

基础很重要~~04.表表达式
阅读目录
以前总是追求新东西,发现基础才是最重要的,今年主要的目标是精通SQL查询和SQL性能优化。
本系列【T-SQL基础】主要是针对T-SQL基础的总结。
【T-SQL基础】06.透视、逆透视、分组集
【T-SQL基础】07.数据修改
【T-SQL基础】09.可编程对象
----------------------------------------------------------
【T-SQL进阶】01.好用的SQL TVP~~独家赠送[增-删-改-查]的例子
----------------------------------------------------------
【T-SQL性能调优】02.Transaction Log的使用和性能问题
【T-SQL性能调优】03.执行计划
【T-SQL性能调优】04.死锁分析
持续更新......欢迎关注我!
概述:
本篇主要是对表表达式中视图和内联表值函数基础的总结。
表表达式包含四种:
1.派生表
2.公用表表达式
3.视图
4.内联表值函数
本篇是表表达式的下篇,只会讲到视图和内联表值函数。
下面是表表达式的思维导图:
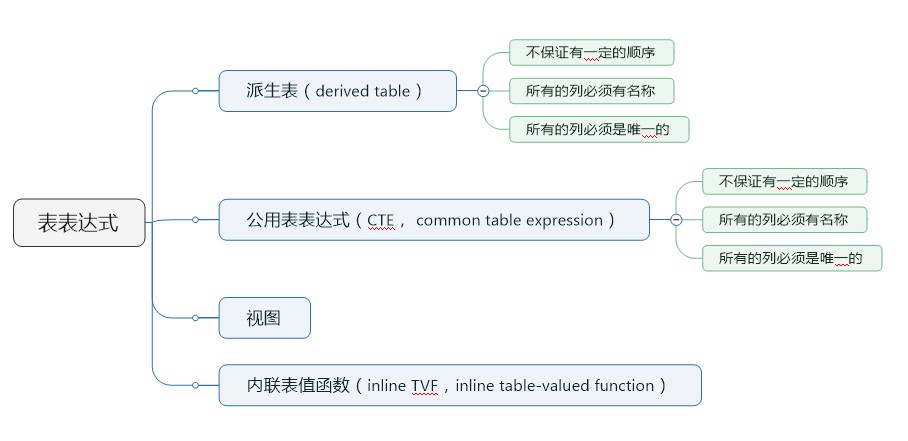
表表达式:
1.一种命名的查询表达式,代表一个有效的关系表。
2.可以像其他表一样,在数据处理语句中使用表表达式。
3.在物理上不是真实存在的什么对象,它们是虚拟的。对于表达式的查询在数据库引擎内部都将转化为对底层对象的查询。
为什么使用表表达式:
1.使用表表达式的好处是逻辑方面,在性能上没有提升。
2.通过模块化的方法简化问题的解决方案,规避语言上的某些限制。在外部查询的任何字句中都可以引用在内部查询的SELECT字句中分配的列别名。比如在SELECT字句中起的别名,不能在WHERE,group by等字句(逻辑顺序位于SELECT字句之前的字句)中使用,通过表表达式可以解决这类问题。
在阅读下面的章节时,我们可以先把环境准备好,以下的SQL脚本可以帮助大家创建数据库,创建表,插入数据。
下载脚本文件:TSQLFundamentals2008.zip
一、视图
1.视图和派生表和CTE的区别和共同点
区别:
派生表和CTE不可重用:只限于在单个语句的范围内使用,只要包含这些表表达式的外部查询完成操作,它们就消失了。
视图和内联表值函数是可重用的:它们的定义存储在一个数据对象中,一旦创建,这些对象就是数据库的永久部分;只有用删除语句显示删除或用右键删除,它们才会从数据库中移除。
共同点:
在很多方面,视图和内联表值函数的处理方式都类似于派生表和CTE。当查询视图和内联表值函数时,SQL Server会先扩展表表达式的定义,再直接查询底层对象。
2.语法
下面的例子定义了一个视图,视图名称为Sales.USACusts,查询所有来自美国的客户。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
USE TSQLFundamentals2008 IF OBJECT_ID('Sales.USACusts') IS NOT NULL DROP VIEW Sales.USACusts;GOCREATE VIEW Sales.USACustsAS SELECT custid , companyname , contacttitle , address , city , region , postalcode , country , phone , fax FROM Sales.Customers WHERE country = N'USA' |
定义好了视图之后,在数据库中刷新视图列表之后就会出现刚刚创建的视图Sales.USACusts
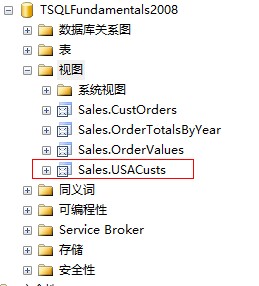
然后,就可以像查询数据库中其他表一样对视图进行查询:
|
1
2
3
|
SELECT custid , companynameFROM sales.usacusts |
3.视图的权限
可以像其他数据库对象一样,对视图的权限进行控制:如SELECT、INSERT、UPDATE、DELETE权限
4.避免使用SELECT * 语句
列是在编译视图时进行枚举的,新加的列不会自动加到视图中。以后对视图中用到的表增加了几列,这些列不会自动添加到视图中。可以用sp_refreshview的存储过程刷新视图的元数据,但是为了以后的维护,还是在视图中显示地需要的列名。如果在底层表中添加了列,而在视图中需要这些新加的列,可以使用ALTER VIEW语句对视图定义进行相应的修改。
5.创建视图的要求:
必须要满足之前介绍派生表时对表表达式提到的所有要求:
a.列必须有名称
b.列必须唯一
