

Django模型系统——ORM中跨表、聚合、分组、F、Q
核心知识点:
1.明白表之间的关系
2.根据关联字段确定正反向,选择一种方式
在Django的ORM种,查询既可以通过查询的方向分为正向查询和反向查询,也可以通过不同的对象分为对象查询和Queryset查询。
下面会一一进行讲解,首先给出表结构对应关系,以及表格中的数据:



from django.db import models # Create your models here. class Book(models.Model): title = models.CharField(max_length=32) publish_date = models.DateField(auto_now_add=True) price = models.DecimalField(max_digits=5, decimal_places=2) # 创建外键,关联publish,一个出版社有多本书,书和出版社是多对一 publisher = models.ForeignKey(to="Publisher") # 创建多对多关联author #一本书可能有多个作者,一个作者可能有多本书,因此双方是多对多的关系 #因此会自动生成author_book表 #定义关系在book或者author任意一张表中指定都可以 #但是一般放在字段稍微少的表格中这样有利于数据查询 author = models.ManyToManyField(to="Author") def __str__(self): return self.title # 出版社 class Publisher(models.Model): name = models.CharField(max_length=32) city = models.CharField(max_length=32) def __str__(self): return self.name # 作者 class Author(models.Model): name = models.CharField(max_length=32) age = models.IntegerField() phone = models.IntegerField() #作者和详情表是一对一关联 detail = models.OneToOneField(to="AuthorDetail") def __str__(self): return self.name # 作者详情 class AuthorDetail(models.Model): addr = models.CharField(max_length=64) email = models.EmailField()
mysql> show tables; +----------------------------+ | Tables_in_books | +----------------------------+ | app01_author | | app01_authordetail | | app01_book | | app01_book_author | | app01_publisher | | auth_group | | auth_group_permissions | | auth_permission | | auth_user | | auth_user_groups | | auth_user_user_permissions | | django_admin_log | | django_content_type | | django_migrations | | django_session | +----------------------------+ 15 rows in set (0.00 sec) mysql> select * from author; ERROR 1146 (42S02): Table 'books.author' doesn't exist mysql> select * from app01_author; +----+-----------+-----+--------+-----------+ | id | name | age | phone | detail_id | +----+-----------+-----+--------+-----------+ | 6 | 路遥 | 78 | 12 | 1 | | 7 | 黄仁宇 | 67 | 12345 | 2 | | 8 | 陈忠实 | 55 | 789 | 3 | | 9 | 刘天斯 | 35 | 567 | 4 | | 10 | 老男孩 | 40 | 456 | 5 | | 11 | 北岛 | 56 | 123 | 6 | | 12 | 付磊 | 35 | 56788 | 7 | | 13 | 张益军 | 38 | 234566 | 8 | +----+-----------+-----+--------+-----------+ 8 rows in set (0.00 sec) mysql> select * from app01_publisher; +----+-----------------------+--------+ | id | name | city | +----+-----------------------+--------+ | 1 | 机械工业出版社 | 杭州 | | 2 | 电子工业出版社 | 北京 | | 3 | 长江文艺出版社 | 武汉 | | 4 | 人民出版社 | 北京 | | 5 | 岳麓书社出版社 | 扬州 | +----+-----------------------+--------+ 5 rows in set (0.00 sec) mysql> select * from