MySQL 【常识与进阶】

MySQL 事物
InnoDB事务原理
- 事务(Transaction)是数据库区别于文件系统的重要特性之一,事务会把数据库从一种一致性状态转换为另一种一致性状态。
- 在数据库提交时,可以确保要么所有修改都已保存,要么所有修改都不保存。
事务的(ACID)特征
- 原子性(Atomicity):整个事物的所有操作要么全部提交成功,要么全部失败回滚(不会出现部分执行的情况)。
- 一致性(Consistency):几个并行执行的事务,其执行结果必须与按某一顺序串行执行的结果相一致。
- 隔离性(Isolation):事务的执行不受其他事务的干扰,事务执行的中间结果对其他事务必须是透明的。
- 持久性(Durability): 一个事务一旦被提交了,那么对数据库中的数据的改变就是永久性的,即便是在数据库系统遇到故障的情况下也不会丢失提交事务的操作。
事物隔离级别
- 未提交读:脏读
- 读取到其他事物还未提交的数据
- 例:初始count=100,B事物把count修改为101,但是还没有commit提交到数据库,可能由于回滚并没有真正保存到数据库,但是A事物此时就读取到了101
- 不可重复读:提交读
- 同一个事物两次读取到的数据时其他事物提交前后的,所以读取数据不一样
- 例:A先读取到数据count=100,但是B事物把count修改成了101,A这个事物还没有完成,在此读取时发现同一个事物两次读取的数据不一样
- 可重复读:幻读(mysql默认隔离级别)
- 取数据时加一个版本号,如果其他事物修改了这个数据,我还是会读取我以前读取那个版本的数据,不会管他修改后的数据
- 但并不能阻止另一个事务插入新的数据行,这就会导致该事物中凭空多出数据行,像出现了幻读一样,这便是幻读问题
- 例:A事物读取count=100后加了一个版本号,如果后续B事物将 count修改成了101,A事物不会读取最新版本的101,而是读取自己最初读取的那个版本100
- 可串行读
- 这是事务的最高隔离级别,通过强制事务排序,使之不可能相互冲突,就是在每个读的数据行加上共享锁来实现。
- 在该隔离级别下,可以解决前面出现的脏读、不可重复读和幻读问题,但也会导致大量的超时和锁竞争现象,一般不推荐使用。
MySQL 锁
InnoDB与MyISAM区别
- MyISAM不支持事物回滚,InnoDB是支持事物
- MyISAM和MEMORY存储引擎采用的是表级锁(table-level locking)。
- InnoDB存储引擎既支持行级锁(row-level locking),也支持表级锁,但默认情况下是采用行级锁。
- MyISAM更适合查询多的情况
- InnoDB更适合写入多的
行级锁 & 表级锁 & 页级锁
- 行级锁开销大,加锁慢,锁定粒度最小,发生锁冲突概率最低,并发度最高