c.不保证有一定的顺序。在定义表表达式的查询语句中不允许出现ORDER BY字句。因为关系表的行之间没有顺序。
6.加密选项ENCRYPTION
在创建视图、存储过程、触发器及用户定义函数时,都可以使用ENCRYPTION加密选项。如果指定ENCRYPTION选项,SQL Server在内部会对定义对象的文本信息进行混淆(obfuscated)处理。普通用户看不到该视图的文本,只有特权用户通过特殊手段才能访问创建对象的文本。
在视图定义的头部,用WITH字句来指定ENCRYPTION选项,如下所示:
| 1 | CREATE VIEW Sales.USACusts WITH ENCRYPTION |
可以用下面的语句查看视图的文本:
| 1 | SELECT OBJECT_DEFINITION(OBJECT_ID('Sales.USACusts')) |
结果如下:
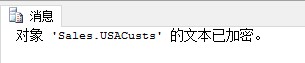
也可以用sp_helptext查看视图的文本:
| 1 | sp_helptext 'Sales.USACusts' |
结果如下:
只有在对安全要求较高的情况下才需要对视图进行加密,一般情况不需要加密。
7.架构绑定选项SCHEMABINDING
视图和用户自定义函数支持SCHEMABINDING选项。一旦指定了这个选项,视图引用的对象不能删除,被引用的列不能删除或修改。
在视图定义的头部,用WITH字句来指定SCHEMABINDING选项,如下所示:
| 1 | CREATE VIEW Sales.USACusts WITH SCHEMABINDING |
可以用下面的语句,更新Sales.USACusts视图所引用的Sales.Customers对象的address列
| 1 | ALTER TABLE Sales.Customers DROP COLUMN address |
结果如下:

建议在创建视图时,使用SCHEMABINDING选项。
如果使用SCHEMABINDING选项,必须满足两个技术要求:
a.必须在SELECT字句中显示地列出列名
b.在引用对象时,必须使用带有架构名称修饰的完整对象名称。
8.CHECK OPTION选项
CHECK OPTION选项的目的是为了防止通过视图执行的数据修改与视图中设置的过滤条件(假设在定义视图的查询中存在过滤条件)发生冲突。
假设想通过Sales.USACusts视图往Sales.Customers表中插入数据,可以使用下面的语句:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
INSERT INTO Sales.USACusts ( companyname , contactname , contacttitle , address , city , region , postalcode , country , phone , fax )VALUES ( 'A' , 'A' , 'A' , 'A' , 'London' , 'A' , 'A' , 'UK' , '123' , '123' ) |
然后查询Sales.Customers表,如下所示:
|
1
2
3
|
SELECT custid,companyname,countryFROM Sales.CustomersWHERE companyname = 'A' |
结果:

如果用视图进行查询,如下所示:
|
1
2
3
4
5
|
SELECT custid , companyname , countryFROM Sales.USACustsWHERE companyname = 'A' |
则得到的是一个空的结果集,因为视图中的WHERE条件WHERE country = N'USA'只筛选来自美国的客户。
如果想防止这种与视图的查询过滤条件相冲突的修改,只须在定义视图的查询语句末尾加上WITH CHECK OPTION即可:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
ALTER VIEW [Sales].[USACusts]AS SELECT custid , companyname , contactname , contacttitle , address , city , region , postalcode , country , phone , fax FROM Sales.Customers WHERE country = N'USA'WITH CHECK OPTION;GO |
再试下插入与视图的过滤条件相冲突的记录:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