app01_authordetail; +----+--------------+-------+ | id | addr | email | +----+--------------+-------+ | 1 | 陕西平原 | 1@ | | 2 | 美国 | 2@ | | 3 | 重庆 | 3@ | | 4 | 江苏扬州 | 4@ | | 5 | 北京 | 5@ | | 6 | 湖北宜昌 | 6@ | | 7 | 江苏 | 7@ | | 8 | 安徽芜湖 | 8@ | +----+--------------+-------+ 8 rows in set (0.00 sec) mysql> select * from app01_book; +----+----------------------------+--------------+-------+--------------+ | id | title | publish_date | price | publisher_id | +----+----------------------------+--------------+-------+--------------+ | 1 | 平凡的世界 | 2009-04-22 | 56.00 | 4 | | 2 | 跟老男孩学shell脚本 | 2012-02-16 | 78.00 | 2 | | 3 | 万历十五年 | 2004-04-21 | 39.90 | 3 | | 4 | python自动化运维 | 2017-01-10 | 68.00 | 1 | | 5 | 中国大历史 | 2014-01-14 | 45.00 | 5 | | 6 | 北岛诗集 | 1999-10-10 | 29.90 | 3 | | 7 | Redis运维与开发 | 2019-10-01 | 68.00 | 1 | +----+----------------------------+--------------+-------+--------------+ 7 rows in set (0.00 sec) mysql> select * from app01_book_author; +----+---------+-----------+ | id | book_id | author_id | +----+---------+-----------+ | 1 | 1 | 6 | | 2 | 2 | 10 | | 3 | 3 | 7 | | 4 | 4 | 9 | | 5 | 5 | 7 | | 6 | 6 | 11 | | 7 | 7 | 12 | | 8 | 7 | 13 | +----+---------+-----------+ 8 rows in set (0.00 sec)
下面使用表格展示关系:
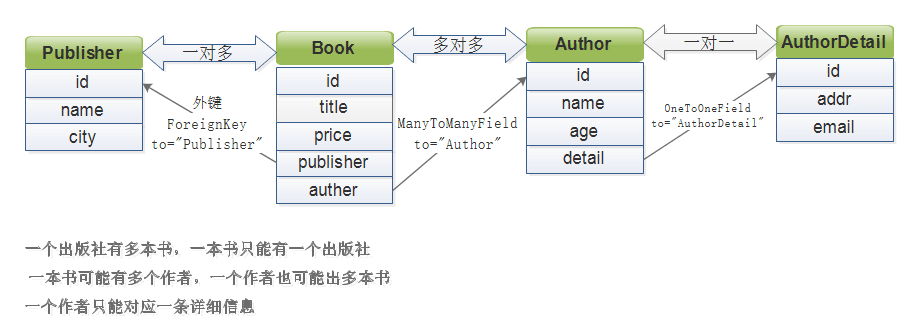
不管是基于对象查询,还是基于Queryset查询,都遵循正向查询字段,反向查询通过表名的规则。
关于何时是正向查,何时是反查取决于关联字段定义在那个列表上,如果字段在本地,查询关联字段就是正向查,反之则是反向查询。
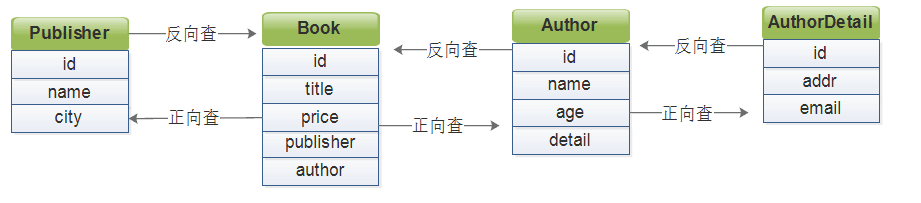
关于格式上的用法:
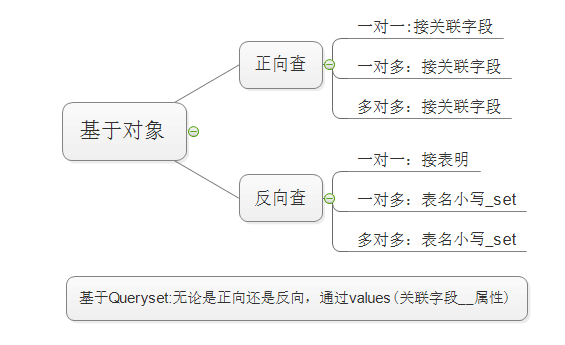
一、基本查询
1.一对一(Author和Authordetail)
(1)正向查询:查询黄仁宇的所在地址
可以看出,需要跨表,下面使用两种方式查询。
首先通过对象正向查:
models.Author.objects.filter(name="黄仁宇").first().detail.addr '美国' #首先作者查信息,从作者查,所以是正向查询 #字段定义在谁那里,谁就是正的一方 #首先找到黄仁宇这个对象 models.Author.objects.filter(name="黄仁宇").first() #然后通过detail这个字段直接查询相关联的对象 models.Author.objects.filter(name="黄仁宇").first().detail
通过Queryset对象正向查:
#正向查询按找字段名 models.Author.objects.filter(name="黄仁宇").values("detail__addr").first() {'detail__addr': '美国'} #这样也是可以得到相应的结果 #为什么说是基于queryset对象正向查询了? models.Author.objects.filter(name="黄仁宇") <QuerySet [<Author: 黄仁宇>]> #这是一个对象 #当然返回的结果也是对象 models.Author.objects.filter(name="黄仁宇").values("detail__addr") <QuerySet [{'detail__addr': '美国'}]> #values其实就是帮你做了一个循环,按照你的要求得到相应的字段值
(2)反向查询:查询住在北京的作家的名称
分析:有住址的是一张表,有作家姓名的是一张表,所以要跨表。
基于对象查询:
#反向查询按照表名(小写) models.AuthorDetail.objects.filter(addr="北京").first().author.name '老男孩' #先找到住在北京的对象 models.AuthorDetail.objects.filter(addr="北京").first() #然后通过表名author直接查询,得到的也是对象
基于Queryset查询:
#反向查询通过表名,而且是基于Queryset models.AuthorDetail.objects.filter(addr="北京").values("author__name").first() {'author__name': '老男孩'} #Queryset对象返回的也是Queryset对象,values只是帮你循环取值,不会帮你转换数据类型