### 行锁 ''' client1中执行: select * from shop where id=1 for update; clenet2中执行: select * from shop where id=2 for update; # 可以正常放回数据 select * from shop where id=1 for update; # 阻塞 ''' # 可以看到:id是主键,当在client1上查询id=1的数据时候,在client2上查询id=2的数据没问题 # 但在client2上查询id=1的数据时阻塞,说明此时的锁时行锁。 # 当client1执行commit时,clinet2查询的id=1的命令立即返回数据。
- 表级锁开销小,加锁快,锁定粒度大、发生锁冲突最高,并发度最低
### 表锁 # 可以看到,client1通过非索引的name字段查询到prod11的数据后,在client2查prod**的数据会阻塞,产生表锁。 ''' client1中执行: select * from shop where name="prod11" for update; clenet2中执行: select * from shop where name="prod**" for update; '''
- 页级锁开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般。
锁分类
- 按操作划分:DML锁,DDL锁
- 按锁的粒度划分:表级锁、行级锁、页级锁
- 按锁级别划分:共享锁、排他锁
- 按加锁方式划分:自动锁、显示锁
- 按使用方式划分:乐观锁、悲观锁
乐观锁 & 悲观锁
- 乐观锁:读取商品数量时不加锁,到修改商品数量是回校验,当前商品数量和刚读取的数量是否一致,如果相同加排他锁,然后写入,否则重试。
- 悲观锁:读取商品数量时就加一把排它锁,直到修改商品数量完成释放排它锁,其他线程才能读取商品数量
# 悲观锁的实现,往往依靠数据库提供的锁机制 # MySQL会对查询结果集中每行数据都添加排他锁,其他线程对该记录的更新与删除操作都会阻塞,排他锁包含行锁、表锁。 # 申请前提:没有线程对该结果集中的任何行数据使用排他锁或共享锁,否则申请会阻塞。 # 适用场景:悲观锁适合写入频繁的场景。 # 注: # 首先我们需要set autocommit=0,即不允许自动提交 # 用法:select * from tablename where id = 1 for update;
示例:对商品数量-1操作
- 每次获取商品时,对该商品加排他锁。
- 也就是在用户A获取获取 id=1 的商品信息时对该行记录加锁,期间其他用户阻塞等待访问该记录。
## 悲观锁实现加一操作代码 # 我们可以看到,首先通过begin开启一个事物,在获得shop信息和修改数据的整个过程中都对数据加锁,保证了数据的一致性。 ''' begin; select id,name,stock as old_stock from shop where id=1 for update; update shop set stock=stock-1 where id=1 and stock=old_stock; commit '''
- 每次获取商品时,不对该商品加锁。
- 在更新数据的时候需要比较程序中的库存量与数据库中的库存量是否相等,如果相等则进行更新
- 反之程序重新获取库存量,再次进行比较,直到两个库存量的数值相等才进行数据更新。
## 乐观锁实现加一操作代码 # 我们可以看到,只有当对数量-1操作时才会加锁,只有当程序中值和数据库中的值相等时才正真执行。 ''' //不加锁 select id,name,stock where id=1; //业务处理 begin; update shop set stock=stock-1 where id=1 and stock=stock; commit; '''
乐观锁解决事物问题
- 使用 django.db.transaction 模块解决MySQL 事物管理 问题
- 在事务当前启动celery异步任务, 无法获取未提交的改动.
- 在使用transaction当中, Model.save()都不做commit .
- 因此如果在transaction当中设置异步任务,使用get()查询数据库,将看不到对象在事务当中的改变.
- 这也是实现”可重复读”的事务隔离级别,即同一个事务里面的多次查询都应该保持结果不变.
# with语句用法 from django.db import transaction def viewfunc(request): # 这部分代码不在事务中,会被Django自动提交 ... with transaction.atomic(): # 这部分代码会在事务中执行 ... ''' from django.db import transaction # 创建保存点 save_id = transaction.savepoint() # 回滚到保存点 transaction.savepoint_rollback(save_id) # 提交从保存点到当前状态的所有数据库事务操作 transaction.savepoint_commit(save_id) '''
from django.db import transaction def create(self, validated_data): """ 保存订单 """ # 获取当前下单用户 user = self.context['request'].user # 组织订单编号 20170903153611+user.id # timezone.now() -> datetime order_id = timezone.now().strftime('%Y%m%d%H%M%S') + ('%09d' % user.id) address = validated_data['address'] pay_method = validated_data['pay_method'] # 生成订单 with transaction.atomic(): # 创建一个保存点 save_id = transaction.savepoint() try: # 创建订单信息 order = OrderInfo.objects.create( order_id=order_id, user=user, address=address, total_count=0, total_amount=Decimal(0), freight=Decimal(10), pay_method=pay_method, status=OrderInfo.ORDER_STATUS_ENUM['UNSEND'] if pay_method == OrderInfo.PAY_METHODS_ENUM['CASH'] else OrderInfo.ORDER_STATUS_ENUM['UNPAID'] ) # 获取购物车信息 redis_conn = get_redis_connection("cart") redis_cart = redis_conn.hgetall("cart_%s" % user.id) cart_selected = redis_conn.smembers('cart_selected_%s' % user.id) # 将bytes类型转换为int类型 cart = {} for sku_id in cart_selected: cart[int(sku_id)] = int(redis_cart[sku_id]) # 一次查询出所有商品数据 skus = SKU.objects.filter(id__in=cart.keys()) # 处理订单商品 for sku in skus: sku_count = cart[sku.id] # 判断库存 origin_stock = sku.stock # 原始库存 origin_sales = sku.sales # 原始销量 if sku_count > origin_stock: transaction.savepoint_rollback(save_id) raise serializers.ValidationError('商品库存不足') # 用于演示并发下单 # import time # time.sleep(5) # 减少库存 new_stock = origin_stock - sku_count new_sales = origin_sales + sku_count sku.stock = new_stock sku.sales = new_sales sku.save() # 累计商品的SPU 销量信息 sku.goods.sales += sku_count sku.goods.save() # 累计订单基本信息的数据 order.total_count += sku_count # 累计总金额 order.total_amount += (sku.price * sku_count) # 累计总额 # 保存订单商品 OrderGoods.objects.create( order=order, sku=sku, count=sku_count, price=sku.price, ) # 更新订单的金额数量信息 order.total_amount += order.freight order.save() except ValidationError: raise except Exception as e: logger.error(e) transaction.savepoint_rollback(save_id) raise # 提交事务 transaction.savepoint_commit(save_id) # 更新redis中保存的购物车数据 pl = redis_conn.pipeline() pl.hdel('cart_%s' % user.id, *cart_selected) pl.srem('cart_selected_%s' % user.id, *cart_selected) pl.execute() return order
-
- 注:mysql默认数据库引擎是MyISAM,MyISAM默认不支持事物,所以要先使用乐观锁需要先修改数据库引擎
mysql> show variables like '%storage_engine%'; # 查看数据默认引擎 mysql> select table_name,`engine` from information_schema.tables where table_schema = 'weibo'; # 查看"weibo"这个数据库所有表默认引擎 mysql> select CONCAT('alter table ',table_name,' engine=InnoDB;') FROM information_schema.tables WHERE table_schema="weibo" AND ENGINE="MyISAM"; # 生成修改表引擎的语法 alter table auth_group engine=InnoDB; alter table auth_group_permissions engine=InnoDB; alter table auth_permission engine=InnoDB; alter table authtoken_token engine=InnoDB; alter table django_admin_log engine=InnoDB; alter table django_content_type engine=InnoDB; alter table django_migrations engine=InnoDB; alter table django_session engine=InnoDB; alter table users_socialuser engine=InnoDB; alter table users_user engine=InnoDB; alter table users_user_groups engine=InnoDB; alter table users_user_user_permissions engine=InnoDB;
共享锁 & 排它锁
- 共享锁(读锁):所有线程都可以读这个数据,但不能写
# SELECT … LOCK IN SHARE MODE;
- 排它锁(写锁):一旦加了排它锁,其他线程连读数据的权利都没有
# SELECT … FOR UPDATE
MySQL 数据库引擎
数据库引擎
- 数据库引擎是用于存储、处理和保护数据的核心服务。利用数据库引擎可控制访问权限并快速处理事务,从而满足企业内大多数需要处理大量数据的应用程序的要求。 使用数据库引擎创建用于联机事务处理或联机分析处理数据的关系数据库。这包括创建用于存储数据的表和用于查看、管理和保护数据安全的数据库对象(如索引、视图和存储过程)。
数据库引擎任务
- 在数据库引擎文档中,各主题的顺序遵循用于实现使用数据库引擎进行数据存储的系统的任务的主要顺序。
- 设计并创建数据库以保存系统所需的关系或XML文档
- 实现系统以访问和更改数据库中存储的数据。包括实现网站或使用数据的应用程序,还包括生成使用SQL Server工具和实用工具以使用数据的过程。
- 为单位或客户部署实现的系统
- 提供日常管理支持以优化数据库的性能
MySQL数据库引擎类别
- 你能用的数据库引擎取决于mysql在安装的时候是如何被编译的。要添加一个新的引擎,就必须重新编译MYSQL。在缺省情况下,MYSQL支持三个引擎:ISAM、MYISAM和HEAP。另外两种类型INNODB和BERKLEY(BDB),也常常可以使用。
- ISAM
-
- ISAM是一个定义明确且历经时间考验的数据表格管理方法,它在设计之时就考虑到数据库被查询的次数要远大于更新的次数。因此,ISAM执行读取操作的速度很快,而且不占用大量的内存和存储资源。ISAM的两个主要不足之处在于,它不支持事务处理,也不能够容错:如果你的硬盘崩溃了,那么数据文件就无法恢复了。如果你正在把ISAM用在关键任务应用程序里,那就必须经常备份你所有的实时数据,通过其复制特性,MYSQL能够支持这样的备份应用程序。
- MYISAM
-
- MYISAM是MYSQL的ISAM扩展格式和缺省的数据库引擎。除了提供ISAM里所没有的索引和字段管理的功能,MYISAM还使用一种表格锁定的机制,来优化多个并发的读写操作。其代价是你需要经常运行OPTIMIZE TABLE命令,来恢复被更新机制所浪费的空间。MYISAM还有一些有用的扩展,例如用来修复数据库文件的MYISAMCHK工具和用来恢复浪费空间的MYISAMPACK工具。
- MYISAM强调了快速读取操作,这可能就是为什么MYSQL受到了WEB开发如此青睐的主要原因:在WEB开发中你所进行的大量数据操作都是读取操作。所以,大多数虚拟主机提供商和INTERNET平台提供商只允许使用MYISAM格式。
- HEAP
-
- HEAP允许只驻留在内存里的临时表格。驻留在内存里让HEAP要比ISAM和MYISAM都快,但是它所管理的数据是不稳定的,而且如果在关机之前没有进行保存,那么所有的数据都会丢失。在数据行被删除的时候,HEAP也不会浪费大量的空间。HEAP表格在你需要使用SELECT表达式来选择和操控数据的时候非常有用。要记住,在用完表格之后就删除表格。
- INNODB和BERKLEYDB
-
- INNODB和BERKLEYDB(BDB)数据库引擎都是造就MYSQL灵活性的技术的直接产品,这项技术就是MYSQL++ API。在使用MYSQL的时候,你所面对的每一个挑战几乎都源于ISAM和MYISAM数据库引擎不支持事务处理也不支持外来键。尽管要比ISAM和MYISAM引擎慢很多,但是INNODB和BDB包括了对事务处理和外来键的支持,这两点都是前两个引擎所没有的。如前所述,如果你的设计需要这些特性中的一者或者两者,那你就要被迫使用后两个引擎中的一个了。
mysql数据引擎更换方式
- 查看当前数据库支持的引擎和默认的数据库引擎:
# show engines;
我的查询结果如下:

- 更改数据库引擎
- 更改方式1:修改配置文件my.ini
- 将my-small.ini另存为my.ini,在[mysqld]后面添加default-storage-engine=InnoDB,重启服务,数据库默认的引擎修改为InnoDB
- 更改方式2:在建表的时候指
create table mytbl( id int primary key, name varchar(50) )type=MyISAM;
- 更改方式-建表后更改
# alter table mytbl2 type = InnoDB;
- 查看修改结果
# 方式1: show table status from mytest; # 方式2: show create table table_name
MyIASM 和 Innodb引擎
- Innodb引擎
- Innodb引擎提供了对数据库ACID事务的支持,并且实现了SQL标准的四种隔离级别,关于数据库事务与其隔离级别的内容请见数据库事务与其隔离级别这篇文章。该引擎还提供了行级锁和外键约束,它的设计目标是处理大容量数据库系统,它本身其实就是基于MySQL后台的完整数据库系统,MySQL运行时Innodb会在内存中建立缓冲池,用于缓冲数据和索引。但是该引擎不支持FULLTEXT类型的索引,而且它没有保存表的行数,当SELECT COUNT(*) FROM TABLE时需要扫描全表。当需要使用数据库事务时,该引擎当然是首选。由于锁的粒度更小,写操作不会锁定全表,所以在并发较高时,使用Innodb引擎会提升效率。但是使用行级锁也不是绝对的,如果在执行一个SQL语句时MySQL不能确定要扫描的范围,InnoDB表同样会锁全表。
- 名词 ACID 解析:
-
- A 事务的原子性(Atomicity):指一个事务要么全部执行,要么不执行.也就是说一个事务不可能只执行了一半就停止了.比如你从取款机取钱,这个事务可以分成两个步骤:1划卡,2出钱.不可能划了卡,而钱却没出来.这两步必须同时完成.要么就不完成.
- C 事务的一致性(Consistency):指事务的运行并不改变数据库中数据的一致性.例如,完整性约束了a+b=10,一个事务改变了a,那么b也应该随之改变.
- I 独立性(Isolation):事务的独立性也有称作隔离性,是指两个以上的事务不会出现交错执行的状态.因为这样可能会导致数据不一致.
- D 持久性(Durability):事务的持久性是指事务执行成功以后,该事务所对数据库所作的更改便是持久的保存在数据库之中,不会无缘无故的回滚.
MyIASM引擎
- MyIASM是MySQL默认的引擎,但是它没有提供对数据库事务的支持,也不支持行级锁和外键,因此当INSERT(插入)或UPDATE(更新)数据时即写操作需要锁定整个表,效率便会低一些。不过和Innodb不同,MyIASM中存储了表的行数,于是SELECT COUNT(*) FROM TABLE时只需要直接读取已经保存好的值而不需要进行全表扫描。如果表的读操作远远多于写操作且不需要数据库事务的支持,那么MyIASM也是很好的选择。
两种引擎的选择
- 大尺寸的数据集趋向于选择InnoDB引擎,因为它支持事务处理和故障恢复。数据库的大小决定了故障恢复的时间长短,InnoDB可以利用事务日志进行数据恢复,这会比较快。主键查询在InnoDB引擎下也会相当快,不过需要注意的是如果主键太长也会导致性能问题,关于这个问题我会在下文中讲到。大批的INSERT语句(在每个INSERT语句中写入多行,批量插入)在MyISAM下会快一些,但是UPDATE语句在InnoDB下则会更快一些,尤其是在并发量大的时候。
Index(索引)
- 索引(Index)是帮助MySQL高效获取数据的数据结构。MyIASM和Innodb都使用了树这种数据结构做为索引。下面我接着讲这两种引擎使用的索引结构,讲到这里,首先应该谈一下B-Tree和B+Tree。
MyIASM引擎的索引结构
- MyISAM引擎的索引结构为B+Tree,其中B+Tree的数据域存储的内容为实际数据的地址,也就是说它的索引和实际的数据是分开的,只不过是用索引指向了实际的数据,这种索引就是所谓的非聚集索引。如下图所示:

- 这里设表一共有三列,假设我们以Col1为主键,则上图是一个MyISAM表的主索引(Primary key)示意。可以看出MyISAM的索引文件仅仅保存数据记录的地址。在MyISAM中,主索引和辅助索引(Secondary key)在结构上没有任何区别,只是主索引要求key是唯一的,而辅助索引的key可以重复。如果我们在Col2上建立一个辅助索引,则此索引的结构如下图所示:

- 同样也是一颗B+Tree,data域保存数据记录的地址。因此,MyISAM中索引检索的算法为首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其data域的值,然后以data域的值为地址,读取相应数据记录。
Innodb引擎的索引结构
- 与MyISAM引擎的索引结构同样也是B+Tree,但是Innodb的索引文件本身就是数据文件,即B+Tree的数据域存储的就是实际的数据,这种索引就是聚集索引。这个索引的key就是数据表的主键,因此InnoDB表数据文件本身就是主索引。
- 并且和MyISAM不同,InnoDB的辅助索引数据域存储的也是相应记录主键的值而不是地址,所以当以辅助索引查找时,会先根据辅助索引找到主键,再根据主键索引找到实际的数据。所以Innodb不建议使用过长的主键,否则会使辅助索引变得过大。建议使用自增的字段作为主键,这样B+Tree的每一个结点都会被顺序的填满,而不会频繁的分裂调整,会有效的提升插入数据的效率。
两者区别:
- 第一个重大区别是InnoDB的数据文件本身就是索引文件。从上文知道,MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。而在InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。
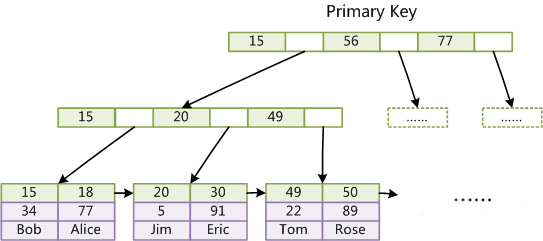
- 上图是InnoDB主索引(同时也是数据文件)的示意图,可以看到叶节点包含了完整的数据记录。这种索引叫做聚集索引。因为InnoDB的数据文件本身要按主键聚集,所以InnoDB要求表必须有主键(MyISAM可以没有),如果没有显式指定,则MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整形。
- 第二个与MyISAM索引的不同是InnoDB的辅助索引data域存储相应记录主键的值而不是地址。换句话说,InnoDB的所有辅助索引都引用主键作为data域。例如,下图为定义在Col3上的一个辅助索引:
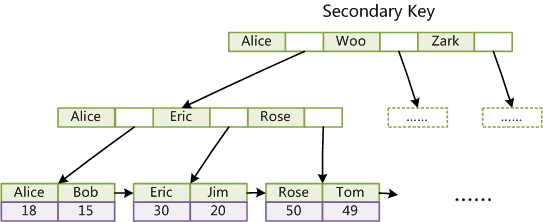
- 这里以英文字符的ASCII码作为比较准则。聚集索引这种实现方式使得按主键的搜索十分高效,但是辅助索引搜索需要检索两遍索引:首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录。
MySQL 索引集合
什么是索引?为什么要建立索引?
- 索引用于快速找出在某个列中有一特定值的行,不使用索引,MySQL必须从第一条记录开始读完整个表,直到找出相关的行,表越大,查询数据所花费的时间就越多,如果表中查询的列有一个索引,MySQL能够快速到达一个位置去搜索数据文件,而不必查看所有数据,那么将会节省很大一部分时间。
- 例如:有一张person表,其中有2W条记录,记录着2W个人的信息。有一个Phone的字段记录每个人的电话号码,现在想要查询出电话号码为xxxx的人的信息。如果没有索引,那么将从表中第一条记录一条条往下遍历,直到找到该条信息为止。如果有了索引,那么会将该Phone字段,通过一定的方法进行存储,好让查询该字段上的信息时,能够快速找到对应的数据,而不必在遍历2W条数据了。其中MySQL中的索引的存储类型有两种:BTREE、HASH。 也就是用树或者Hash值来存储该字段,要知道其中详细是如何查找的,就需要会算法的知识了。我们现在只需要知道索引的作用,功能是什么就行。
MySQL中索引的优点和缺点和使用原则
- 优点
- 所有的MySql列类型(字段类型)都可以被索引,也就是可以给任意字段设置索引
- 大大加快数据的查询速度
- 缺点
- 创建索引和维护索引要耗费时间,并且随着数据量的增加所耗费的时间也会增加
- 索引也需要占空间,我们知道数据表中的数据也会有最大上线设置的,如果我们有大量的索引,索引文件可能会比数据文件更快达到上线值
- 当对表中的数据进行增加、删除、修改时,索引也需要动态的维护,降低了数据的维护速度。
- 使用原则
- 通过上面说的优点和缺点,我们应该可以知道,并不是每个字段度设置索引就好,也不是索引越多越好,而是需要自己合理的使用。
- 对经常更新的表就避免对其进行过多的索引,对经常用于查询的字段应该创建索引,
- 数据量小的表最好不要使用索引,因为由于数据较少,可能查询全部数据花费的时间比遍历索引的时间还要短,索引就可能不会产生优化效果。
- 在一同值少的列上(字段上)不要建立索引,比如在学生表的"性别"字段上只有男,女两个不同值。相反的,在一个字段上不同值较多可以建立索引。
- 上面说的只是很片面的一些东西,索引肯定还有很多别的优点或者缺点,还有使用原则,先基本上理解索引,然后等以后真正用到了,就会慢慢知道别的作用。
- 注意:学习这张,很重要的一点就是必须先得知道索引是什么,索引是干嘛的,有什么作用,为什么要索引等等,如果不知道,就重复往上面看看写的文字,好好理解一下。一个表中很够创建多个索引,这些索引度会被存放到一个索引文件中(专门存放索引的地方)
索引的分类
- 注意:索引是在存储引擎中实现的,也就是说不同的存储引擎,会使用不同的索引
- MyISAM和InnoDB存储引擎:只支持BTREE索引, 也就是说默认使用BTREE,不能够更换MEMORY/HEAP存储引擎:支持HASH和BTREE索引
- 索引我们分为四类来讲 单列索引(普通索引,唯一索引,主键索引)、组合索引、全文索引、空间索引
- 单列索引:一个索引只包含单个列,但一个表中可以有多个单列索引。 这里不要搞混淆了。
- 普通索引:MySQL中基本索引类型,没有什么限制,允许在定义索引的列中插入重复值和空值,纯粹为了查询数据更快一点。
- 唯一索引:索引列中的值必须是唯一的,但是允许为空值,
- 主键索引:是一种特殊的唯一索引,不允许有空值。
- 组合索引:在表中的多个字段组合上创建的索引,只有在查询条件中使用了这些字段的左边字段时,索引才会被使用,使用组合索引时遵循最左前缀集合。这个如果还不明白,等后面举例讲解时在细说
- 全文索引:全文索引,只有在MyISAM引擎上才能使用,只能在CHAR,VARCHAR,TEXT类型字段上使用全文索引,介绍了要求,说说什么是全文索引,就是在一堆文字中,通过其中的某个关键字等,就能找到该字段所属的记录行,比如有"你是个靓仔,靓女 ..." 通过靓仔,可能就可以找到该条记录。这里说的是可能,因为全文索引的使用涉及了很多细节,我们只需要知道这个大概意思,如果感兴趣进一步深入使用它,那么看下面测试该索引时,会给出一个博文,供大家参考。
- 空间索引:空间索引是对空间数据类型的字段建立的索引,MySQL中的空间数据类型有四种,GEOMETRY、POINT、LINESTRING、POLYGON。在创建空间索引时,使用SPATIAL关键字。要求,引擎为MyISAM,创建空间索引的列,必须将其声明为NOT NULL。具体细节看下面
索引操作(创建和删除)
- 创建索引
- 创建表的时候创建索引

