
词频统计
此作业的要求参见 https://edu.cnblogs.com/campus/nenu/2018fall/homework/2126
此作业的代码地址 https://git.coding.net/yanglei749/wordcount1.git
需求分析:
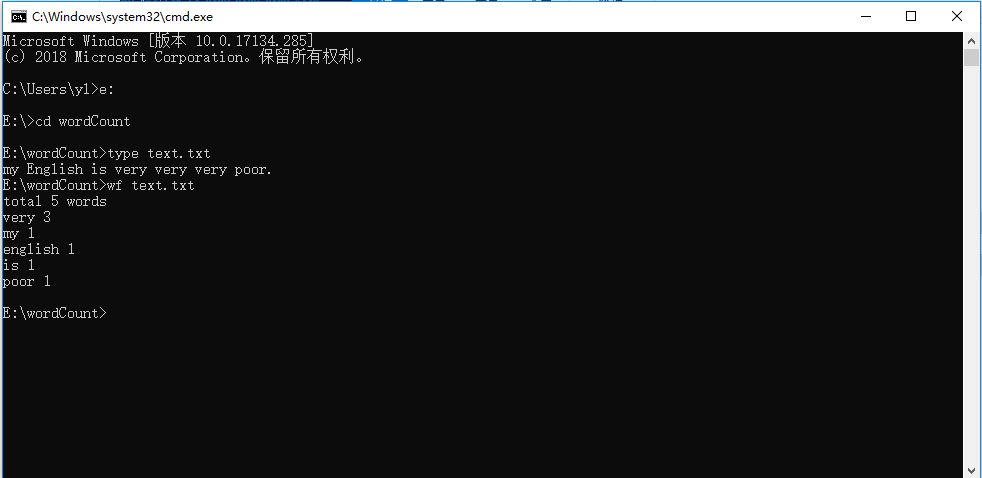
1、小文件输入。在控制台下输入命令,统计结果total项中相同单词不重复计数
2、支持命令行输入英文作品的文件名,统计每个单词出现的次数以及不同单词总数
3、支持命令行输入存储有英文作品文件的目录名,批量统计,并且列出出现次数最多的10个单词
4、从控制台读入英文单篇作品,进行重定向
功能实现:
1、此项目采用python语言进行编码,对文件进行读入操作,运用open方法
if __name__ == '__main__': filename = sys.argv[1] with open(filename, 'w+') as f: f.writelines(input())
2、对文件进行读取功能,提取文件中的每个单词,不包括如“,”等的特殊符号以及空格,这也是此功能的难点,尤其是在处理单引号和双引号这两个特殊符号时,最后我选择了用replace方法将单、双引号用空格代替去除,统计各种单词出现的频数以及不同单词的总数,从控制台读取目录名进行批量统计,按照出现的频数高低对单词进行排序,只列出出现次数最多的前十个单词
def wf(filename): with open(filename,encoding='utf8') as f: lines = f.readlines() d = {} for line in lines: line = re.split('[ "",$.?!;*#:-]', line.lower().replace("'",' ').replace('"',' ').replace("/",' ').replace("(",' ').replace(")",' ').strip('\n')) for