2.多对一(Book与publisher)
(1)正向查询:打印《万历十五年》这本书出版社的名字
分析:正向查询依然按照字段名publisher
基于对象查询:
#找到书这个对象 models.Book.objects.filter(title="万历十五年").first() <Book: 万历十五年> #找到与《万历十五年》这本书先关联的出版社的名字 models.Book.objects.filter(title="万历十五年").first().publisher <Publisher: 长江文艺出版社> #找到对象之后直接获取相应的属性 models.Book.objects.filter(title="万历十五年").first().publisher.name '长江文艺出版社'
基于Queryset查询:
#找到相应的Queryset models.Book.objects.filter(title="万历十五年").values("publisher__name") <QuerySet [{'publisher__name': '长江文艺出版社'}]> #得到相应的字段值 models.Book.objects.filter(title="万历十五年").values("publisher__name").first() {'publisher__name': '长江文艺出版社'} #为什么只有Queryset才能使用__下划线,因为values是专门正对于Queryset的方法
(2)反向查询:
反向查询通过小写表名__set
基于对象查询:
models.Publisher.objects.filter(name="长江文艺出版社").first().book_set.values() <QuerySet [{'id': 3, 'title': '万历十五年', 'publish_date': datetime.date(2004, 4, 21), 'price': Decimal('39.90'), 'publisher_id': 3}, {'id': 6, 'title': '北岛诗集', 'publish_date': datetime.date(1999, 10, 10), 'price': Decimal('29.90'), 'publisher_id': 3}]>
基于Queryset对象查询:
models.Publisher.objects.filter(name="长江文艺出版社").values("book__title") <QuerySet [{'book__title': '万历十五年'}, {'book__title': '北岛诗集'}]>
3.多对多
(1)正向查询:Redis运维与开发所有的作者的名字
基于对象查询:
#找到相对应的对象 models.Book.objects.filter(title="Redis运维与开发") <QuerySet [<Book: Redis运维与开发>]> #找到对象相关联的作者 models.Book.objects.filter(title="Redis运维与开发").first().author.values() <QuerySet [{'id': 12, 'name': '付磊', 'age': 35, 'phone': 56788, 'detail_id': 7}, {'id': 13, 'name': '张益军', 'age': 38, 'phone': 234566, 'detail_id': 8}]> #取出相应的字段值 models.Book.objects.filter(title="Redis运维与开发").first().author.values("name",) <QuerySet [{'name': '付磊'}, {'name': '张益军'}]>
基于Queryset查询
#找到Queryset对象
models.Book.objects.filter(title="Redis运维与开发") <QuerySet [<Book: Redis运维与开发>]>
#直接取相应的字段 models.Book.objects.filter(title="Redis运维与开发").values("author__name") <QuerySet [{'author__name': '付磊'}, {'author__name': '张益军'}]>
(2)反向查询:黄仁宇出的所有书的名字, author——》book,属于多对多,字段定义在book,属于反向查询
基于对象查询:
#获取黄仁宇这个任务对象 models.Author.objects.filter(name="黄仁宇").first() <Author: 黄仁宇> #通过表名+set获取相关联的书籍名称 models.Author.objects.filter(name="黄仁宇").first().book_set <django.db.models.fields.related_descriptors.create_forward_many_to_many_manager.<locals>.ManyRelatedManager object at 0x0000022D330E73C8> #获取相应的属性值 models.Author.objects.filter(name="黄仁宇").first().book_set.values("title") <QuerySet [{'title': '万历十五年'}, {'title': '中国大历史'}]>
基于Queryset查询:
