
饮冰三年-人工智能-Python-37 爬虫之初窥门径
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本
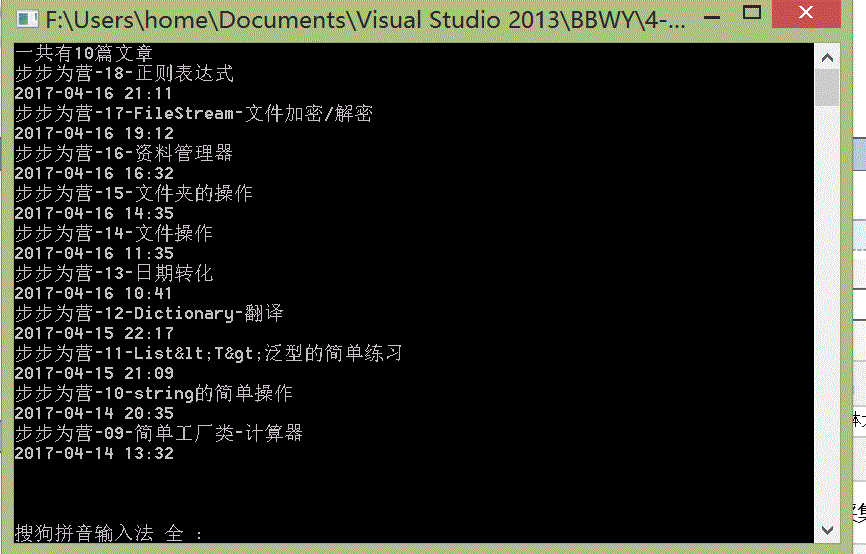
示例一:很早之前,用C#通过正则表达式写过一个小功能,就是获取自己写过的博客的数量以及标题和书写时间,现在我们用python来再次实现这个这个功能
https://www.cnblogs.com/YK2012/p/6722402.html


import requests from bs4 import BeautifulSoup for i in range(1,20): response = requests.get(url='http://www.cnblogs.com/YK2012/default.html?page='+str(i)) response.encoding = response.apparent_encoding soup = BeautifulSoup(response.text,features="html.parser") target = soup.find_all(name='div', attrs={"class":'day'}) for entity in target: title = entity.find('a','postTitle2') desc = entity.find('div', 'postDesc') print(title.text.strip(),desc.text[10:27])
中心思想:拿到网址,get请求,分析数据
示例二:自动登录GitHub,并获取项目信息
import requests from bs4 import BeautifulSoup import lxml from bs4.element import Tag # 1:访问登录页面,获取authenticity_token i1 = requests.get("https://github.com/login") soup1 = BeautifulSoup(i1.text, features='lxml') token = soup1.find(name='input', attrs={'name': 'authenticity_token'}) authenticity_token = token.get('value') ga_id = soup1.find(attrs={'name': 'octolytics-dimension-ga_id'}) c1 = i1.cookies.get_dict() i1.close() # print('令牌', authenticity_token) print(c1) # 2 拿掉令牌和用户名密码,发送用户验证 form_data = { "authenticity_token": authenticity_token, "utf8": "", "commit": "Sign in", "login": "1692134188@qq.com", 'password': '90opl;./()OPL:>?', 'ga_id': '470285644.1573810874', 'webauthn-support': ' supported', 'webauthn-iuvpaa-support': ' unsupported', 'required_field_3d5b': '', 'timestamp': '1573811914069', 'timestamp_secret': '2787f62a778139ef3be7fdea96b5f867e9e08b8976ecc07bb4869748d930cabd' } i2 = requests.post('https://github.com/session', data=form_data, cookies=c1) c2 = i2.cookies.get_dict() c1.update(c2) print('如果不出意外,这样就登录成功了!') i3 = requests.get('https://github.com/settings/repositories', cookies=c1) soup3 = BeautifulSoup(i3.text, features='lxml') list_group = soup3.find(name='div', class_='js-collaborated-repos') for child in list_group.children: if isinstance(child, Tag): project_tag = child.find(name='a', class_='mr-1') size_tag = child.find(name='span',class_='text-small') temp = "项目:%s(%s); 项目路径:%s" % (project_tag.get('href'), size_tag.get_text().strip()[0:8].strip(), project_tag.string, ) print(temp)
GitHub的小心机:登录的时候需要传递令牌。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号