第十周
学号 2019-2020-20182321 《数据结构与面向对象程序设计》第十周学习总结
教材学习内容总结
- 在计算机科学中,一个图就是一些顶点的集合,这些顶点通过一系列边结对(连接)。顶点用圆圈表示,边就是这些圆圈之间的连线。顶点之间通过边连接
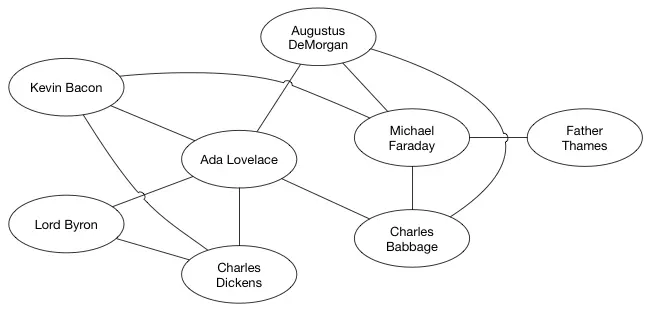
- 无向图的边是没有方向的,它只是单纯的节点和边之间的连接
- 有向图的边是有方向的,这就是它和无向图的区别
- 有向图图
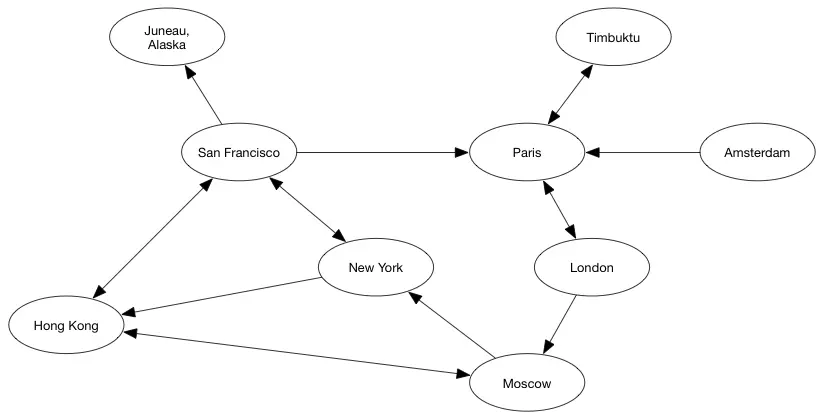
- 无向图图
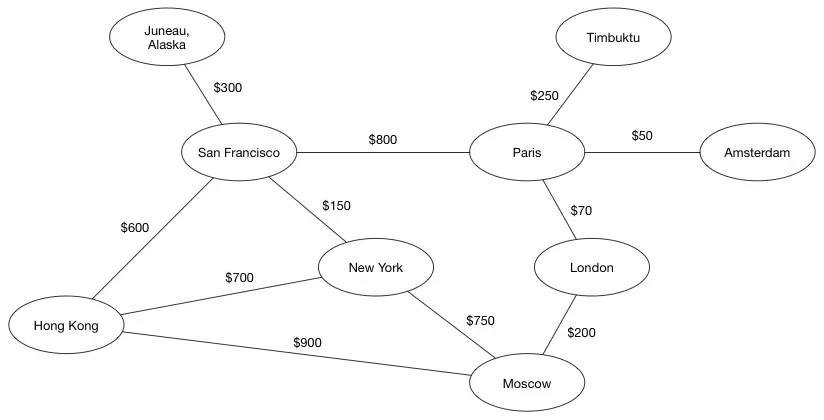
- 带权图就是每条边都有自己的权值的图(可以是无向的也可以是有向的)
- 图的遍历有两种,广度遍历还有深度遍历。
- 生成树是包含图中所有顶点及图中部分(可能不是全部)边的一棵树。因为数总是图,对于有些图来说,图本身就是一颗树,所以这样的图的生成树中将包含全部的边。而最小生成树是其所含边的权值之和小于等于图的任意其他生成树的边的权值之和的生成树。
- 邻接表,在邻接列表实现中,每一个顶点会存储一个从它这里开始的边的列表,如下图
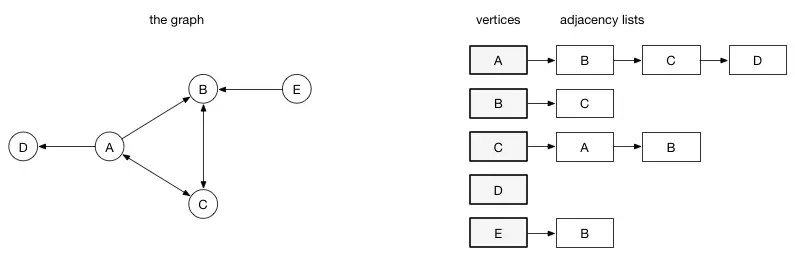
- 邻接矩阵,在邻接矩阵实现中,由行和列都表示顶点,由两个顶点所决定的矩阵对应元素表示这里两个顶点是否相连、如果相连这个值表示的是相连边的权重。

教材中遇到的问题和解决过程
- 问题1:如何判断最短路径?
