

性能优化——存储性能优化
核心知识点:
存储性能优化无非从磁盘类型、数据结构以及存储备份方式来进行,根据业务场景选择最合适的方案。
1.机械vsSSD(磁盘类型)
a.机械:由于每次访问数据,都需要移动磁头臂,因此连续访问和随机访问性能差别比较大。快速顺序读写、慢速随机读写
b.SSD:使用硅晶体存储数据,因此像内存一样随机访问,功耗和噪音也比较小,但是可靠性和性价比有待提高。
2.B+树 vs LSM树(数据结构)
a.为了优化磁盘的随机读写能力,文件系统或数据库系统会先将数据排序,保证数据更新、插入、删除之后依然有序,加快检索速度。
b.B+树:传统的关系型数据库使用,N叉排序树,一般两级索引,最多三层树,需要5次才能更新一条数据。
c.LSM树:非关系型使用,N阶排序树,数据写在内存中完成,因此读写性能可能会由于B+
d.LSM存储步骤:先往内存排序中写,到达阀值与磁盘最新排序树合并,再次到达阀值,与上下级排序树合并。
e.读:先访问内存,内存没有再访问磁盘;写:在内存中进行
3.RAID vs HDFS(存储和备份方式)
1)RAID{关键词:条带(striping)、镜像(mirroring)、奇偶校验(XOR)}
a.RAID0:将数据分段存储在多个磁盘上,没有冗余(条带)
b.RAID1:将数据同时存储在两个或多个磁盘上,写的速度低,读的速度快,磁盘利用率低。(镜像)
c.RAID01:先做条带(0),再做镜像(1);RAID10:先做镜像(1),在做条带(0);但是RAID10的安全性能高于RAID01。(条带+镜像)
d.RAID3:拿出一块磁盘做奇偶校验块,但是对于数据修改较多的场景,奇偶校验块的压力比较大,更换频繁。(XOR)
e.RAID5:数据条带分布在磁盘上,奇偶校验数据分布在所有磁盘上。(XOR)
f.RAID6:与RAID5唯一不同的是,使用不同算法有两份校验数据,能在两块磁盘损坏的情况下恢复数据。(XOR)
2)HDFS:
a.在整个集群上进行数据读写和备份,不是一磁盘为单位,而是以服务器为存储单位。
b.1个名称节点和多个数据节点。一份数据写完之后会自动存储两份。
在网站应用中,海量的数据读写对磁盘访问造成巨大压力,虽然可以通过Cache解决一部分数据读压力,
但是很多时候,磁盘仍然是系统最严重的瓶颈。而且磁盘中存储的数据是网站最重要的资产,磁盘的可用性和容错性也至关重要。
一、机械硬盘 vs 固态硬盘
机械硬盘是目前最常用的一种硬盘,通过马达驱动磁头臂,带动磁头到指定的磁盘位置访问数据,
由于每次访问数据都需要移动磁头臂,因此机械硬盘在数据连续访问(要访问的数据存储在连续的磁盘空间上)
和随机访问(要访问的数据存储在不连续的磁盘空间)时,由于移动磁头臂的次数相差巨大,性能表现差别也非常大。
固态硬盘又称作SSD或Flash硬盘,这种硬盘没有机械装置,数据存储在可持久记忆的硅晶体上,
因此可以像内存一样快速随机访问。而且SSD具有更小的功耗和更少的磁盘震动与噪音。
在网站应用中,大部分应用访问数据都是随机的,这种情况下SSD具有更好的性能表现。
但是目前SSD磁盘还不太成熟,可靠性、性价比都有待提升,因此SSD的使用还在摸索阶段。
二、B+树 vs LSM树
由于传统的机械磁盘具有快速顺序读写、慢速随机读写的访问特性,这个特性对磁盘存储结构和算法的选择影响甚大。