-
- 创建普通索引

- 上面两种方式创建都可以,通过这个例子可以对比一下格式,就差不多明白格式是什么意思了。

- 通过打印结果,我们在创建索引时没写索引名的话,会自动帮我们用字段名当作索引名。
# 测试:看是否使用了索引进行查询。 EXPLAIN SELECT * FROM book WHERE year_publication = 1990\G;
- 解释:虽然表中没数据,但是有EXPLAIN关键字,用来查看索引是否正在被使用,并且输出其使用的索引的信息。

- id:
- SELECT识别符。这是SELECT的查询序列号,也就是一条语句中,该select是第几次出现。在次语句中,select就只有一个,所以是1.
- select_type:
- 所使用的SELECT查询类型,SIMPLE表示为简单的SELECT,不实用UNION或子查询,就为简单的SELECT。也就是说在该SELECT查询时会使用索引。其他取值,PRIMARY:最外面的SELECT.在拥有子查询时,就会出现两个以上的SELECT。UNION:union(两张表连接)中的第二个或后面的select语句 SUBQUERY:在子查询中,第二SELECT。
- table:
- 数据表的名字。他们按被读取的先后顺序排列,这里因为只查询一张表,所以只显示book
- type:
- 指定本数据表和其他数据表之间的关联关系,该表中所有符合检索值的记录都会被取出来和从上一个表中取出来的记录作联合。ref用于连接程序使用键的最左前缀或者是该键不是 primary key 或 unique索引(换句话说,就是连接程序无法根据键值只取得一条记录)的情况。当根据键值只查询到少数几条匹配的记录时,这就是一个不错的连接类型。(注意,个人这里不是很理解,百度了很多资料,全是大白话等以后用到了这类信息时,在回过头来补充,这里不懂对后面的影响不大。)可能的取值有 system、const、eq_ref、index和All
- possible_keys:
- MySQL在搜索数据记录时可以选用的各个索引,该表中就只有一个索引,year_publication
- key:
- 实际选用的索引
- key_len:
- 显示了mysql使用索引的长度(也就是使用的索引个数),当 key 字段的值为 null时,索引的长度就是 null。注意key_len的值可以告诉你在联合索引中mysql会真正使用了哪些索引。这里就使用了1个索引,所以为1,
- ref:
- 给出关联关系中另一个数据表中数据列的名字。常量(const),这里使用的是1990,就是常量。
- rows:
- MySQL在执行这个查询时预计会从这个数据表里读出的数据行的个数。
- extra:
- 提供了与关联操作有关的信息,没有则什么都不写。上面的一大堆东西能看懂多少看多少,我们最主要的是看possible_keys和key 这两个属性,上面显示了key为year_publication。说明使用了索引。
创建唯一索引
CREATE TABLE t1 ( id INT NOT NULL, name CHAR(30) NOT NULL, UNIQUE INDEX UniqIdx(id) );
- 解释:对id字段使用了索引,并且索引名字为UniqIdx。
- SHOW CREATE TABLE t1\G;

- 要查看其中查询时使用的索引,必须先往表中插入数据,然后在查询数据,不然查找一个没有的id值,是不会使用索引的。
- INSERT INTO t1 VALUES(1,'xxx');
- EXPLAIN SELECT * FROM t1 WHERE id = 1\G;

-
- 可以看到,通过id查询时,会使用唯一索引。并且还实验了查询一个没有的id值,则不会使用索引,我觉得原因是所有的id应该会存储到一个const tables中,到其中并没有该id值,那么就没有查找的必要了。
创建主键索引
CREATE TABLE t2 ( id INT NOT NULL, name CHAR(10), PRIMARY KEY(id) ); INSERT INTO t2 VALUES(1,'QQQ'); EXPLAIN SELECT * FROM t2 WHERE id = 1\G;

- 通过这个主键索引,我们就应该反应过来,其实我们以前声明的主键约束,就是一个主键索引,只是之前我们没学过,不知道而已。
创建单列索引
- 这个其实就不用在说了,前面几个就是单列索引。
创建组合索引
- 组合索引就是在多个字段上创建一个索引,创建一个表t3,在表中的id、name和age字段上建立组合索引
CREATE TABLE t3 ( id INT NOT NULL, name CHAR(30) NOT NULL, age INT NOT NULL, info VARCHAR(255), INDEX MultiIdx(id,name,age) ); SHOW CREATE t3\G;

解释最左前缀
- 组合索引就是遵从了最左前缀,利用索引中最左边的列集来匹配行,这样的列集称为最左前缀,不明白没关系,举几个例子就明白了,例如,这里由id、name和age3个字段构成的索引,索引行中就按id/name/age的顺序存放,索引可以索引下面字段组合(id,name,age)、(id,name)或者(id)。如果要查询的字段不构成索引最左面的前缀,那么就不会是用索引,比如,age或者(name,age)组合就不会使用索引查询
# 在t3表中,查询id和name字段 EXPLAIN SELECT * FROM t3 WHERE id = 1 AND name = 'joe'\G;

# 在t3表中,查询(age,name)字段,这样就不会使用索引查询。来看看结果 EXPLAIN SELECT * FROM t3 WHERE age = 3 AND name = 'bob'\G;

- 全文索引可以用于全文搜索,但只有MyISAM存储引擎支持FULLTEXT索引,并且只为CHAR、VARCHAR和TEXT列服务。索引总是对整个列进行,不支持前缀索引,
CREATE TABLE t4 ( id INT NOT NULL, name CHAR(30) NOT NULL, age INT NOT NULL, info VARCHAR(255), FULLTEXT INDEX FullTxtIdx(info) ) ENGINE=MyISAM; SHOW CREATE TABLE t4\G;

# 使用一下什么叫做全文搜索。就是在很多文字中,通过关键字就能够找到该记录。 INSERT INTO t4 VALUES(8,'AAA',3,'text is so good,hei,my name is bob'),(9,'BBB',4,'my name isgorlr'); SELECT * FROM t4 WHERE MATCH(info) AGAINST('gorlr');