#获取黄仁宇这个Queryset models.Author.objects.filter(name="黄仁宇") <QuerySet [<Author: 黄仁宇>]> #直接通过values特性获取相应的信息 models.Author.objects.filter(name="黄仁宇").values("book__title") <QuerySet [{'book__title': '万历十五年'}, {'book__title': '中国大历史'}]>
还有在过滤元素的时候,还可以通过__可以跨表进行参数设置:
#书找书 models.Book.objects.filter(author__name="黄仁宇").values("title") <QuerySet [{'title': '万历十五年'}, {'title': '中国大历史'}]> #可以看到与刚才基于对象和Queryset跨表结果一直 #作者找书 models.Author.objects.filter(name="黄仁宇").values("book__title") <QuerySet [{'book__title': '万历十五年'}, {'book__title': '中国大历史'}]>
直接对着所需的对象,然后通过下换线过滤这种方法来的更加直白。
拓展:查询“机械工业出版社”出版的书籍名和书籍的作者姓名
#首先来查看需求 #出版社一个表、书籍一个表以及作者一个表,也就是有三个表 #正向查 models.Book.objects.filter(publisher__name="机械工业出版社").values_list("title","author__name") <QuerySet [('python自动化运维', '刘天斯'), ('Redis运维与开发', '付磊'), ('Redis运维与开发', '张益军')]> #联合book--publisher,找到书名 #联合book--author,再找到作者名, #与上一题相比,就实在显示的时候多了一个__跨表差 #反向查 models.Publisher.objects.get(name="机械工业出版社").book_set.all().values_list("title","author__name") <QuerySet [('python自动化运维', '刘天斯'), ('Redis运维与开发', '付磊'), ('Redis运维与开发', '张益军')]> #publisher—(正向)—》book—(反向)—》author #双下划线反向查 models.Publisher.objects.filter(name="机械工业出版社").values_list("book__title","book__author__name") <QuerySet [('python自动化运维', '刘天斯'), ('Redis运维与开发', '付磊'), ('Redis运维与开发', '张益军')]> #最后显示的时候一次性跨了两张表
二、聚合查询和分组查询
1.聚合
aggregate()是QuerySet 的一个终止子句,意思是说,它返回一个包含一些键值对的字典。键的名称是聚合值的标识符,值是计算出来的聚合值。键的名称是按照字段和聚合函数的名称自动生成出来的。
from django.db.models import Avg models.Book.objects.all().aggregate(Avg("price")) {'price__avg': 54.971429}
如果你想要为聚合值指定一个名称,可以向聚合子句提供它。
models.Book.objects.all().aggregate(average_price=Avg("price")) {'average_price': 54.971429}
如果你希望生成不止一个聚合,你可以向aggregate()子句中添加另一个参数。所以,如果你也想知道所有图书价格的最大值和最小值,可以这样查询:
models.Book.objects.all().aggregate(Avg("price"),Max("price"),Min("price")) {'price__avg': 54.971429, 'price__max': Decimal('78.00'), 'price__min': Decimal('29.90')}
2.分组
为调用的QuerySet中每一个对象都生成一个独立的统计值
示例1:统计每一本书的作者个数
from django.db.models import Avg,Max,Min,Count book_list = models.Book.objects.all().annotate(author_num=Count("author")) for obj in book_list: print(obj.author_num) 1 1 1 1 1 1
示例2:统计出每个出版社买的最便宜的书的价格
publisher_list = models.Publisher.objects.annotate(min_price=Min("book__price")) for obj in publisher_list: print(obj.min_price) 68.00 78.00 29.90 56.00 45.00
方法二:
models.Book.objects.values("publisher__name").annotate(min_price=Min("price")) <QuerySet [{'publisher__name': '机械工业出版社', 'min_price': Decimal('68.00')}, {'publisher__name': '电子工业出版社', 'min_price': Decimal('78.00')}, {'publisher__name': '长江文艺出版社', 'min_price': Decimal('29.90')}, {'publisher__name': '人民出版社', 'min_price': Decimal('56.00')}, {'publisher__name': '岳麓书社出版社', 'min_price': Decimal('45.00')}]>
