on、where、having的区别和关系
三种条件关键字的执行顺序如下:
on > where > 聚合函数 > having
ON、WHERE、HAVING的主要差别是其子句中限制条件起作用时机引起的,
ON是在生产临时表之前根据条件筛选记录,
WHERE是从生产的临时表中筛选数据,
而HAVING是对临时表中满足条件的数据,进行计算分组之后,通过HAVING限制语句筛选分组,返回结果是满足HAVING子句限制的分组。
(Where分组前过滤,不能使用聚合函数;Having 分组之后过滤,可以使用聚合函数,HAVING不能单独出现,只能出现在GROUP BY子句之中)
选择的标准:
1. 如果我们的过滤条件需要在聚合函数运算完毕之后才能确定,比如我们想要找出平均分数大于60分的班级,那么就必须等待分组聚合函数执行完毕才能进行过滤,那这个条件肯定就是放在having中了,因为where生效的时候聚合函数还没有进行运算呢。
2. 如果我们的过滤条件不需要依赖聚合函数,只是想要表关联之后的结果表中符合条件的部分,而没有要求保留主表的全部记录,那么我们就应该放在where条件中,当然,如果表关联是采用inner join的话,因为没有主从表的关系,所以放在 where 和 on 中是一样的。
3. 如果我们的过滤条件不需要依赖聚合函数,并且在表关联后需要保留主表的所有记录,不论有没有相匹配的从表记录,那么我们就应该将过滤条件放在 on 中。
就性能来看:
因为on生效最早,所以放在on中应该最快,其次是where,最后是having。
on和where的区别
数据库在通过连接两张或多张表来返回记录时,都会生成一张中间的临时表,然后再将这张临时表返回给用户。
在使用left jion时,on和where条件的区别如下:
1、 on条件是在生成临时表时使用的条件,它不管on中的条件是否为真,都会返回左边表中的记录。
2、where条件是在临时表生成好后,再对临时表进行过滤的条件。这时已经没有left join的含义(必须返回左边表的记录)了,条件不为真的就全部过滤掉。
join过程可以这样理解:首先两个表做一个笛卡尔积,on后面的条件是对这个笛卡尔积做一个过滤形成一张临时表,如果没有where就直接返回结果,如果有where就对上一步的临时表再进行过滤。
下面看实验:
先准备两张表:
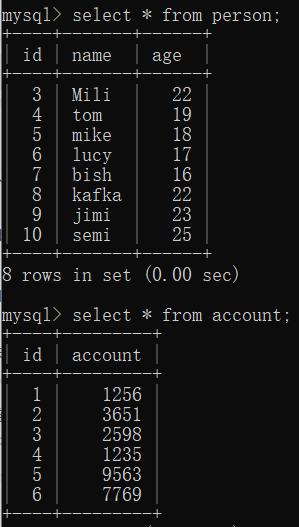
先执行inner join:
select * from person p inner join account a on p.id=a.id and p.id!=4 and a.id!=4;

select * from person p inner join account a on p.id=a.id where p.id!=4 and a.id!=4;

结果没有区别,前者是先求笛卡尔积然后按照on后面的条件进行过滤,后者是先用on后面的条件过滤,再用where的条件过滤。
再看看左连接left join
select * from person p left join account a on p.id=a.id and p.id!=4 and a.id!=4;
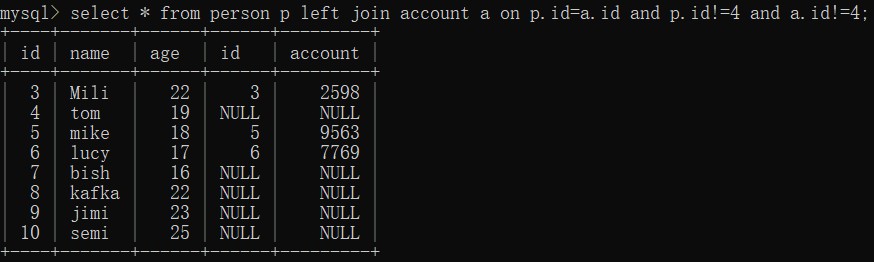
select * from person p left join account a on p.id=a.id where p.id!=4 and a.id!=4;

在on为选择条件时,id为4的记录还在,这是由left join的特性决定的,使用left join时on后面的条件只对右表有效(可以看到右表的id=4的记录为NULL)
在where为选择条件时,where过滤掉了左表中的内容。
记住:所有的连接条件都必需要放在ON后面,不然前面的所有LEFT,和RIGHT关联将作为摆设,而不起任何作用。
-
不考虑where条件下,left join 会把左表所有数据查询出来,on及其后面的条件仅仅会影响右表的数据(符合就显示,不符合全部为null)
-
在匹配阶段,where子句的条件都不会被使用,仅在匹配阶段完成以后,where子句条件才会被使用,它将从匹配阶段产生的数据中检索过滤
-
所以左连接关注的是左边的主表数据,不应该把on后面的从表中的条件加到where后,这样会影响原有主表中的数据
-
where后面:是先连接然生成临时查询结果,然后再筛选
on后面:先根据条件过滤筛选,再连接生成临时查询结果
参考博客:https://blog.csdn.net/u013468917/article/details/61933994

 浙公网安备 33010602011771号
浙公网安备 33010602011771号