# EXPLAIN SELECT * FROM t4 WHERE MATCH(info) AGAINST('gorlr');

- 注意:在使用全文搜索时,需要借助MATCH函数,并且其全文搜索的限制比较多,比如只能通过MyISAM引擎,比如只能在CHAR,VARCHAR,TEXT上设置全文索引。比如搜索的关键字默认至少要4个字符,比如搜索的关键字太短就会被忽略掉。等等,如果你们在实验的时候可能会实验不出来。感兴趣的可以往下看
- MySQL支持全文索引和搜索功能。MySQL中的全文索引类型FULLTEXT的索引。 FULLTEXT 索引仅可用于 MyISAM 表;他们可以从CHAR、VARCHAR或TEXT列中作为CREATE TABLE语句的一部分被创建,或是随后使用ALTER TABLE 或 CREATE INDEX被添加。
- 一些词在全文搜索中会被忽略:
- 任何过于短的词都会被忽略。 全文搜索所能找到的词的默认最小长度为 4个字符。
- 停止字中的词会被忽略。禁用词就是一个像“the” 或“some” 这样过于平常而被认为是不具语义的词。存在一个内置的停止字, 但它可以通过用户自定义列表被改写。
- 词库和询问中每一个正确的单词根据其在词库和询问中的重要性而被衡量。 通过这种方式,一个出现在许多文件中的单词具有较低的重要性(而且甚至很多单词的重要性为零),原因是在这个特别词库中其语义价值较低。反之,假如这个单词比较少见,那么它会得到一个较高的重要性。然后单词的重要性被组合,从而用来计算该行的相关性。
- 这项技术最适合同大型词库一起使用 (事实上, 此时它经过仔细的调整 )。对于很小的表,单词分布并不能充分反映它们的语义价值, 而这个模式有时可能会产生奇特的结果。例如, 虽然单词 “MySQL” 出现在文章表中的每一行,但对这个词的搜索可能得不到任何结果:
mysql> SELECT * FROM articles -> WHERE MATCH (title,body) AGAINST ('MySQL');
- 这个搜索的结果为空,原因是单词 “MySQL” 出现在至少全文的50%的行中。 因此, 它被列入停止字。对于大型数据集,使用这个操作最合适不过了----一个自然语言问询不会从一个1GB 的表每隔一行返回一次。对于小型数据集,它的用处可能比较小。
- 一个符合表中所有行的内容的一半的单词查找相关文档的可能性较小。事实上, 它更容易找到很多不相关的内容。我们都知道,当我们在因特网上试图使用搜索引擎寻找资料的时候,这种情况发生的频率颇高。可以推论,包含该单词的行因其所在特别数据集 而被赋予较低的语义价值。 一个给定的词有可能在一个数据集中拥有超过其50%的域值,而在另一个数据集却不然。
- 当你第一次尝试使用全文搜索以了解其工作过程时,这个50% 的域值提供重要的蕴涵操作:若你创建了一个表,并且只将文章的1、2行插入其中, 而文中的每个单词在所有行中出现的机率至少为 50% 。那么结果是你什么也不会搜索到。一定要插入至少3行,并且多多益善。需要绕过该50% 限制的用户可使用布尔搜索代码。
创建空间索引
- 空间索引也必须使用MyISAM引擎, 并且空间类型的字段必须为非空。 这个空间索引具体能干嘛我也不知道,可能跟游戏开发有关,可能跟别的东西有关,等遇到了自然就知道了,现在只要求能够创建出来。
CREATE TABLE t5 ( g GEOMETRY NOT NULL, SPATIAL INDEX spatIdx(g) ) ENGINE = MyISAM; SHOW CREATE TABLE t5\G;

# 格式:ALTER TABLE 表名 ADD[UNIQUE|FULLTEXT|SPATIAL] [INDEX|KEY] [索引名] (索引字段名)[ASC|DESC] # 有了上面的基础,这里就不用过多陈述了。 # 命令一:SHOW INDEX FROM 表名\G # 查看一张表中所创建的索引 SHOW INDEX FROM book\G;

- 挑重点讲,我们需要了解的就5个,用红颜色标记了的,如果想深入了解,可以去查查该方面的资料,我个人觉得,这些等以后实际工作中遇到了在做详细的了解把。
- Table:创建索引的表
- Non_unique:表示索引非唯一,1代表 非唯一索引, 0代表 唯一索引,意思就是该索引是不是唯一索引
- Key_name:索引名称
- Seq_in_index: 表示该字段在索引中的位置,单列索引的话该值为1,组合索引为每个字段在索引定义中的顺序(这个只需要知道单列索引该值就为1,组合索引为别的)
- Column_name:表示定义索引的列字段
- Sub_part:表示索引的长度
- Null:表示该字段是否能为空值
- Index_type:表示索引类型
为表添加索引
# 就拿上面的book表来说。本来已经有了一个year_publication,现在我们为该表在加一个普通索引 ALTER TABLE book ADD INDEX BkNameIdx(bookname(30));

- 看输出结果,就能知道,添加索引成功了。
- 这里只是拿普通索引做个例子,添加其他索引也是一样的。依葫芦画瓢而已。这里就不一一做讲解了。
使用CREATE INDEX创建索引
# 格式:CREATE [UNIQUE|FULLTEXT|SPATIAL] [INDEX|KEY] 索引名称 ON 表名(创建索引的字段名[length])[ASC|DESC] # 解释:其实就是换汤不换药,格式改变了一下而已,做的事情跟上面完全一样,做一个例子。 # 在为book表增加一个普通索引,字段为authors。 CREATE INDEX BkBookNameIdx ON book(bookname);

SHOW INDEX FROM book\G; # 查看book表中的索引

注意:第一条截图没截到,因为图太大了,这里只要看到有我们新加进去的索引就证明成功了。。其他索引也是一样的创建。
删除索引
- 前面讲了对一张表中索引的添加,查询的方法。
- 添加的两种方式
- 1在创建表的同时如何创建索引,
- 2在创建了表之后如何给表添加索引的两种方式,
- 查询的方式
SHOW INDEX FROM表名\G; # \G只是让输出的格式更好看
- 现在来说说如何给表删除索引的两种操作。
# 格式一:ALTER TABLE 表名 DROP INDEX 索引名。 # 很简单的语句,现在通过一个例子来看看,还是对book表进行操作,删除我们刚才为其添加的索引。 # 删除book表中的名称为BkBookNameIdx的索引。 ALTER TABLE book DROPINDEX BkBookNameIdx;

