基于用户的协同过滤(u2u2i)
一、核心思想:
先根据历史消费行为帮你找到一群和你口味相似的用户;然后根据这些和你相似的用户再消费了什么新的、你没有见过的物品,都可以推荐给你。

由此可知,大概流程如下:
1.计算用户之间的相似矩阵
2.基于用户相似矩阵(去给B做推荐)找到与B最相似的用户A,用户A喜欢的物品并且B用户未看过的物品,推荐给B
二、优缺点
|
UserCF:基于用户的协同过滤算法 |
ItemCF:基于物品的协同过滤算法 |
|
| 性能 | 适用于用户较少的场合,如果用户很多,计算用户相似度矩阵代价很大 | 适用于物品数明显小于用户数的场合,如果物品很多(网页),计算物品相似度矩阵代价很大 |
| 领域 | 时效性较强,用户个性化兴趣不太明显的领域 | 长尾物品丰富,用户个性化需求强烈的领域 |
| 实时性 | 用户有新行为,不一定造成推荐结果的立即变化 | 用户有新行为,一定会导致推荐结果的实时变化 |
| 冷启动 | 在新用户对很少的物品产生行为后,不能立即对他进行个性化推荐,因为用户相似度表是每隔一段时间离线计算的 | 新用户只要对一个物品产生行为,就可以给他推荐和该物品相关的其他物品 |
| 新物品上线后一段时间,一旦有用户对物品产生行为,就可以将新物品推荐给和对它产生行为的用户兴趣相似的其他用户 | 但没有办法在不离线更新物品相似度表的情况下将新物品推荐给用户 | |
| 推荐理由 | 很难提供令用户信服的推荐解释 | 利用用户的历史行为给用户做推荐解释,可以令用户比较信服 |
三、整体流程
1、原始数据:用户听歌日志表(表:user_listen)
四个字段分别为:
userId 用户id
musicId 歌曲id
remainTime 收听时长(秒)
durationHour 收听的时间点(在一天的几点收听的)
2、制作用户对音乐的喜爱程度字段(核心就是用户听该音乐的总时长/该用户听歌的时长)
SELECT userid , musicid,(t1.itemTotalTime/t2.totalTime) as rating FROM (SELECT userid , musicid ,SUM(remaintime) as itemTotalTime FROM default.user_listen group by userid , musicid) t1 --用户听该音乐的总时长 LEFT JOIN (SELECT userid as userid2 , SUM(remaintime) as totalTime FROM default.user_listen group by userid ) t2 --一个用户听歌的总时长 ON t1.userid=t2.userid2
得到字段 userid , musicid, rating(用户对音乐的喜爱程度评分)
3、计算用户之间的相似性
由上一步能够转换得到每个用户所有音乐喜爱程度的列表,如下形式:
ui=[i1:0.3,i19:0.5,i21:0.3,i41:0.5] uj=[i1:0.4,i21:0.2,i41:0.7]
根据余弦相似度计算两两用户之间的相似评分

注:严格按照余弦公式分母是ui和uj共同物品的喜爱列表的平方和的根,即:i1、i21、i41
转换成ui和uj各自物品的喜爱列表的平方和的根,共同变小不影响最终的相对评分
分母:sqrt(0.3^2+0.5^2+0.3^2+0.5^2)*sqrt(0.4^2+0.2^2+0.7^5)
group by userid 就能够实现的到字段:userid userid分母
分子:把userid , musicid, rating的数据再复制一份,通过musicid join得到:
userid1,userid2,musicid,rating1,rating2
在此join的优化:
(1)业务指定避免所有人去参与相似计算。年龄、性别、地理位置等一系列用户自身属性的字段,去减小计算能量
(2)基于业务方面的聚类,对用户进行聚类,避免所有用户进行两两相似计算。
用户间的相似评分流程如下:
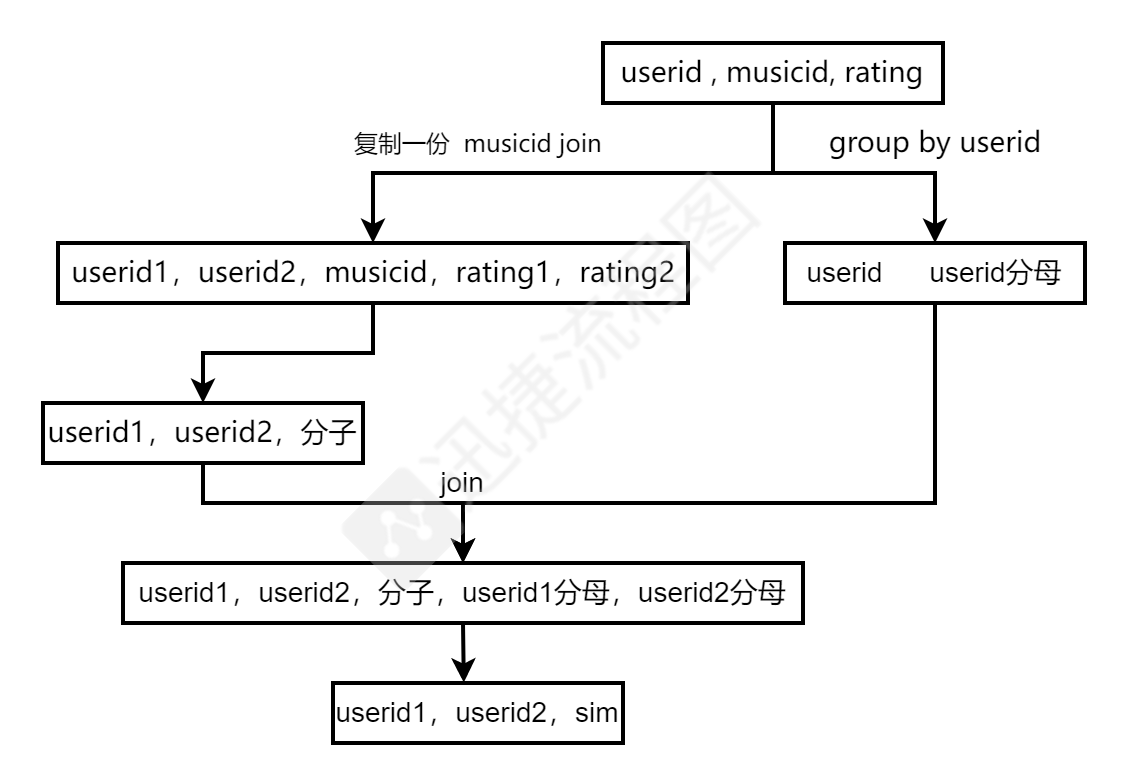
用户间的相似性计算量相对较大可以落地到hive,周更
4、制作用户物品推荐评分,用于线上推荐(日更)
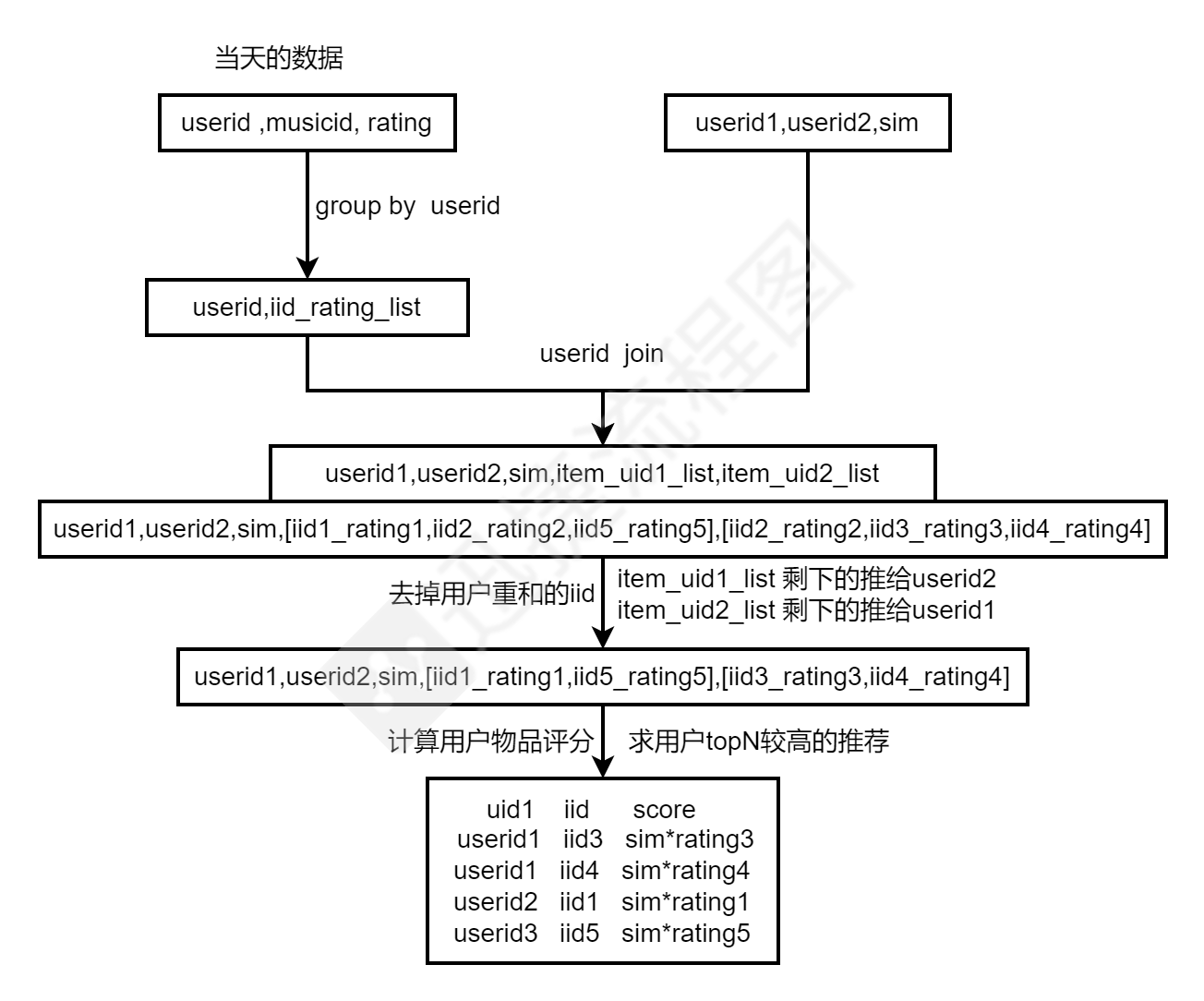
参考代码:


import breeze.numerics.{pow, sqrt} import org.apache.spark.sql.SparkSession object RecallUserCf { def main(args: Array[String]): Unit = { // 在driver端创建 sparksession val spark = SparkSession. builder(). // master("local"). appName("RecallUserCf"). config("hive.metastore.uris", "thrift://"+"kf1-82-hdp"+":9083"). // config("spark.sql.warehouse.dir", "F:/recommend/spark-warehouse"). enableHiveSupport(). getOrCreate() /*** *1.导入数据,并加工评分数据 */ // 10w用户 //我们在日常spark开发中,90%的数据都是从hive里面读取的。 //user_listen有500mb, user_listen 的 rdd的partition有多少个: // block128mb, 4个。当你从hdfs里面读取数据,你的rdd的分区是有 block来决定的 val user_profile = spark.sql("select * from badou.user_profile") // val user_listen = spark.sql("select userid,musicid,cast(remaintime as double),cast(durationhour as double) from badou.user_listen ") val user_listen = spark.sql("select userid,musicid,cast(remaintime as double),cast(durationhour as double) from default.ul_log ") // 2.计算用户听某一首歌曲的总时间 val itemTotalTime = user_listen. selectExpr("userId", "musicId", "cast(remainTime as double)", "cast(durationHour as double)"). groupBy("userId", "musicId"). sum("remainTime"). withColumnRenamed("sum(remainTime)", "itemTotalTime") // withColumnRenamed指的是重新名命名字段 // 用户总共听歌时长 val totalTime = user_listen. selectExpr("userId", "musicId", "cast(remainTime as double)", "cast(durationHour as double)"). groupBy("userId"). sum("remainTime"). withColumnRenamed("sum(remainTime)", "totalTime") // uid ,iid ,rating // itemTotalTime //| userId| musicId|itemTotalTime| //+--------------------+----------+-------------+ //|00941e652b84b9967...|6326709127| 200.0| //|01e7b27c256cc06c1...|5652309207| 280.0| //|0115519e4f2e7488d...| 536400214| 195.0| //+--------------------+----------+-------------+ // totalTime 表比较小,1000w (1gb) //+--------------------+---------+ //| userId|totalTime| //+--------------------+---------+ //|001182ecc8be5e709...| 75.0| //|003bfa68b61dd5c9e...| 1810.0| //|00c68f637da1a8731...