INSERT INTO Sales.USACusts ( companyname , contactname , contacttitle , address , city , region , postalcode , country , phone , fax )VALUES ( 'A' , 'A' , 'A' , 'A' , 'London' , 'A' , 'A' , 'UK' , '123' , '123' ) |
结果如下:

9.练习题:
(1)创建一个视图,返回每个雇员每年处理的总订货量:
期望结果:
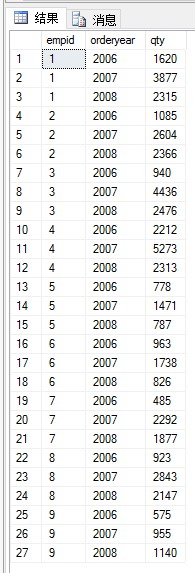
本题考察视图的创建
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
IF OBJECT_ID('Sales.VEmpOrders') IS NOT NULL DROP VIEW Sales.VEmpOrders;GOCREATE VIEW Sales.VEmpOrdersAS SELECT empid , YEAR(orderdate) AS orderyear , SUM(qty) AS qty FROM Sales.Orders AS O INNER JOIN Sales.OrderDetails AS D ON O.orderid = D.orderid GROUP BY empid , YEAR(orderdate);GO |
(2)写一个对Sales.VEmpOrders表的查询,返回每个雇员每年处理过的连续总订货量
期望的输出:
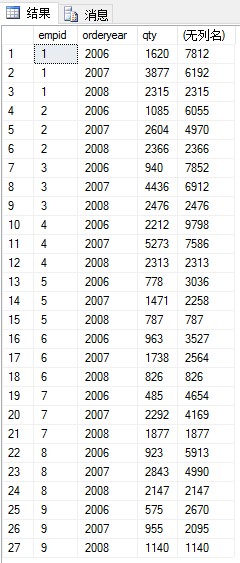
此题需要用到相关子查询:
|
1
2
3
4
5
6
7
8
9
10
|
SELECT empid , orderyear , qty , ( SELECT SUM(qty) AS runqty FROM Sales.VEmpOrders AS EO2 WHERE EO1.empid = EO2.empid AND EO1.orderyear <= EO2.orderyear )FROM Sales.VEmpOrders AS EO1ORDER BY EO1.empid , |
子查询返回订单年份小于或等于外查询当前行的订单年份的所有行,并计算这些行的订货量之和。
二、内联表值函数
1.什么是内联表值函数
一种可重用的表表达式,能够支持输入参数。除了支持输入参数以外,内联表值函数在其他方面都与视图相似。
2.如何定义内联表值函数
下面的例子创建了一个函数fn_GetCustOrders。这个内联表值接收一个输入客户ID参数@cid,另外一个输入参数订单年份参数@orderdateyear,返回客户ID等于@cid的客户下的所有订单,且订单的订单年份等于@orderdateyear
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
IF OBJECT_ID('dbo.fn_GetCustOrders') IS NOT NULL DROP FUNCTION dbo.fn_GetCustOrdersGOCREATE FUNCTION dbo.fn_GetCustOrders ( @cid AS INT ,@orderdateyear AS DATETIME)RETURNS TABLEAS RETURN SELECT orderid , custid , empid , orderdate , requireddate , shippeddate , shipperid , freight , shipname , shipaddress , shipcity , shipregion , shippostalcode , shipcountry FROM Sales.Orders WHERE custid = @cid AND YEAR(orderdate) = YEAR(@orderdateyear)Go |
定义好了内联表值函数之后,在数据库中刷新可编程性-函数-表值函数列表之后就会出现刚刚创建的函数fn_GetCustOrders
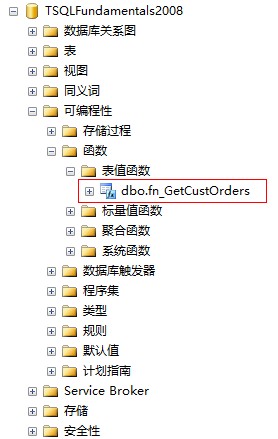
3.如何使用内联表值函数
可以用内联表值函数查询出客户id=1,订单日期年份=2008的所有订单:
| 1 | SELECT orderid,custid,orderdate FROM fn_GetCustOrders(1,'2008') |
内联表值函数也可以用在联接查询中:
下面的例子是用内联表值函数与HR.Employees表进行关联,查询出客户id=1,订单日期年份=2008的所有订单,以及处理对应订单的员工详情:
