
分布式共识算法随笔 —— 从 Quorum 到 Paxos
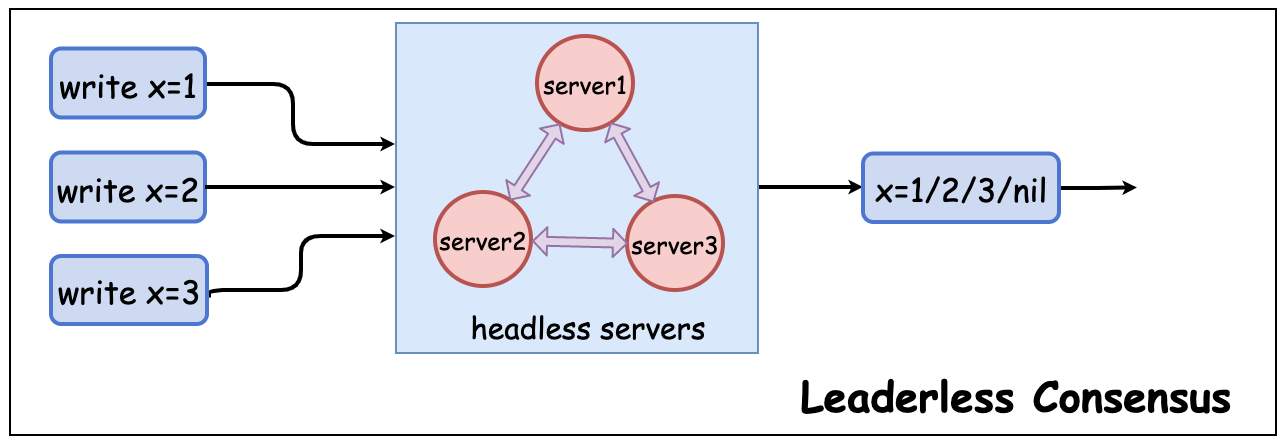
 复制(Replication) 是一种通过将同一份数据在复制在多个服务器上来提高系统可用性和扩展写吞吐的策略, 。常见的复制策略有主从架构(Leader/Follower), 多主架构(Multi-Leader) 和 无主架构(LeaderLess)[1]。在无主架构模式下,需要保证多个节点写入数据的一致(即共识(consensus))。如, 某个无主架构包含 Server1, Server2, Server3 三个服务器, 当前状态为 x=nil,并发同时向他们分别发起 x=1, x=2, x=3 请求,最终一定会得到一个确定的值(而不会产生分歧)。这个值可以是写入成功的 x=1, x=2 或 x=3,也可以是未发起写入操作前的 x=nil。
复制(Replication) 是一种通过将同一份数据在复制在多个服务器上来提高系统可用性和扩展写吞吐的策略, 。常见的复制策略有主从架构(Leader/Follower), 多主架构(Multi-Leader) 和 无主架构(LeaderLess)[1]。在无主架构模式下,需要保证多个节点写入数据的一致(即共识(consensus))。如, 某个无主架构包含 Server1, Server2, Server3 三个服务器, 当前状态为 x=nil,并发同时向他们分别发起 x=1, x=2, x=3 请求,最终一定会得到一个确定的值(而不会产生分歧)。这个值可以是写入成功的 x=1, x=2 或 x=3,也可以是未发起写入操作前的 x=nil。
分布式共识算法随笔 —— 从 Quorum 到 Paxos
本文主要参考各类英文文献,部分专业术语翻译较为生硬,望谅解。
概览: 为什么需要共识算法?
昨夜西风凋碧树,独上高楼,望尽天涯路
复制(Replication) 是一种通过将同一份数据在复制在多个服务器上来提高系统可用性和扩展写吞吐的策略, 。常见的复制策略有主从架构(Leader/Follower), 多主架构(Multi-Leader) 和 无主架构(LeaderLess)[1]。在无主架构模式下,需要保证多个节点写入数据的一致(即共识(consensus))。如, 某个无主架构包含 Server1, Server2, Server3 三个服务器, 当前状态为 x=nil,并发同时向他们分别发起 x=1, x=2, x=3 请求,最终一定会得到一个确定的值(而不会产生分歧)。这个值可以是写入成功的 x=1, x=2 或 x=3,也可以是未发起写入操作前的 x=nil。
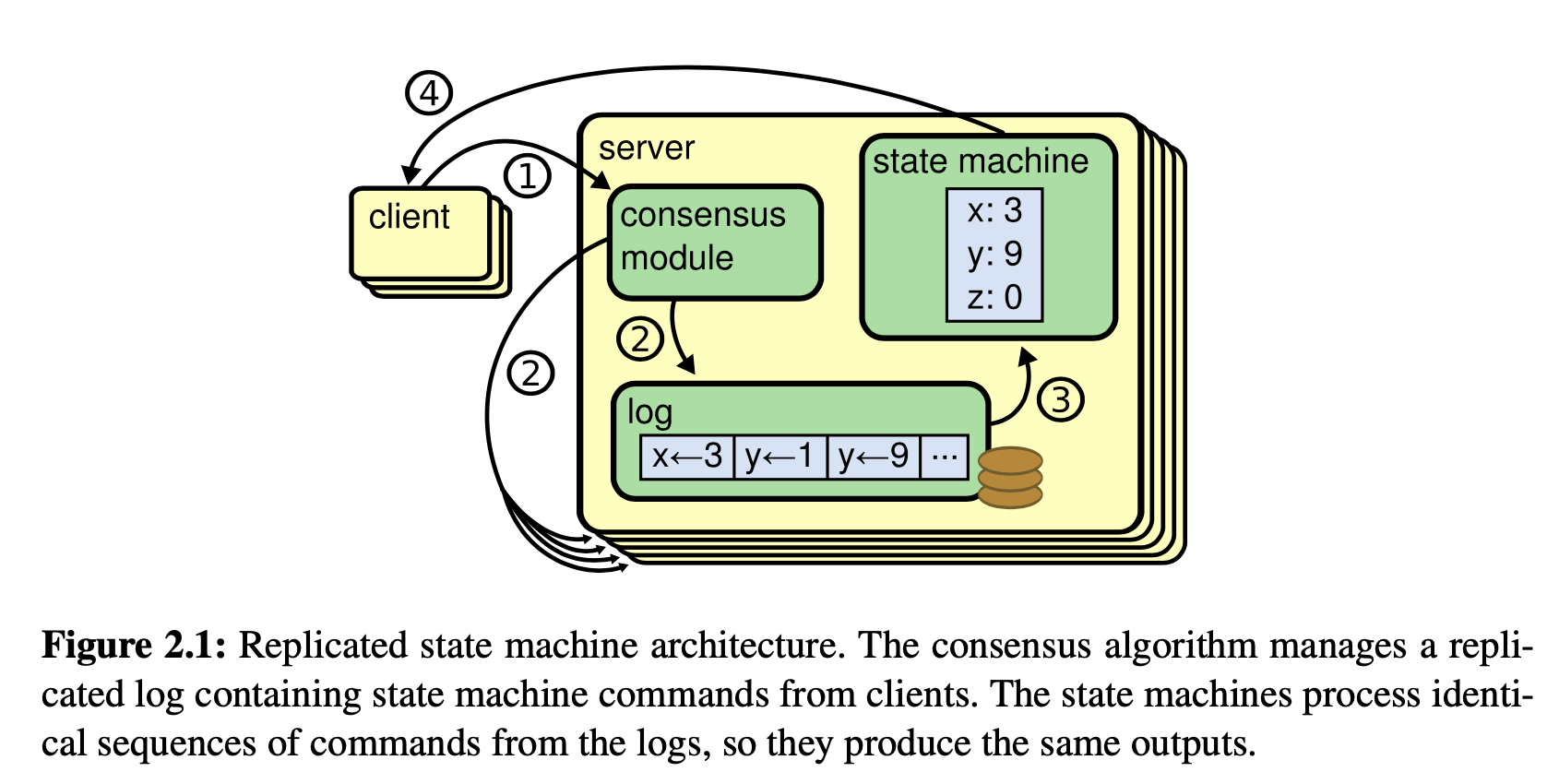
