Python 【面试总结】
基于 Django框架实现,采用 RBAC 权限管理机制
-
用户表、角色表、权限表
-
用户表:账号、姓名、邮箱、添加时间、最后登录时间、账号是否禁止登录
-
角色表:商品管理员、订单管理员、超级管理员
-
资源列表:资源名称(项目模块名称),资源路径(后台路由)
-
资源分类:商品模块、订单模块、营销模块、权限模块、内容模块、其他模块
-
-

- RBAC角色权限管理机制实现思路
# 面向资源编程 https://www.shiyanlou.com/v1/books/ # 请求后端 books书籍表中数据 get post # 用户表 # 角色表 # 权限表 get/post/put/delete 对应关系
- 所有权限的本质是对数据库中表中数据增删改查的操作
- 而这些增删改查的操作是通过前端不同路由,通过get、post、put、delete方法操作数据库的
- 对权限的控制,最简单的方法就是判断当前用户是否可以对指定路由请求操作的权限
- 把角色和这个角色能够访问的 url 和 请求方式进行关联(因为正是的业务逻辑用户权限划分力度可能非常细致)
- 再简单的业务逻辑中这一张表就是权限表
| 路由 资源(可能对应的是后端路由的 name名称,可以通过name名称解析出对应路由) | 请求方式 | 说明 |
|---|---|---|
| https://www.shiyanlou.com/v1/books/ | get | 判断用户是否可以查询books表中数据 |
| https://www.shiyanlou.com/v1/books/ | post | 判断用户是否可以添加books表中数据 |
| https://www.shiyanlou.com/v1/books/ | put | 判断用户是否可以更新books表中数据 |
| https://www.shiyanlou.com/v1/books/ | delete | 判断用户是否可以删除books表中数据 |
-
后端如何判断用户权限
-
用户发送求方法 https://www.shiyanlou.com/v1/books/ 的url
-
后端首先查询时哪一个用户,然后查询当前用户的角色
-
最后判断这个角色是否可以访问 https://www.shiyanlou.com/v1/books/ 的对应方法即可
-
JWT接口安全登录验证


使用restful规范进行接口的开发和维护
- RESTful不是一种技术,而是一种接口规范,主要规范包括:1.请求方式、2.状态码、3、url规范、4、传参规范
- 请求方式method
GET :从服务器取出资源(一项或多项)
POST :在服务器新建一个资源
PUT :在服务器更新资源(客户端提供改变后的完整资源)
PATCH :在服务器更新资源(客户端提供改变的属性)
DELETE:从服务器删除资源
- 状态码
'''1. 2XX请求成功''' # 200 请求成功,一般用于GET与POST请求 # 201 Created - [POST/PUT/PATCH]:用户新建或修改数据成功。 # 202 Accepted - [*]:表示一个请求已经进入后台排队(异步任务) # 204 NO CONTENT - [DELETE]:用户删除数据成功。 '''2. 3XX重定向''' # 301 NO CONTENT - 永久重定向 # 302 NO CONTENT - 临时重定向 '''3. 4XX客户端错误''' # 400 INVALID REQUEST - [POST/PUT/PATCH]:用户发出的请求有错误。 # 401 Unauthorized - [*]:表示用户没有权限(令牌、用户名、密码错误)。 # 403 Forbidden - [*] 表示用户得到授权(与401错误相对),但是访问是被禁止的。 # 404 NOT FOUND - [*]:用户发出的请求针对的是不存在的记录。 # 406 Not Acceptable - [GET]:用户请求的格式不可得(比如用户请求JSON格式,但是只有XML格式)。 # 410 Gone -[GET]:用户请求的资源被永久删除,且不会再得到的。 # 422 Unprocesable entity - [POST/PUT/PATCH] 当创建一个对象时,发生一个验证错误。 '''4. 5XX服务端错误''' # 500 INTERNAL SERVER ERROR - [*]:服务器内部错误,无法完成请求 # 501 Not Implemented 服务器不支持请求的功能,无法完成请求 ```
- 面向资源编程: 路径,视网络上任何东西都是资源,均使用名词表示(可复数)
- 所有请求实际操作的都是数据库中的表,每一个表当做一个资源
