[ETL] Flume 理论与demo(Taildir Source & Hdfs Sink)
一、Flume简介
1. Flume概述
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
2. Flume系统功能
- 日志收集
Flume最早是Cloudera提供的日志收集系统,目前是Apache下的一个孵化项目,Flume支持在日志系统中定制各类数据发送方,用于收集数据。
- 数据处理
Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力, Flume提供了从console(控制台)、RPC(Thrift-RPC)、text(文件)、tail(UNIX tail)、syslog(syslog日志系统,支持TCP和UDP2种模式),exec(命令执行)等数据源上收集数据的能力。
3. Flume的工作方式
Flume-og采用了多Master的方式。为了保证配置数据的一致性,Flume引入了ZooKeeper,用于保存配置数据,ZooKeeper本身可保证配置数据的一致性和高可用,另外,在配置数据发生变化时,ZooKeeper可以通知Flume Master节点。Flume Master间使用gossip协议同步数据。
Flume-ng最明显的改动就是取消了集中管理配置的 Master 和 Zookeeper,变为一个纯粹的传输工具。Flume-ng另一个主要的不同点是读入数据和写出数据现在由不同的工作线程处理(称为 Runner)。 在 Flume-og 中,读入线程同样做写出工作(除了故障重试)。如果写出慢的话(不是完全失败),它将阻塞 Flume 接收数据的能力。这种异步的设计使读入线程可以顺畅的工作而无需关注下游的任何问题。
4. Flume的安装
如果使用Apache-Flume的话只要上传安装包到服务器,然后解压,再配置一下环境变量即可。本文使用CDH-5.12.2安装Flume。
二、Flume工作原理及组件详解
1. Flume工作原理
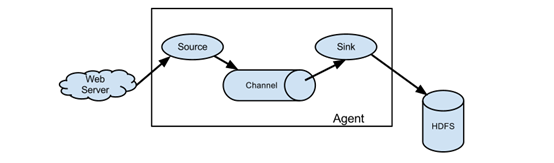
Flume的主要工作就是启动一个Agent,一个Agent由三个部分组成,Source、Sink和Channel。Source表示数据从哪里来,Sink表示数据收集到哪里去,Channel是一个缓冲区。更详细介绍可以参看官方文档。
2. Source组件
对于Source和Sink则根据不同的需求有很多种写法。例如Source可以直接从一个文件/目录中去取数据,也可以别人直接给你传数据。所以,总的来说Source只有两类,一类是主动的Source、一类是被动的Source。
主动的Source就是将Source配置成主动的到别人那里去拿,主动的Source与被动的Source不同,它不是一个服务。主动的source有Exec Source、Spooling Directory Source、Taildir Source、Kafka Source等。
被动的Source就是别人给发过来,前提是Flume机器的source一定是一个服务,可以是Http协议、tcp协议、Rcp协议的服务,规定是哪种协议的服务,B机器就按那种协议去发。总之,被动的Source就是一种服务,至于使用什么协议就看实际需求。被动的source有Avro Source、Thrift Source、JMS Source、NetCat Source等。
3. Sink组件
一般来说,Sink没有主动和被动之分。如果要将收集到的数据放到HDFS上的话,那么Sink就是Hdfs的客户端;如果放到Kafka中,那么Sink就是Kafka的客户端。总之,Sink一般都是做客户端的。
4. Channel组件
对于Channel。只有两种情况,一种缓冲在内存中,一种缓冲在磁盘中。
三、Demo(Taildir Source & Hdfs Sink)
1. Taildir Source

相比于Spooldir Source,Taildir Source做了一些优化。Spooldir Source读取目录时,文件在很短的时间内不能修改,否则会报错,导致Flume终止。而我们经常需要上传较大文件,当文件达到几MB或者十几MB,Flume就会报错。当然,可以对Flume的源代码进行修改,来解决这个问题(可参见Flume Spooldir 源的一些问题)。Flume 1.7之后增加了Taildir Source,这个Source也可以解决这个问题。
