
大数据平台Hive数据迁移至阿里云ODPS平台流程与问题记录
一、背景介绍
最近几天,接到公司的一个将当前大数据平台数据全部迁移到阿里云ODPS平台上的任务。而申请的这个ODPS平台是属于政务内网的,因考虑到安全问题当前的大数据平台与阿里云ODPS的网络是不通的,所以不能使用数据采集工作流模板。
然而,考虑到原大数据平台数据量并不是很大,可以通过将原大数据平台数据导出到CSV文件,然后再将CSV文件导入到ODPS平台。在这个过程中踩的坑有点多,所以想写篇文档作为记录。
二、大数据平台Hive数据导出到本地
编写export_data.sh脚本如下:
#!/bin/bash # #导出数据 hive -e "use swt_ods; show tables;" > /root/hive_data/table_names.txt for table_name in `cat /root/hive_data/table_names.txt` do hive -e "select * from swt_ods.$table_name;" > /root/hive_data/export_data/$table_name".csv" sed -i 's/\t/,/g' /root/hive_data/export_data/$table_name".csv" done
执行脚本,并将数据/root/hive_data/export_data/目录下载到本地。
三、ODPS平台创建对应表
3.1 导出原大数据平台Hive建表语句
编写export_create_table_sql.sh脚本如下:
#!/bin/bash # #导出DDL hive -e "use swt_ods; show tables;" > /root/hive_data/table_names.txt for table_name in `cat /root/hive_data/table_names.txt` do hive -e "show create table swt_ods.