- 问题1解决方法:
判断最短路径有两种方法
一、Dijkstra算法
规定一个 出发点,然后先初始化距离数组。数组中的每个下标就对应一个结点,每个数据项就是出发点到每个结点的距离。
1:将一个集合分为两部分,一个是已经找过的结点U,一个是没有找到过的v
2:在距离的数组中,没有访问过的结点中找一个权重最小的边,然后将这个结点添加到u中,并且以这个结点作为中间结点,来更新数组,判断条件是i到temp+temp到j 的距离是不是小于i到j的距离,若是,则就要更新。
3:直到u中的结点的个数=图中的结点的个数
算法的实现其实还是比较简单,和prim算法图的prim算法没什么差别,都是维护一个距离数组,来更新数组,不同的是只是添加一个判断条件而已。,在这里就没什么可说的,不懂的分析程序,运行结果一两遍就基本明白了
二、Floyd算法
Floyd算法(Floyd-Warshall algorithm)又称为弗洛伊德算法、插点法,是解决给定的加权图中顶点间的最短路径的一种算法,可以正确处理有向图或负权的最短路径问题,同时也被用于计算有向图的传递闭包。该算法名称以创始人之一、1978年图灵奖获得者、斯坦福大学计算机科学系教授罗伯特·弗洛伊德命名。
适用范围:无负权回路即可,边权可正可负,运行一次算法即可求得任意两点间最短路。
优缺点:
Floyd算法适用于APSP(AllPairsShortestPaths),是一种动态规划算法,稠密图效果最佳,边权可正可负。此算法简单有效,由于三重循环结构紧凑,对于稠密图,效率要高于执行|V|次Dijkstra算法。
优点:容易理解,可以算出任意两个节点之间的最短距离,代码编写简单
缺点:时间复杂度比较高,不适合计算大量数据。
时间复杂度:O(n3);空间复杂度:O(n2);