为了改善数据访问特性,文件系统或数据库系统通常会对数据排序后存储,加快数据检索速度,
这就需要保证数据在不断更新、插入、删除后依然有序,传统关系数据库的做法是使用B+树。
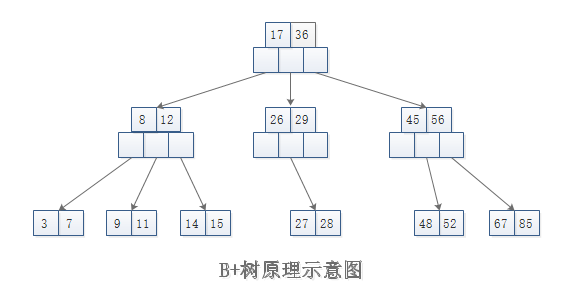
B+树是一种专门针对磁盘存储而优化的N叉排序树,以节点为单位存储在磁盘中,
从根开始查找所需数据所在节点编号和磁盘位置,将其加载到内存中然后继续查找,直到找到所需的数据。
目前数据库多采用两级索引的B+树,树的层次最多三层,因此可能需要5次磁盘访问才能更新一条记录
(三次磁盘访问获取数据索引及行ID,然后再进行一次数据文件读操作及一次数据文件写操作。)
但是由于每次磁盘访问都是随机的,而传统机械硬盘可能在数据随机访问时性能较差,
每次数据访问都需要多次访问磁盘,影响数据访问性能。
目前许多NoSQL产品采用LSM树作为主要数据结构。
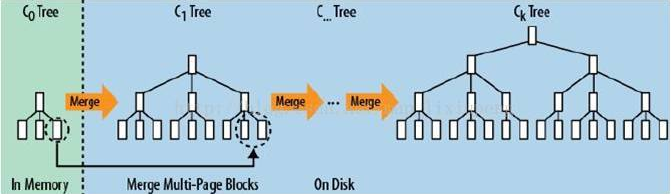
LSM 树可以看作是一个N阶合并树。数据写操作(包括插入、修改、删除)都在内存中进行,
并且都会创建一个新纪录(修改会创建新的数据值,而删除会记录一个删除一个标志),
这些数据在内存中仍然还是一棵排序树,当数据量超过设定的内存阀值后,会将这颗排序树和磁盘上最新的排序合并。
当这棵排序树的数据量也超过设定阀值后,和磁盘上下一级的排序树合并。合并过程中,会用最新更新的数据覆盖旧的数据(或者记录为不同版本)。
在需要进行操作时,总是从内存的排序树开始搜索,如果没有找到,就从磁盘上的排序树顺序查找。
在LMS树上进行一次数据更新不需要磁盘访问,在内存即可完成,速度远快于B+树。
当数据访问以写操作为主,而都操作集中在最近写入的数据上是,使用LSM树可以极大程度地减少磁盘的访问次数,加快访问速度。
作为存储结构,B+树不是关系数据库所独有的,NoSQL数据库也可以使用B+树。
同理,关系数据库有也可以使用LSM,而且随着SSD磁盘的日趋成熟及大容量持久存储的内存技术的出现,相信B+树这一古老的存储结构会再次算法青春。
三、RAID vs HDFS
1.RAID
RAID全称为独立磁盘冗余阵列(Redundant Array of Independent Disks),
基本思想就是把多个相对便宜的硬盘组合起来,成为一个硬盘阵列组,使性能达到甚至超过一个价格昂贵、 容量巨大的硬盘。(目的)
RAID通常被用在服务器电脑上,使用完全相同的硬盘组成一个逻辑扇区,因此操作系统只会把它当做一个硬盘。
RAID分为不同的等级,各个不同的等级均在数据可靠性及读写性能上做了不同的权衡。 在实际应用中,可以依据自己的实际需求选择不同的RAID方案。
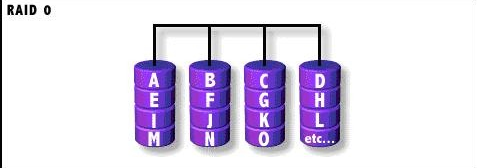
1).RAID0
RAID0称为条带化(Striping)存储,将数据分段存储于 各个磁盘中,读写均可以并行处理。因此其读写速率为单个磁盘的N倍(N为组成RAID0的磁盘个数),但是却没有数 据冗余,单个磁盘的损坏会导致数据的不可修复。
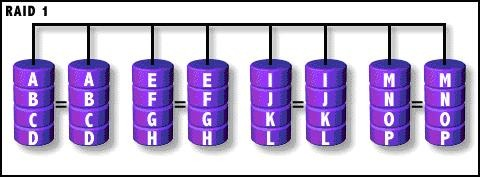
2).RAID1
