数据中台概述
一、大数据平台组件总结
1、数据存储
HDFS,HBase,Kudu等
2、数据收集和迁移
常用技术:flume,canal,sqoop,datax,waterdrop 等
3、任务调度
常用技术:azkaban,oozie,dophinscheduler,airflow 等
4、部署运维
常用技术:cloudera manager, ambari,SaltStack 等
5、监控告警
常用技术:Alertmanager+Prometheus,zabbix,openfalcon 等
6、安全和权限
常用技术:Kerberos,ranger 等
7、资源调度
YARN,Mesos,Kubernetes
8、数据计算
MapReduce, Spark, Flink
9、交互式查询
Impala, Presto
10、在线实时分析
ClickHouse,Kylin,Doris,Druid,Kudu等
11、元数据管理
Metacat擅长管理数据字典,Atlas擅长管理数据血缘。
二、数据中台由来
数据库阶段 ---> 传统数仓 ---> 大数据平台 ----> 大数据中台
三、数据中台适合哪些企业
数据中台的构建需要非常大的投入:一方面数据中台的建设离不开系统支撑,研发系统需要投入大量的人力,而这些系统是否能够匹配中台建设的需
求,还需要持续打磨。另外一方面,面对大量的数据需求,要花费额外的人力去做数据模型的重构,也需要下定决心。
所以数据中台的建设,需要结合企业的现状,根据需要进行选择。我认为企业在选择数据中台的时候,应该考虑这样几个因素。
1、企业是否有大量的数据应用场景: 数据中台本身并不能直接产生业务价值,数据中台的本质是支撑快速地孵化数据应用。所以当你的企业有较多数
据应用的场景时(一般有 3 个以上就可以考虑),就像我在课程开始时提到电商中有各种各样的数据应用场景,此时你要考虑构建一个数据中台。
2、经过了快速的信息化建设,企业存在较多的业务数据的孤岛,需要整合各个业务系统的数据,进行关联的分析,此时,你需要构建一个数据中台。
比如在我们做电商的初期,仓储、供应链、市场运营都是独立的数据仓库,当时数据分析的时候,往往跨了很多数据系统,为了消除这些数据孤
岛,就必须要构建一个数据中台。
3、当你的团队正在面临效率、质量和成本的苦恼时,面对大量的开发,却不知道如何提高效能,数据经常出问题而束手无策,老板还要求你控制数据
的成本,这个时候,数据中台可以帮助你。
当你所在的企业面临经营困难,需要通过数据实现精益运营,提高企业的运营效率的时候,你需要构建一个数据中台,同时结合可视化的 BI 数据产
品,实现数据从应用到中台的完整构建,在我的接触中,这种类型往往出现在传统企业中。
企业规模也是必须要考虑的一个因素,数据中台因为投入大,收益偏长线,所以更适合业务相对稳定的大公司,并不适合初创型的小公司。
四、如何构建数据中台
方法论 + 技术 + 组织
4.1 方法论
阿里提出的OneData 和 OneService
OneData 就是所有数据只加工一次。
OneData 体系的目标是构建统一的数据规范标准,让数据成为一种资产,而不是成本。资产和成本的差别在于资产是可以沉淀的,是可以被复用的。成 本是消耗性质的、是临时的、无法被复用的。
OneService,数据即服务,强调数据中台中的数据应该是通过统一的 API 接口的方式被访问。