$table_name;" > /root/hive_data/export_create_table_sql/$table_name tac $table_name| sed 1,14d| tac > /root/hive_data/export_create_table_sql/$table_name".sql" rm -f $table_name echo ";" >> /root/hive_data/export_create_table_sql/$table_name".sql" cat /root/hive_data/export_create_table_sql/$table_name".sql" >> /root/hive_data/export_create_table_sql/all.sql done
执行脚本,并将/root/hive_data/export_create_table_sql/all.sql下载到本地。
3.2 在ODPS中创建对应的表
3.2.1 下载并配置MaxCompute 命令行工具
点击压缩包链接下载
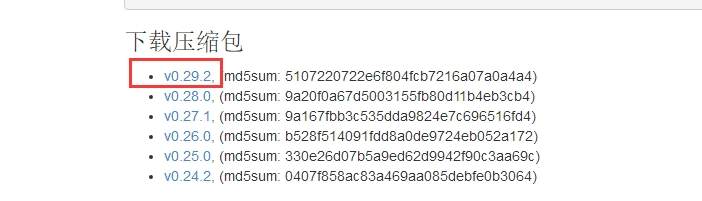
在Windows中,解压即安装。在解压目录中配置odps_config.ini文件
在解压目录odpscmd_public\bin目录下,双击运行odpscmd.bat。
3.2.2 使用命令行创建表
将all.sql中的建表语句粘贴到命令行执行即可创建表。
3.2.3 建表过程遇到的问题
主要问题:
一是,hive中建表的属性的数据类型和MaxCompute的数据类型不对应。可以参考数据类型说明文档,https://help.aliyun.com/document_detail/27821.html?spm=a2c4g.11186623.2.5.X8fmyl 。例如:decimal类型不需要添加精度,如果写成decimal(a,b)则会报错;MaxCompute没有date类型,只有datetime类型;没有char类型。所以要根据MaxCompute的数据类型,对hive的建表语句进行调整。
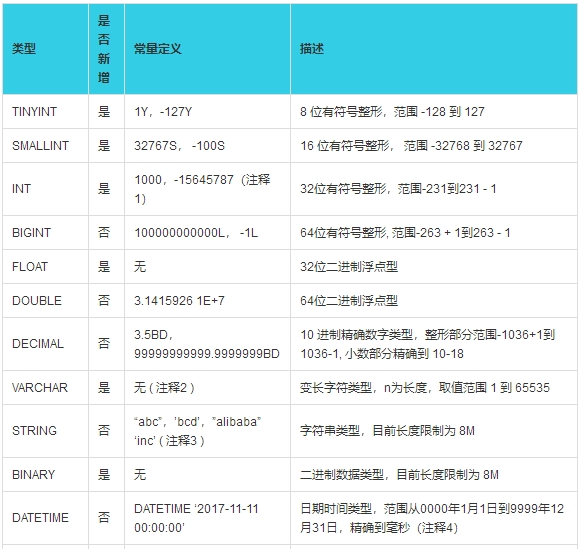

二是,涉及到新数据类型(TINYINT、SMALLINT、 INT、 FLOAT、VARCHAR、TIMESTAMP BINARY),需在SQL语句前加语句set odps.sql.type.system.odps2=true;,执行时set语句和SQL语句一起提交执行。
在解决完上述两个问题后,在重复步骤二,在命令行中批量执行建表语句。
四、本地数据导入到ODPS平台
4.1 命令行使用tunnel命令导入数据