任意节点i到j的最短路径两种可能:
直接从i到j;
从i经过若干个节点k到j。
map(i,j)表示节点i到j最短路径的距离,对于每一个节点k,检查map(i,k)+map(k,j)小于map(i,j),如果成立,map(i,j) = map(i,k)+map(k,j);遍历每个k,每次更新的是除第k行和第k列的数。
步骤:
第1步:初始化map矩阵。
矩阵中map[i][j]的距离为顶点i到顶点j的权值;
如果i和j不相邻,则map[i][j]=∞。
如果i==j,则map[i][j]=0;
第2步:以顶点A(假设是第1个顶点)为中介点,若a[i][j] > a[i][1]+a[1][j],则设置a[i][j]=a[i][1]+a[1][j]。
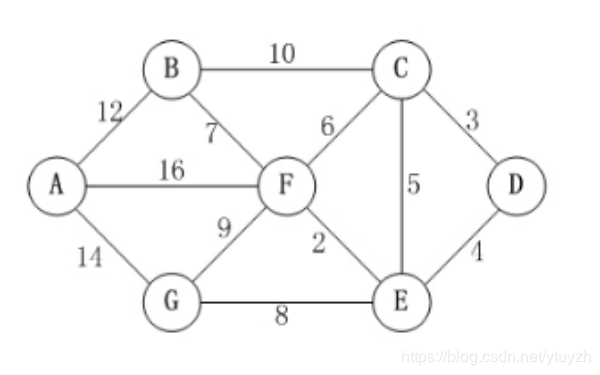
无向图构建最短路径长度邻接矩阵:
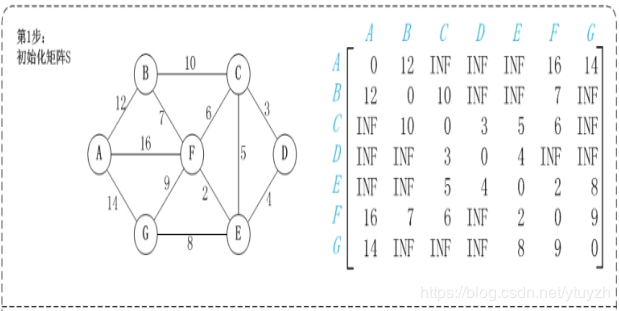
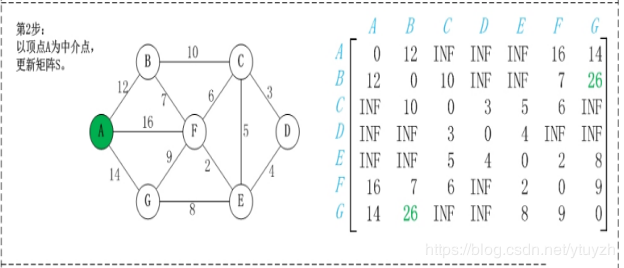
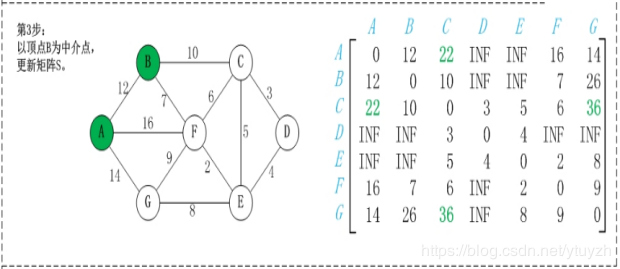

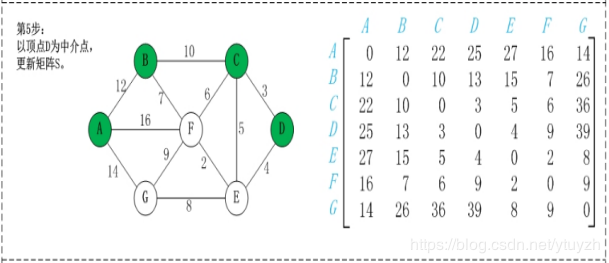
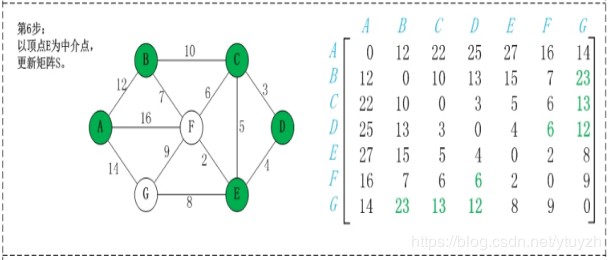
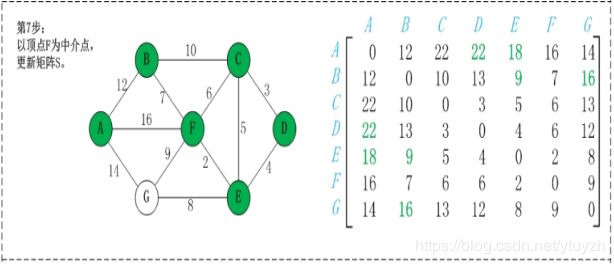
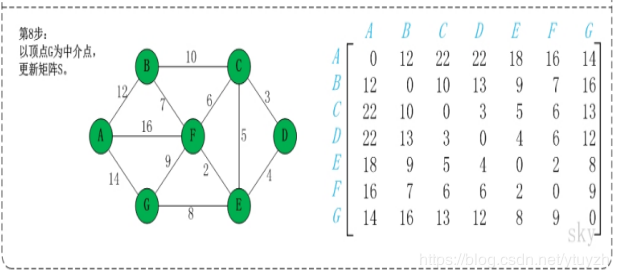
有向图构建最短路径长度邻接矩阵:
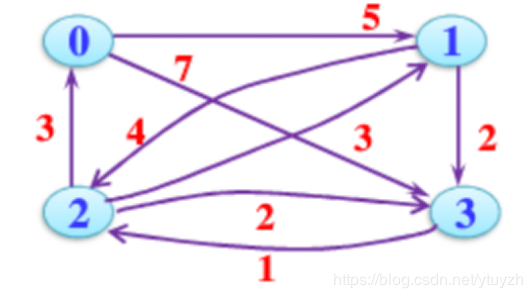
- 问题2:深度遍历和广度遍历的算法?
