
Scala编程快速入门系列(一)
目 录
一、Scala概述
二、Scala数据类型
三、Scala函数
四、Scala集合
五、Scala伴生对象
六、Scala trait
七、Actor
八、隐式转换与隐式参数
九、Scala JDBC
由于整理的篇幅较长,所以文章计划分三次发布。
一、Scala概述
1. Scala简介
Scala是一种针对JVM将函数和面向对象技术组合在一起的编程语言。所以Scala必须要有JVM才能运行,和Python一样,Scala也是可以面向对象和面向函数的。Scala编程语言近来抓住了很多开发者的眼球。它看起来像是一种纯粹的面向对象编程语言,而又无缝地结合了命令式和函数式的编程风格。Scala的名称表明,它还是一种高度可伸缩的语言。Scala的设计始终贯穿着一个理念:创造一种更好地支持组件的语言。Scala融汇了许多前所未有的特性,而同时又运行于JVM之上。随着开发者对Scala的兴趣日增,以及越来越多的工具支持,无疑Scala语言将成为你手上一件必不可少的工具。Spark最最源生支持的语言是Scala。Spark主要支持java、Scala、Python和R。Scala的底层协议是akka(异步消息传递)。
2. Scala安装与开发工具
Scala版本使用Scala-2.10.x。
JDK使用jdk-1.8。
开发工具使用Intellij IDEA-2017.3.5。
二、Scala数据类型
1. 数据类型
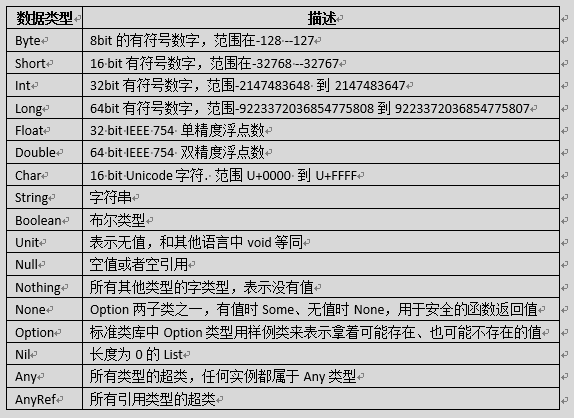
scala拥有和java一样的数据类型,和java的数据类型的内存布局完全一致,精度也完全一致。其中比较特殊的类型有Unit,表示没有返回值;Nothing表示没有值,是所有类型的子类型,创建一个类就一定有一个子类是Nothing;Any是所有类型的超类;AnyRef是所有引用类型的超类;注意最大的类是Object。
上表中列出的数据类型都是对象,也就是说scala没有java中的原生类型。在scala是可以对数字等基础类型调用方法的。例如数字1可以调方法,使用1.方法名。
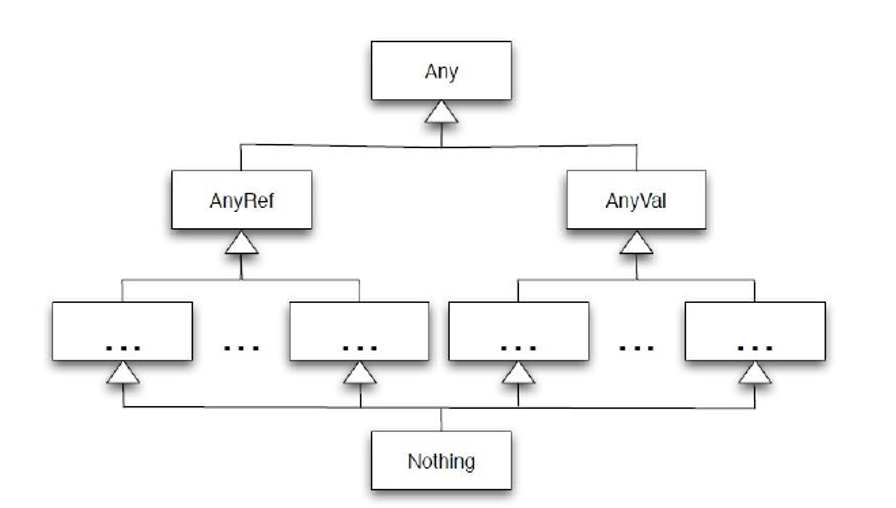
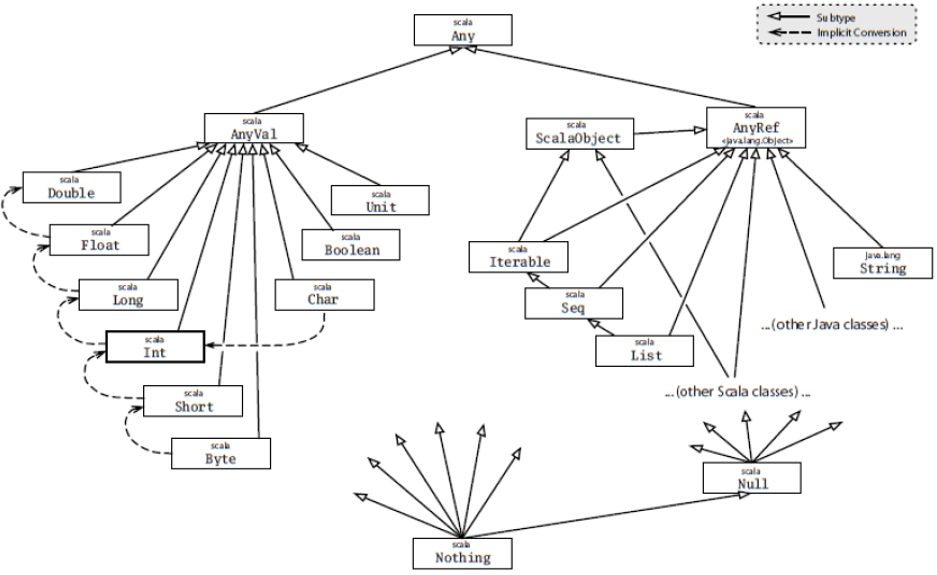
如上两图所示,可见所有类型的基类与Any。Any之后分为两个AnyVal与AnyRef。其中AnyVal是所有数值类型的父类型,AnyRef是所有引用类型的父类型。
与其他语言稍微有点不同的是,Scala还定义了底类型。其中Null类型是所有引用类型的底类型,及所有AnyRef的类型的空值都是Null;而Nothing是所有类型的底类型,对应Any类型;Null与Nothing都表示空。
在基础类型中只有String是继承自AnyRef的,与Java,Scala中的String也是内存不可变对象,这就意味着,所有的字符串操作都会产生新的字符串。其他的基础类型如Int等都是Scala包装的类型,例如Int类型对应的是Scala.Int只是Scala包会被每个源文件自动引用。