状态机(State Machine) 常用于维护不同服务器之间的数据同步状态[2]。只要保证各个服务器之间的状态机状态一致,则它们的数据集就是一样的。状态机通常由 Write-Ahead-Log(WAL 日志) 实现,这些日志记录了一系列有序的命令。每个服务器将会按照 WAL 日志的内容,按序执行这些命令。
因此, 只要这些服务器的 WAL 日志保持一致,则它们最终的状态机就是一致的,那么他们最终的数据集也就是一致的。通常, WAL 日志一旦写入,都是不可变的。因为一旦 WAL 写入, 很可能它已经应用到了状态机。如果要变更该日志, 意味着需要从状态机内回滚该操作。而回滚这一条 WAL 日志的操作,很可能需要先将后续的 WAL 日志都回滚, 这样的成本往往是很高的。(如果引入了共识模块, 情况将会变得更加糟糕。)
通过在每个服务器加入实现 WAL 日志保持一致性的共识模块(Consensus Module),我们就可以让所有的服务器的数据保持一致。各个服务器的共识模块通过和其他服务器的共识模块之间的通信,对并发写入的数据达成共识,确保最终写入的 WAL 日志顺序和命令(日志内容)都是一样的[3][4] 。下图出自参考文献[4] (本文未注明来源的图均为原创)。
为了保证所有的 WAL 日志的顺序和日志内容都是一样的,共识模块只需要依次对单个日志 ID(有的地方也被称为日志槽(Log Slot)[5]) 达成共识, 最终就会使得整个 WAL 日志都是达成共识的, 从而使得所有服务器的整个数据集都是一致的。
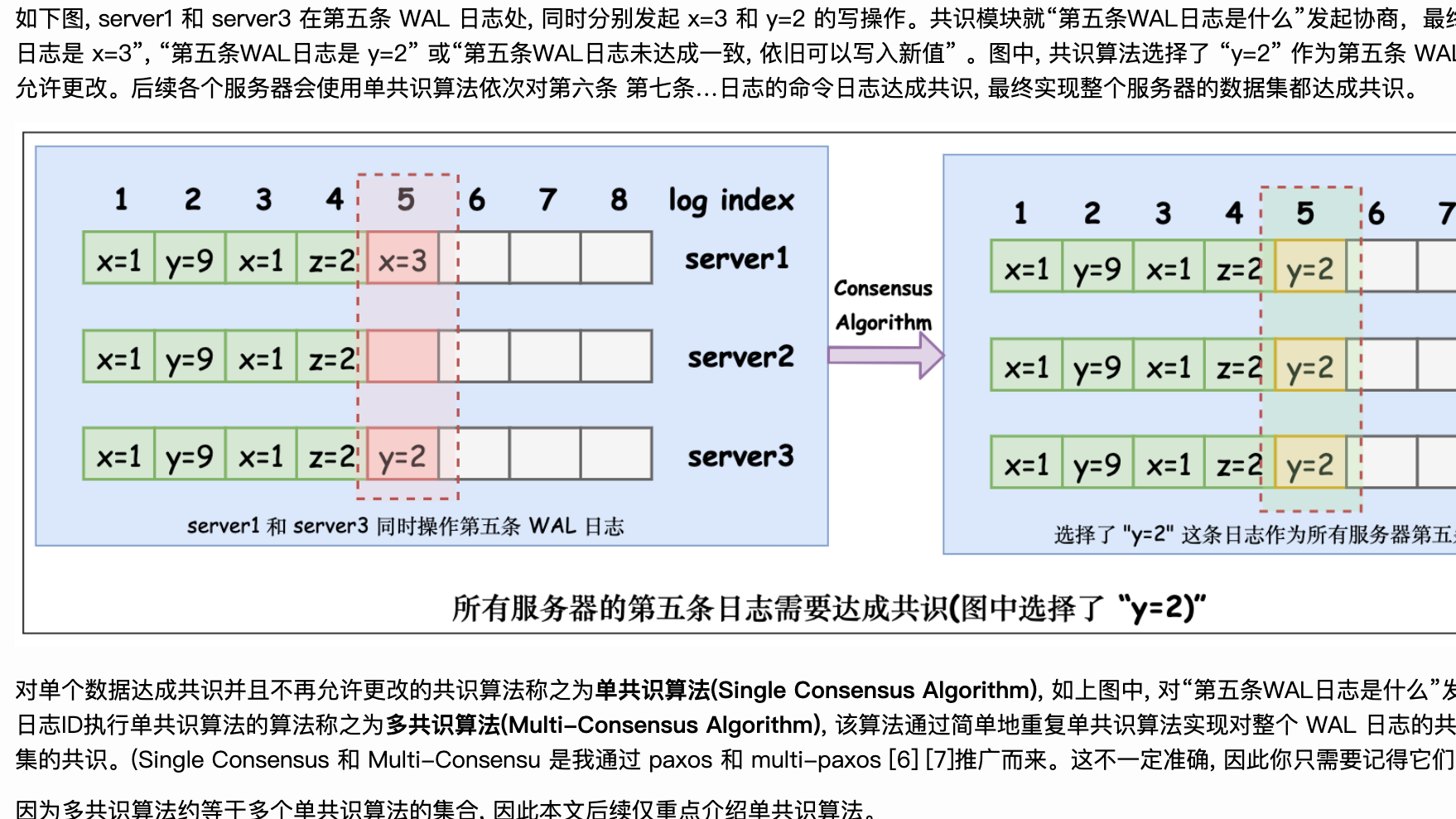
如下图, server1 和 server3 在第五条 WAL 日志处, 同时分别发起 x=3 和 y=2 的写操作。共识模块就“第五条WAL日志是什么”发起协商,最终的共识可以是 “第五条WAL日志是 x=3”, “第五条WAL日志是 y=2” 或“第五条WAL日志未达成一致, 依旧可以写入新值” 。图中, 共识算法选择了 “y=2” 作为第五条 WAL 日志,这一条日志将不再被允许更改。后续各个服务器会使用单共识算法依次对第六条 第七条…日志的命令日志达成共识, 最终实现整个服务器的数据集都达成共识。
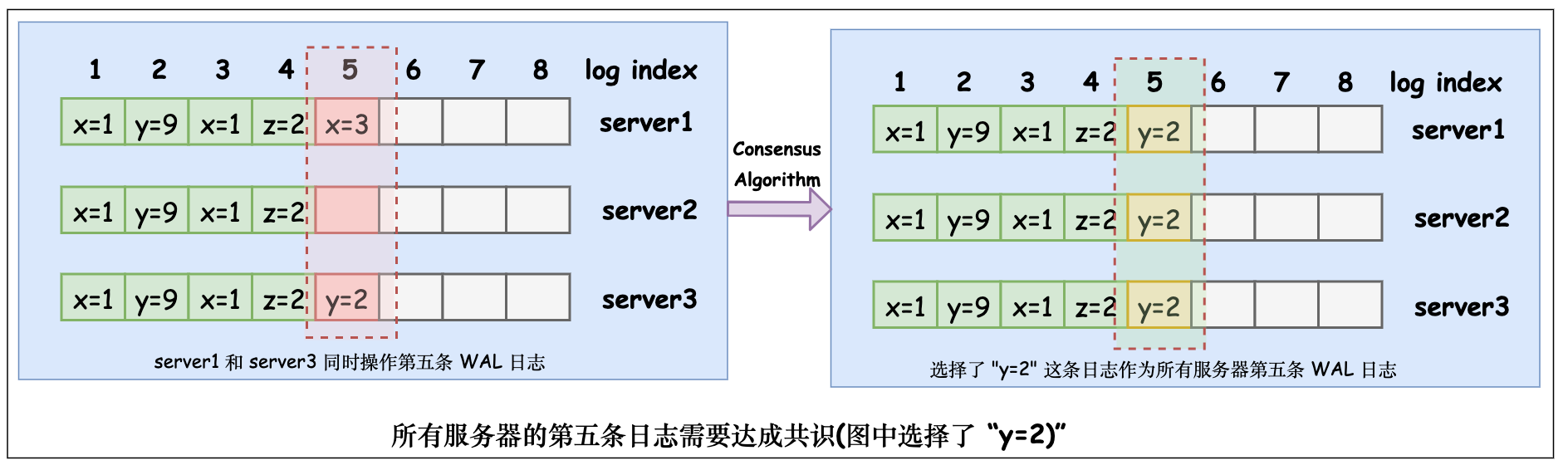
对单个数据达成共识并且不再允许更改的共识算法称之为单共识算法(Single Consensus Algorithm), 如上图中, 对“第五条WAL日志是什么”发起的共识算法。而分别对每个日志ID执行单共识算法的算法称之为多共识算法(Multi-Consensus Algorithm), 该算法通过简单地重复单共识算法实现对整个 WAL 日志的共识,从而实现所有服务器数据集的共识。(Single Consensus 和 Multi-Consensu 是我通过 paxos 和 multi-paxos [6] [7]推广而来。这不一定准确, 因此你只需要记得它们的对应关系即可)