镜像存储(mirroring),没有数据校验。数据被同等地写入两个或多个磁盘中,
可想而知,写入速度会比较 慢,但读取速度会比较快。读取速度可以接近所有磁盘吞吐量的总和,写入速度受限于最慢 的磁盘。 RAID1也是磁盘利用率最低的一个。
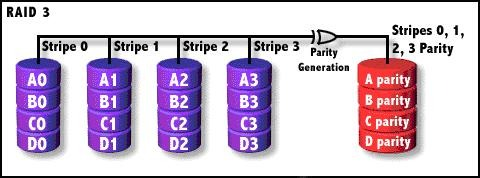
3).RAID3
一般情况下,一台服务器上不会出现同时损坏两块磁盘的情况,在只损坏一块磁盘的情况下,
如果能利用其它磁盘的数据恢复损坏磁盘的数据,这样在保证可靠性和性能的同时,磁盘利用率也得到大幅提升。
RAID3在数据写入的时候,将数据分为N-1份,并发写入N-1块磁盘,并在第N块磁盘记录校验数据,
任何一块磁盘损坏(包括校验数据磁盘),都可以利用其它N-1块磁盘的数据恢复。
但在数据修改较多的场景中,修改任何磁盘数据都会导致第N块磁盘重写校验数据,
频繁写入的后果是第N块磁盘比其他磁盘容易损坏,容易频繁更换,因此RAID3在实践中很少使用。
4).RAID5
奇偶校验(XOR),数据以块分段条带化存储。校验信息交叉地存储在所有的数据盘上。

RAID5把数据和相对应的奇偶校验信息存储到组成RAID5的各个磁盘上,
并且奇偶校验信息和 相对应的数据分别存储于不同的磁盘上,其中任意N-1块磁盘上都存储完整的数据,
也就是 说有相当于一块磁盘容量的空间用于存储奇偶校验信息。
因此当RAID5的一个磁盘发生损坏 后,不会影响数据的完整性,从而保证了数据安全。
当损坏的磁盘被替换后,RAID还会自动利用剩下奇偶校验信息去重建此磁盘上的数据,来保持RAID5的高可靠性。
RAID 5可以理解为是RAID 0和RAID 1的折衷方案。RAID 5可以为系统提供数据安全保障,但 保障程度要比镜像低而磁盘空间利用率要比镜像高。
RAID 5具有和RAID 0相近似的数据读取速度,只是因为多了一个奇偶校验信息,写入数据的速度相对单独写入一块硬盘的速度略慢。
5).RAID6
类似RAID5,但是增加了第二个独立的奇偶校验信息块,两个独立的奇偶系统使用不同的算法, 数据的可靠性非常高,即使两块磁盘同时失效也不会影响数据的使用。
但RAID 6需要分配给奇偶校验信息更大的磁盘空间,同时需要计算,相对于RAID 5有更大的“写损失”,因此“写性能”非常差。

由图所知,每个硬盘上除了都有同级数据XOR校验区外,还有一个针对每个数据 块的XOR校验区。
当然,当前盘数据块的校验数据不可能存在当前盘而是交错存储的。
从数 学角度来说,RAID 5使用一个方程式解出一个未知变量,而RAID 6则能通过两个独立的线性 方程构成方程组,从而恢复两个未知数据。
伴随着硬盘容量的增长,RAID6已经变得越来越重要。
TB级别的硬盘上更容易造成数据丢失, 数据重建过程(比如RAID5,只允许一块硬盘损坏)也越来越长,甚至到数周,这是完全不可接受的。
而RAID6允许两 块硬盘同时发生故障,所以渐渐受到人们的青睐。
6).RAID 01
RAID0和RAID1的结合。先做条带(0),再做镜像(1)。
RAID01中块作为独立的个体,因此一个块中的部分发生损坏,整个块都不能访问。

7).RAID10
相对于RAID01来说,先做镜像(1),再做条带(0)。
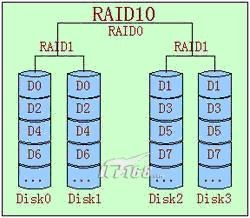
