数据挖掘-基于贝叶斯算法及KNN算法的newsgroup18828文档分类器的JAVA实现(上)
本文主要描述基于贝叶斯算法及KNN算法的newsgroup18828文档分类器的设计及实现,包括数据预处理、贝叶斯算法及KNN算法实现。本分类器的完整工程可以到点击打开链接下载,详细说明的运行方法,用eclipse可以运行,学习数据挖掘的朋友可以跑一下,有问题可以联系我,欢迎交流:)。本文主要内容如下:
对newsgroup文档集进行预处理,提取出30095 个特征词
计算每篇文档中的特征词的TF*IDF值,实现文档向量化,在KNN算法中使用
用JAVA实现了KNN算法及朴素贝叶斯算法的newsgroup文本分类器
1、Newsgroup文档集介绍
Newsgroups最早由Lang于1995收集并在[Lang 1995]中使用。它含有20000篇左右的Usenet文档,几乎平均分配20个不同的新闻组。除了其中4.5%的文档属于两个或两个以上的新闻组以外,其余文档仅属于一个新闻组,因此它通常被作为单标注分类问题来处理。Newsgroups已经成为文本分及聚类中常用的文档集。美国MIT大学Jason Rennie对Newsgroups作了必要的处理,使得每个文档只属于一个新闻组,形成Newsgroups-18828。
2、Newsgroup文档预处理
要做文本分类首先得完成文本的预处理,预处理的主要步骤如下
出现次数大于等于1次的词有87554个
出现次数大于等于3次的词有36456个
出现次数大于等于4次的词有30095个
特征词的选取策略:
策略一:保留所有词作为特征词 共计87554个
策略二:选取出现次数大于等于4次的词作为特征词共计30095个
特征词的选取策略:采用策略一,后面将对两种特征词选取策略的计算时间和平均准确率做对比
3、贝叶斯算法描述及实现
类条件概率P(tk|c)=(类c下单词tk在各个文档中出现过的次数之和+1)/(类c下单词总数+训练样本中不重复特征词总数)
先验概率P(c)=类c下的单词总数/整个训练样本的单词总数
伯努利模型(Bernoulli model) –以文件为粒度
(2) 类条件概率P(tk|c)=(类c下包含单词tk的文件数+1)/(类c下单词总数+2)
先验概率P(c)=类c下文件总数/整个训练样本的文件总数
本分类器选用多项式模型计算,根据《Introduction to Information Retrieval 》,多项式模型计算准确率更高
(2) 用交叉验证法做十次分类实验,对准确率取平均值
(3) 根据正确类目文件和分类结果文计算混淆矩阵并且输出
(4) Map<String,Double> cateWordsProb key为“类目_单词”, value为该类目下该单词的出现次数,避免重复计算
4 朴素贝叶斯算法对newsgroup文档集做分类的结果
为方便计算混淆矩阵,将类目编号如下
0 alt.atheism
1 comp.graphics
2 comp.os.ms-windows.misc
3comp.sys.ibm.pc.hdwar
4comp.sys.mac.hardwar
5 comp.windows.x
6 misc.forsale
7 rec.autos
8 rec.motorcycles
9 rec.sport.baseball
10 rec.sport.hockey
11 sci.crypt
12 sci.electronics
13 sci.med
14 sci.space
15 soc.religion.christian
16 talk.politics.guns
17 talk.politics.mideast
18 talk.politics.misc
19 talk.religion.misc

取所有词共87554个作为特征词:10次交叉验证实验平均准确率78.19%,用时23min,准确率范围75.65%-80.47%,第6次实验准确率超过80%
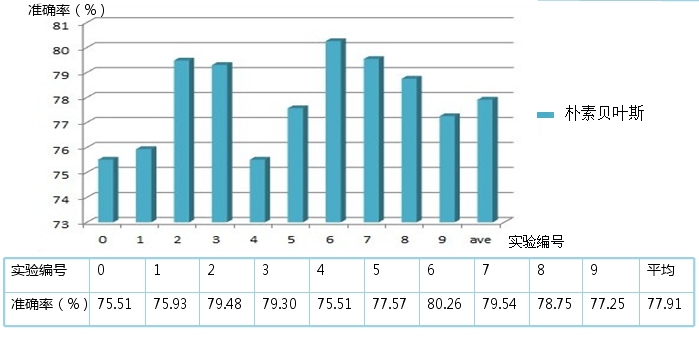
取出现次数大于等于4次的词共计30095个作为特征词: 10次交叉验证实验平均准确率77.91%,用时22min,准确率范围75.51%-80.26%,第6次实验准确率超过80%