- 资源是一个名称,所以RESTful规范中URL只能有名称或名词的复数形式
- https://api.example.com/v1/zoos
- https://api.example.com/v1/animals
- https://api.example.com/v1/employees
- 过滤,通过在url上传参的形式传递搜索条件
- https://api.example.com/v1/zoos?limit=10:指定返回记录的数量
- https://api.example.com/v1/zoos?offset=10:指定返回记录的开始位置
- https://api.example.com/v1/zoos?page=2&per_page=100:指定第几页,以及每页的记录数
- https://api.example.com/v1/zoos?sortby=name&order=asc:指定返回结果按照哪个属性排序,以及排序顺序
- https://api.example.com/v1/zoos?animal_type_id=1:指定筛选条件
- django的DRF
- 认证
- 权限
- 序列化
- 版本号
- 限流
使用websocket实现用户与旅行专家的在线聊天功能
- websocket
- webssh
- 什么是WebSSH?
- webssh 泛指一种技术可以在网页上实现一个 SSH 终端。
- ssh终端:用来通过ssh协议,连接服务器进行管理
- 运维开发方向:堡垒机登录、线上机器管理(因为运维人员不肯能24小时携带电脑)
- 在线编程:提供一个编程环境
- websocket(3w1h)
- 什么是websocket
- webSocket是一种在单个TCP连接上进行全双工通信的协议
- 客户端和服务器之间的数据交换变得更加简单,**允许服务端主动向客户端推送数据。
- 浏览器和服务器只需要完成一次握手,两者之间就直接可以创建持久性的连接,并进行双向数据传输
- websocket与http区别
- http请求建立连接只能发送一次请求,不能有服务器端主动向客户端发送请求
- websocket建立的长连接,一次连接,后续一直通信,这样节省资源,可以有客户端发送请求给服务器端
- 远古时期解决方案就是轮询
- 客户端以设定的时间间隔周期性地向服务端发送请求,频繁地查询是否有新的数据改动(浪费流量和资源)
- webSocket应用场景?
- 聊天软件:最著名的就是微信,QQ,这一类社交聊天的app
- 弹幕:各种直播的弹幕窗口
- 在线教育:可以视频聊天、即时聊天以及其与别人合作一起在网上讨论问题…
- websocket原理
- websocket首先借助http协议(通过在http头部设置属性,请求和服务器进行协议升级,升级协议为websocket的应用层协议)
- 建立好和服务器之间的数据流,数据流之间底层还是依靠TCP协议;
- websocket会接着使用这条建立好的数据流和服务器之间保持通信;
- 由于复杂的网络环境,数据流可能会断开,在实际使用过程中,我们在onFailure或者onClosing回调方法中,实现重连
- websocket实现心跳检测的思路
- 通过setInterval定时任务每个3秒钟调用一次reconnect函数
- reconnect会通过socket.readyState来判断这个websocket连接是否正常
- 如果不正常就会触发定时连接,每4s钟重试一次,直到连接成功
- 如果是网络断开的情况下,在指定的时间内服务器端并没有返回心跳响应消息,因此服务器端断开了。
- 服务断开我们使用ws.close关闭连接,在一段时间后,可以通过 onclose事件监听到。
- 什么是websocket


# 后端的django代码 from django.shortcuts import render from dwebsocket.decorators import accept_websocket,require_websocket from django.http import HttpResponse def index(request): return render(request, 'index.html') from dwebsocket.backends.default.websocket import DefaultWebSocket # request.websocket就是DefaultWebSocket对象 tmp = [] # 只有加了这个装饰器,这个视图函数才能处理websocket请求 @accept_websocket def echo(request): if not request.is_websocket(): #判断是不是websocket连接 try: #如果是普通的http方法 message = request.GET['message'] return HttpResponse(message) except: return render(request,'index.html') else: '''1.