因为多共识算法约等于多个单共识算法的集合, 因此本文后续仅重点介绍单共识算法。
在进入各种共识算法的介绍之前,我们还得了解下单共识算法的安全属性,这样才能明确我们需要达到的目标(系统需要始终保证其安全属性始终满足)。安全属性(Safety Property) 是指约束系统状态, 在系统运行中, 限制一些不可逆转的不好的事情发生(nothing bad happens)的属性。在系统正常运行过程中,需要始终保证满足安全属性。正式的定义可参考 [1] [8]。
根据上述内容, 我们可以简单地梳理出单共识算法需要满足的 Safety Property:
- 只有客户端提交的数据才能被服务端达成共识而选中。(防止异常数据产生)
- 当多个客户端并发写入时, 只能有一个 value 能被服务端选中。某个 value 一旦被服务端达成共识而选中, 它将不可被更改。(确保选中数据不会冲突, 不能被更改)
- 读请求只能“看见”服务端达成共识的 value。(防止脏读等情况)
探索: 单共识算法的可能性
衣带渐宽终不悔,为伊消得人憔悴
从 Quorum 算法聊起
Quorum 算法的基本思想是: 假如有 n 个服务器, 每次写请求至少保证 w 个服务器写入成功, 每次读请求至少保证 r 个服务器返回成功。根据鸽巢原理, 只要保证 w + r > n, 则我们一定能读到最新的数据 。[1][9], 下图引用自参考文献 [1]
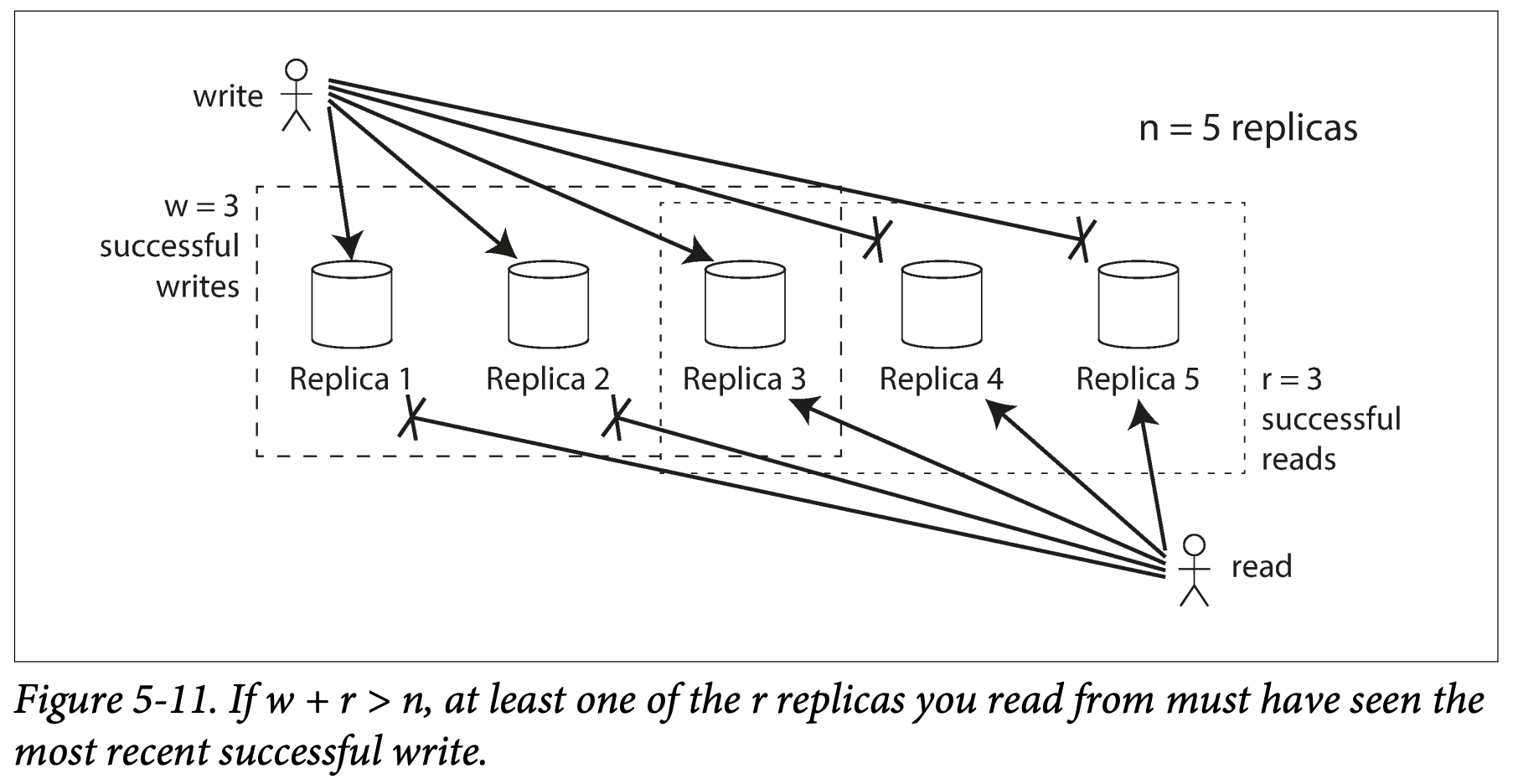
简单起见, 下面都令 w = r = ⌊n⌋ + 1, 即读写都至少保证大部分服务器返回成功, 才认为操作成功。
-
时间戳(timestamp)
为了区分 r 个服务器返回的数据谁的版本最新, 我们需要定义数据写入的时间戳, 以区分数据的写入顺序。定义时间戳timestamp := <clientID, version>。其中, clientID 表示发起该写请求的客户端的 ID。版本号 version 表示该数据(预期)在服务器中的版本号。 timestamp 的比较算法如下:
-
写请求流程
- 客户端(ID 记为 clientID)向服务端广播 get version 请求获取最新的版本号 version。
- 当大多数服务端已返回, 记它们的最大版本号为 latest_version。客户端发起写入请求 x=a, 请求的时间戳为 <clientID, latest_version+1>。
- 服务端接收到写请求后,比较上次写入操作的时间戳 last_timestamp 和本次写请求的时间戳 timestamp:
- 如果 last_timestamp 小于 timestamp,, 则执行写操作(在当前服务器写入 x=a, 令 last_timestamp = timestamp), 并向客户端返回“操作执行成功, 当前版本号为 timestamp.version, 当前 x 的值为 a”。
- 否则, 向客户端返回“执行失败,当前版本号为 last_timestamp.version, 当前 x 的值”
- 客户端接受到大部分服务端返回执行成功, 则该写请求已执行成功(服务端已达成共识)。
- 否则:
- 如果大多数服务端返回 x 的当前值为 a 或 nil(因为 timestamp 过期导致写入操作失败), 则令版本号为返回版本号的最大值加一, 并再次发起 x=a 的写请求操作(回到第 2 步)。
- 否则, 数据冲突, 写入失败。
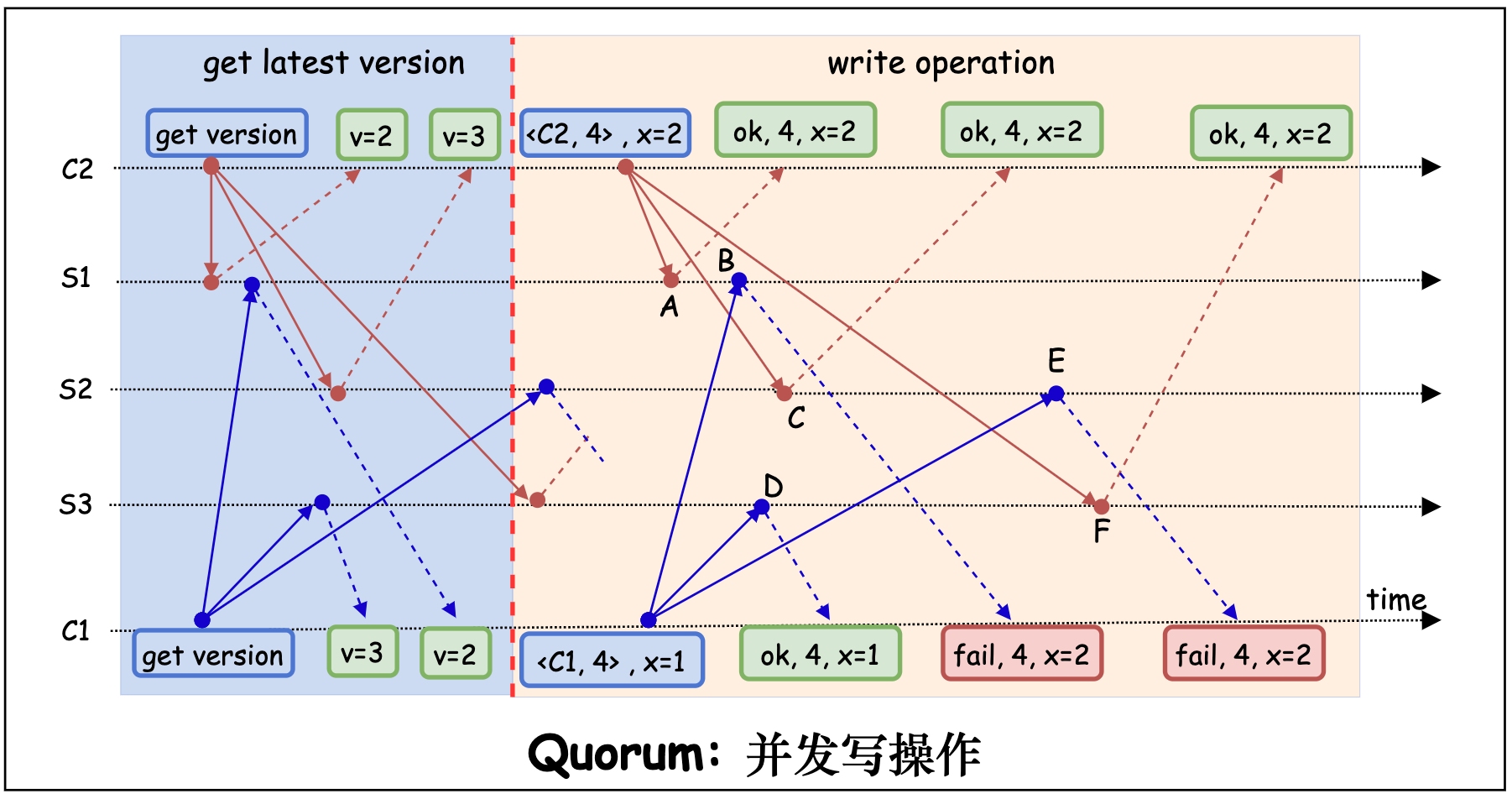
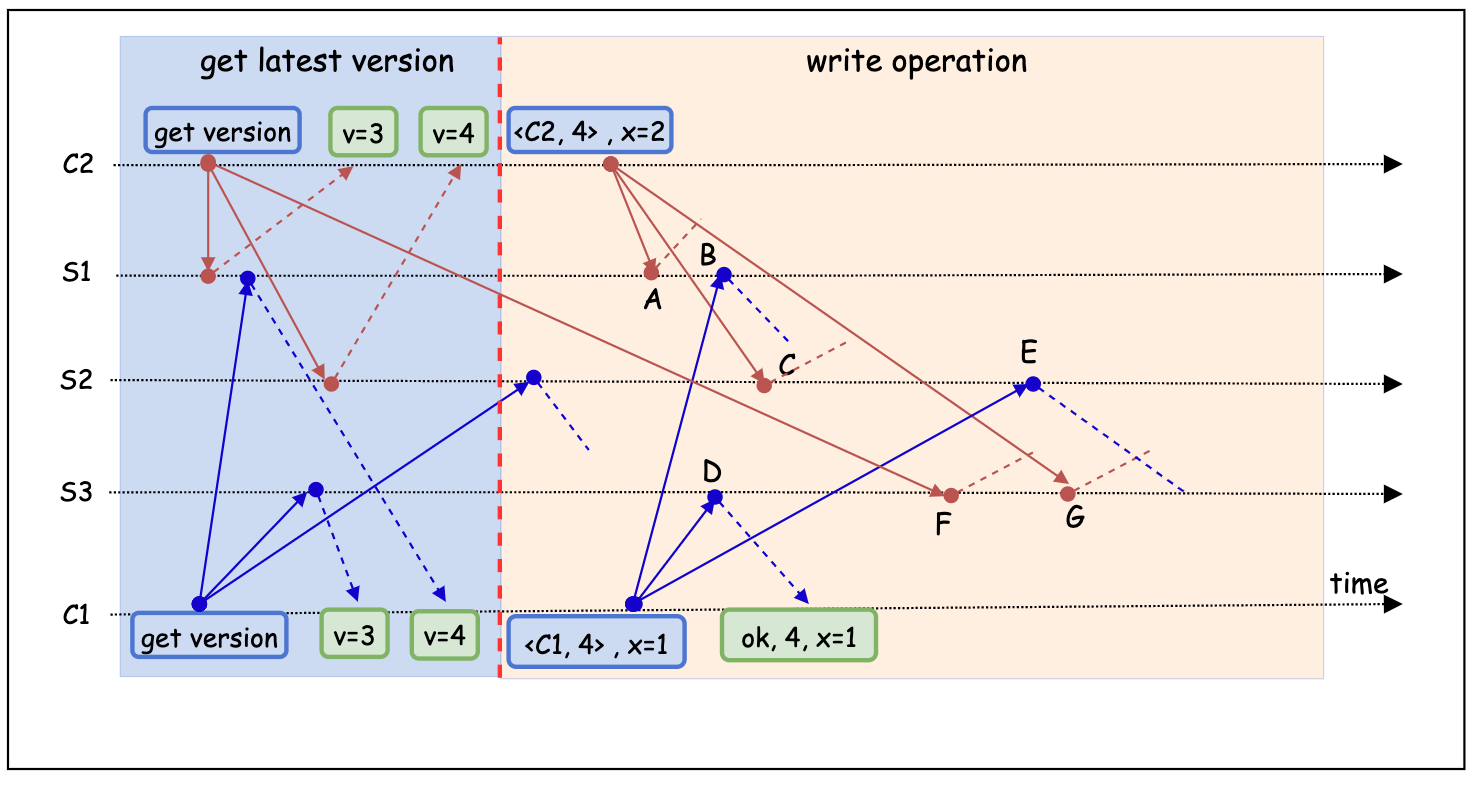
下图展示了客户端 C1, C2 同时向服务端 S1, S2, S3 发起写请求的场景。其中, C1 发起写操作 x = 1, C2 发起写操作 x = 2。最终服务端达成共识,成功写入 x = 2。
- 读请求流程
- 客户端向服务端广播读请求
- 当大多数服务端已返回数据, 将 timestamp 最新的数据作为最终结果返回。
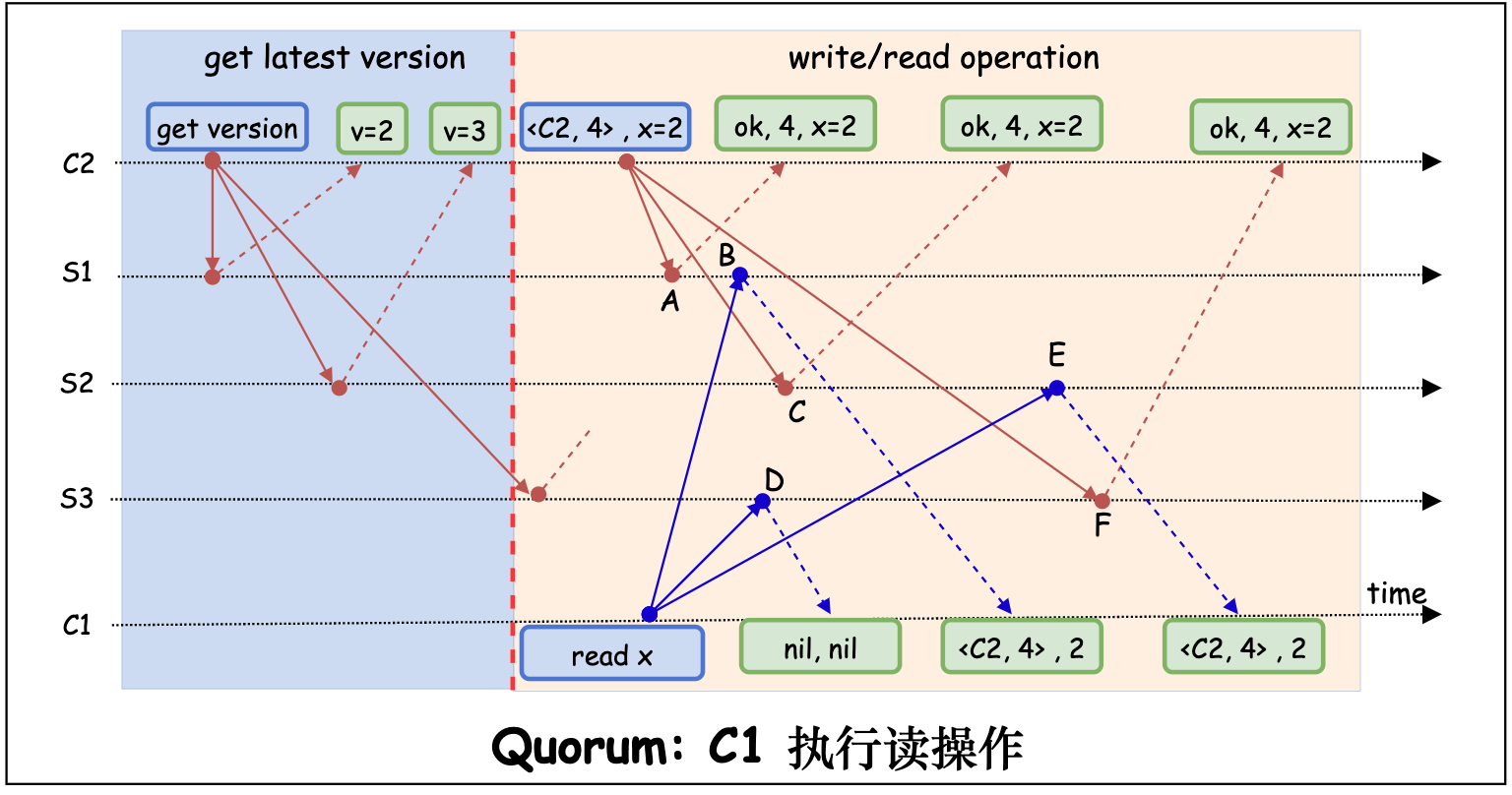
下图展示了客户端 C1 同时向服务端 S1, S2, S3 发起读请求, C2 发起 x=2 的写请求的场景。C1 最终读取到的数据为 x = 2。
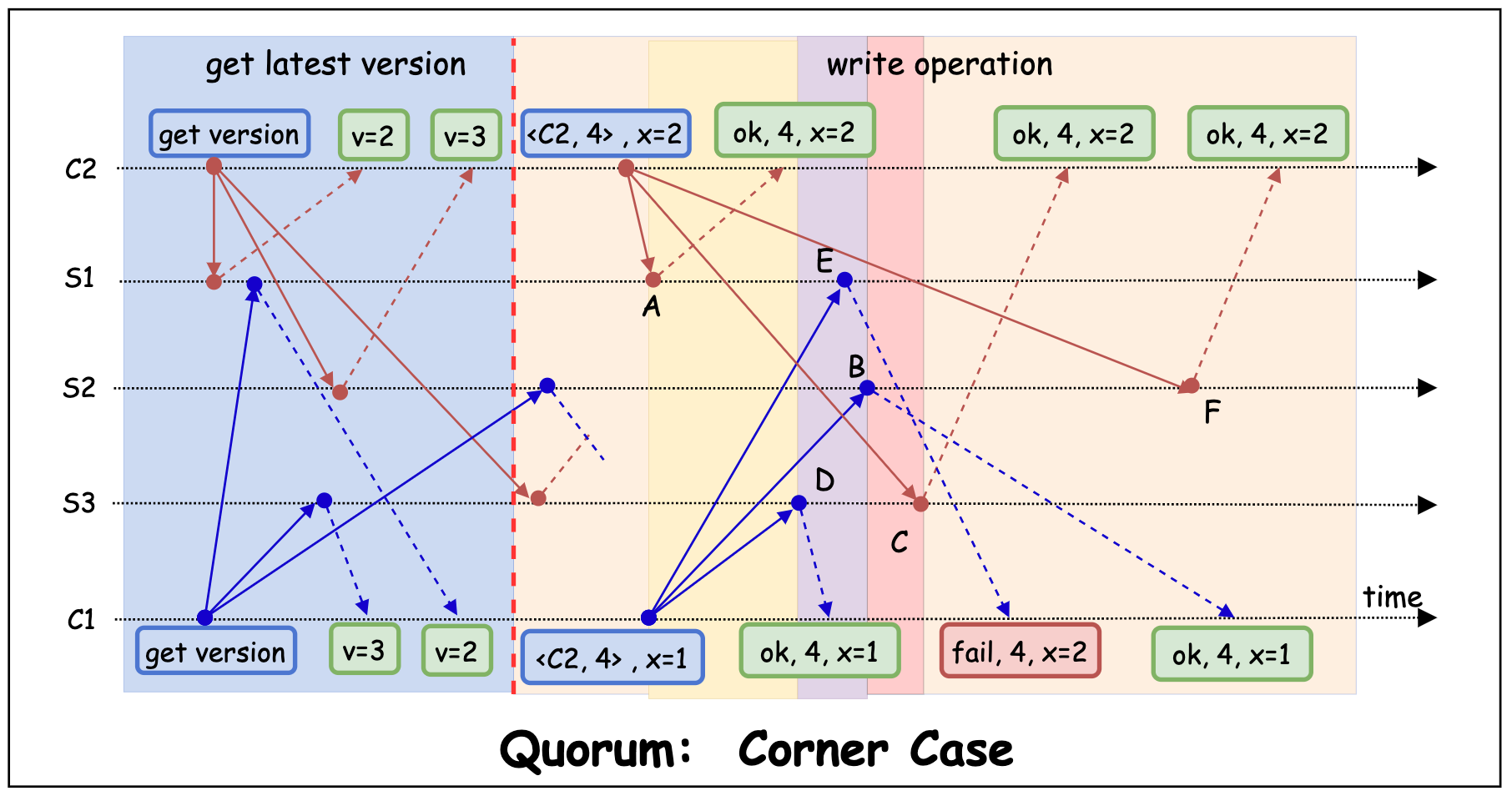
- Corner Case: 如下图,客户端 C1, C2 同时向服务端 S1, S2, S3 发起写请求的场景。其中, C1 发起写操作 x = 1, C2 发起写操作 x = 2。
- 图中点 A 时刻到点 D 时刻之间,用户读取到的数据可能是 x=2(用户读取 S1,S2 或 S1,S3),也可能是 x=nil(用户读取 S2, S3)。这违背了第三条 Safety Property(只有被选中的 value 才能被 “看见”)。
- 图中点 D 时刻到点 B 时刻之间, 用户可能读取到 x=2(用户读取 S1,S2 或 S1,S3),或 x=1(用户读取 S2, S3)。这同样违背了第三条 Safety Property。
- 点 B 时刻到点 C 时刻之间, 用户读到的数据为 x=1。但在点 C 时刻之后, 用户读到的数据却变为了 x=2。而这两个数据均是服务端达成的共识(值唯一),因此, 违背了第二条 Safety Property(只能有一个 value 能被服务端选中。某个 value 一旦被服务端达成共识而选中, 它将不可被更)。