标准类库中的Option类型用样例类来表示拿着可能存在、也可能不存在的值。样例子类Some包装了某个值,例如:Some(“Fred”);而样例对象None表示没有值;这比使用空字符串的意图更加清晰,比使用null来表示缺少某值的做法更加安全(避免了空指针异常)。
2. 声明与定义
字段/变量的定义Scala中使用var/val 变量/不变量名称: 类型的方式进行定义,例如
var index1 : Int= 1
val index2 : Int= 1
在Scala中声明变量也可以不声明变量的类型。
- 常量的声明 val
使用val来声明一个常量。与java一样,常量一次赋值不可修改。
val name : String="Yang"//这是完整的写法,可以省略类型,如下所示: val name="Yang"
name="Yang2"//会报错reassignment to val
- 变量的声明 var
var name : String = "Yang" //这是完整的写法,可以省略类型,如下所示: //var name = "Yang" //变量或常量声明时,类型可以省略,Scala内部机制会推断。 name = "Yang2"//变量的值可以修改
- 函数的声明 def
使用def关键字来声明函数。例如:
object HelloScala { def main(args: Array[String]): Unit = { println(f) } val a=1 var b=2 def f=a*b }
def f=a*b;//只是定义a*b表达式的名字,并不求值,在使用的时候求值。这里Scala已经推断出了f函数的返回值类型了,因为a和b都是Int,所以f也是Int。从控制台可以看出这个效果:
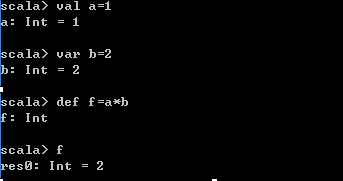
def f=a*b//如果写成val f,这时会直接算出结果。这是定义函数和定义常量的区别。

3. 字符串
- 注释
单行注释://
- 单行字符串
同Java
- 多行字符串/多行注释
scala中还有类似于python的多行字符串表示方式(三个单引号),用三个双引号表示分隔符,如下:
val strs=”””
多行字符串的第一行
多行字符串的第二行
多行字符串的第三行”””
- S字符串
S字符串,可以往字符串中传变量。
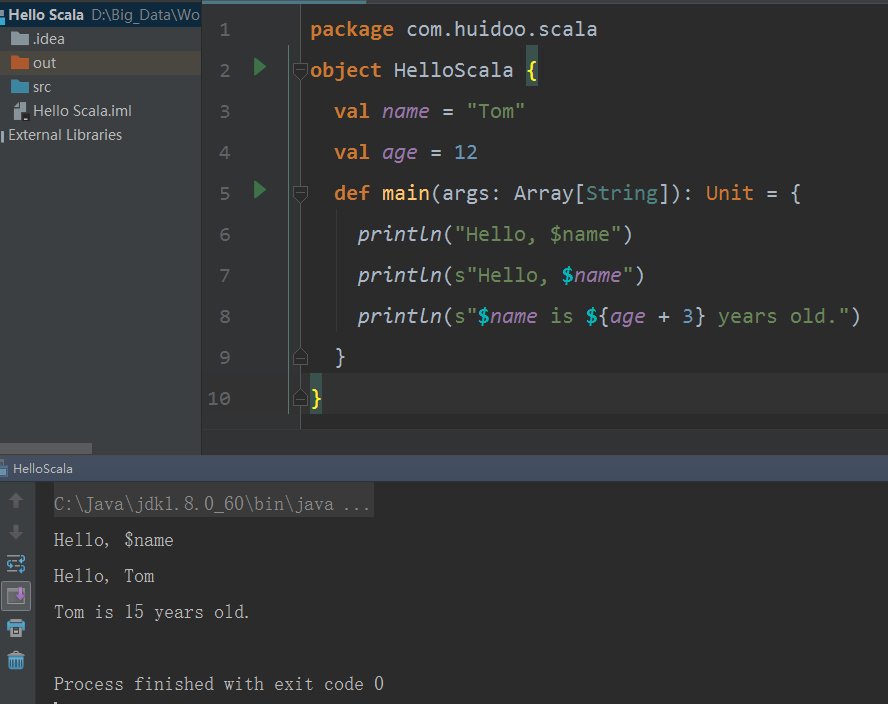
S字符串可以调用变量/常量,在字符串前面加s,在字符串中使用${变量/常量名的数学表达式},来调用变量。如图所示,字符串之前不写s,则原样输出。${变量/常量的数学表达式},如上图所示对常量age进行计算。
- F字符串
传入的参数可以进行相应的格式的转化。例如:
先val height = 1.7//声明了一个一位小数的常量身高。
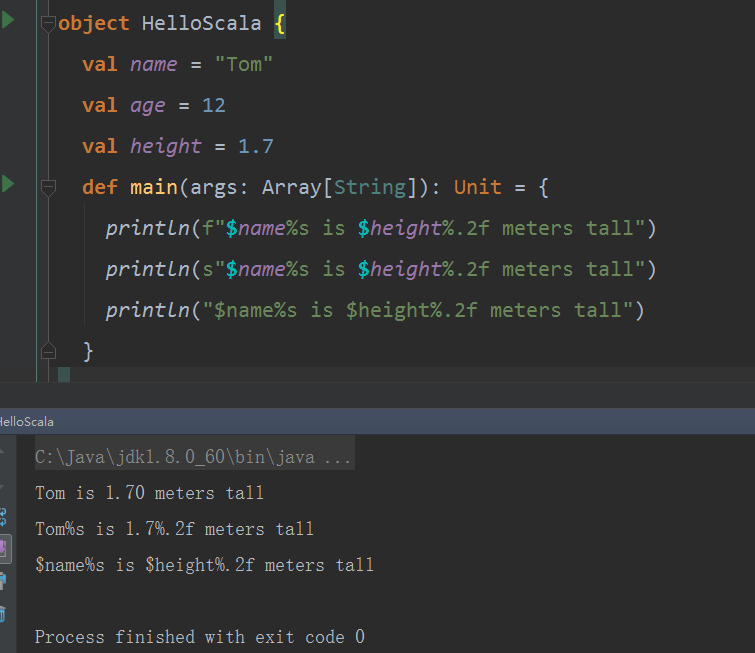
println(f"$name%s is $height%.2f meters tall")//在字符串前加f使用f字符串的功能,包含了s字符串的调用变量的功能,并且在变量名后面跟%格式来格式化变量。例如%s是表示字符串,%.2f是精确到百分位。
println(s"$name%s is $height%.2f meters tall")//如果这里使用s字符串则只能包含s字符串调用变量的功能,不能使用f字符串格式化的功能。