- 问题2解决方法:
一、深度遍历
沿着树的深度遍历结点,尽可能深的搜索树的分支。如果当前的节点所在的边都被搜索过,就回溯到当前节点所在的那条边的起始节点。一直重复直到进行到发现源节点所有可达的节点为止。
二、广度遍历
从根节点开始,沿着树的宽度遍历树的节点,直到所有节点都被遍历完为止。
- 问题3:什么是事件的最早发生时间和最晚发生时间
- 问题3解决方法:
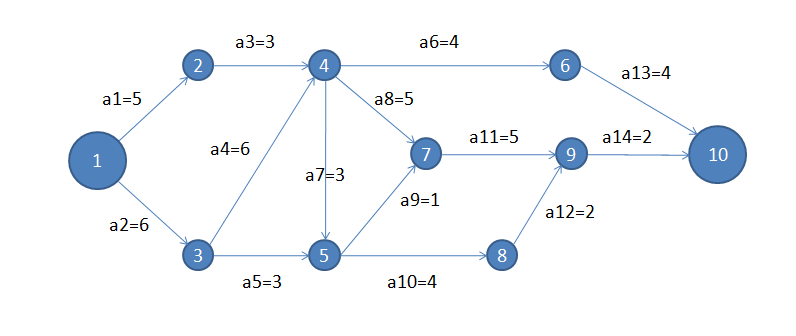
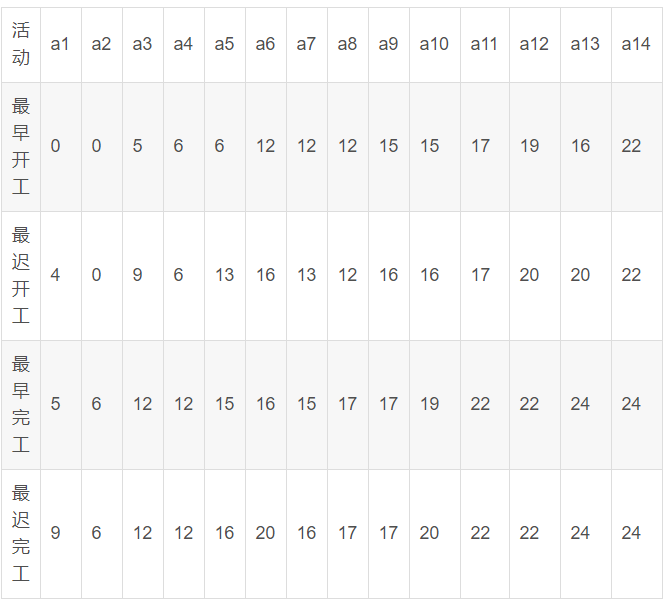
一、最早发生时间
从前往后,前驱结点到当前结点所需时间,取最大值。
如上图中的节点4有两个前驱结点(节点2和3),节点2到节点4的最早发生时间是a1+a3也就是8,节点3到节点4的最早发生时间是a2+a4也就是12,因为12>8,所以节点4的最早发生时间是12.
住:结束节点(10)的最早发生时间和最迟发生时间相同。
二、最迟发生时间
如上图中的节点9的最迟发生时间为其后继节点10(只有一个)的最迟发生时间减去a14即24-2=22.