- Corner Case 的处理
-
点 A 时刻到点 D 时刻之间: 将读操作逻辑以大多数server返回的值为最终的结果值(而不是 latest version 的 value)。这样在 A->D 读到的数据为 (2, nil, nil), 大多数的值为 nil, 因此结果始终为 nil。(x = 2 并未达成共识, 因此无法被读取)。
-
点 D 时刻到点 B 时刻之间: 服务端在每次接收到 get version 操作后, 都将自身的 version 加一并返回, 同时限制过期的 version 的写入。(仅接受 version 号和自身相同的 write 请求)。但这么一来就会出现图中 S3 先接受了 C1 的写请求(x=1), 再接收到 C2 的 get version 请求。而 S1, S2 则正好相反的情况。这种情况下, 可能会出现下图的点 D 时刻到点 C 时刻之间, 业务读取到的数据为 (2, nil, 1), 不存在大多数派的数据, 服务端未达成共识, 可以认为当前的共识为 x=nil。
-
点 B 时刻到点 C 时刻之间(x=1)以及点 C 时刻之后(x=2): 2 的解决方案, 同时也能解决该问题。
以上处理 Corner Case 的逻辑已经可以管中窥豹,看到一些 paxos 算法的雏形了。我们先按下不表,先看下如何改造 两阶段提交(2PC) 算法实现单一致性算法。
改造 2PC(Two Phase Commit) 算法
2PC(Two-Phase Commit) 是一种用于解决多个服务器如何就同一分布式事务达成一致的方法。在 2PC 中,多个服务器分别处理用于执行同一个写入操作的不同子请求(比如某个写请求需要处理不同服务器上的 partition 的数据)。它们必须同时成功地将写入提交(committed),否则就会同时失败并回滚(aborted)。[1] [14]
我们可以将同一个写请求通过 2PC 实现的事务在不同的服务器上执行一遍,实现 replication 功能。该方式能够保证不同服务器上的数据要么同时写入, 要么同时回滚,从而使得服务器间对该数据达成共识。
用上述方式实现的共识算法虽然扩展了服务器的读性能, 但是一旦某个服务器崩溃,所有的写请求都会失败(2PC 需要保证所有的服务器都执行成功)。这将导致集群的可用性大幅降低。
为了提高集群的可用性,我们引入上文的 Quorum 算法改造 2PC 算法,以实现读性能高可用的同步扩展。
2PC 算法有两个角色,一个是发起事务操作的客户端 TM(transaction manager), 一个是处理事务的服务器 RM(resource manager)。 2PC 单一致性算法保证 TM 提交的写操作在 RM 集群达成共识。
- 写请求流程