其中,channels,type,filegroups,filegroups.<filegroupName>是必配属性。type=TAILDIR;filegroups是给若干个目录取别名,例如 g1 g2;filegroups.<filegroupName>是设置对应目录(g1或g2)下的文件匹配规则。
2. HDFS Sink
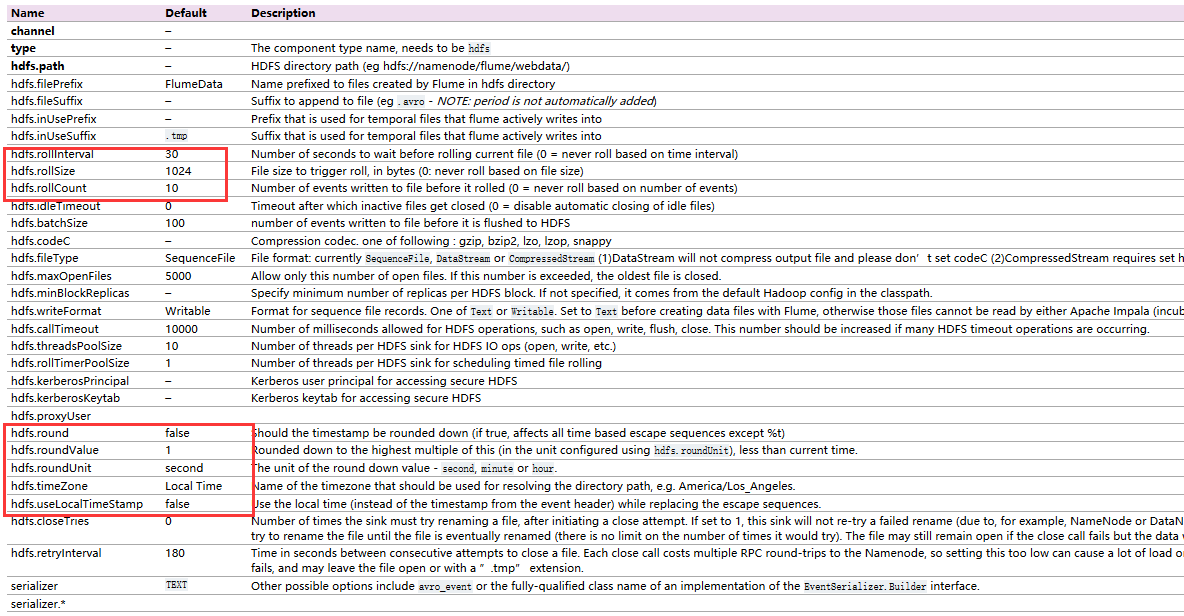
- 属性的配置
配置基本属性。其中,channel、type、hdfs.path是必配属性。type=hdfs;hdfs.path=hdfs://namenode:rpc端口/path。
设置写文件的方式。hdfs.rollInterval,间隔时间,每间隔多少秒写一个文件;hdfs.rollSize,写入一个文件的最大大小;hdfs.rollCount,设置往一个文件中写数据的最大次数。HDFS Sink写数据到HDFS中,有三种不同的方式来写文件。第一种是按设置的hdfs.rollInterval间隔时间来写,达到这么长时间就写一个文件;第二种是根据文件的大小来生成文件,当文件达到hdfs.rollSize设置的大小之后重新写一个文件;第三种是按照设置的hdfs.rollCount每次写的次数,当达到这个极限时关闭流,生成一个文件。如果三个都配了,无论哪个属性先满足设置,就会关闭流,生成一个文件。如果不考虑某种写文件的方式,就将其属性值设置为0。另外,hdfs.idleTimeout,设置超时时间,可以设置超过多少秒都没有数据过来,无论是否满足写文件三个方式的设置,都会关闭流。
配置生成的文件名属性。hdfs.filePrefix,生成的文件的前缀。hdfs.fileSuffix,生成文件的后缀。hdfs.inUsePrefix,是否使用用户的前缀。
配置动态目录属性。需要用到的属性为hdfs.rund,hdfs.roundValue,hdfs.roundUnit,hdfs.useLocalTimeStamp等。例如,本文的flume.conf最后四行配置,可以在hdfs上动态生成目录,每隔10分钟生成一个。
- 变量的使用
如下图所示,可以使用这里的变量来设置一些动态的sink目录,例如按照不同的时间(日期)来作为不同的sink目录。
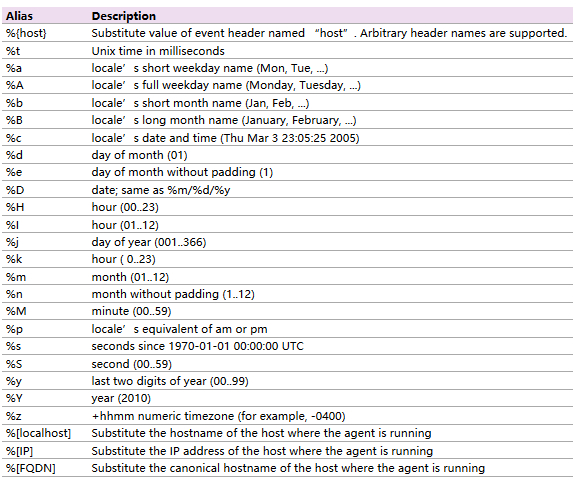
3. 配置flume.conf文件
a1.sources=s a1.channels=c a1.sinks=k a1.sources.s.type=TAILDIR a1.sources.s.filegroups=g1 a1.sources.s.filegroups.g1=/data/.*csv.* a1.sources.s.positionFile=/tmp/myflume/taildir_position.json a1.sources.s.channels=c a1.sources.s.fileHeader=true a1.channels.c.type=memory a1.channels.c.capacity=100 a1.channels.c.transactionCapacity=100 a1.channels.c.keep-alive=10 a1.channels.c.byteCapacity=0 a1.sinks.k.type=hdfs a1.sinks.k.channel=c a1.sinks.k.hdfs.path=hdfs://cdh01:8020/flume/%Y-%m-%d/%H%M a1.sinks.k.hdfs.rollInterval=60 a1.sinks.k.hdfs.rollSize=20971520 a1.sinks.k.hdfs.rollCount=0 a1.sinks.k.hdfs.idleTimeout=60 a1.sinks.k.hdfs.fileType=DataStream a1.sinks.k.hdfs.round=true a1.sinks.k.hdfs.roundValue=10 a1.sinks.k.hdfs.roundUnit=minute a1.sinks.k.hdfs.useLocalTimeStamp=true

 浙公网安备 33010602011771号
浙公网安备 33010602011771号