| 763.0| //+--------------------+---------+ // 在做join的是后,提前聚合数据. val data = itemTotalTime. join(totalTime, "userId"). selectExpr("userId", "musicId as itemId", "itemTotalTime/totalTime as rating") data.createOrReplaceTempView("user") data.cache() // data.show(2) /** * * +--------------------+---------+-------------------+ * | userId| itemId| rating| * +--------------------+---------+-------------------+ * |000005a451226ca84...|177200319| 1.0| * |0000cbb6ea39957f7...|068800255|0.20651420651420652| * +--------------------+---------+-------------------+ */ // data.write.mode("overwrite").saveAsTable("user_item_rating") /*** *2.计算用户相似性 */ //(x1*y1+x2*y2......)/|X|*|Y| //|X| =sqrt(x1^2+x2^2+x3^2) //|Y| =sqrt(y1^2+y2^2+y3^2) // 2.1计算分母 import spark.implicits._ // userSumPowRatin 每个用户 对所有的物品进行评分的平方和 (|X| =sqrt(x1^2+x2^2+x3^2) val userSumPowRating = data. rdd. map(x => (x(0).toString, x(2).toString)). groupByKey(). // 一条数据 // (003d60470fbc5eb862940b4a9c8b3b26,CompactBuffer(0.6582343830665979, 0.24109447599380485, 0.10067114093959731)) mapValues(x => sqrt(x.toArray.map(rating => pow(rating.toDouble, 2)).sum)). toDF("userId", "sqrt_rating_sum") userSumPowRating.cache() userSumPowRating.show(3) // 2.计算分子 // uid 247999,如果要计算 两两相似性,直接爆炸。 val data_with_copy =data.selectExpr("userId as userId1","itemId as itemId1","rating as rating1") // item->user倒排表,去除一样用户的打分 // todo优化计算空间,对用户不进行笛卡尔积 // 优化前 // 333499378条数据 val user_item2item = data. join(data_with_copy,data_with_copy("itemId1")===data("itemId")). filter("userId <> userId1 ") user_item2item.selectExpr("userId").distinct().count() // 92964 说明 部分用户跟其他人听的歌没有任何交集,这部分用户不会有召回结果,所以,我们需要对这部分用户以其他方式进行相似性计算。 // 计算两个用户在一个item下的评分的乘积,consine举例的分子的一部分 // dot import org.apache.spark.sql.functions._ val product_udf = udf((s1:Double,s2:Double)=>s1*s2) val selectData = user_item2item.selectExpr("userId","rating","itemId","userId1","rating1") // val user_data = selectData.selectExpr("userId","userId1","rating1*rating as rating_product") val user_data = selectData. withColumn("rating_product",product_udf(col("rating"),col("rating1"))). selectExpr("userId","userId1","itemId","rating_product") // 