基于物品的协同过滤(u2i2i)
一、概述
核心思想:根据所有用户对物品或者信息的评价,发现物品和物品之间的相似度,然后根据用户的历史偏好信息将类似的物品推荐给该用户。
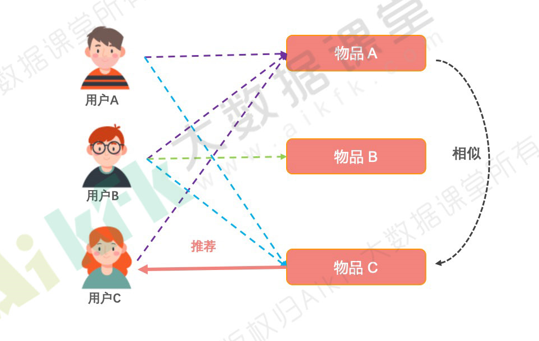
二、优点
UserCF的缺点:
(1)用户数量往往比较大,计算起来非常吃力,成为瓶颈。
(2)用户的口味其实变化还是很快的,不是静态的,所以兴趣迁移问题很难反映出来。
(3)数据稀疏,用户和用户之间有共同的消费行为实际上是比较少的,而且一般都是热门物品,对发现用户兴趣帮助也不大。
Iterm CF 如何解决上面的问题呢?
(1)首先,物品的数量,或者严格的说,可以推荐的物品数量往往少于用户数量;所以一般计算物品之间的相似度就不会成为瓶颈。
(2)其次,物品之间的相似度比较静态,它们变化的速度没有用户的口味变化快;所以完全解耦了用户兴趣迁移这个问题。
(3)最后,物品对应的消费者数量较大,对于计算物品之间的相似度稀疏是好过计算用户之间相似度的。
三、整体流程
1、由u2u2i(基于用户的协同过滤) 可以知道基于用户听歌日志表得到用户对音乐的喜爱程度字段
userid , musicid, rating
2、计算分子和分母,详细过程如下
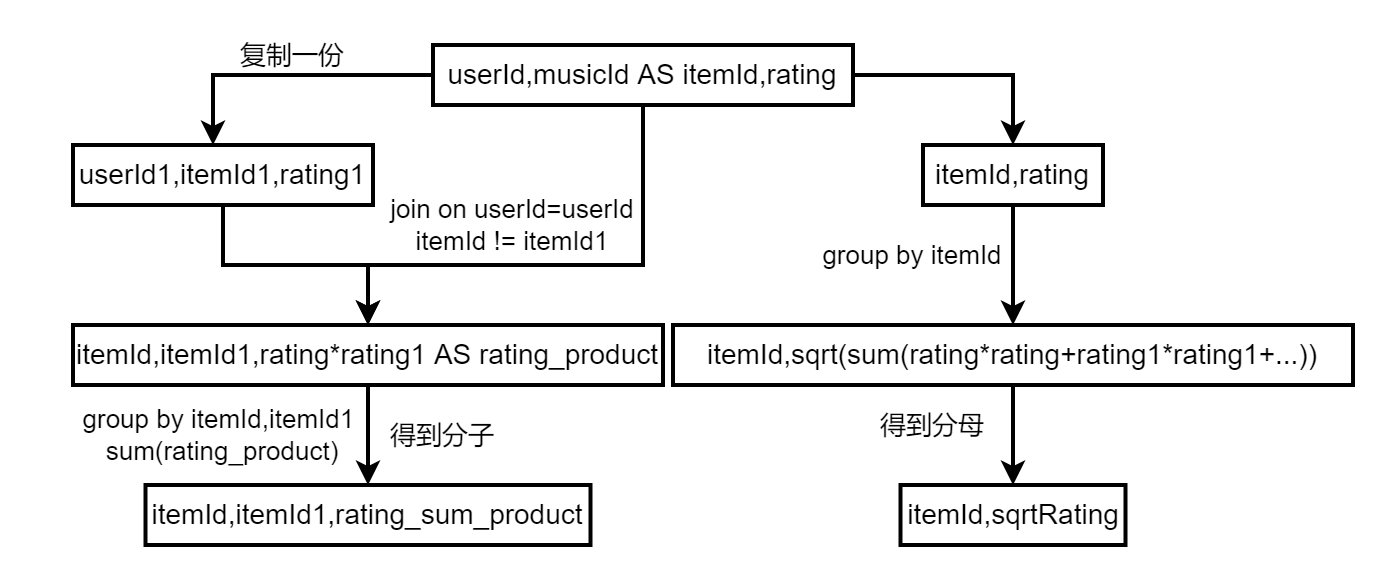
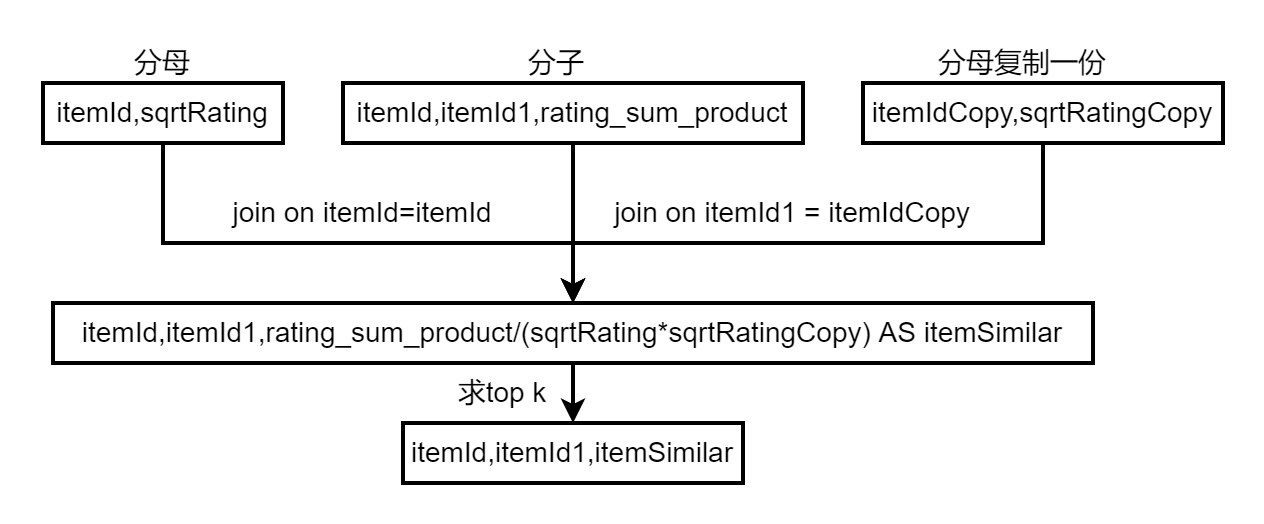
3、计算物品之间的相似矩阵
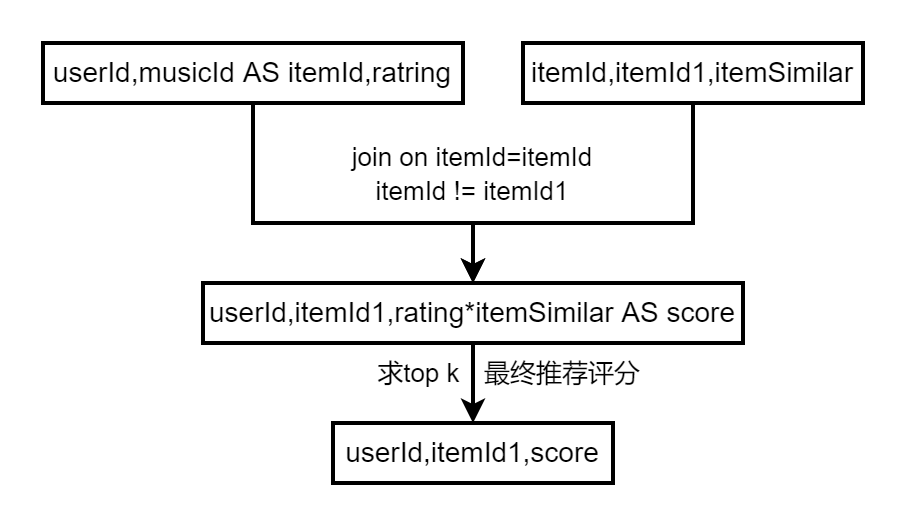
4、制作用户物品推荐评分,用于线上推荐(日更)
参考代码:


import breeze.numerics.{pow, sqrt} import org.apache.spark.sql.{DataFrame, SparkSession} import org.apache.spark.sql.expressions.Window import org.apache.spark.sql.functions.{desc, row_number, udf} object RecallItermCf { def main(args: Array[String]): Unit = { val sparkSession = SparkSession .builder() .master("local[*]") .appName("feat_eg") .config("spark.serializer", "org.apache.spark.serializer.KryoSerializer") // .config("hive.metastore.uris", // "thrift://"+"192.168.10.42"+":9083") // .config("spark.storage.memoryFraction",0.6) .enableHiveSupport() .getOrCreate() import sparkSession.implicits._ val uerLogPath = "E:\\tmp\\badou\\music_data\\user_listen.csv" val user_listen: DataFrame = sparkSession.read.format("csv").option("header", "true").load(uerLogPath) // 2.计算用户听某一首歌曲的总时间 val itemTotalTime = user_listen.selectExpr("userId", "musicId", "cast(remainTime as double)", "cast(durationHour as double)"). groupBy("userId", "musicId"). sum("remainTime"). withColumnRenamed("sum(remainTime)", "itemTotalTime") // 用户总共听歌时长 val totalTime = user_listen.selectExpr("userId", "musicId", "cast(remainTime as double)", "cast(durationHour