实现消息推送''' tmp.append(request.websocket) # 把所有连接的websocket连接都加入列表中 # request.websocket = <dwebsocket.backends.default.websocket.DefaultWebSocket object at 0x00000272E69A4320> # failed:Invalid frame header:你的视图没有阻塞,请求过一次后服务器端就关闭连接了 # 所以使用for循环 request.websocket 对象就会调用 __iter__()方法,利用迭代器进行阻塞 for message in request.websocket: for ws in tmp: ws.send(message) '''2.实现聊天室思路''' # d = {} # 使用了一个dict来保存数据, # d['zhangsan'] = request.websocket # key值是用户身份,value值是dict类型的{username:websocket}。 # d['zhangsan'].send(message) # 发送消息到客户端 # d['lisi'].send(message) ==> request.websocket.send(message) # 这只是个思路,如果正式使用的话,肯定会对group封装,也不会只保存在内存中,需要保存到redis中去 # 并且对每个websocket对象设置有效期,过期清除,避免长期挂起状态消耗系统资源等 ```
```html # 前端VUE代码 <template> <div> <button @click="send">发消息</button> </div> </template> <script> export default { data () { return { path:"ws://127.0.0.1:8000/echo?username=zhangsan&token=xxxx", socket:"" } }, mounted () { // 初始化 this.init() }, methods: { init: function () { if(typeof(WebSocket) === "undefined"){ alert("您的浏览器不支持socket") }else{ // 实例化socket this.socket = new WebSocket(this.path) // 监听socket连接 this.socket.onopen = this.open // 监听socket错误信息 this.socket.onerror = this.error // 监听socket消息 this.socket.onmessage = this.getMessage } }, open: function () { console.log("socket连接成功") }, error: function () { console.log("连接错误") }, getMessage: function (msg) { console.log(msg.data) // 打印后台返回的数据 }, send: function () { var params = 'hahahahhahaha'; this.socket.send(params) // 发送给后台的数据 }, close: function () { console.log("socket已经关闭") } }, destroyed () { // 销毁监听 this.socket.onclose = this.close } } </script> <style> </style> ```
使用Redis实现分布式部署单点登录
- 因为这个项目是一个分布式部署的项目,而且我们采用的是nginx负载均衡的策略,导致了每一个服务器都需要开辟一个空间来进行用户信息的维护,消耗了大量的资源,所以,我当时使用到了Redis来作为维护用户信息的空间,将用户登录的信息存入Redis中,并且在存入时设置key的过期时间,所有的服务器共用一个Redis,每次进行操作时只需要去Redis中去判断这个用户是否存在,存在的话就说明这个用户现在是登录状态,不存在就说明这个用户没有登录,或者登录已经失效,让用户进行重新登录。