此处直接爆炸了 val user_rating_sum = user_data. groupBy("userId","userId1"). agg("rating_product"->"sum"). withColumnRenamed("sum(rating_product)","rating_dot") // 分子除以分母 做相似性 val userSumPowRatingCopy = userSumPowRating.selectExpr("userId as userId1","sqrt_rating_sum as sqrt_rating_sum1") val df_sim = user_rating_sum. join(userSumPowRating,"userId"). join(userSumPowRatingCopy,"userId1"). selectExpr("userId","userId1", "rating_dot/(sqrt_rating_sum*sqrt_rating_sum1) as cosine_sim") // 2. 获取相似用户的物品集合 // 2.1取得前n个相似用户 val df_nsim =df_sim. rdd. map(x=> (x(0).toString,(x(1).toString,x(2).toString))). groupByKey(). mapValues { x => x.toArray.sortWith((x, y) => x._2 > y._2).slice(0,10)}. flatMapValues(x=>x).toDF("userid","user_v_sim"). selectExpr("user_id","user_v_sim._1 as user_v","user_v_sim._2 as sim") // 2.2获取用户的物品集合进行过滤,拿到每一个用户的物品集合,列表 val df_user_item = data. rdd. map(x=>(x(0).toString,x(1).toString+"_"+x(2).toString)). groupByKey().mapValues(x=>x.toArray) .toDF("user_id","item_rating_arr") val df_user_item_v = df_user_item.selectExpr("user_id as user_v", "item_rating_arr as item_rating_arr_v") /** df_gen_item: * +------+-------+-------------------+--------------------+--------------------+ |user_v|user_id| sim| item_rating_arr| item_rating_arr_v| +------+-------+-------------------+--------------------+--------------------+ | 296| 71|0.33828954632615976|[89_5, 134_3, 346...|[705_5, 508_5, 20...| | 467| 69| 0.4284583738949647|[256_5, 240_3, 26...|[1017_2, 50_4, 15...| | 467| 139|0.32266158985444504|[268_4, 303_5, 45...|[1017_2, 50_4, 15...| | 467| 176|0.44033327143526596|[875_4, 324_5, 32...|[1017_2, 50_4, 15...| | 467| 150|0.47038691576507874|[293_4, 181_5, 12...|[1017_2, 50_4, 15...