示例3:统计不止一个作者的图书
models.Book.objects.annotate(author_num=Count("author")).filter(author_num__gt=1) <QuerySet [<Book: Redis运维与开发>]>
示例4:根据一本图书作者数量的多少对查询集 QuerySet进行排序
models.Book.objects.annotate(author_num=Count("author")).order_by("author_num") <QuerySet [<Book: 平凡的世界>, <Book: 万历十五年>, <Book: 中国大历史>, <Book: 跟老男孩学shell脚本>, <Book: python自动化运维>, <Book: 北岛诗集>, <Book: Redis运维与开发>]>
示例5:查询各个作者出的书的总价格
models.Author.objects.annotate(sum_price=Sum("book__price")).values("name", "sum_price") <QuerySet [{'name': '路遥', 'sum_price': Decimal('56.00')}, {'name': '黄仁宇', 'sum_price': Decimal('84.90')}, {'name': '陈忠实', 'sum_price': None}, {'name': '刘天斯', 'sum_price': Decimal('68.00')}, {'name': '老男孩', 'sum_price': Decimal('78.00')}, {'name': '北岛', 'sum_price': Decimal('29.90')}, {'name': '付磊', 'sum_price': Decimal('68.00')}, {'name': '张益军', 'sum_price': Decimal('68.00')}]>
三、F查询和Q查询
1.F查询
在上面所有的例子中,我们构造的过滤器都只是将字段值与某个常量做比较。如果我们要对两个字段的值做比较,那该怎么做呢?
Django 提供 F() 来做这样的比较。F() 的实例可以在查询中引用字段,来比较同一个 model 实例中两个不同字段的值。
示例1:
查询评论数大于收藏数的书籍
from django.db.models import F models.Book.objects.filter(commnet_num__lt=F('keep_num'))
Django 支持 F() 对象之间以及 F() 对象和常数之间的加减乘除和取模的操作。
models.Book.objects.filter(commnet_num__lt=F('keep_num')*2)
修改操作也可以使用F函数,比如将每一本书的价格提高30元
models.Book.objects.all().update(price=F("price")+30)
引申:
如果要修改char字段咋办?
如:把所有书名后面加上(第一版)
>>> from django.db.models.functions import Concat >>> from django.db.models import Value >>> models.Book.objects.all().update(title=Concat(F("title"), Value("("), Value("第一版"), Value(")")))
2.Q查询
filter() 等方法中的关键字参数查询都是一起进行“AND” 的。 如果你需要执行更复杂的查询(例如OR语句),你可以使用Q对象。
示例1:
查询作者名是黄仁宇或老男孩
from django.db.models import Q models.Book.objects.filter(Q(author__name="黄仁宇")|Q(author__name="老男孩")) <QuerySet [<Book: 跟老男孩学shell脚本>, <Book: 万历十五年>, <Book: 中国大历史>]>
你可以组合& 和| 操作符以及使用括号进行分组来编写任意复杂的Q 对象。同时,Q 对象可以使用~ 操作符取反,这允许组合正常的查询和取反(NOT) 查询。
示例2:
查询作者名字是黄仁宇并且不是2014年出版的书的书名
models.Book.objects.filter(Q(author__name="黄仁宇") & ~Q(publish_date__year=2014)).values_list("title") <QuerySet [('万历十五年',)]>
查询函数可以混合使用Q 对象和关键字参数。所有提供给查询函数的参数(关键字参数或Q 对象)都将"AND”在一起。但是,如果出现Q 对象,它必须位于所有关键字参数的前面。
示例3:
查询出版年份是2017或2018,书名中带物语的所有书。
models.Book.objects.filter(Q(publish_date__year=2004) | Q(publish_date__year=2014), title__icontains="历") <QuerySet [<Book: 万历十五年>, <Book: 中国大历史>]>


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 终于写完轮子一部分:tcp代理 了,记录一下
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理