三、最早开始时间:等于当前边起始结点的最早发生时间。
四、最晚开始时间:等于当前边指向结点的最迟发生时间-当前边的权值。
五、最早完工时间:等于当前边指向结点的最早发生时间。
七、最晚完工时间:等于当前边指向结点的最迟发生时间。
代码调试中的问题和解决过程
- 问题1:如何编写生成图的邻接矩阵
- 问题1解决方法:
建立起邻接矩阵的第一步是要先设置一个二维数组,利用二维数组来创建我们的邻接矩阵
以下是我的代码
//初始化矩阵
public Graph(int n) {
vertexList = new ArrayList<String>(n);
edges = new int[n][n];
numofEdges = 0;
this.n = n;
}
接着是插入每个边
public void InsertEdge(int v1, int v2, int weight) {
edges[v1][v2] = weight;
edges[v2][v1] = weight;
numofEdges++;
}
也有删除边
public void deleteEdge(int v1, int v2) {
edges[v1][v2] = 0;
numofEdges--;
}
还有计算出每个边的度
public int wuxiangdu(int a) {
int result = 0;
for (int i = 0; i < n; i++) {
result += edges[a][i];
}
return result;
}
而有向图的插入和无向图有些不一样
public void InsertEdge2(int v1, int v2, int weight) {
edges[v1][v2] = weight;
numofEdges++;
}
输出的度也不一样
public int youxiangtu(int a)
{
int result = 0;
for (int i = 0; i < n; i++) {
result += edges[a][i];
}
for(int i=0;i<n;i++)
{
result +=edges[i][a];
}
return result;
}
}
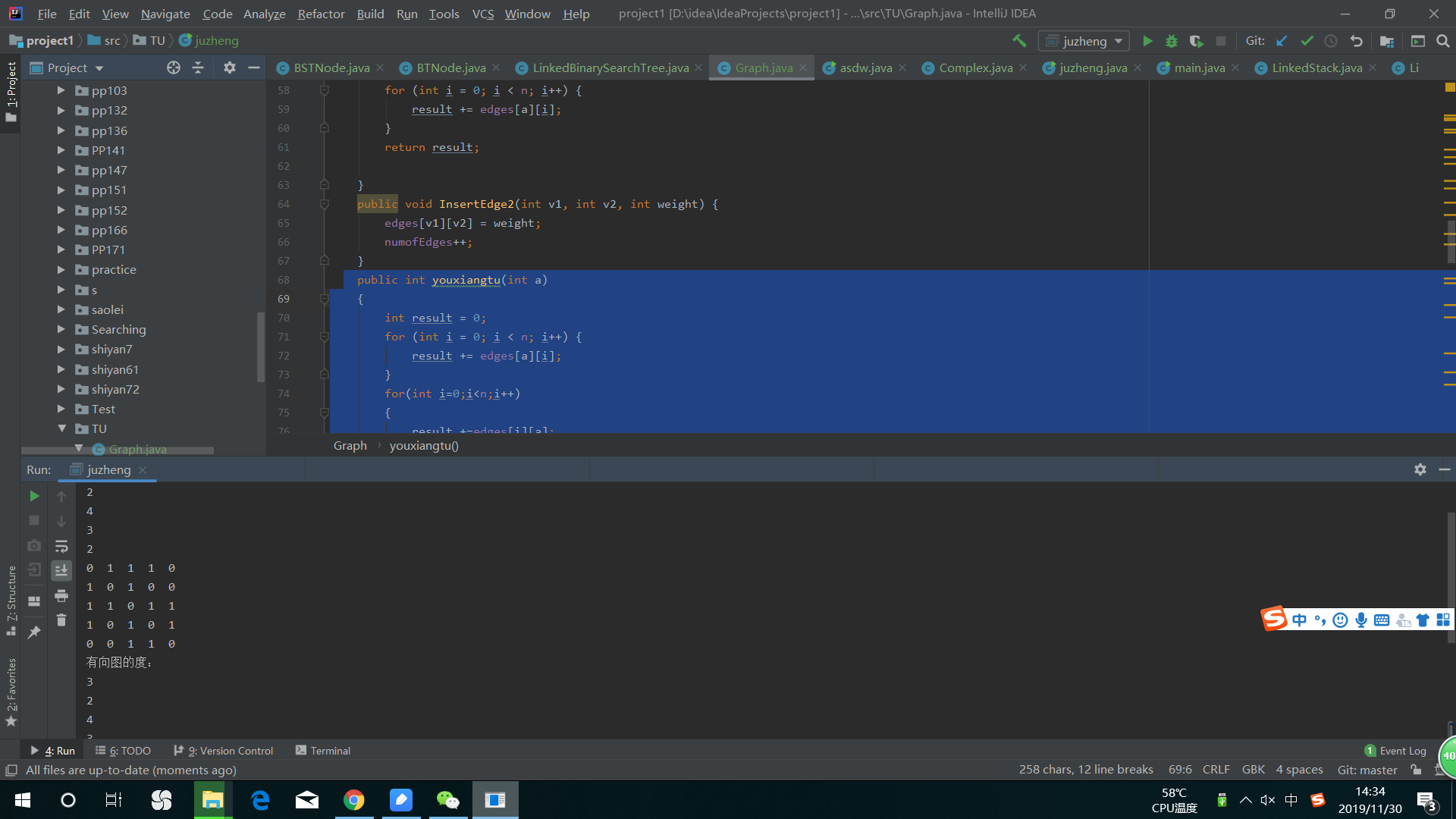
总的来说打出这个算法不是什么苦难事,运行截图如下
- 问题2:如何代码打出广度遍历和深度遍历
- 问题2解决方法:
在上面的基础上,我们进行编写广度遍历和深度遍历的方法,这两个方法用到了堆栈的方式来实现,以下给出代码
深度遍历
public String DFS(String startnode,ArrayList<String> vertexList,int [][]edges) {
if (!vertexList.contains(startnode)) {
System.out.print("输入节点不在该图内");
return null;
}
int startindex=vertexList.indexOf(startnode);
int numOfNodes=vertexList.size();
boolean[]visted=new boolean[numOfNodes];
StringBuilder resultBuilder=new StringBuilder();
Stack<Integer> stack=new Stack<Integer>();
stack.push(startindex);
visted[startindex]=true;
while (!stack.isEmpty()) {
int v=stack.pop();
resultBuilder.append(vertexList.get(v)+",");
for(int i=0;i<numOfNodes;i++)
{
//当edges【v】【i】的值不为0,不为最大,且没有被访问时,将其压入栈中
if((edges[v][i]!=0)&&(edges[v][i]!=Integer.MAX_VALUE)&&!visted[i])
{
stack.push(i);
visted[i]=true;
}
}
}
return resultBuilder.length()>0?resultBuilder.substring(0,resultBuilder.length()-1):null;