println("$name%s is $height%.2f meters tall")//如果不加s也不加f则原样输出。
- R字符串
R字符串和Python中的raw字符串是一样的,在java中要原样输出一些带\的字符,如\t、\n等需要在前面再加一个\转义,不然就会输出制表符、回车。比如\n就要写成\\n,才能原样输出\n,但是加上raw则不需要。例如:
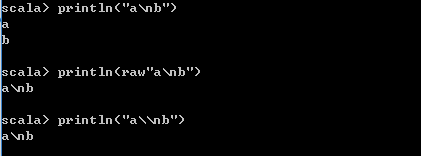
注意r字符串的使用是在字符串前面加raw,而不是r。
4. 懒加载
在Scala的底层有一个延迟执行功能,其核心是利用懒加载。如下图懒加载常量:
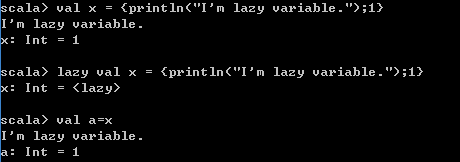
对比上面两条命令的差异,可以发现没有lazy的命令立即执行,并将1赋给常量x。而带有lazy的命令没有立即执行方法体,而是在后面val a=xl时才执行了方法体的内容。
其中lazy是一个符号,表示懒加载;{println("I'mtoolazy");1},花括号是方法体,花括号中的分号是隔开符,用于隔开两句话,方法体的最后一行作为方法的返回值。
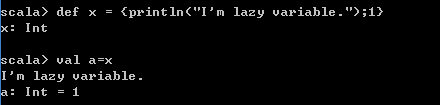
如上图所示,定义函数的效果和懒加载方式的效果一样,只有在调用的时候才会执行方法体。
三、Scala 函数
1. 函数的定义
- 函数定义的一般形式
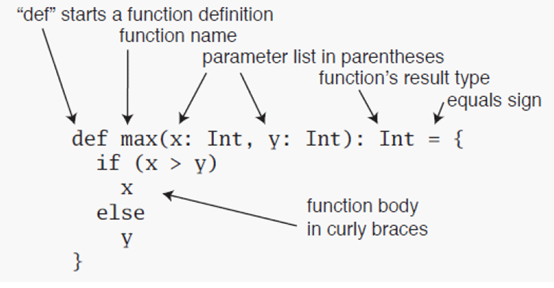
如上图所示,其中def关键字表示开始一个函数的定义;max是函数名;小括号中的x和y表示参数列表,用逗号隔开;小括号中的参数后面的:类型表示参数的类型;参数列表之后的:类型是函数的返回值类型;等号表示要返回值,如果没有等号和返回值类型就表示不需要返回值,或返回值类型改为Unit也表示不需要返回值;花括号中的内容是方法体,方法体的最后一行将作为函数的返回值,这里的最后一行是x或者y。
- 函数定义的简化形式
省略return(实际已经简化)。Scala中,可以不写return,如果不写return则自动将最后一行作为返回值,如果没有返回值,则函数的返回类型为Unit,类似于Java中void。
函数和变量一样,可以推断返回类型。所以上述函数可以简写成:
def max( x : Int, y : Int) = {if(x > y) x else y}
这里还可以进一步把方法体的花括号也省略,所以函数可以进一步简化为:
def max(x : Int, y : Int) = if(x>y) x else y
- 案例一(单个参数)
object HelloScala { // 定义sayMyName方法,方法需要一个参数,类型是String,默认值是Jack。方法体前面没有等号,就相当于没有返回值,Unit def sayMyName(name : String = "张三"){ println(name) } //函数的调用需要main函数 def main(args: Array[String]) { sayMyName("李四")//如果没有使用参数sayMyName()则使用默认值张三,如果使用参数"李四",则输出李四 } }