SHOW INDEX FROM book\G; # 在查看book表中的索引,就会发现BkBookNameIdx这个索引已经不在了

# 格式二:DROP INDEX 索引名 ON 表名; # 删除book表中名为BkNameIdx的索引 DROP INDEX BkNameIdx ON book; SHOW INDEX FROM book\G;

- MySQL的索引到这里差不多就讲完了,总结一下我们到目前为止应该知道哪些东西
- 索引是干嘛的?为什么要有索引?
- 这个很重要,需要自己理解一下,不懂就看顶部的讲解
- 索引的分类
- 索引的操作
- 给表中创建索引,添加索引,删除索引,删除索引
MySQL 主从复制的原理
- mysql是现在普遍使用的数据库,但是如果宕机了必然会造成数据丢失。为了保证mysql数据库的可靠性。就要会一些提高可靠性的技术。做数据的热备,主库宕机后能够及时替换主库,保证业务可用性。
- 架构的扩展。业务量越来越大,I/O访问频率过高,单机无法满足,此时做多库的存储,降低磁盘I/O访问的频率,提高单个机器的I/O性能。
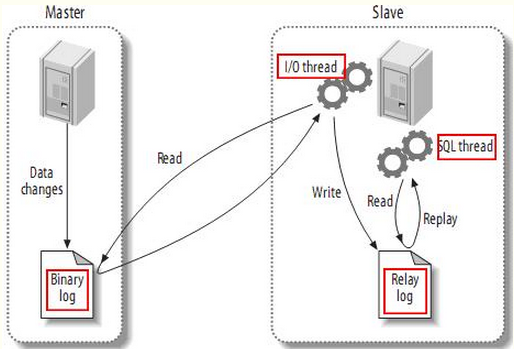
- 主从复制原理如下
- slave(从服务器)
- master(主服务器)
-
- master服务器将数据的改变都记录到二进制binlog日志中,只要master上的数据发生改变,则将其改变写入二进制日志;
- salve服务器会在一定时间间隔内对master二进制日志进行探测其是否发生改变,如果发生改变,则开始一个I/O Thread请求master二进制事件
- 同时主节点为每个I/O线程启动一个dump线程,用于向其发送二进制事件,并保存至从节点本地的中继日志中
- 从节点将启动SQL线程从中继日志中读取二进制日志,在本地重放,使得其数据和主节点的保持一致
- 最后I/O Thread和SQL Thread将进入睡眠状态,等待下一次被唤醒。
- 需要理解:
-
-
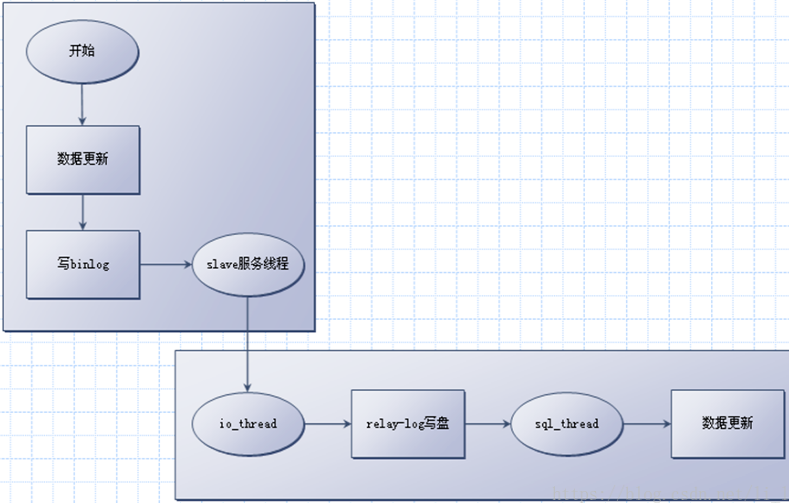
- 从库会生成两个线程,一个I/O线程,一个SQL线程;
- I/O线程会去请求主库的binlog,并将得到的binlog写到本地的relay-log(中继日志)文件中;
- 主库会生成一个log dump线程,用来给从库I/O线程传binlog;
- SQL线程,会读取relay log文件中的日志,并解析成sql语句逐一执行;
-
- mysql主从是异步复制过程
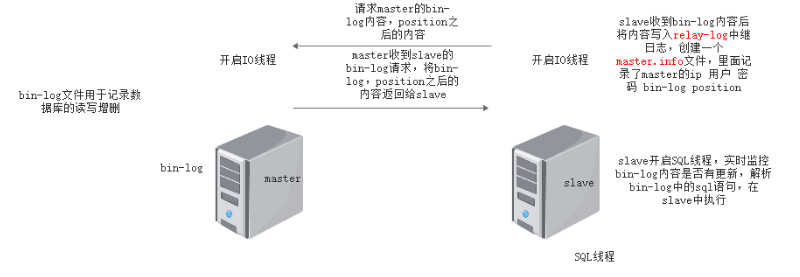
- master开启bin-log功能,日志文件用于记录数据库的读写增删
- 需要开启3个线程,master IO线程,slave开启 IO线程 SQL线程,
- Slave 通过IO线程连接master,并且请求某个bin-log,position之后的内容。
- MASTER服务器收到slave IO线程发来的日志请求信息,io线程去将bin-log内容,position返回给slave IO线程。
- slave服务器收到bin-log日志内容,将bin-log日志内容写入relay-log中继日志,创建一个master.info的文件,该文件记录了master ip 用户名 密码 master bin-log名称,bin-log position。
- slave端开启SQL线程,实时监控relay-log日志内容是否有更新,解析文件中的SQL语句,在slave数据库中去执行。
优点主要有
- 可以作为备用数据库进行操作,当主数据库出现故障之后,从数据库可以替代主数据库继续工作,不影响业务流程
- 读写分离,将读和写应用在不同的数据库与服务器上。一般读写的数据库环境配置为,一个写入的数据库,一个或多个读的数据库,各个数据库分别位于不同的服务器上,充分利用服务器性能和数据库性能;当然,其中会涉及到如何保证读写数据库的数据一致,这个就可以利用主从复制技术来完成。
- 吞吐量较大,业务的查询较多,并发与负载较大。
Mysql复制流程图
- master将操作语句记录到binlog日志中
- salve服务器会在一定时间间隔内对master二进制日志进行探测其是否发生改变,如果发生改变
- salave开启两个线程:IO线程和SQL线程
- IO线程:负责读取master的binlog内容到中继日志relay log里;
- SQL线程:负责从relay log日志里读出binlog内容,并更新到slave的数据库里(保证数据一致)
1、造成mysql同步延迟常见原因
- 网络:如主机或者从机的带宽打满、主从之间网络延迟很大,导致主上的binlog没有全量传输到从机,造成延迟。
- 机器性能:从机使用了烂机器?比如主机使用SSD而从机还是使用的SATA。
- 从机高负载:有很多业务会在从机上做统计,把从机服务器搞成高负载,从而造成从机延迟很大的情况
- 大事务:比如在RBR模式下,执行带有大量的delete操作,这种通过查看processlist相关信息以及使用mysqlbinlog查看binlog中的SQL就能快速进行确认
- 锁: 锁冲突问题也可能导致从机的SQL线程执行慢,比如从机上有一些select .... for update的SQL,或者使用了MyISAM引擎等。
2、硬件方面(优化)
- 1.采用好服务器,比如4u比2u性能明显好,2u比1u性能明显好。
- 2.存储用ssd或者盘阵或者san,提升随机写的性能。
- 3.主从间保证处在同一个交换机下面,并且是万兆环境。
- 总结:硬件强劲,延迟自然会变小。一句话,缩小延迟的解决方案就是花钱和花时间。
3、mysql主从同步加速
- sync_binlog在slave端设置为0
- 当事务提交后,Mysql仅仅是将binlog_cache中的数据写入Binlog文件,但不执行fsync之类的磁盘 同步指令通知文件系统将缓存刷新到磁盘
- 而让Filesystem自行决定什么时候来做同步,这个是性能最好的。
- slave端 innodb_flush_log_at_trx_commit = 2
- 每次事务提交时MySQL都会把log buffer的数据写入log file,但是flush(刷到磁盘)操作并不会同时进行。
- 该模式下,MySQL会每秒执行一次 flush(刷到磁盘)操作。
- –logs-slave-updates 从服务器从主服务器接收到的更新不记入它的二进制日志。
- 直接禁用slave端的binlog
windows上的mysql主从复制搭建
- 所谓mysql的主从,我们首先应该准备好两个数据库,为了避免接口冲突,我的一台mysql的服务器的端口为3306,另一台服务器的端口号为3307,端口号在mysql的配置文件my.ini中配置。
- 主服务器配置:
[mysqld] # mysqld 配置 port=3307 basedir=D:\laravel\mysql2 datadir=D:\laravel\mysql2\data
- 从服务器的端口部分配置:
[mysqld] port=3306 basedir="F:/myphp_www/PHPTutorial/MySQL/" datadir="F:/myphp_www/PHPTutorial/MySQL/data/"
- 在我新配置的主数据库上,需要配置mysql的服务于启动:
- 首先使用管理员身份运行cmd,跳转到mysql中的bin目录。安装mysql的服务:mysqld install mysql2 --defaults-file="c:\wamp\bin\mysql2\mysql5.6.17\my.ini"
- 红色字体的mysql2是我配置的环境变量:

- 启动mysql服务
net start mysql # 启动mysql服务 Net stop mysql # 停止mysql服务

- 配置mysql的主从复制,我的这里是端口号为3307的为主数据库,3306的为从数据库,在主数据库上添加主从复制的mysql账号,两个数据库链接的纽扣:
GRANT REPLICATION SLAVE,RELOAD,SUPER ON *.* TO mysql_backup@'%' IDENTIFIED BY '123456'; # 一个账号为mysql_backup的用户创建成功了,密码为123456 # 刷新数据库权限:flush privileges;
- 配置主服务器,这里注意两台服务器的server_id不可以一样,现在我的主服务器的配置如下:
[mysqld] #mysqld 配置 port=3307 basedir=D:\laravel\mysql2 datadir=D:\laravel\mysql2\data server-id=1 log-bin=mysql-bin # 开启了二进制文件 binlog_do_db=follow # 主从复制的数据库 binlog_ignore_db=mysql # 不参与数从复制的数据库,例如mysql binlog_checksum=none # mysql主从复制版本高 sql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES # 配置完成只好在cmd中重启我的mysql2 # navicat中重启master之后并查看master的状态:SHOW MASTER STATUS

# 重置master:reset master;
- 配置从服务器
[mysqld] port=3306 basedir="F:/myphp_www/PHPTutorial/MySQL/" datadir="F:/myphp_www/PHPTutorial/MySQL/data/" character-set-server=utf8 default-storage-engine=MyISAM server_id=2 log-bin=mysql-bin binlog-do-db=follow #同步的数据库 binlog-ignore-db=mysql #同步的数据库 # 重启mysql之后通过配置的账号密码链接主数据库,根据master的状态自定:CHANGE MASTER TO master_host = '127.0.0.1', master_user = 'mysql_backup', master_password = '123456', master_log_file = 'mysql-bin.000004', master_port = 3307; master_log_pos = 120; # 重启slave:START SLAVE # 重置slave:RESET SLAVE # 查看从数据库的状态:show slave status; # 当相应的结果中,slave_IO_Running与slave_SQL_Running两个线程都为Yes时,主从配置成功。