- 为什么会存在单点登录的问题
- session默认是存储在当前服务器的内存中,如果是集群,那么只有登录那台机器的内存中才有这个session
- 比如说我在A机器登录,B机器是没有这个session存在的,所以需要重新验证
- 如何解决这个单点登录问题
- 不管在那一台web服务器登录,都会把token值存放到我们的一个集中管理的redis服务器中
- 但客户端携带token验证的时候,会先从redis中获取,就实现单点登录
- 现实举例
- 比如你写的一个tornado项目,分别部署到A,B两台机器上
- 如果直接使用session,那么如果在A机器登录,token只会在A服务器的内存
- 因为请求会封不到A,b连个机器,如果这个请求到了B机器,B的内存中没有就会让重新登录
- 所以登录A机器的时候我们应该把token值写入到redis中,A/B机器登录,都从redis中获取token进行校验
session,cookie,sessionStorage,localStorage的区别及应用场景
- 首先cookie和session
- Cookie机制:如果不在浏览器中设置过期时间,cookie被保存在内存中,生命周期随浏览器的关闭而结束,这种cookie简称会话cookie。如果在浏览器中设置了cookie的过期时间,cookie被保存在硬盘中,关闭浏览器后,cookie数据仍然存在,直到过期时间结束才消失。Cookie是服务器发给客户端的特殊信息,cookie是以文本的方式保存在客户端,每次请求时都带上它
- Session机制:当服务器收到请求需要创建session对象时,首先会检查客户端请求中是否包含sessionid。如果有sessionid,服务器将根据该id返回对应session对象。如果客户端请求中没有sessionid,服务器会创建新的session对象,并把sessionid在本次响应中返回给客户端。通常使用cookie方式存储sessionid到客户端,在交互中浏览器按照规则将sessionid发送给服务器。如果用户禁用cookie,则要使用URL重写,可以通过response.encodeURL(url) 进行实现;API对encodeURL的结束为,当浏览器支持Cookie时,url不做任何处理;当浏览器不支持Cookie的时候,将会重写URL将SessionID拼接到访问地址后。
- 存储内容
- cookie只能保存字符串类型,以文本的方式;
- session通过类似与Hashtable的数据结构来保存,能支持任何类型的对象(session中可含有多个对象)
- 存储的大小
- cookie:单个cookie保存的数据不能超过4kb;
- session大小没有限制。
- 安全性
- cookie:针对cookie所存在的攻击:Cookie欺骗,Cookie截获;
- session的安全性大于cookie。
- 原因如下
- sessionID存储在cookie中,若要攻破session首先要攻破cookie;
- sessionID是要有人登录,或者启动session_start才会有,所以攻破cookie也不一定能得到sessionID;
- 第二次启动session_start后,前一次的sessionID就是失效了,session过期后,sessionID也随之失效。
- sessionID是加密的
- 综上所述,攻击者必须在短时间内攻破加密的sessionID,并非易事。
- 应用场景
- cookie:
- 判断用户是否登陆过网站,以便下次登录时能够实现自动登录(或者记住密码)。如果我们删除cookie,则每次登录必须从新填写登录的相关信息。
- 保存上次登录的时间等信息。
- 保存上次查看的页面
- 浏览计数
- session:
- Session用于保存每个用户的专用信息,变量的值保存在服务器端,通过SessionID来区分不同的客户。
- 网上商城中的购物车
- 保存用户登录信息
- 将某些数据放入session中,供同一用户的不同页面使用
- 防止用户非法登录
- cookie:
- 缺点
- cookie:
- 大小受限
- 用户可以操作(禁用)cookie,使功能受限
- 安全性较低
- 有些状态不可能保存在客户端。
- 每次访问都要传送cookie给服务器,浪费带宽。
- cookie数据有路径(path)的概念,可以限制cookie只属于某个路径下。
- session:
- Session保存的东西越多,就越占用服务器内存,对于用户在线人数较多的网站,服务器的内存压力会比较大。
- 依赖于cookie(sessionID保存在cookie),如果禁用cookie,则要使用URL重写,不安全