使用命令行的方式批量导入数据到对应的表中。
tunnel上传数据的命令为:tunnel upload [options] <path> <[project.]table[/partition]>。详见:https://help.aliyun.com/document_detail/27833.html?spm=a2c4g.11186623.2.1.rLlM5i
例如:tunnel upload C:\PATH\table_name.csv project_name.table_name;
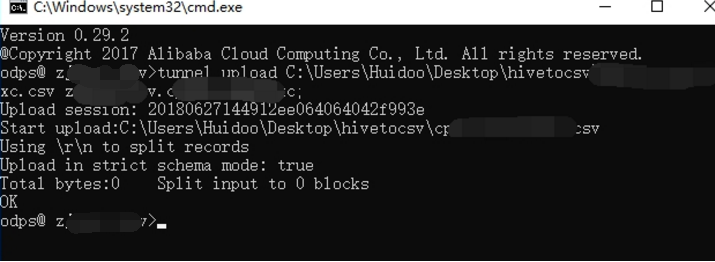
4.2 导入数据遇到的主要问题
4.2.1 decimal类型数据无法插入空值
问题描述:
在导入数据时报format error, decimal nullcontent错误。
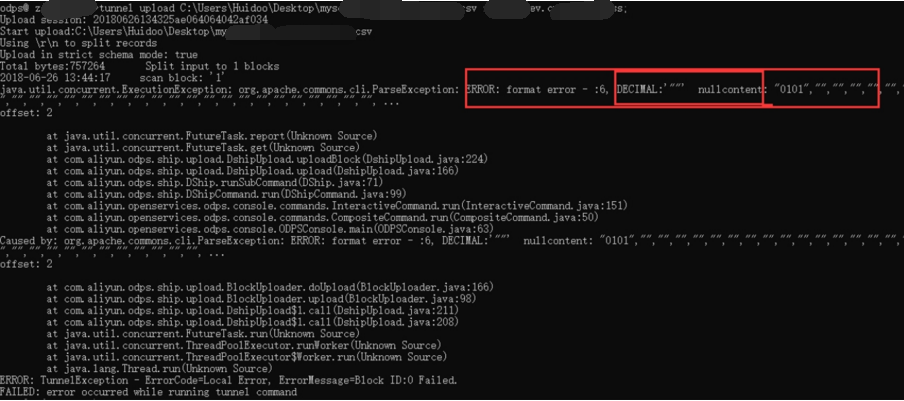
可能需要加什么选项或者参数可以解决,但是在查看tunnel upload命令的详细介绍后也没有找到使用命令行来解决这个问题的方法。
解决方法:
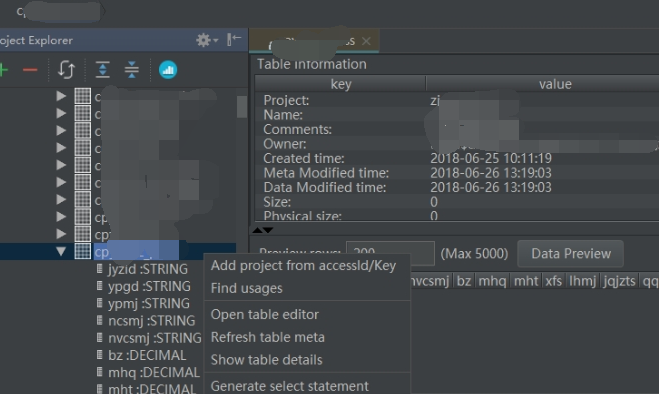
使用MaxCompute Studio 导入数据可以解决上述问题。MaxCompute Studio安装及介绍可参看文档,https://help.aliyun.com/document_detail/50889.html?spm=a2c4g.11186623.6.745.ZVGpPm
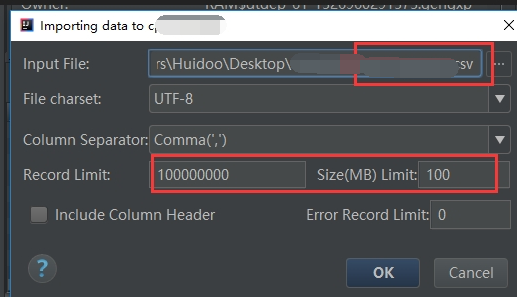
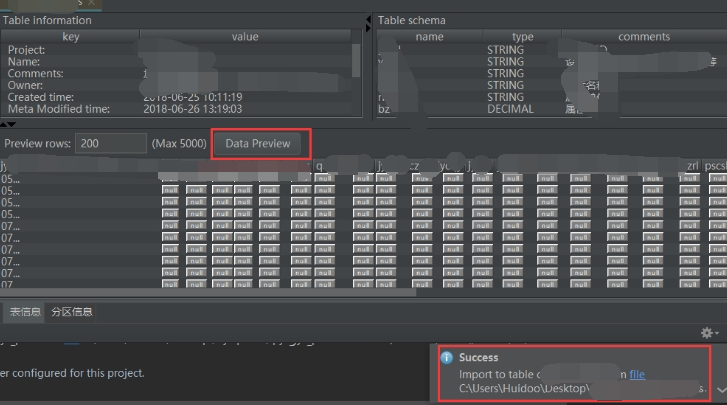
4.2.2 原始数据存在的问题
问题描述:
在导入数据时报column missmatch错误。
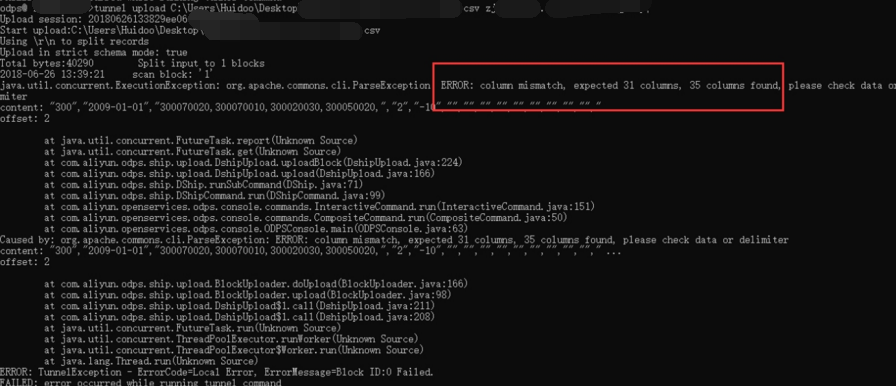
解决方法:
经检查原始数据,可以发现数据中存在列,该列的值中含有逗号。而数据导入按逗号作为列分隔符,所以会出现数据列数大于表的列数。因为这样的表比较少,所以直接修改数据中那一列中的逗号为其他符号,然后再导入。
作者:Huidoo_Yang
本文版权归作者Huidoo_Yang和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号