

python中的函数、生成器的工作原理
1.python中函数的工作原理
def foo(): bar() def bar(): pass
python的解释器,也就是python.exe(c编写)会用PyEval_EvalFramEx(c函数)运行foo()函数
首先会创建一个栈帧(stack Frame),在栈帧对象的上下文里面去运行这个字节码。
import dis print(dis.dis(foo)) #打印字节码
可以尝试着去打印foo的字节码:
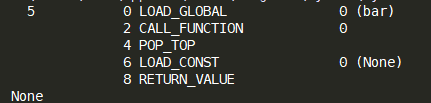
关于字节码的解释:
LOAD_GLOBAL:首先导入bar这个函数
CALL_FUNCTION:执行bar函数
POP_TOP:从栈的顶端去把元素打印出来
LOAD_CONST:返回结果,这里没有return,就是None
RETURN_VALUE:返回结果
打印bar的字节码:
print(dis.dis(bar))

这个字节码全局是唯一的,函数是全局唯一的,然后在函数里面会调用另外一个函数。
当foo调用函数bar,又会创建一个栈帧,然后将这个函数的控制权交给这个栈帧。
所有的栈帧都分配在内存中,它不是放在栈的内存上,而是放在堆的内存上,你不去释放它就会一直存在我们的内存当中。
这就决定了栈帧可以独立于调用者存在,比如就算函数不存在了,只要有指针指向bar这个栈帧,就可以对其进行控制。
(python中一切皆对象,栈帧也是对象,是一个字节码对象)

import inspect frame = None #保存frame def foo(): bar() def bar(): global frame #引入全局变量 frame = inspect.currentframe() #将bar的frame赋给全局变量 foo() print(frame.f_code.co_name) #bar 函数退出之后,依然可以拿到bar函数的栈帧 caller_frame = frame.f_back print(caller_frame.f_code.co_name) #foo 也可以拿到foo函数的栈帧
2.生成器的实现原理
在静态语言中,函数调用的时候是一个栈的形式,函数调用完成之后栈就会被销毁。
下面是函数的调用过程:
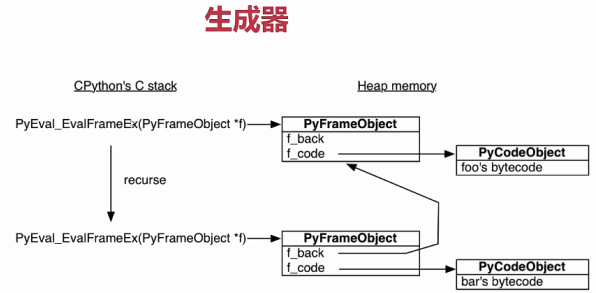
PyEval_evalFrameEx会创建一个foo的栈帧对象,这个对象里面有两个属性。f_back为None,因为没有上层函数,f_code指向foo的字节码
同时PyEval_evalFrameEx也会创建一个bar的栈帧对象,f_back指向foo,f_code指向bar的字节码。
最大的特点就是栈帧对象存在于堆内存中,这样生成器才有实现的可能。
def gen_func(): yield 1 name = "ming" yield 2 age = 28 return "kebi" #在早期的生成器版本中不能使用return
当python解释器在读取gen_fun()这个函数的时候,发现yield关键字就会将其标记为生成器函数。
gen_func()
当我们来调用这个函数的时候,就会返回一个生成器对象。
这个生成器对象是将PyFrame做了一层封装。

在PyFrameObject和PyCodeObject上面又封装了一层PyGenObject,就是python的生成器对象。
PyGenObject中gi_frame属性指向PyGrameObject,gi_code属性指向PyCodeObject。
PyFrameObject又有f_lasti和f_locals属性。
f_lasti会指向最近执行的这个代码。
可以尝试打印字节码:
def gen_func(): yield 1 name = "ming" yield 2 age = 28 return "kebi" #在早期的生成器版本中不能使用return import dis gen = gen_func() print(dis.dis(gen))
查看结果:
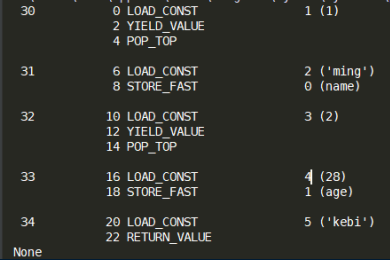
这里面可以看到有两次yield。当我们每一次对生成器做一次调用的时候,它遇到yield就会停止。
停止了之后,就会记录f_lasti(位置)和f_locals(变量)这两个值。
可以尝试着调用打印取每一个值,f_lasti和f_locals的变化
print(gen.gi_frame.f_lasti) #-1 print(gen.gi_frame.f_locals) #{} next(gen) print(gen.gi_frame.f_lasti) #2 print(gen.gi_frame.f_locals) #{} next(gen) print(gen.gi_frame.f_lasti) #12 print(gen.gi_frame.f_locals) #{'name':'ming'}
与上方字节码是一样的。
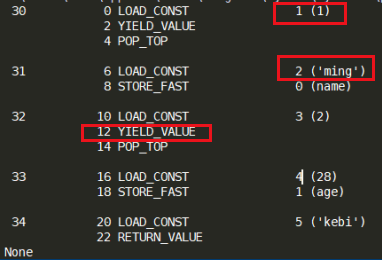
这样整个生成器对象就存在与堆内存中,可以独立存在,每次执行一次函数,就会生成一个栈帧对象。
我们可以在任何地方,只要能拿到这个栈帧对象就能够往前走。这也是python中协程的一个理论基础。
此时我们可以知道为什么生成器是一个一个返回。
3.pyc文件
当你在执行python代码的时候,会发现执行目录下面会出现.pyc文件。
[root@tuoguan resources]# ls r1.py r1.pyc r2.py r3.py [root@tuoguan resources]# cat r1.pyc ¶:]c@s dZdS(tname_r1N(R(((s/tmp/demo/resources/r1.py<module>s
r1.pyc是一个二进制文件,当执行的文件中存在包的引入就会编译生成二进制文件。
当python程序运行时,编译的结果则是保存在位于内存中的PyCodeObject中,当Python程序运行结束时,Python解释器则将PyCodeObject写回到pyc文件中。
当python程序第二次运行时,首先程序会在硬盘中寻找pyc文件,如果找到,则直接载入,否则就重复上面的过程。
所以我们应该这样来定位PyCodeObject和pyc文件,我们说pyc文件其实是PyCodeObject的一种持久化保存方式。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 终于写完轮子一部分:tcp代理 了,记录一下
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
2018-07-26 Redis——安装
2018-07-26 MySQL——安装