- 案例二(多个参数,可变参数)
多个相同类型的参数可以使用*表示,例如(k : Int*)表示多个Int类型的参数,具体数量不确定,类似于java中的可变参数。
object HelloScala { def sumMoreParameter(k : Int*)={ var sum=0 for(i <- k){//使用foreach(<-)来遍历元素k println(i) sum += i } sum } def main(args: Array[String]) { println(sumMoreParameter(3,5,4,6))//这里传递的参数个数可变 } }
当然也可以定义参数个数确定的函数,如下:
object HelloScala { def add(a:Int,b:Int) = a+b//省略了方法体的花括号和方法返回值类型 def main(args: Array[String]) { println(add(3,6)) } }
- 案例三(下划线作参数)
使用下划线做参数名称
object HelloScala { def add(a:Int,b:Int) = a+b def add2 = add(_:Int,3)//调用add方法,使用下划线是一个符号,可以不取变量名,参数的类型是Int def main(args: Array[String]) { println(add2(5))//这里的结果和add(2,5)=7是一样的。 } }
2. 递归函数
递归实际上就是方法自己调自己,也可以看成是递推公式。以阶乘为例:
- 案例四(递归函数)
object HelloScala { def fact(n: Int): Int = if (n <= 0) 1 else n * fact(n - 1)//注意这里需要写方法的返回值类型Int,因为递归的方法体里面还有这个函数,所以无法对结果的类型进行推断。 def main(args: Array[String]) { println(fac(6)) } }
3. 柯里化函数
在计算机科学中,柯里化(Currying)是把接受多个参数的函数变换成接受一个单一参数(最初函数的第一个参数)的函数,并且返回接受余下的参数且返回结果的新函数的技术。有时需要允许他人一会在你的函数上应用一些参数,然后又应用另外的一些参数。例如一个乘法函数,在一个场景需要选择乘数,而另一个场景需要选择被乘数。所以柯里化函数就是将多个参数分开写,写在不同的小括号里,而不是在一个小括号中用逗号隔开。例如:
- 案例五(柯里化函数)
object HelloScala { def mulitply(x:Int)(y:Int) = x*y def main(args: Array[String]) { println(mulitply(2)(4)) } }
object HelloScala { def mulitply(x:Int)(y:Int) = x*y def mulitply2 = mulitply(2)_;//柯里化就是把参数可以分开来,把部分函数参数可以用下划线来代替 def main(args: Array[String]) { println(mulitply2(3)) } }