- 创建Session变量有很大的随意性,可随时调用,不需要开发者做精确地处理,所以,过度使用session变量将会导致代码不可读而且不好维护。
- 说白了,这两种状态保持方式都差强人意,于是webStroage应运而生
- cookie:
- WebStorage的目的是克服由cookie所带来的一些限制,当数据需要被严格控制在客户端时,不需要持续的将数据发回服务器
- WebStorage两个主要目标:(1)提供一种在cookie之外存储会话数据的路径。(2)提供一种存储大量可以跨会话存在的数据的机制。
- HTML5的WebStorage提供了两种API:localStorage(本地存储)和sessionStorage(会话存储)。
- 生命周期
- localStorage:localStorage的生命周期是永久的,关闭页面或浏览器之后localStorage中的数据也不会消失。localStorage除非主动删除数据,否则数据永远不会消失。
- sessionStorage的生命周期是在仅在当前会话下有效。sessionStorage引入了一个“浏览器窗口”的概念,sessionStorage是在同源的窗口中始终存在的数据。只要这个浏览器窗口没有关闭,即使刷新页面或者进入同源另一个页面,数据依然存在。但是sessionStorage在关闭了浏览器窗口后就会被销毁。同时独立的打开同一个窗口同一个页面,sessionStorage也是不一样的。
- 存储大小
- localStorage和sessionStorage的存储数据大小一般都是:5MB
- 存储位置
- localStorage和sessionStorage都保存在客户端,不与服务器进行交互通信。
- 存储内容类型
- localStorage和sessionStorage只能存储字符串类型,对于复杂的对象可以使用ECMAScript提供的JSON对象的stringify和parse来处理
- 获取方式
- localStorage:window.localStorage;;sessionStorage:window.sessionStorage;。
- 应用场景
- localStoragese:常用于长期登录(+判断用户是否已登录),适合长期保存在本地的数据(令牌)。sessionStorage:敏感账号一次性登录;
- WebStorage的优点:
- 存储空间更大:cookie为4KB,而WebStorage是5MB;
- 节省网络流量:WebStorage不会传送到服务器,存储在本地的数据可以直接获取,也不会像cookie一样美词请求都会传送到服务器,所以减少了客户端和服务器端的交互,节省了网络流量;
- 对于那种只需要在用户浏览一组页面期间保存而关闭浏览器后就可以丢弃的数据,sessionStorage会非常方便;
- 快速显示:有的数据存储在WebStorage上,再加上浏览器本身的缓存。获取数据时可以从本地获取会比从服务器端获取快得多,所以速度更快;
- 安全性:WebStorage不会随着HTTP header发送到服务器端,所以安全性相对于cookie来说比较高一些,不会担心截获,但是仍然存在伪造问题;
- WebStorage提供了一些方法,数据操作比cookie方便;
- setItem (key, value) —— 保存数据,以键值对的方式储存信息。
使用协同过滤算法对用户提供旅行推荐
- 什么是协同过滤算法
- 协同过滤推荐算法是诞生最早,并且较为著名的推荐算法,主要的功能是预测和推荐。
- 算法通过对用户历史行为数据的挖掘发现用户的偏好,基于不同的偏好对用户进行群组划分并推荐品味相似的商品。
- 协同过滤推荐算法分为两类,分别是基于用户的协同过滤算法(user-based collaboratIve filtering),和基于物品的协同过滤算法(item-based collaborative filtering)。
- 简单的说就是:人以类聚,物以群分。下面我们将分别说明这两类推荐算法的原理和实现方法。
- 基于用户的协同过滤算法
- 假设有甲和乙两名用户,有a、b、c三款产品。
- 如果甲和乙都购买了a和b这两种产品,我们可以假定甲和乙有近似的购物品味。
- 当甲购买了产品c而乙还没有购买c的时候,我们就可以把c也推荐给乙。
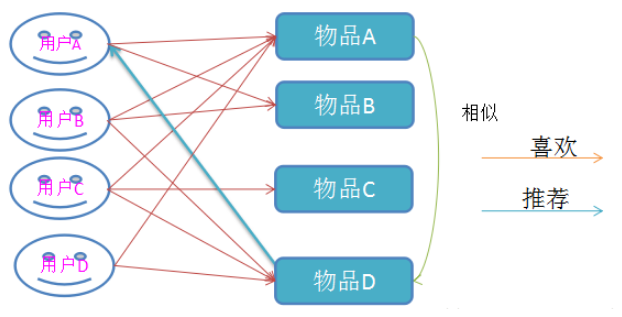
- 举例:
- 直觉分析:“用户A/B”都喜欢物品A和物品B,从而“用户A/B”的口味最为相近
- 因此,为“用户A”推荐物品时可参考“用户B”的偏好,从而推荐D

- 基于物品的协同过滤算法
- 举例:
- 物品组合(A,D)被同时偏好出现的次数最多,因而可以认为A/D两件物品的相似度最高
- 从而,可以为选择了A物品的用户推荐D物品
- 举例:
- 欧几里得度量 是什么?
