明2', sex='男', createTime=2020-02-29, noUse='null'} } // 查询总数 // Hibernate: select count(*) as col_0_0_ from user user0_ System.out.println("总数:" + userDao.count()); // 6 // 根据传入的ID删除 // 查找id为7的 Optional<User> user3 = userDao.findById(8L); System.out.println(user3); // 数据不存在会报错 userDao.deleteById(8L); System.out.println(userDao.existsById(8L)); // 根据传入对象删除 // getOne是懒加载,如果直接删除这个对象会报错,需要使用,因此使用findById // User user5 = userDao.getOne(9L); // findById 返回结果是Optional<T>,调用get即刻返回对象 // Hibernate: select user0_.id as id1_0_0_, user0_.create_time as create_t2_0_0_, user0_.u_sex as u_sex3_0_0_, user0_.username as username4_0_0_ // from user user0_ where user0_.id=? User user5 = userDao.findById(9L).get(); System.out.println(user5); // Hibernate: delete from user where id=? userDao.delete(user5); System.out.println(userDao.existsById(9L)); // 删除所有 // 看一下表中数据 System.out.println(userDao.count()); // 6 //Hibernate: delete from user where id=? //Hibernate: delete from user where id=? //Hibernate: delete from user where id=? //Hibernate: delete from user where id=? //Hibernate: delete from user where id=? //Hibernate: delete from user where id=? userDao.deleteAll(); // 再看一下表中数据 System.out.println(userDao.count()); // 0 }
上面是常用的,但是感觉还是缺点什么,于是作者又搞了一个接口QueryByExampleExecutor
public interface QueryByExampleExecutor<T> { /** * 根据传入的条件查询一个 */ <S extends T> Optional<S> findOne(Example<S> example); /** * 根据传入的条件查询所有 */ <S extends T> Iterable<S> findAll(Example<S> example); /** * 根据查询条件以及排序规则查询所有 */ <S extends T> Iterable<S> findAll(Example<S> example, Sort sort); /** * 根据查询条件以及分页规则,查询 */ <S extends T> Page<S> findAll(Example<S> example, Pageable pageable); /** * 根据查询条件,进行计数 */ <S extends T> long count(Example<S> example); /** * 根据查询条件,判断表中是否存在 */ <S extends T> boolean exists(Example<S> example); }
接下来看一下测试
@Test public void testQueryByExampleExecutor() { // 测试数据 List<User> all = userDao.findAll(); for (User user : all) { System.out.println(user); // User{id=18, username='xiao ming', sex='男', createTime=2020-02-29, noUse='null'} //User{id=19, username='小红', sex='女', createTime=2020-02-29, noUse='null'} //User{id=20, username='xiao ming', sex='男', createTime=2020-02-29, noUse='null'} //User{id=21, username='小宁', sex='男', createTime=2020-02-29, noUse='null'} //User{id=22, username='小红', sex='女', createTime=2020-02-29, noUse='null'} //User{id=23, username='小美', sex='女', createTime=2020-02-29, noUse='null'} //User{id=24, username='小梅', sex='女', createTime=2020-02-29, noUse='null'} } // 设置查询条件 User user = new User(); user.setId(18L); Example<User> of = Example.of(user); // 根据传入条件查询一个,如果不是唯一的会报错 // Hibernate: select user0_.id as id1_0_, user0_.create_time as create_t2_0_, user0_.u_sex as u_sex3_0_, user0_.username as username4_0_ // from user user0_ where user0_.id=18 Optional<User> one = userDao.findOne(of); // Optional[User{id=18, username='xiao ming', sex='男', createTime=2020-02-29, noUse='null'}] System.out.println(one); // 根据传入条件查询所有 // 设置查询条件 User user1 = new User(); user1.setUsername("小红"); Example<User> of1 = Example.of(user1); // Hibernate: select user0_.id as id1_0_, user0_.create_time as create_t2_0_, user0_.u_sex as u_sex3_0_, user0_.username as username4_0_ // from user user0_ where user0_.username=? List<User> all1 = userDao.findAll(of1); for (User user2 : all1) { System.out.println(user2); // User{id=19, username='小红', sex='女', createTime=2020-02-29, noUse='null'} // User{id=22, username='小红', sex='女', createTime=2020-02-29, noUse='null'} } // 根据条件技术 // Hibernate: select count(user0_.id) as col_0_0_ from user user0_ where user0_.id=18 System.out.println(userDao.count(of)); //1 // Hibernate: select count(user0_.id) as col_0_0_ from user user0_ where user0_.username=? System.out.println(userDao.count(of1)); //2 // 根据查询条件判断是否存在 // Hibernate: select user0_.id as id1_0_, user0_.create_time as create_t2_0_, user0_.u_sex as u_sex3_0_, user0_.username as username4_0_ from user user0_ where user0_.id=18 System.out.println(userDao.exists(of)); // true // Hibernate: select user0_.id as id1_0_, user0_.create_time as create_t2_0_, user0_.u_sex as u_sex3_0_, user0_.username as username4_0_ from user user0_ where user0_.username=? System.out.println(userDao.exists(of1)); // true // 查询需求 // 第2页 int pageIndex = 1; // 每页大小 int pageSize = 1; // 排序 Sort.Order order = new Sort.Order(Sort.Direction.DESC, "id"); ArrayList<Sort.Order> orders = new ArrayList<>(); orders.add(order); Sort sort = Sort.by(orders); Pageable pageable = PageRequest.of(pageIndex - 1, pageSize, sort); // 根据查询条件以及分页规则查询 // Hibernate: select user0_.id as id1_0_, user0_.create_time as create_t2_0_, user0_.u_sex as u_sex3_0_, user0_.username as username4_0_ // from user user0_ where user0_.username=? order by user0_.id desc limit ? Page<User> all2 = userDao.findAll(of1, pageable); System.out.println("总记录: " + all2.getTotalElements()); // 2 System.out.println("总页数: " + all2.getTotalPages()); // 2 System.out.println("当前第几页: : " + all2.getNumber()); // 0 从0开始 System.out.println("当前页条数: : " + all2.getNumberOfElements()); // 1 for (User user2 : all2) { System.out.println(user2); // User{id=22, username='小红', sex='女', createTime=2020-02-29, noUse='null'} } }
这个就是大体算法,我们还可以使用自定义sql,注解方式,只要保持jpa规范就好,至于一对一,一对多,多对多就是@anyToMany之类的,一般都不使用,因为有外键不舒服,一般做逻辑一致。
另外对于对于多表操作,一定需要开启事务。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号