Linux的mysql主从复制搭建:
- 跟本地一样,搭建mysql主从复制,首先需要两台数据库,我是两台服务上直接搭建的mysql主从复制
- 1、首先在主机上赋予丛机的权限,如果有多台从机的话,就赋予多次:GRANT REPLICATION SLAVE ON *.* TO slave@'118.24.89.47' IDENTIFIED BY '1234';
- 然后进入数据库执行:select user,host from mysql.user;
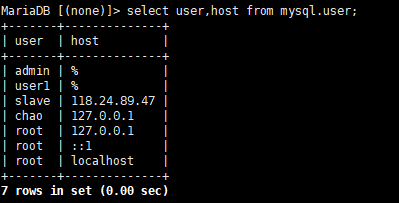
- 可以看到这里给了从机ip为118的一个权限,账号为slave.
- 2、然后就需要设置主机数据库的my.cnf,设置主机标识的service-id,确保可写的二进制log_bin文件,具体如下:
server_id=1 #主机的标识 log-bin=mysql-bin.log #确保可写入的日志文件 binlog_format=mixed #二进制日志的格式, binlog-do-db=master #允许主从复制数据库 binlog-ignore-db=mysql #不允许主从复制的数据库 # ~~~~~~~~~~~~~~~~~~~~重新启动mysql服务
- 3、配置丛机的配置,同样也是在my.cnf的配置文件中,注意service_id不可重复:
server_id=2 #主机的标识 log-bin=mysql-bin.log #确保可写入的日志文件 binlog_format=mixed #二进制日志的格式, replicate_wild_do_table=oldboy.% replicate_wild_ignore_table=mysql.%
- 4、给主机的(1)mysql 锁表,(2)查询master的状态,并(3)解锁:
- flush tables with read lock;
- show master status;(是查看当前bin-log日志的位置点)
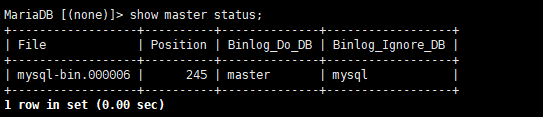
- file:生成的二进制日志
position: # 随着bin_log的日志文件更新内容,发生的变化 binlog_do_db: # 主从复制的数据库 binlog_ignore_db: # 不允许主从复制的数据库 (3)unlock tables;
- 5、在从库上链接主数据库,链接数据master_host='是主机的ip' 依次在数据上执行:
stop slave; change master to master_host='119.27.169.173',master_user='slave',master_password='1234',master_log_file='mysql-bin.000006',master_log_pos=245; start slave;
- 6、最后查看slave的状态:show slave status\G;