- 欧几里得度量(euclidean metric)(也称欧氏距离)是一个通常采用的距离定义
- 指在m维空间中两个点之间的真实距离,或者向量的自然长度(即该点到原点的距离)。
- 在二维和三维空间中的欧氏距离就是两点之间的实际距离

-
- n维空间的公式

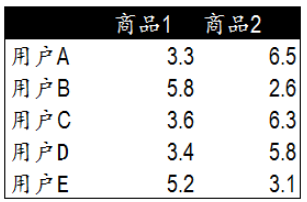
- 借助“欧几里得度量” 寻找偏好相似的用户原理
- 在示例中,5个用户分别对两件商品进行了评分。
- 这里的分值可能表示真实的购买,也可以是用户对商品不同行为的量化指标。
- 例如,浏览商品的次数,向朋友推荐商品,收藏,分享,或评论等等。
- 这些行为都可以表示用户对商品的态度和偏好程度。
-
-
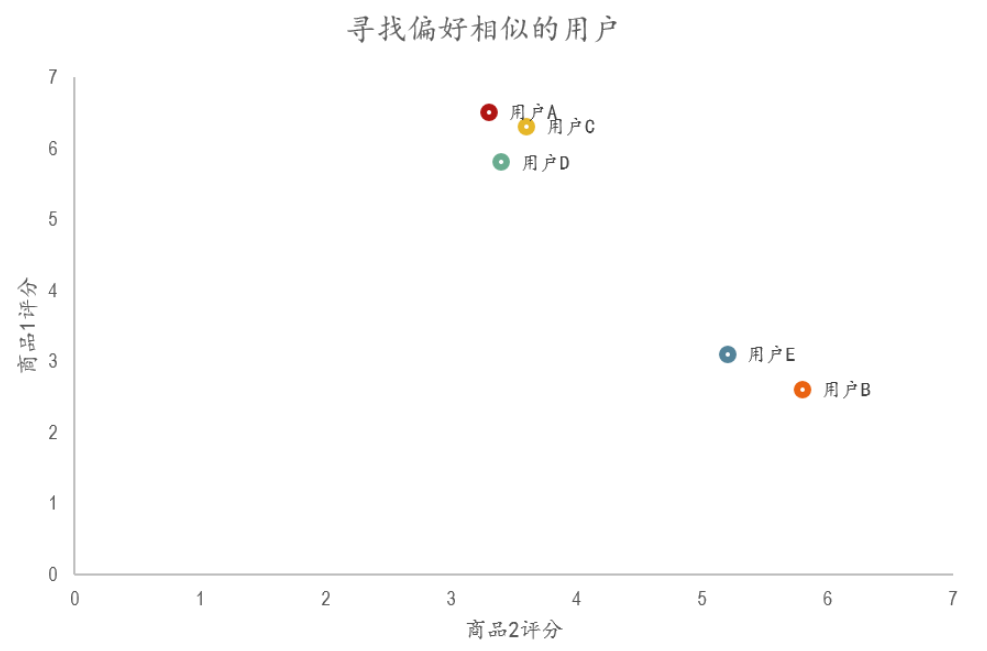
- 在散点图中,Y轴是商品1的评分,X轴是商品2的评分,通过用户的分布情况可以发现,A,C,D三个用户距离较近。
- 用户A(3.3 6.5)和用户C(3.6 6.3),用户D(3.4 5.8)对两件商品的评分较为接近。而用户E和用户B则形成了另一个群体。
- 散点图虽然直观,但无法投入实际的应用,也不能准确的度量用户间的关系。
- 因此我们需要通过数字对用户的关系进行准确的度量,并依据这些关系完成商品的推荐。
-
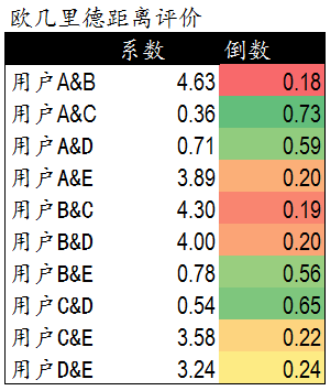
- 欧几里德系数 对上面用户评价分析
- 通过公式我们获得了5个用户相互间的欧几里德系数,也就是用户间的距离。
- 系数越小表示两个用户间的距离越近,偏好也越是接近。
- 不过这里有个问题,太小的数值可能无法准确的表现出不同用户间距离的差异,因此我们对求得的系数取倒数,使用户间的距离约接近,数值越大。
- 在下面的表格中,可以发现,用户A&C用户A&D和用户C&D距离较近。同时用户B&E的距离也较为接近。与我们前面在散点图中看到的情况一致。
- 使用协同过滤算法简单测试
- 测试数据
- 第一步,将数据读取并格式化为字典形式,便于解析
- 第二步:借助"欧几里德"算法计算用户相似度
- 第三步:计算某个用户与其他用户的相似度
- 第四步:根据相似度最高的用户喜好商品排序,把相似度最高用户的喜好推荐给当前用户
- 测试数据
1,华为p30,2.0 1,三星s10,5.0 1,小米9,2.6 2,华为p30,1.0 2,vivo,5.0 2,htc,4.6 3,魅族,2.0 3,iphone,5.0 3,pixel2,2.6
#!/usr/bin/env python3 # -*- coding: utf-8 -*- with open('./phone.txt', 'r', encoding='utf-8') as fp: content = fp.readlines() # 第一步,将数据读取并格式化为字典形式,便于解析 def parse_data(): with open('./phone.txt','r',encoding='utf-8') as fp: content = fp.readlines() # 将用户、评分、和手机写入字典data data = {} for line in content: line = line.strip().split(',') #如果字典中没有某位用户,则使用用户ID来创建这位用户 if not line[0] in data.keys(): data[line[0]] = {line[1]:line[2]} #否则直接添加以该用户ID为key字典中 