as double)"). groupBy("userId"). sum("remainTime"). withColumnRenamed("sum(remainTime)", "totalTime") // uid ,iid ,rating val data = itemTotalTime.join(totalTime, "userId"). selectExpr("userId", "musicId as itemId", "itemTotalTime/totalTime as rating").limit(10) data.show(false) /*** *2.计算物品相似度 */ //2.1计算分子 //1.计算两个物品点击的用户有哪些,过滤掉两个一样的物品,因为他们的用户肯定一样。计算相似读为1,也不必计算。 val dataCopy = data.selectExpr("userId as userId1", "itemId as itemId1", "rating as rating1") val df_item_decare = dataCopy. join(data, dataCopy("userId1") === data("userId")). filter("cast(itemId as long)!=cast(itemId1 as long)"); //2.计算两个物品,评分相乘。 val rating_product = df_item_decare.selectExpr("itemId", "itemId1", "rating*rating1 as rating_product") //3.得到分子 val itemSameUserRatingProductSum = rating_product. groupBy("itemId", "itemId1"). agg("rating_product" -> "sum"). withColumnRenamed("sum(rating_product)", "rating_sum_product") /*** * itemSameUserRatingProductSum * +----------+----------+--------------------+ * | itemId| itemId1| rating_sum_product| * +----------+----------+--------------------+ * | 588400351|4563509337|0.041795941194973006| * |9773909220|6650509295| 0.1377822768744407| * |8969009236| 517009772| 0.21658469755042362| * +----------+----------+--------------------+ */ // 下面这几部 val itemSqrtRatingSum = data.rdd.map(x => (x(1).toString(), x(2).toString)). groupByKey(). mapValues(x => sqrt(x.toArray.map(rating => pow(rating.toDouble, 2)).sum)). toDF("itemId", "sqrtRating") /*** +----------+-------------------+ | itemId| sqrtRating| +----------+-------------------+ | 244400255|0.09191077667293739| |8753609189| 1.0070562241992123| | 527009593|0.09236453201970443| +----------+-------------------+ */ //计算相似性 val itemSqrtRatingSumCopy = itemSqrtRatingSum.selectExpr("itemId as itemIdCopy", "sqrtRating as sqrtRatingCopy") // dataCopy.cache() // dataCopy.show(3) val