OneService 体系的目标是提高数据的共享能力,让数据可以被用得好,用得爽。
4.2 技术

(1) 大数据计算、存储基础设施
数据中台的底层是以 Hadoop 为代表的大数据计算、存储基础设施,提供了大数据运行所必须的计算、存储资源。
(2) 工具产品
在 Hadoop 之上,浅绿色的部分是原有大数据平台范畴内的工具产品,覆盖了从数据集成、数据开发、数据测试到任务运维的整套工具链产品。同
时还包括基础的监控运维系统、权限访问控制系统和项目用户的管理系统。由于涉及多人协作,所以还有一个流程协作与通知中心。
(3) 数据治理模块
灰色的部分,是数据中台的核心组成部分:数据治理模块。它对应的方法论就是 OneData 体系。以元数据中心为基础,在统一了企业所有数据源
的元数据基础上,提供了包括数据地图、数仓设计、数据质量、成本优化以及指标管理在内的 5 个产品,分别对应的就是数据发现、模型、质量、
成本和指标的治理。
(4) 数据服务
深绿色的部分是数据服务,它是数据中台的门户,对外提供了统一的数据服务,对应的方法论就是 OneService。数据服务向下提供了应用和表的访
问关系,使数据血缘可以延申到数据应用,向上支撑了各种数据应用和服务,所有的系统通过统一的 API 接口获取数据。
(5) 数据产品和应用
在数据服务之上,是面向不同场景的数据产品和应用,包括面向非技术人员的自助取数系统;面向数据开发、分析师的自助分析系统;面向敏捷数
据分析场景的 BI 产品;活动直播场景下的大屏系统;以及用户画像相关的标签工厂。
4.3 组织
数据中台提供的是一个跨业务部门共享的公共数据能力,所以,承担数据中台建设职责的部门一定是一个独立于业务线的部门。独立部门的最大风险是与业务脱节,所以我们对数据中台的组织定位是:懂业务,能够深入业务,扎根业务。
五、中台实现:元数据中心
5.1 元数据概念
数据中台的构建,需要确保全局指标的业务口径一致,要把原先口径不一致的、重复的指标进行梳理,整合成一个统一的指标字典。而这项工作的前 提,是要搞清楚这些指标的业务口径、数据来源和计算逻辑。而这些数据呢都是元数据。
元数据划为三类:数据字典、数据血缘和数据特征。
数据字典:描述的是数据的结构信息:表结构信息,主要包括像表名,字段名称、类型和注释,表的数据产出任务,表和字段的权限等
数据血缘:指一个表是直接通过哪些表加工而来。数据血缘一般会帮我们做影响分析和故障溯源。比如说有一天,你的老板看到某个指标的数据违反常 识,让你去排查这个指标计算是否正确,你首先需要找到这个指标所在的表,然后顺着这个表的上游表逐个去排查校验数据,才能找到异常数据的根源。
数据特征:主要是指数据的属性信息:存储空间大小,数仓分层,访问热度,主题分类,关联指标等。
关于开源的这两款产品,Metacat 擅长管理数据字典,Atlas 擅长管理数据血缘。
5.2 元数据中心架构设计
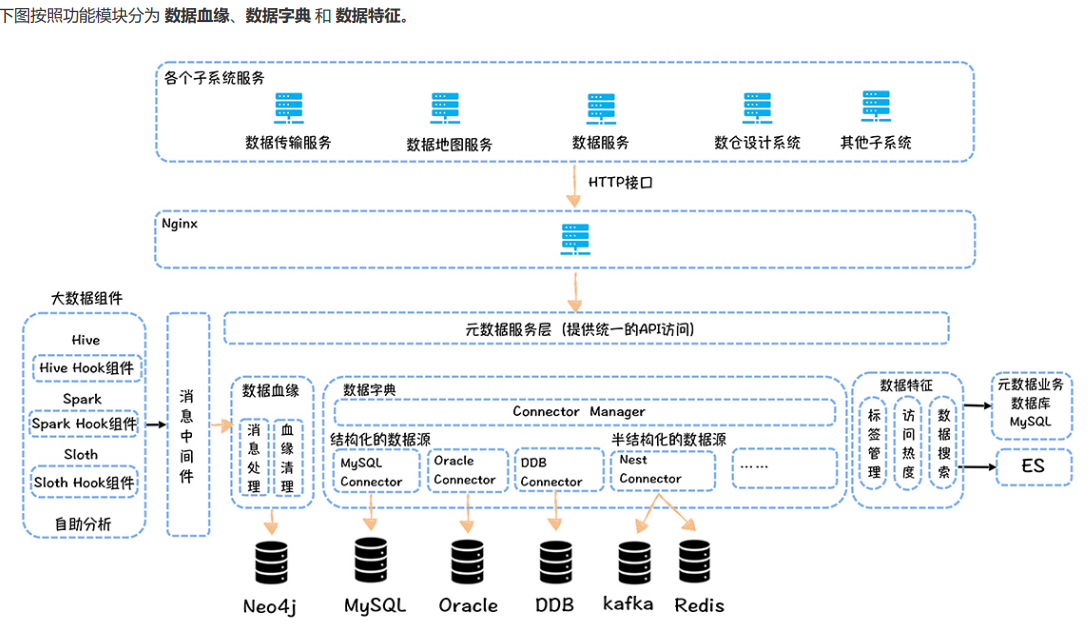
元数据中心统一对外提供了 API 访问接口,数据传输、数据地图、数据服务等其他的子系统都可以通过 API 接口获取元数据。另外 Ranger 可以基于元数据中心提供的 API 接口,获取标签对应的表,然后根据标签更新表对应的权限,实现基于标签的权限控制。
5.3 元数据设计要点