- TM 将写请求的 prepare 消息广播给各个 RM。
- RM 接收到 prepare 请求后(相当于加了写锁),
- RM 前处于 preparing 状态,且 prepare 请求和 RM 中 preparing 的请求不一致,则请求冲突,返回 prepare 失败。
- 当前已有提交的值,且 prepare 请求写入的值和 RM 中已提交的值不一致,则请求冲突,返回 prepare 失败。
- 否则, 保存 prepare 信息, 将 RM 状态置为 preparing, 返回 prepare 成功。
- 当TM 接收到大多数 RM 返回 prepare 失败,则向 RM 广播 abort 消息,写操作执行失败。 若大多数 RM 都返回 prepare 执行成功, 则向所有 RM 广播 commit 操作。写操作执行成功。
- RM 接收到 commit 请求后,写入数据,并将 RM 恢复初始状态。
- RM 接受到 abort 请求后,并将 RM 恢复初始状态。
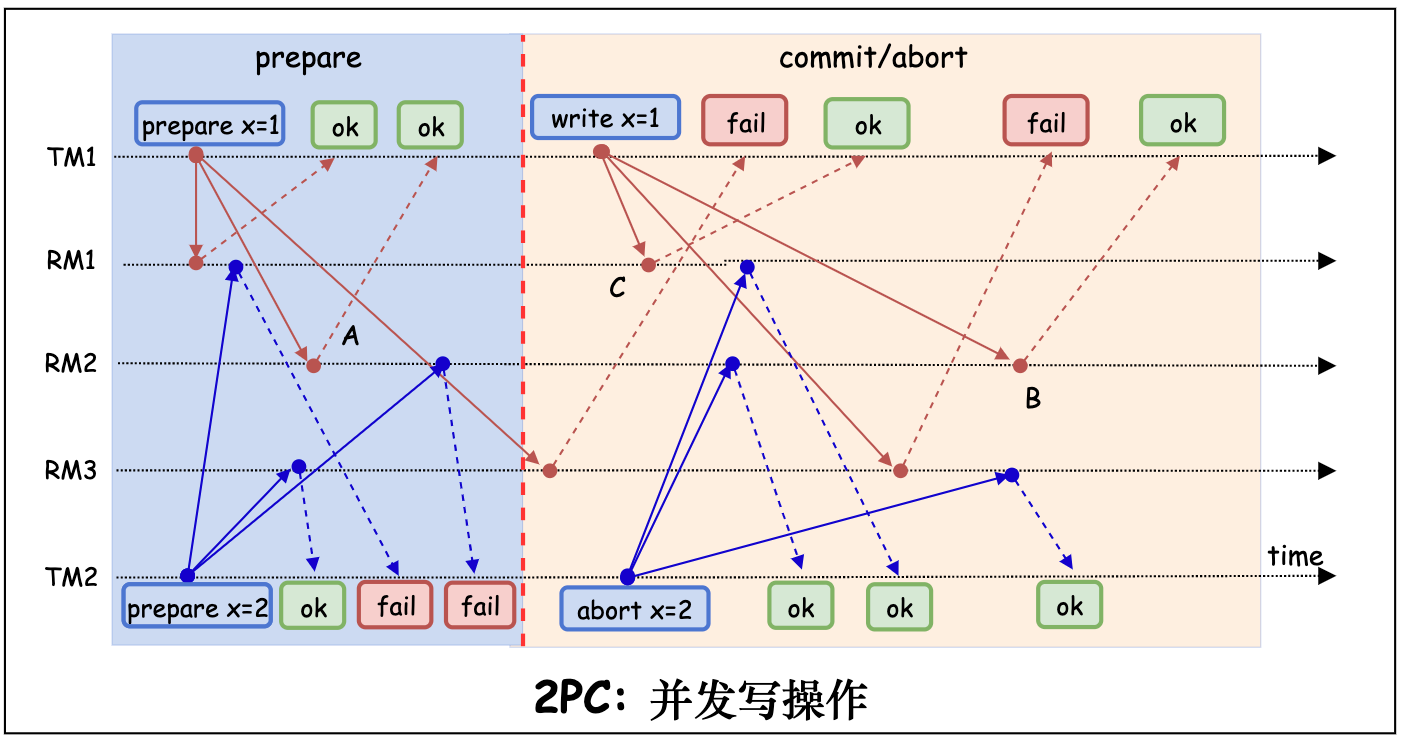
下图展示了 TM1, TM2 并发发起写操作, TM1 写入成功, 而 TM2 回滚的场景。
- 读操作流程
- TM 向 RM 广播读请求
- 当大多数 RM 返回数据作为最终结果返回,如果不存在多数派数据, 则表示 RM 并未达成共识, 返回 nil。
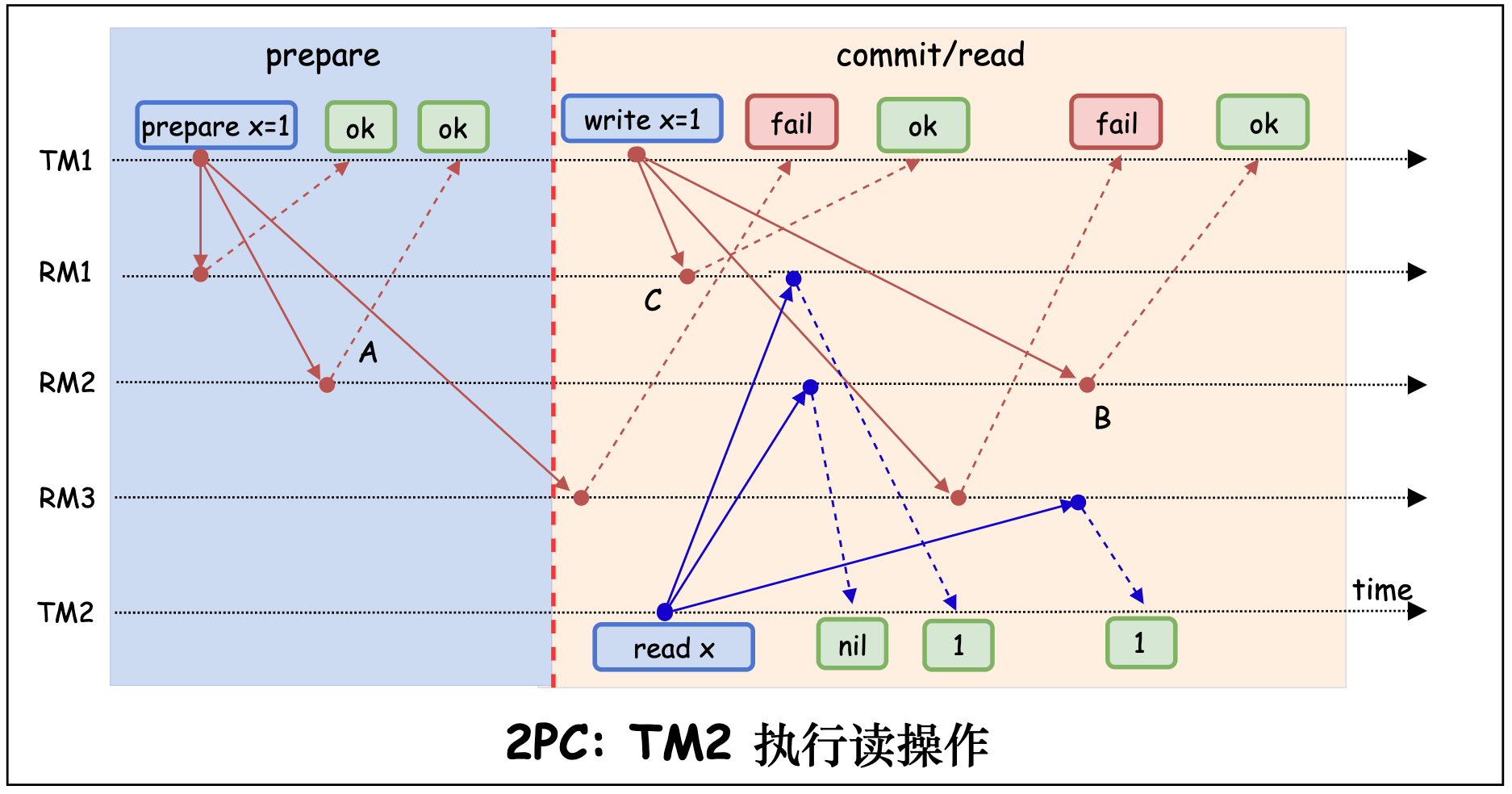
下图展示了 TM1 发起写操作 x=1, TM2 同时发起读操作 read x 的场景。TM2 最终读取到的数据为 x=1。
- Corner Case
-
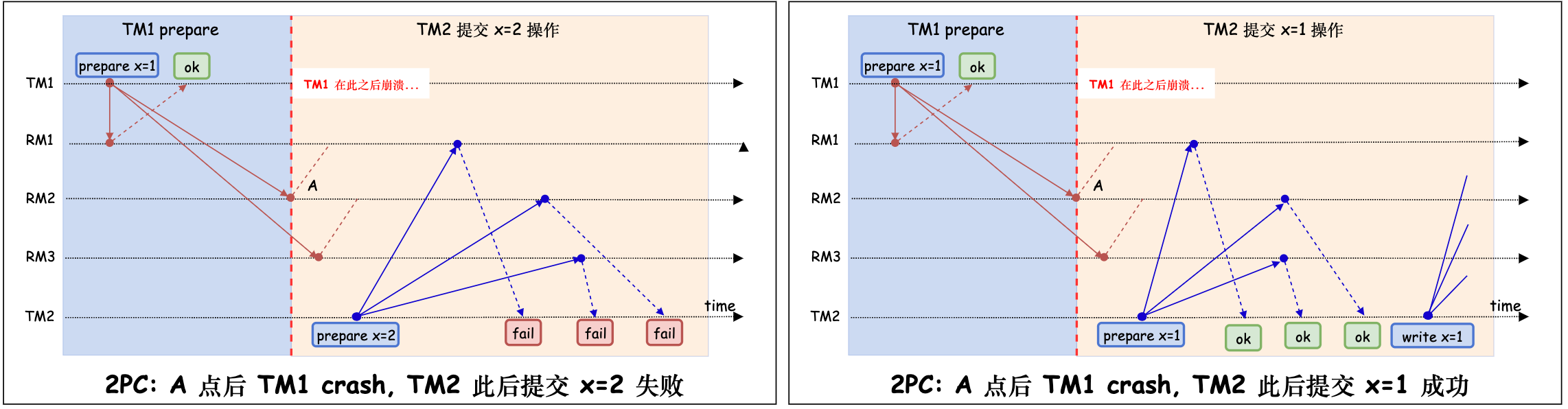
上图中, 如果 TM1 在点 A 时刻到点 B 时刻崩溃,其他 TM 虽然可以处理其他 key 的数据,但是 x 已经处于 prepare x=1 状态,其他 TM 只能发起 x=1 操作(而不能做其他处理)。如下图,TM2 发起 x=2 写操作失败,但是它发起 x=1 写操作成功。
-
如下图,如果存在三个 TM 对一个相同的 key 分别在三个不同的 RM prepare 了不同的 value, 则这个 key 将永远无法达成一致。
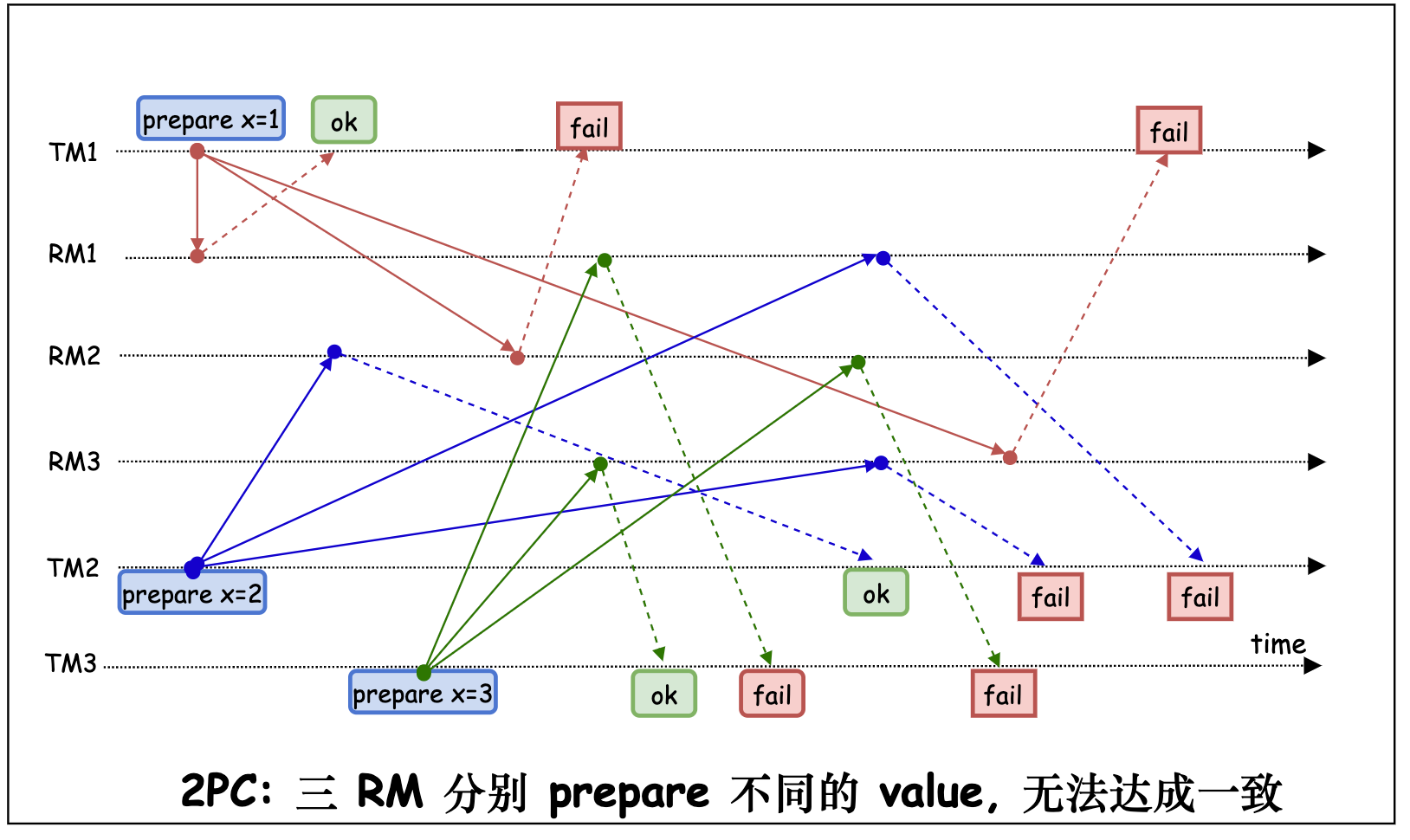
- Corner Case 的处理
- 点 A 时刻到点 B 时刻 TM1 崩溃: 后续的 prepare 可以覆盖前面的 prepare,但是需要通过 timestamp 来确定因果顺序(casual order)。
- Corner Case 2 也可由 Corner Case 1 的解决方案解决处理。
解密: paxos 算法“略解”
众里寻他千百度,蓦然回首,那人正在灯火阑珊处