else: data[line[0]][line[1]] = line[2] return data data = parse_data() ''' { "1":{ "华为p30":"2.0", "三星s10":"5.0", "小米9":"2.6" }, "2":{ "华为p30":"1.0", "vivo":"5.0", "htc":"4.6" }, "3":{ "魅族":"2.0", "iphone":"5.0", "pixel2":"2.6" } } ''' # 第二步:借助"欧几里德"算法计算用户相似度 from math import * def Euclid(user1, user2): # 取出两位用户购买过的手机和评分 user1_data = data[user1] user2_data = data[user2] distance = 0 # 找到两位用户都购买过的手机,并计算欧式距离 for key in user1_data.keys(): if key in user2_data.keys(): # 注意,distance越大表示两者越相似 distance += pow(float(user1_data[key]) - float(user2_data[key]), 2) return 1 / (1 + sqrt(distance)) # 这里返回值越小,相似度越大 # 第三步:计算某个用户与其他用户的相似度 def top_simliar(userID): res = [] for userid in data.keys(): #排除与自己计算相似度 if not userid == userID: simliar = Euclid(userID,userid) res.append((userid,simliar)) # res = # [('2', 0.5), ('3', 1.0)] res.sort(key=lambda val:val[1]) return res # 第四步:根据相似度最高的用户喜好商品排序,把相似度最高用户的喜好推荐给当前用户 def recommend(userid): #相似度最高的用户 top_sim_user = top_simliar(userid)[0][0] # top_sim_user=2 找到相似度最高的用户ID #相似度最高的用户的购买记录 items = data[top_sim_user] # items = {'华为p30': '1.0', 'vivo': '5.0', 'htc': '4.6'} recommendations = [] #筛选出该用户未购买的手机并添加到列表中 for item in items.keys(): if item not in data[userid].keys(): recommendations.append((item,items[item])) recommendations.sort(key=lambda val:val[1],reverse=True)#按照评分排序 return recommendations if __name__ == '__main__': # 找到与用户id为1的用户相似度最高的用户 print(recommend('1')) # [('vivo', '5.0'), ('htc', '4.6')]
第三方用户的登录,第三方支付,模块开发
- https://open.weixin.qq.com/connect/qrconnect?