元数据中心是数据中台的基石,它提供了我们做数据治理的必须的数据支撑,数据的指标、模型、质量、成本、安全等的治理,这些都离不开元数据中
心的支撑。
(1) 元数据中心设计上必须注意扩展性,能够支持多个数据源,所以宜采用集成型的设计方式。
(2) 数据血缘需要支持字段级别的血缘,否则会影响溯源的范围和准确性。
(3) 数据地图提供了一站式的数据发现服务,解决了检索数据,理解数据的“找数据的需求”。
六、中台实现:指标管理
指标是一种特定类型的元数据,公司的运营会围绕它进行工作,可以说,它是业务和数据的交汇点。指标数据能不能用,会影响他们的日常工作。而且元数据在指标管理、模型设计、数据质量和成本治理四个领域也都发挥着作用,而这些领域构成了数据中台 OneData 数据体系。
七、中台实现:模型设计

八、中台实现:数据质量
想提升数据质量,最重要的就是 “早发现,早恢复”:
早发现,是要能够先于数据使用方发现数据的问题,尽可能在出现问题的源头发现问题,这样就为“早恢复”争取到了大量的时间。
早恢复,就是要缩短故障恢复的时间,降低故障对数据产出的影响。
具体实施:
添加稽核校验任务:确保数据的完整性、一致性和准确性
建立全链路监控:可以基于血缘关系建立全链路数据质量监控。
通过智能预警,确保任务按时产出:延迟产出,异常任务等立即报警
通过应用的重要性区分数据等级,加快恢复速度
九、中台实现:成本控制
精细化成本管理
第一:全局资产盘点 精细化成本管理的第一步,就是要对数据中台中,所有的数据进行一次全面盘点,基于元数据中心提供的数据血缘,建立全链路的数据资产视图。 数据成本计算:一张表的成本 = 每个加工任务的计算资源成本 * m + 上有依赖表的存储资源成本 * n 数据价值计算:给使用人数,使用频率,数据应用数,老板等因素加权计算
第二:发现问题 持续产生成本,但是已经没有使用的末端数据(“没有使用”一般指 30 天内没有访问):没有使用,却消耗了资源 数据应用价值很低,成本却很高,这些数据应用上游链路上的所有相关数据:低价值产出 高峰期高消耗的数据:高成本的数据
第三:治理优化 对于第一类问题,应该对表进行下线 对于第二类问题,我们需要按照应用粒度评估应用是否还有存在的必要,如果没有,则删除。 对于第三类问题,主要是针对高消耗的数据,又具体分为产出数据的任务高消耗和数据存储高消耗,分配到非高峰期运行即可。
第四:治理效果评估 最简单粗暴的标准:省了多少钱 下线了多少任务和数据;这些任务每日消耗了多少资源;数据占用了多少存储空间。 将上述节省资源换算成钱,这就是你为公司省的钱。
十、中台实现:数据服务化
数据服务主要解决的问题:
1、数据接入效率低
2、数据服务解决的问题
3、不确定数据应用在哪里
4、数据部门的字段更变导致数据应用变更
为了保障数据的查询速度,需要引入中间存储
数据量小:MySQL
低延时:Redis
数据两大:HBase
多维分析,数据量大:GreenPlum
不同中间存储提供的 API 接口不一致,导致使用复杂度提高。维护困难。
解决方案:提供统一的 API 接口,为开发者和应用者屏蔽不同的中间存储和底层数据源
十一、CDH 和 HDP 大数据平台
Amabari+HDP部署和维护使用
CM+CDH部署和维护使用

 浙公网安备 33010602011771号
浙公网安备 33010602011771号