}
广度遍历
public String BFS(String startnode,ArrayList<String> vertexList,int [][]edges) {
if (!vertexList.contains(startnode)) {
System.out.print("输入节点不在该图内");
return null;
}
StringBuilder resultBuilder=new StringBuilder();
boolean []visited=new boolean[vertexList.size()];
int startIndex=vertexList.indexOf(startnode);
Queue<Integer>queue=new LinkedList<Integer>();
queue.offer(startIndex);
visited[startIndex]=true;
while (!queue.isEmpty()) {
int v=queue.poll();
resultBuilder.append(vertexList.get(v)+",");
for(int i=0;i<vertexList.size();i++)
{
if((edges[v][i]!=0) &&( edges[v][i]!=Integer.MAX_VALUE)&&!visited[i])
{
queue.offer(i);
visited[i]=true;
}
}
}
return resultBuilder.length()>0?resultBuilder.substring(0,resultBuilder.length()-1):null;
}
- 问题3:实现迪杰斯特拉算法
- 问题3解决方法:
一、算法思想
Dijkstra算法是最短路径算法中为人熟知的一种,是单起点全路径算法。该算法被称为是“贪心算法”的成功典范。
1、令G = (V,E)为一个带权无向图。G中若有两个相邻的节点,i和j。aij(在这及其后面都表示为下标,请注意)为节点i到节点j的权值,在本算法可以理解为距离。每个节点都有一个值di(节点标记)表示其从起点到它的某条路的距离。
2、算法初始有一个数组V用于储存未访问节点的列表,我们暂称为候选列表。选定节点1为起始节点。开始时,节点1的d1=0, 其他节点di=无穷大,V为所有节点。
初始化条件后,然后开始迭代算法,直到V为空集时停止。具体迭代步骤如下:
将d值最小的节点di从候选列表中移除。(本例中V的数据结构采用的是优先队列实现最小值出列,最好使用斐波那契对,在以前文章有过介绍,性能有大幅提示)。对于以该节点为起点的每一条边,不包括移除V的节点, (i, j)属于A, 若dj > di + aij(违反松弛条件),则令
dj = di + aij , (如果j已经从V中移除过,说明其最小距离已经计算出,不参与此次计算)
可以看到在算法的运算工程中,节点的d值是单调不增的。
代码如下
public class Dijkstra {
class Item
{ String endString;
ArrayList<String>lujingArrayList=new ArrayList<String>();
int distance;
}
public void GetShortWay(Graph graph,String startpoint,String endpoint) {
int startindex=graph.vertexList.indexOf(startpoint);
ArrayList<Item>Sarray=new ArrayList<Dijkstra.Item>();//S列表中存已知最短路径的对象,U列表中存未知最短路径的对象
ArrayList<Item>Uarray=new ArrayList<Dijkstra.Item>();//S列表中存已知最短路径的对象,U列表中存未知最短路径的对象
//初始化U列表
for(int i=0;i<graph.getNumofVertex();i++)
{
Item tempItem=new Item();
tempItem.endString=graph.vertexList.get(i);