- appid=wx827225356b689e24&(到官方注册的应用标识,标识开发者)
- redirect_uri=http://127.0.0.1:8080参考博客
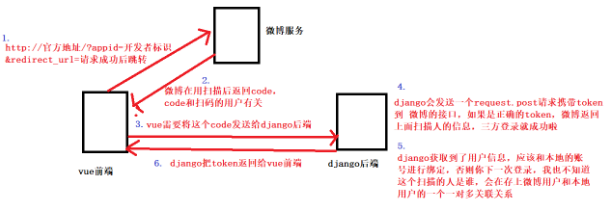
与支付宝接口进行对接,实现用户支付功能
- 支付宝支付
- 相关的资源:appid、支付宝公钥、app公钥、app私钥、django环境
- 流程
- 生成公钥(app公钥、app私钥)
- APP的公钥要上传到沙箱环境,然后我们要下载支付宝公钥
- 代码如何实现
- 第一:生成支付的url
- 在电脑本地生成公钥、私钥(app公钥、app私钥)
- APP的公钥要上传到沙箱环境,然后我们要下载支付宝公钥
- 提供(实例化Alipay对象):appid、支付宝公钥、app私钥
- 提供(拼接付款的url):订单id、金额、标题、return_url(付款成功的回调接口)、notify_url(付款成功后的异步通知)
- 第二:主动查询支付结果
- 提供(实例化Alipay对象):appid、支付宝公钥、app私钥
- 提供一个 订单id就可以查询当前订单支付结果
- 支付宝是如何保证数据安全的(数据传输如何保证安全)

使用Redis缓存数据库查询,减少数据库查询
https://blog.kido.site/2018/12/01/db-and-cache-01/
https://blog.csdn.net/simba_1986/article/details/77823309
场景一:对数据实时性要求不高,更新不频繁
读取数据:先判断当前是否有缓存(通常是根据key来判断),如果存在则从redis缓存读取,如果没有缓存,则从mysql中读取并重新写入缓存。
更新数据:同样首先判断是否有缓存,如果有则更新redis中的缓存,然后再更新mysql数据库,如果没有缓存,则直接更新mysql数据库。
场景二:高并发,更新频繁(如果用户1更新数据时,会先删除缓存,然后更新mysql,在mysql更新还没完成的时候,用户2来查询数据,查询完mysql后会写入缓存,此时写入的缓存是mysql更新前的数据,接着用户1完成了更新mysql的操作,造成了mysql和缓存redis数据不一致的问题)
解决方案:使用队列,根据商品的ID去做hash值,然后对队列个数取模,当有数据更新请求时,先把它丢到队列里去,当更新完后再从队列里去除,如果在更新的过程中,遇到以上场景,先去缓存里看下有没有数据,如果没有,可以先去队列里看是否有相同商品ID正在进行更新,如果有某个商品正在更新同时又有查询这个商品的请求,就把查询的请求放到队列里,然后同步等待缓存更新完成。
这里有一个优化点,如果发现队列里有一个查询请求了,那么就不要放新的查询操作进去了,用一个while(true)循环去查询缓存,循环个200MS左右。
Python 多线程和多进程的适用场景