paxos 算法共有两个角色: 负责发起写请求的 proposer 和负责达成共识的 acceptor。[5] [6] [7] [10] [11]
- 写操作流程
- proposer 指定一个 proposal number n, 向所有 acceptor 广播 prepare(n, key) 请求。其中 proposal number 的定义与 Quorum 算法提到的 timestamp 一致。
- acceptor 会将当前接收到的最大的 proposal number 记作 promise_number, acceptor 将会拒绝接受所有小于 promise_number 的 propose/prepare 请求。
- acceptor 接收到 prepare(n,key) 请求后, 如果 promise_numver < n, 则令 promise_number = n。向 proposer 返回当前 acceptor 已接收的 proposal number 和 value, promise_number。
- 当大多数 acceptor 都已成功接受 prepare 请求(promise_number = proposal_number):
- 如果响应均没有返回 accept proposal,则 proposer 发起 propose(n, key, value) 请求。
- 否则,令 value 等于响应中 accepted proposal number 最大的 accepted proposal value ,并发起 propose(n, key, value) 请求。
- 如果大多数 acceptor 都已拒绝 prepare 请求(promise_number > proposal_number),则令 n.version 等于 acceptor 返回的最大的 promise_number.version+1, 再次发起 prepare(n) 请求。
- 响应 propose(n, key, value) 请求:
- 如果 acceptor 的 promise_number 小于等于 n,则接受该值, 并且将 promise_number 置为 n,返回 promise_number
- 否则, 拒绝该 propose。返回 promise_number。
- 如果大多数已返回,且大多数 propose 被拒绝, 则令 n.version 等于 acceptor 返回的最大的 promise_number.version+1, 再次发起 prepare(n) 请求。否则, 大多数返回的 promise number 和 prepare 一致,value 已经写入成功。
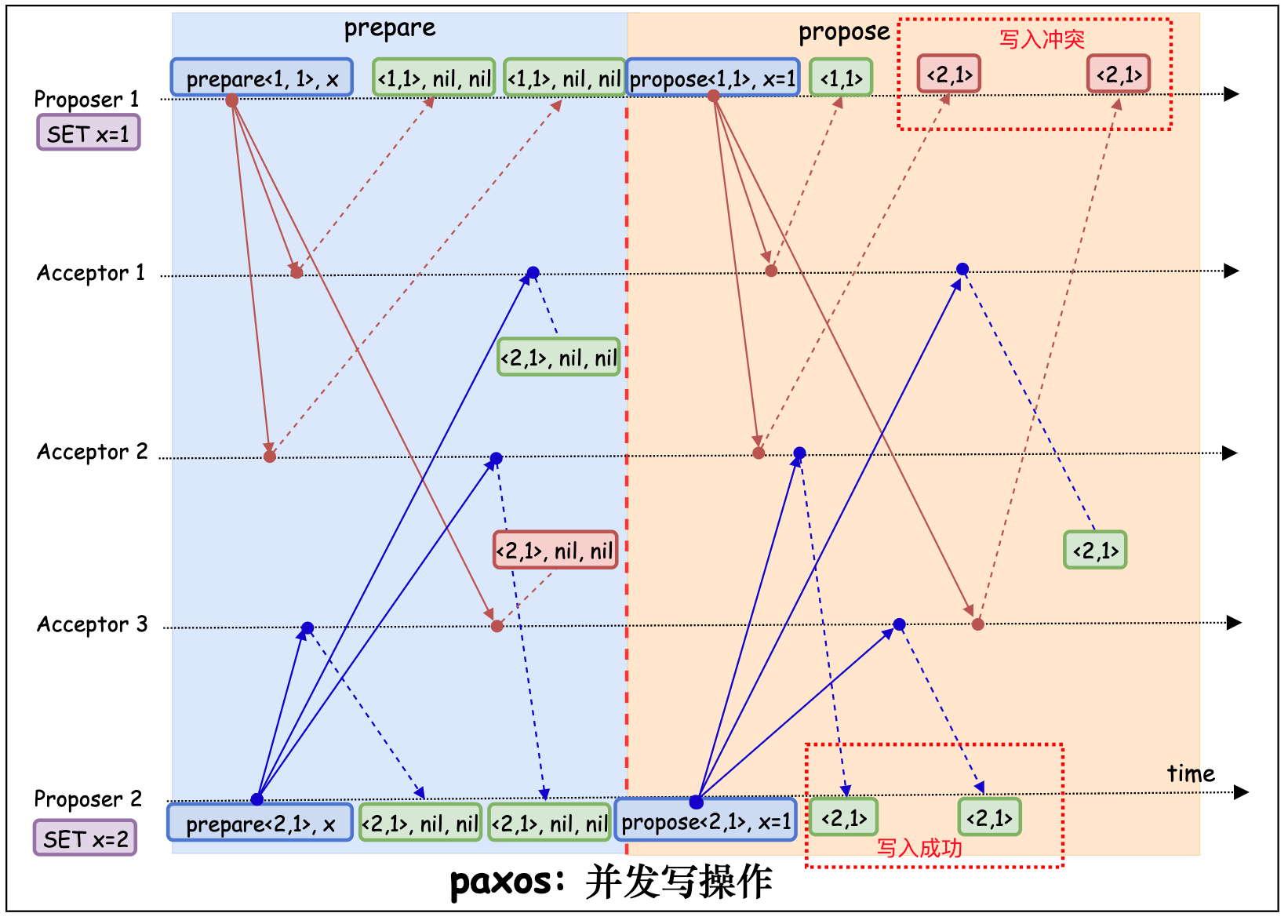