当Slave_IO_Running和Slave_SQL_Running线程都为yes是主从复制配置成功!
-
binlog 日志
- 基本概念
- binlog是Mysql sever层维护的一种二进制日志,与innodb引擎中的redo/undo log是完全不同的日志;其主要是用来记录对mysql数据更新或潜在发生更新的SQL语句,记录了所有的DDL和DML(除了数据查询语句)语句,并以
事务的形式保存在磁盘中,还包含语句所执行的消耗的时间,MySQL的二进制日志是事务安全型的。 - 一般来说开启二进制日志大概会有1%的性能损耗(参见MySQL官方中文手册 5.1.24版)。
- binlog是Mysql sever层维护的一种二进制日志,与innodb引擎中的redo/undo log是完全不同的日志;其主要是用来记录对mysql数据更新或潜在发生更新的SQL语句,记录了所有的DDL和DML(除了数据查询语句)语句,并以
- 作用主要有
- 复制:MySQL Replication在Master端开启binlog,Master把它的二进制日志传递给slaves并回放来达到master- slave数据一致的目的
- 数据恢复:通过mysqlbinlog工具恢复数据
- 增量备份
- 二进制日志包括两类文件:二进制日志索引文件(文件名后缀为.index)用于记录所有的二进制文件,二进制日志文件(文件名后缀为.00000*)记录数据库所有的DDL和DML(除了数据查询语句)语句事件。
日志管理
- 开启binlog
修改配置文件 # my.cnf 配置 log-bin 和 log-bin-index 的值,如果没有则自行加上去。 log-bin=mysql-bin log-bin-index=mysql-bin.index # 这里的 log-bin 是指以后生成各 Binlog 文件的前缀,比如上述使用master-bin,那么文件就将会是master-bin.000001、
master-bin.000002 等。 # log-bin-index 则指 binlog index 文件的名称,这里我们设置为master-bin.index,可以不配置。
- 命令查看配置
- binlog开启后,可以在配置文件中查看其位置信息,也可以在myslq命令行中查看:
mysql> show variables like '%log_bin%'; +---------------------------------+---------------------------------------------+ | Variable_name | Value | +---------------------------------+---------------------------------------------+ | log_bin | ON | | log_bin_basename | D:\Program Files\MySQL\data\mysql-bin | | log_bin_index | D:\Program Files\MySQL\data\mysql-bin.index | | log_bin_trust_function_creators | OFF | | log_bin_use_v1_row_events | OFF | | sql_log_bin | ON | +---------------------------------+---------------------------------------------+ 6 rows in set (0.07 sec)
-
查看binlog文件列表
mysql> show binary logs; +------------------+-----------+-----------+ | Log_name | File_size | Encrypted | +------------------+-----------+-----------+ | mysql-bin.000001 | 202 | No | | mysql-bin.000002 | 2062 | No | +------------------+-----------+-----------+ 2 rows in set (0.07 sec)
- binlog文件开启binlog后,会在数据目录(默认)生产host-bin.n(具体binlog信息)文件及host-bin.index索引文件(记录binlog文件列表)。当binlog日志写满(binlog大小max_binlog_size,默认1G),或者数据库重启才会生产新文件,但是也可通过手工进行切换让其重新生成新的文件(flush logs);另外,如果正使用大的事务,由于一个事务不能横跨两个文件,因此也可能在binlog文件未满的情况下刷新文件。
-
查看日志状态
mysql> show master status; +------------------+----------+--------------+------------------+-------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set | +------------------+----------+--------------+------------------+-------------------+ | mysql-bin.000002 | 2062 | | | | +------------------+----------+--------------+------------------+-------------------+ 1 row in set (0.08 sec)
显示正在写入的二进制文件,及当前position
- 刷新日志
mysql> flush logs; Query OK, 0 rows affected (0.12 sec) mysql> show binary logs; +------------------+-----------+-----------+ | Log_name | File_size | Encrypted | +------------------+-----------+-----------+ | mysql-bin.000001 | 202 | No | | mysql-bin.000002 | 2109 | No | | mysql-bin.000003 | 155 | No | +------------------+-----------+-----------+ 3 rows in set (0.07 sec)
- 自此刻开始产生一个新编号的binlog日志文件
- 每当mysqld服务重启时,会自动执行此命令,刷新binlog日志;在mysqldump备份数据时加 -F 选项也会刷新binlog日志;
-
重置(清空)所有binlog日志
mysql> reset master;
-
mysqlbinlog查看日志
D:\Program Files\MySQL
$ bin\mysqlbinlog data\mysql-bin.000002
- 在MySQL5.5以下版本使用mysqlbinlog命令时如果报错,就加上 “--no-defaults”选项
- mysqlbinlog是mysql官方提供的一个binlog查看工具,
- 也可使用–read-from-remote-server从远程服务器读取二进制日志,
- 还可使用--start-position --stop-position、--start-time= --stop-time精确解析binlog日志
内容:
BINLOG ' K3L4XBMBAAAARQAAAHEGAAAAAJoCAAAAAAEACmxvbmdodWJhbmcABXRoZW1lAAUDDwUREQWWAAgA AAABAQACASGhIgQL K3L4XB4BAAAAPQAAAK4GAAAAAJoCAAAAAAEAAgAF/wA0AQAABGFhYWEAAAAAAMBYQFz4citc+HIr sXjMIA== '/*!*/; # at 1710 #190606 9:53:47 server id 1 end_log_pos 1741 CRC32 0xddb08f33 Xid = 216 COMMIT/*!*/; # at 1741 #190606 9:53:47 server id 1 end_log_pos 1820 CRC32 0x166b4128 Anonymous_GTID last_committed=5 sequence_number=6 rbr_only=yes original_committed_timestamp=1559786027387679 immediate_commit_timestamp=15597860273 transaction_length=321 /*!50718 SET TRANSACTION ISOLATION LEVEL READ COMMITTED*//*!*/; # original_commit_timestamp=1559786027387679 (2019-06-06 09:53:47.387679 ?D1ú±ê×?ê±??) # immediate_commit_timestamp=1559786027387679 (2019-06-06 09:53:47.387679 ?D1ú±ê×?ê±??) /*!80001 SET @@session.original_commit_timestamp=1559786027387679*//*!*/; /*!80014 SET @@session.original_server_version=80016*//*!*/; /*!80014 SET @@session.immediate_server_version=80016*//*!*/; SET @@SESSION.GTID_NEXT= 'ANONYMOUS'/*!*/; # at 1820 #190606 9:53:47 server id 1 end_log_pos 1901 CRC32 0x47def222 Query thread_id=10 exec_time=0 error_code=0 SET TIMESTAMP=1559786027/*!*/; BEGIN /*!*/; # at 1901 #190606 9:53:47 server id 1 end_log_pos 1970 CRC32 0x5a235198 Table_map: `longhubang`.`theme` mapped to number 666 # at 1970 #190606 9:53:47 server id 1 end_log_pos 2031 CRC32 0x62dc1928 Write_rows: table id 666 flags: STMT_END_F
# A.查询第一个(最早)的binlog日志: mysql> show binlog events; # B.指定查询 mysql-bin.000021 这个文件: mysql> show binlog events in 'mysql-bin.000021'; # C.指定查询 mysql-bin.000021 这个文件,从pos点:8224开始查起: mysql> show binlog events in 'mysql-bin.000021' from 8224; # D.指定查询 mysql-bin.000021 这个文件,从pos点:8224开始查起,查询10条 mysql> show binlog events in 'mysql-bin.000021' from 8224 limit 10; # E.指定查询 mysql-bin.000021 这个文件,从pos点:8224开始查起,偏移2行,查询10条 mysql> show binlog events in 'mysql-bin.000021' from 8224 limit 2,10;
内容:
mysql> show binlog events in 'mysql-bin.000002' from 1710 limit 10; +------------------+------+----------------+-----------+-------------+--------------------------------------+ | Log_name | Pos | Event_type | Server_id | End_log_pos | Info | +------------------+------+----------------+-----------+-------------+--------------------------------------+ | mysql-bin.000002 | 1710 | Xid | 1 | 1741 | COMMIT /* xid=216 */ | | mysql-bin.000002 | 1741 | Anonymous_Gtid | 1 | 1820 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' | | mysql-bin.000002 | 1820 | Query | 1 | 1901 | BEGIN | | mysql-bin.000002 | 1901 | Table_map | 1 | 1970 | table_id: 666 (longhubang.theme) | | mysql-bin.000002 | 1970 | Write_rows | 1 | 2031 | table_id: 666 flags: STMT_END_F | | mysql-bin.000002 | 2031 | Xid | 1 | 2062 | COMMIT /* xid=223 */ | | mysql-bin.000002 | 2062 | Rotate | 1 | 2109 | mysql-bin.000003;pos=4 | +------------------+------+----------------+-----------+-------------+--------------------------------------+ 7 rows in set (0.14 sec)
-
完全备份
D:\Program Files\MySQL $ bin\mysqldump -h127.0.0.1 -p3306 -uroot -phongda$123456 -lF -B longhubang >D:\data\backup\longhubang.dump mysqldump: [Warning] Using a password on the command line interface can be insecure.
- 注意要创建好D:\data\backup文件夹。
- 这里使用了
-lF,注意必须大写F,当备份工作刚开始时系统会刷新log日志,产生新的binlog日志来记录备份之后的数据库“增删改”操作。
查看一下:
mysql> show binary logs; +------------------+-----------+-----------+ | Log_name | File_size | Encrypted | +------------------+-----------+-----------+ | mysql-bin.000001 | 202 | No | | mysql-bin.000002 | 2109 | No | | mysql-bin.000003 | 374 | No | | mysql-bin.000004 | 155 | No | +------------------+-----------+-----------+ 4 rows in set (0.10 sec)
也就是说, mysql-bin.000004 是用来记录完全备份命令时间之后对数据库的所有“增删改”操作。
Linux数据备份命令:
/usr/local/mysql/bin/mysqldump -uroot -p123456 -lF --log-error=/root/myDump.err -B zyyshop > /root/BAK.zyyshop.sql
mysql> flush logs;
-
- 此时执行一次刷新日志索引操作,重新开始新的binlog日志记录文件,理论说 mysql-bin.000004 这个文件不会再有后续写入了(便于我们分析原因及查找pos点),以后所有数据库操作都会写入到下一个日志文件;
查看binlog日志:
mysql> show binlog events in 'mysql-bin.000004';
最后一段日志内容:
| mysql-bin.000004 | 3976 | Xid | 1 | 4007 | COMMIT /* xid=2375 */ | | mysql-bin.000004 | 4007 | Anonymous_Gtid | 1 | 4086 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' | | mysql-bin.000004 | 4086 | Query | 1 | 4167 | BEGIN | | mysql-bin.000004 | 4167 | Table_map | 1 | 4236 | table_id: 666 (longhubang.theme) | | mysql-bin.000004 | 4236 | Delete_rows | 1 | 4505 | table_id: 666 flags: STMT_END_F | | mysql-bin.000004 | 4505 | Xid | 1 | 4536 | COMMIT /* xid=2393 */ | | mysql-bin.000004 | 4536 | Anonymous_Gtid | 1 | 4613 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' | | mysql-bin.000004 | 4613 | Query | 1 | 4736 | drop database longhubang /* xid=2411 */ | | mysql-bin.000004 | 4736 | Rotate | 1 | 4783 | mysql-bin.000005;pos=4 | +------------------+------+----------------+-----------+-------------+------------------------------------------+ 70 rows in set (0.21 sec)
- 通过分析,造成数据库破坏的pos点区间是介于4613--4736 之间,只要恢复到4613前就可。
先进行完全备份恢复:
D:\Program Files\MySQL
$ bin\mysql -h127.0.0.1 -p3306 -uroot -phongda$123456 -v <D:\data\backup\longhubang.dump
binlog日志恢复:
D:\Program Files\MySQL $ bin\mysqlbinlog --stop-position=4613 data\mysql-bin.000004 | bin\mysql -h127.0.0.1 -p3306 -uroot -phongda$123456 longhubang mysql: [Warning] Using a password on the command line interface can be insecure.
增量数据恢复语法格式:
mysqlbinlog mysql-bin.0000xx | mysql -u用户名 -p密码 数据库名 常用选项: --start-position=953 起始pos点 --stop-position=1437 结束pos点 --start-datetime="2013-11-29 13:18:54" 起始时间点 --stop-datetime="2013-11-29 13:21:53" 结束时间点 --database=zyyshop 指定只恢复zyyshop数据库(一台主机上往往有多个数据库,只限本地log日志) 不常用选项: -u --user=name Connect to the remote server as username.连接到远程主机的用户名 -p --password[=name] Password to connect to remote server.连接到远程主机的密码 -h --host=name Get the binlog from server.从远程主机上获取binlog日志 --read-from-remote-server Read binary logs from a MySQL server.从某个MySQL服务器上读取binlog日志
小结:实际是将读出的binlog日志内容,通过管道符传递给mysql命令。这些命令、文件尽量写成绝对路径;
上面的binlog恢复语句也可以拆分:
D:\Program Files\MySQL $ bin\mysqlbinlog --stop-position=4613 data\mysql-bin.000004 > D:\data\backup\004.sql D:\Program Files\MySQL $ bin\mysql -h127.0.0.1 -p3306 -uroot -phongda$123456 longhubang mysql: [Warning] Using a password on the command line interface can be insecure. ....... mysql> source D:\data\backup\004.sql
所谓恢复,就是让mysql将保存在binlog日志中指定段落区间的sql语句逐个重新执行一次而已。
复制是mysql最重要的功能之一,mysql集群的高可用、负载均衡和读写分离都是基于复制来实现的;从5.6开始复制有两种实现方式,基于binlog和基于GTID(全局事务标示符)
其复制的基本过程如下:
- Master将数据改变记录到二进制日志(binary log)中
- Slave上面的IO进程连接上Master,并请求从指定日志文件的指定位置(或者从最开始的日志)之后的日志内容
- Master接收到来自Slave的IO进程的请求后,负责复制的IO进程会根据请求信息读取日志指定位置之后的日志信息,返回给Slave的IO进程。返回信息中除了日志所包含的信息之外,还包括本次返回的信息已经到Master端的bin-log文件的名称以及bin-log的位置
- Slave的IO进程接收到信息后,将接收到的日志内容依次添加到Slave端的relay-log文件的最末端,并将读取到的Master端的 bin-log的,文件名和位置记录到master-info文件中,以便在下一次读取的时候能够清楚的告诉Master从某个bin-log的哪个位置开始往后的日志内容
- Slave的Sql进程检测到relay-log中新增加了内容后,会马上解析relay-log的内容成为在Master端真实执行时候的那些可执行的内容,并在自身执行
希望能帮助你,喜欢的就点个关注不迷路哦,有什么错误还望各位及时指出!!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号