|
1
2
3
4
5
6
7
8
9
|
SELECT orderid , custid , orderdate , empid , lastname , firstname , titleFROM fn_GetCustOrders(1, '2008') INNER JOIN HR.Employees AS E ON dbo.fn_GetCustOrders.empid = E.empid |
结果如下:
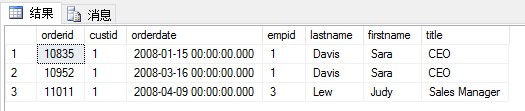
4.练习题
(1)创建一个内联表值函数,其输入参数为供应商ID(@supid AS INT)和要求的产品数量(@n AS INT)。该函数返回给定供应商@supid提供的产品中,单价最高的@n个产品。
当执行以下查询时:
| 1 | SELECT * FROM fn_TopProducts(5,2) |
期望结果:
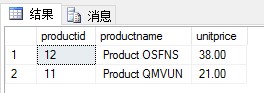
本题可以分三个步骤:
1.写一个查询语句
|
1
2
3
4
5
6
7
|
SELECT TOP ( 1 ) productid , productname , unitpriceFROM Production.ProductsWHERE supplierid = 1ORDER BY unitprice DESC; |
2.将参数替换进去:
|
1
2
3
4
5
6
7
|
SELECT TOP ( @n ) productid , productname , unitpriceFROM Production.ProductsWHERE supplierid = @supidORDER BY unitprice DESC; |
3.将这个查询放到内联表值函数中
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
IF OBJECT_ID('dbo.fn_TopProducts') IS NOT NULL DROP FUNCTION dbo.fn_TopProductsGOCREATE FUNCTION dbo.fn_TopProducts ( @supid AS INT, @n AS INT )RETURNS TABLEAS RETURN SELECT TOP ( @n ) productid , productname , unitprice FROM Production.Products WHERE supplierid = @supid ORDER BY unitprice DESC;Go |
三、APPLY运算符
1.APPLY运算符
APPLY运算符是一个非标准标准运算符。APPLY运算符对两个输入进行操作,其中右边的表可以是一个表表达式。
CROSS APPLY:把右边表达式应用到左表中的每一行,再把结果集组合起来,生成一个统一的结果表。和交叉连接相似
OUTER APPLY:把右边表达式应用到左表中的每一行,再把结果集组合起来,然后添加外部行。和左外联接中增加外部行的那一步相似
2.练习题
(1)使用CROSS APPLY运算符和fn_TopProducts函数,为每个供应商返回两个价格最贵的产品。
涉及到的表:Production.Suppliers
期望结果:
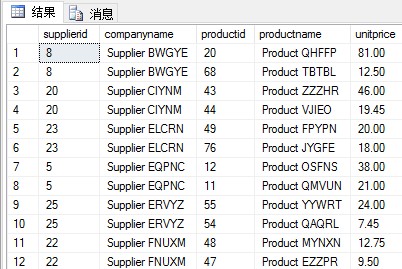
使用CROSS APPLY运算符为每个供应商应用前一个fn_TopProducts函数。
|
1
2
3
4
5
6
7
|
SELECT supplierid , companyname , productid , productname , unitpriceFROM Production.Suppliers AS S CROSS APPLY fn_TopProducts(S.supplierid, 2) AS P |
参考资料:
《SQL2008技术内幕:T-SQL语言基础》
作 者: Jackson0714
出 处:http://www.cnblogs.com/jackson0714/
关于作者:专注于微软平台的项目开发。如有问题或建议,请多多赐教!
版权声明:本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接。
特此声明:所有评论和私信都会在第一时间回复。也欢迎园子的大大们指正错误,共同进步。或者直接私信我
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是作者坚持原创和持续写作的最大动力!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号