RAID01和RAID10非常相似,二者在读写性能上没有什么差别。但是在安全性上RAID10要好于 RAID01。
如图中所示,假设DISK0损坏,在RAID10中,在剩下的3块盘中,只有当DISK1故障, 整个RAID才会失效。
但在RAID01中,DISK0损坏后,左边的条带将无法读取,在剩下的3快盘 中,只要DISK2或DISK3两个盘中任何一个损坏,都会导致RAID失效。

2.HDFS
RAID技术可以通过硬件实现,比如专用的RAID卡或者主板直接支持,也可以通过软件实现。
RAID在传统关系数据库及文件系统中应用比较广泛,但是大型网站比较喜欢用NoSQL,以及分布式文件系统。
在HDFS(Hadoop分布式文件系统中),系统在整个存储集群的多台服务器上进行数据并发读写和备份,
可以看作在服务器集群规模上上实现了类似RAID的功能,因此不需要磁盘RAID。
HDFS以块(Block)为单位管理文件内容,一个文件被分割成若干个Block,当应用程序写文件时,
每写完一个Block,HDFS就将其自动恢复到另外两台机器上,保证每个Block有三个副本,
即使有两台服务器宕机,数据依然可以访问,相当于实现了RAID1的数据恢复功能。
当对文件进行处理计算时,通过MapReduce并发计算任务框架,可以启动多个计算子任务(MapReduce Task),
同时读取文件的多个Block,并发处理,相当于实现了RAID0的并发访问能力。
在HDFS中有两种重要的服务器角色:NameNode(名称服务节点)和DataNode(数据存储节点)。
在整个HDFS中只部署一个实例,提供元数据服务。相当于操作系统中的文件分配表(FAT),
管理文件名Block的分配,维护整个文件系统的目录树结构。
DAtaNode则部署在HDFS集群中其它服务器上,提供真正的数据存储服务。
和操作系统一样,HDFS对数据存储空间的管理以数据块(Block)为单位,只是比操作系统中的数据块(512字节)要大的多,默认为64MB。
HDFS将DataNode上的磁盘空间分成N个这样的块,供应用程序使用。
应用程序(Client)需要写文件时,首先访问NameNode,请求分配数据块,
NameNode根据管理的DataNode服务器的磁盘空间,按照一定的负载均衡策略,分配若干数据供Client使用。
当Client写完一个数据块时,HDFS会将这个数据块再复制两份存储在其他DataNode服务器上,HDFS默认同一份数据有三个副本,保证数据可靠。
因此在HDFS中,即使DataNode服务器有多块磁盘,也不需要使用RAID进行数据备份,而是在整个集群上进行数据备份,
而且系统一旦发现某台服务器宕机,会自动利用其它机器上的数据将这台服务器上存储的数据块自动再备份一份,从而获得更高的数据可靠性。
HDFS配合MapReduce等并行计算框架进行大数据处理时,可以在整个集群上并发访问所有的磁盘,无需RAID支持。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 终于写完轮子一部分:tcp代理 了,记录一下
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理