baseData = itemSameUserRatingProductSum.join(itemSqrtRatingSum, "itemId").join(itemSqrtRatingSumCopy, itemSqrtRatingSumCopy("itemIdCopy") === itemSameUserRatingProductSum("itemId1")) //相似性计算完成 val itemSimilar = baseData.selectExpr("itemId", "itemId1", "rating_sum_product/(sqrtRating*sqrtRatingCopy) as itemSimilar") // 相似性计topk的物品 val itemSimilar_new = itemSimilar.sort(desc("itemId"), desc("itemSimilar")).filter("itemSimilar > 0" ) itemSimilar.selectExpr("itemId", "itemId1","itemSimilar"). withColumn("rank", row_number().over(Window.partitionBy("itemId"). orderBy($"itemSimilar".desc))).filter(s"rank <= 30").drop("rank") // itemId itemId1 sim // 1 2 0.4 // 1 16 0.6 //存hive 或者 存 hdfs 或者 hbase中都可以。 itemSimilar_new.write.mode("overwrite").saveAsTable("itemSimilar") //以上存hive 或者 存 hdfs 或者 hbase中都可以。 /*** *3.进行recommand */ var itemSimilarCache:DataFrame=sparkSession.sql("select * from itemsimilar") ; // 此处对每个用户进行统计,其最喜欢的topk个音乐,当然如果有时间可以基于时间衰减,进行加权。 val userLikeItem = data.withColumn("rank",row_number(). over(Window.partitionBy("userId").orderBy($"rating".desc))). filter(s"rank <= 5").drop("rank") // 基于用户最喜欢的物品找到其相似物品进行推荐 val recommand_list = userLikeItem.join(itemSimilarCache,"itemId"). filter("itemId<>itemId1"). selectExpr("userId","itemId1 as recall_list_channel_001","rating*itemSimilar as recall_weight_channel_001"). withColumn("rank",row_number(). over(Window.partitionBy("userId").orderBy($"recall_weight_channel_001".desc))). filter(s"rank <= 20").drop("rank") /**userItemScore: *+-------+-------+------------------+ |user_id|item_id| score| +-------+-------+------------------+ | 71| 705|1.6914477316307988| | 71| 508|1.6914477316307988| | 71| 20|1.6914477316307988| | 71| 228| 1.353158185304639| | 71| 855|1.6914477316307988| +-------+-------+------------------+ */ } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号