4. 匿名函数
- 匿名函数的概念
匿名函数就是没有名字的函数。例如 (x : Int, y : Int) => x * y 。这里有一点要注意,如果在“=>”前加上了这个函数的返回类型,如:(x:Int, y : Int) : Int=> x * y,反而会报错。原因是在一般情况下,Scala编译器会自动推断匿名函数参数的类型,所以可以省略返回类型,因为返回类型对于编译器而言是多余的。
- 案例六(匿名函数,声明方式)
object HelloScala { val t = () => 123 def main(args: Array[String]) { println(t())//直接调用t,注意要有小括号 } }
匿名函数的标识就是=>,没有方法名,只有一个小括号(这里也没有参数),方法体就是直接返回的123(是{123}的简写)。val t是将声明的这个匿名函数对象付给了常量t。这里看上去像是多此一举,但是因为匿名函数往往是作为参数传给一个函数的,所以匿名函数这样的形式很有必要。
- 案例七(匿名函数,做函数的参数)
object HelloScala { val t = ()=>123//声明了一个匿名函数对象付给了t def testfunc(c : ()=>Int ){ println(c()) 333 } def main(args: Array[String]) { println(testfunc(t)) } }
定义testfunc方法中需要一个参数c,其类型是()=>Int,而()=>Int是匿名函数类型的定义。这个表达式是指传进来参数需要是一个匿名函数,该匿名函数没有参数,返回值是Int,比如t就是这样的匿名函数。
在testfunc中是打印,在方法体里面才真正的调用传进来的函数;传进来的时候只是传进来了一个方法体,并没有正真的调用。只有在里面有了()时才真正的调用。
println(testfunc(t))打印的结果有两行,第一行是123、第二行是(),因为testfunc这个方法没有返回值。如果将函数testfunc方法体前面加个等号就能打印出方法体最后一行(返回值)333。
- 案例八(匿名函数,有参匿名函数的声明)
object HelloScala { val b = (a:Int)=> a*2;//把一个能将传进来的参数乘以2的匿名函数对象赋给b def main(args: Array[String]) { println(b(8))//打印的结果为16 } }
- 案例九(匿名函数,有参匿名函数做参数)
object HelloScala { def testf1(t: (Int,Int)=>Int )={ println(t(15,15)); } def main(args: Array[String]) { testf1((a:Int,b:Int)=>{println(a*b);a*b})//打印的结果为两行225 } }
定义的一个以有参匿名函数作为参数的函数testf1,其参数名是t,参数类型是(Int,Int)=>Int这样的匿名函数,它需要两个Int类型的参数经过相应的转化,转为一个Int类型的返回值。