-
读操作流程: 与上一部分 2PC 的读操作流程一致。
-
live lock: paxos 算法在 prepare 阶段很容易出现 live lock 的情况,如图 Proposer1 和 Proposer2 反复的刷新 promise_number, 却谁都无法抢占先机。 一般有两种处理手段: 其一, Proposer 利用选主算法(可以是一次 paxos)+lease策略, 让集群中始终只有一个 Proposer 处于激活状态[11] [13]。其二, 每次可以随机等待一段时间, 再重试, 减少冲突发生的概率。[4]
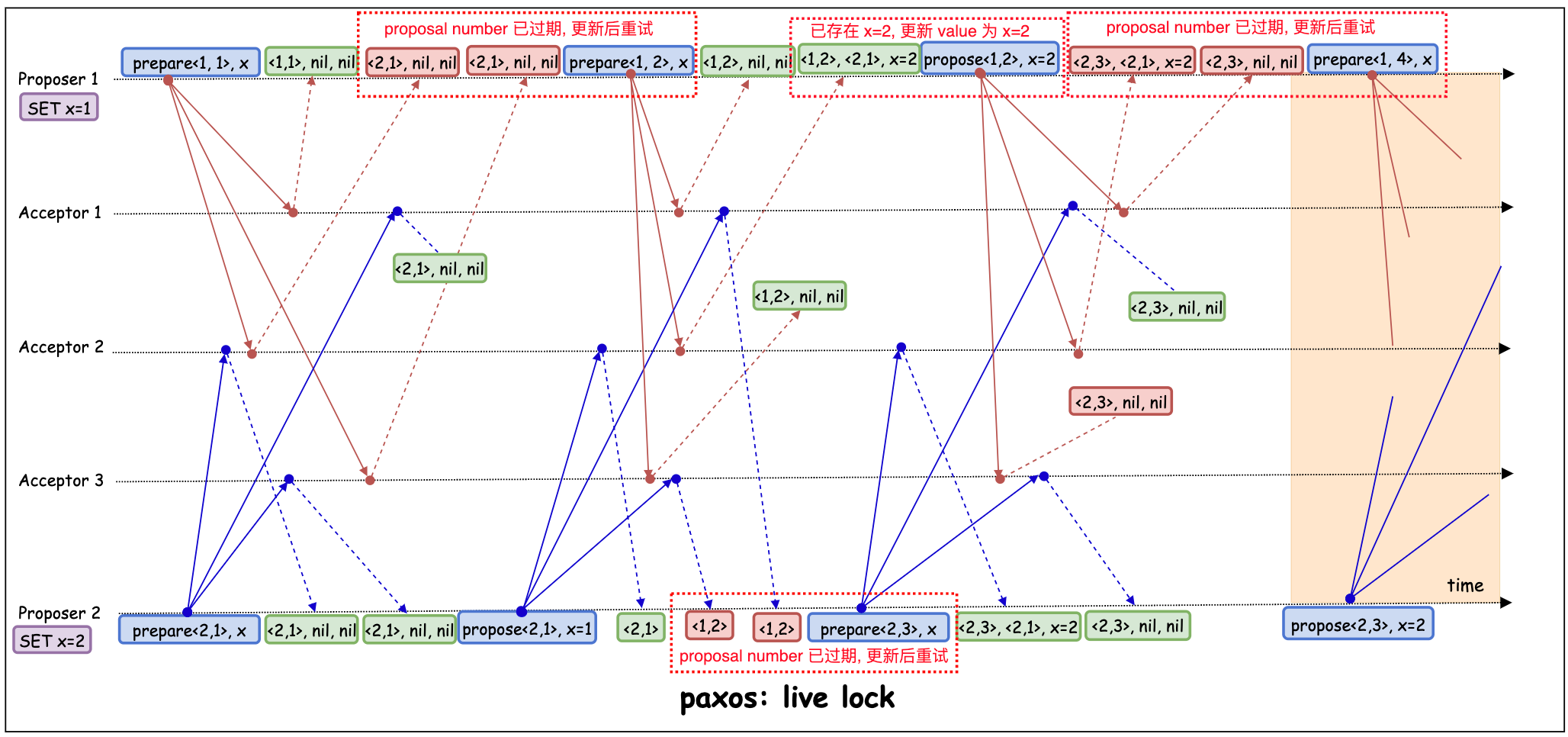
附录: 伪代码
Quorum
-
写请求

-
写响应

-
读请求

2PC(Two Phase Commit)
-
写请求

-
写响应

-
读请求

Paxos
-
写请求

-
写响应

-
读请求

参考文献
- [0] 本文所有绘图均使用 draw.io 绘制
- [1] Designing Data-Intensive Applications - by Martin Kleppmann
- [2] Implementing fault-tolerant services using the state machine approach: a tutorial
- [3] In Search of an Understandable Consensus Algorithm(Extended Version)
- [4] CONSENSUS: BRIDGING THEORY AND PRACTICE
- [5] Paxos Made Moderately Complex
- [6] Paxos Made Live - An Engineering Perspective
- [7] The Part-Time Parliament
- [8] DEFINING LIVENESS - Bowen ALPERN and Fred B. SCHNEIDER
- [9] Quorum Consensus - web.mit.edu/6.033
- [10] Paxos lecture (Raft user study)
- [11] Paxos Made Simple
- [12] How to Build a Highly Available System Using Consensus
- [13] Leases: An Efficient Fault-Tolerant Mechanism for Distributed File Cache Consistency
- [14] Consensus on Transaction Commit