| +------+-------+-------------------+--------------------+--------------------+ * */ val df_gen_item = df_nsim.join(df_user_item,"user_id") .join(df_user_item_v,"user_v") // 2.3用一个udf过滤相似用户user_id1中包含user_id已经打过分的物品 val filter_udf = udf{(items:Seq[String],items_v:Seq[String])=> val fMap = items.map{x=> val l=x.split("_") (l(0),l(1)) }.toMap items_v.filter{x=> val l = x.split("_") fMap.getOrElse(l(0),-1) == -1 } } val df_filter_item = df_gen_item.withColumn("filtered_item", filter_udf(col("item_rating_arr"),col("item_rating_arr_v"))) .select("user_id","sim","filtered_item") /** df_filter_item: * +-------+-------------------+--------------------+ * |user_id| sim| filtered_item| +-------+-------------------+--------------------+ | 71|0.33828954632615976|[705_5, 508_5, 20...| | 69| 0.4284583738949647|[762_3, 264_2, 25...| | 139|0.32266158985444504|[1017_2, 50_4, 76...| | 176|0.44033327143526596|[1017_2, 762_3, 2...| | 150|0.47038691576507874|[1017_2, 762_3, 2...| +-------+-------------------+--------------------+ * */ // 2.4公式计算 相似度*rating val simRatingUDF = udf{(sim:Double,items:Seq[String])=> items.map{x=> val l = x.split("_") l(0)+"_"+l(1).toDouble*sim } } val itemSimRating = df_filter_item.withColumn("item_prod", simRatingUDF(col("sim"),col("filtered_item"))) .select("user_id","item_prod") /**itemSimRating: *+-------+--------------------+ |user_id| item_prod| +-------+--------------------+ | 71|[705_1.6914477316...| | 69|[762_1.2853751216...| | 139|[1017_0.645323179...| | 176|[1017_0.880666542...| | 150|[1017_0.940773831...| +-------+--------------------+ */ val userItemScore = itemSimRating.select(itemSimRating("user_id"), explode(itemSimRating("item_prod"))).toDF("user_id","item_prod") .selectExpr("user_id","split(item_prod,'_')[0] as item_id", "cast(split(item_prod,'_')[1] as double) as score") /**userItemScore: *+-------+-------+------------------+ |user_id|item_id| score| +-------+-------+------------------+ | 71| 705|1.6914477316307988| | 71| 508|1.6914477316307988| | 71| 20|1.6914477316307988| | 71| 228| 1.353158185304639| | 71| 855|1.6914477316307988| +-------+-------+------------------+ */ } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号