word in line: if word == '': continue if word not in d: d[word] = 1 else: d[word] += 1 d_sorted = sorted(d.items(), key=lambda x: x[1], reverse=True) print('total', len(d_sorted), 'words') for i in range(min(len(d_sorted), 10)): print(d_sorted[i][0], d_sorted[i][1]) if __name__ == '__main__': if os.path.isfile(sys.argv[1]): wf(sys.argv[1]) elif os.path.isdir(sys.argv[1]): path = sys.argv[1] for file in os.listdir(sys.argv[1]): print(file) wf(os.path.join(path, file)) print('--------------------') else: print(sys.argv[1], 'is not a file or path')
功能测试效果截图:
1、小文件输入
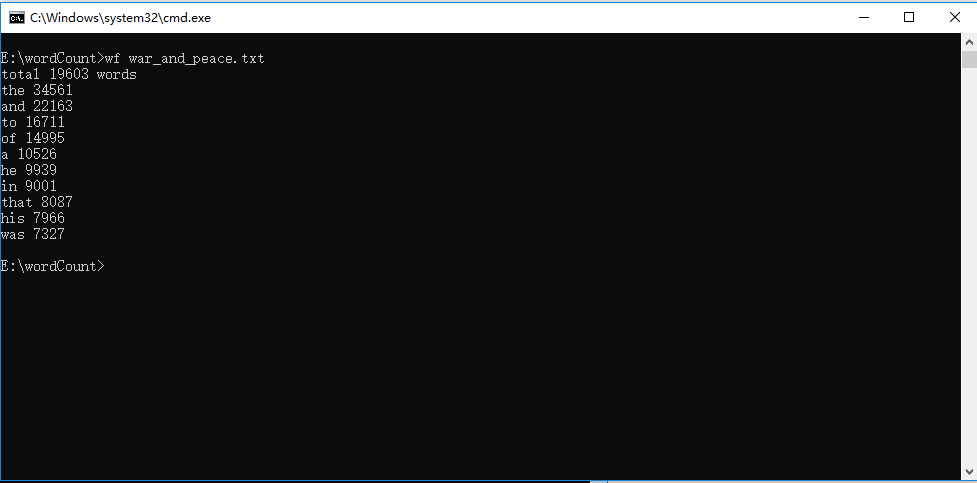
2、命令行输入英文作品的文件名
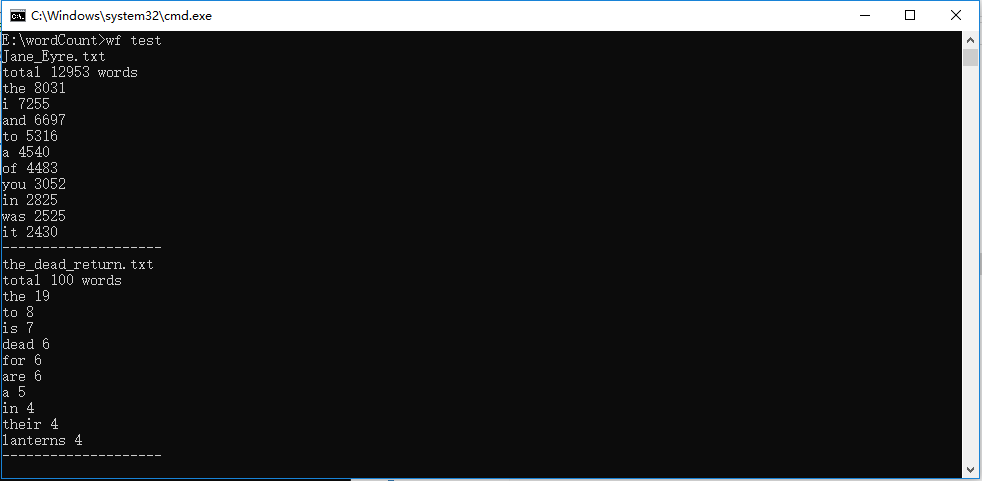
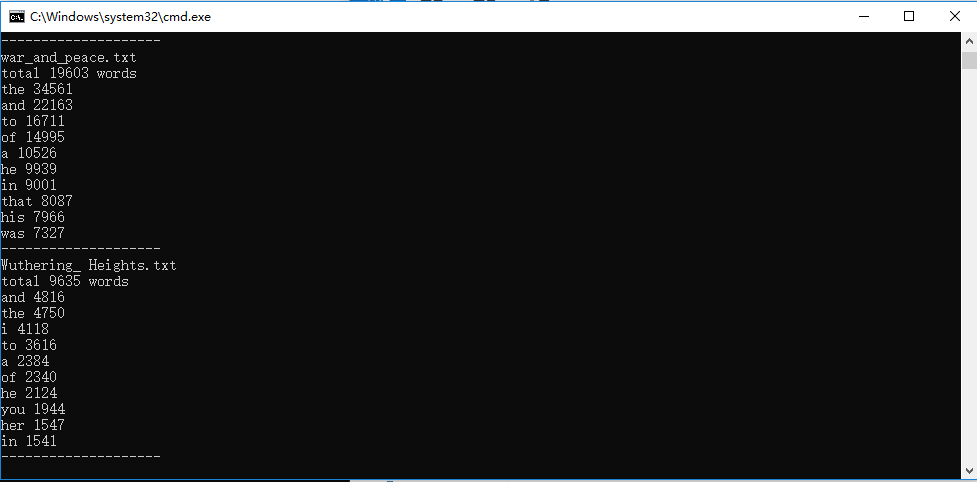
3、命令行输入存储有英文作品文件的目录名,批量统计,并且列出出现次数最多的10个单词
PSP表格:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号