

Pipeline
核心知识点:
1.RTT:往返时间,网络是瓶颈
2.Pipeline机制:将一组命令打包,一次发送过去,节省RTT时间
3.Pipeline和mset等的区别:
a.mset命令原子性,命令不能再拆分
b.mset一个命令对应多个键值对,而Pipeline是多条命令
c.mset只需要服务支持就可以
Redis客户端执行一条命令分为如下四个过程:
1)发送命令
2)命令排队
3)命令执行
4)返回结果
其中1)+4)称为Round Trip Time(RTT,往返时间)。
Redis提供了批量操作命令(例如mget、mset等),有效地节约RTT。
但大部分命令是不支持批量操作地,例如要执行n次hgetall命令,并没有mhgetall命令存在,需要消耗n次RTT。
Redis客户端和服务端可能部署在不同地机器上。例如客户端在北京,Redis服务端在上海,两地直线距离约为1300公里,
那么1次RTT时间=1300X2/(300000X2/3)=13毫秒(光在真空中传输速度为每秒30万公里,这里假设光纤为光速地2/3),
那么客户端在1秒内大约只能执行80次左右地命令,这个和Redis地高并发吞吐特性背道而驰。
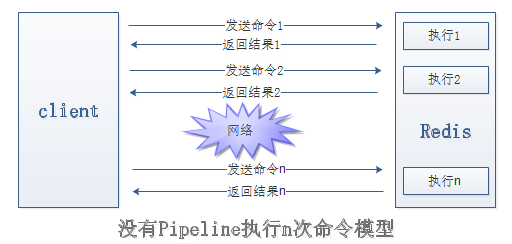
Pipeline(流水线)机制能改善上面这类问题,它能将一组Redis命令进行组装,
通过一次RTT传输给Redis,再将这组Redis命令地执行结果按照顺序返回给客户端。
而使用了Pipeline执行了n次命令,整个过程需要一次PTT。
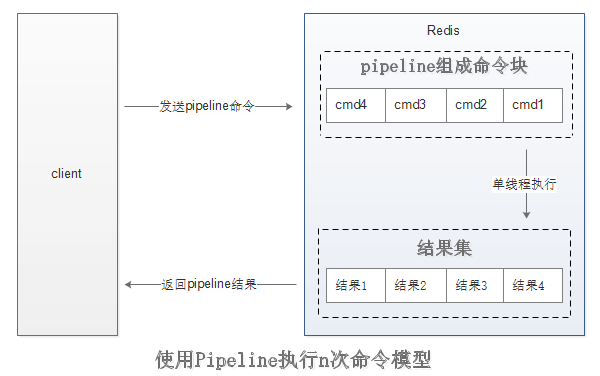
Pipeline并不是什么新地技术或机制,很多技术上都使用过。而且RTT在不同环境下会有不同,
例如同机房和同机器会比较块,跨机房跨地区会比较慢。Redis命令真正执行地时间通常在微秒级别,所以才会有Redis性能瓶颈是网络这样地说法。
redis-cli地--pipe选项实际上就是使用Pipeline机制。
可以使用Pipeline模拟出批量操作地效果,但是在使用时要注意它与原生批量命令地区别,具体包含一下几点:
- 原生批量命令是原子的,Pipeline是非原子的。
- 原生批量命令是一个命令对应多个key、Pipeline支持多个命令。
- 原生批量命令是Redis服务端支持实现的,而Pipe需要服务端和客户端共同实现。
Pipe虽然好用,但是每次Pipeline组装的命令个数不能没有节制,否则一次组装Pipeline数据量过大,
一方面会增加客户端的等待时间,另一方面会造成一定的网络阻塞,可以将一次包含大量命令的Pipeline拆分成多次较小的Pipeline来完成。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 终于写完轮子一部分:tcp代理 了,记录一下
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理