t(15,15)这方法体里才真正的调用匿名函数t,这里的参数是写死的,即在testf1方法里才有真正的数据。但是真正对数据的操作是交给匿名函数的,这就体现了函数式编程的特点。
5. 嵌套函数
嵌套函数可以认为是复合函数,是def了的一个函数中又def了一个函数。 例如:
- 案例十(嵌套函数)
object HelloScala { //定义一个函数f=(x+y)*z def f(x:Int, y:Int ,z:Int) : Int = { //针对需求,要定义个两个数相乘的函数g=a*b,相当于复合函数。 def g(a:Int, b:Int):Int = { a*b } g((x+y),z) } def main(args: Array[String]) { println(f(2,3,5)) } }
6. 循环函数
和Java的类似,Scala有foreach循环。
- 案例十一(foreach循环)
object HelloScala { //定义for_test1方法,使用for循环输出1-50的整数 def for_test1() : Unit = { //"<-"这个符号表示foreach,使用"to"则包含末尾(闭区间),如果是until则不包含(左闭右开)。这里的to是Scala内建的一个方法。 for(i <- 1 to 50 ){ //可以从源码看到to是RichInt类型的方法 println(i) } } def main(args: Array[String]): Unit = { for_test1() } }
- 案例十二(foreach循环嵌入条件判断)
object HelloScala { //打印1000以内(不含),可以被3整除的偶数。 def for_test2() = { //可以直接在for括号里面添加if过滤条件,比Java更简洁。多个条件使用分号隔开 for(i <- 0 until 1000 if (i % 2) == 0 ; if (i % 3) == 0 ){ println("I: "+i) } } def main(args: Array[String]) { for_test2() } }
7. 分支函数
和Java的switch…case…default分支类似,Scala有match…case…case_结构。
object HelloScala { def testmatch(n:Int)={ n match { case 1 => {println("是1") ;n}//"=>"表示有匿名函数,如果与1匹配上就走这个方法体 // break;在Scala中不需要写break,也不能写break,Scala中没有break关键字。 case 2 => println("是2") ;n//方法体的花括号可以省略。 case _ => println("其他") ; "others" //case _:default } } def main(args: Array[String]) { println(testmatch(1))//结果为是1 \n 1 println(testmatch(0))//结果为其他 \n others } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号