tempItem.lujingArrayList.add(graph.vertexList.get(startindex));
tempItem.lujingArrayList.add(graph.vertexList.get(i));
tempItem.distance=graph.edges[startindex][i];
Uarray.add(tempItem);
}
while (!Uarray.isEmpty()) {
int t=0;
int tempdistance=Uarray.get(0).distance;
for(int i=0;i<Uarray.size();i++)
{
if(tempdistance>Uarray.get(i).distance)
{
t=i;
tempdistance=Uarray.get(i).distance;
}
}
Sarray.add(Uarray.remove(t));
for(int i=0;i<Uarray.size();i++)
{
int index1=graph.vertexList.indexOf(Uarray.get(i).endString);
for(int j=0;j<Sarray.size();j++)
{
int index2=graph.vertexList.indexOf(Sarray.get(j).lujingArrayList.get(Sarray.get(j).lujingArrayList.size()-1));
if(graph.edges[index1][index2]==Integer.MAX_VALUE)
{
continue;
}
else {
int newdistance=Sarray.get(j).distance+graph.edges[index1][index2];
if(newdistance<Uarray.get(i).distance)
{
Uarray.get(i).distance=newdistance;
Uarray.get(i).lujingArrayList=new ArrayList<String>( Sarray.get(j).lujingArrayList);
Uarray.get(i).lujingArrayList.add(graph.vertexList.get(index1));
}
}
}
}
}
for(int i=0;i<Sarray.size();i++)
{
System.out.print( startpoint+"-->"+Sarray.get(i).endString+"的最短路径为:");
for(int j=0;j<Sarray.get(i).lujingArrayList.size();j++)
{System.out.print( Sarray.get(i).lujingArrayList.get(j)+" ");}
System.out.println("长度为:"+ Sarray.get(i).distance);
}
}
}
代码托管
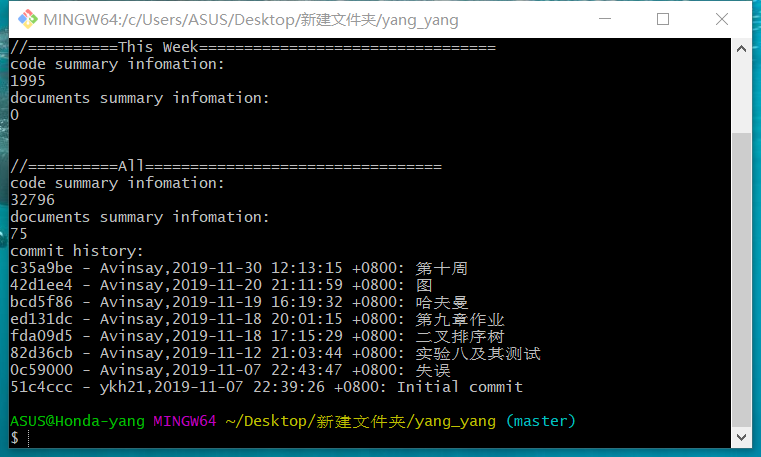
(statistics.sh脚本的运行结果截图)
上周考试错题总结
上周无考试
- 上周博客互评情况
- 20182334
- 结对照片
![]()
其他(感悟、思考等,可选)
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 200/200 | 2/2 | 20/20 | |
| 第二周 | 300/500 | 2/4 | 18/38 | |
| 第三周 | 623/1000 | 3/7 | 22/60 | |
| 第四周 | 600/1600 | 2/9 | 22/82 | |
| 第五周 | 1552/2987 | 2/11 | 22/94 | |
| 第六周 | 892/3879 | 2/11 | 22/114 | |
| 第七周 | 2284/6163 | 2/13 | 22/134 | |
| 第八周 | 2284/6163 | 2/13 | 22/156 | |
| 第九周 | 24118/30281 | 2/15 | 40/196 | |
| 第十周 | 1995/32796 | 2/17 | 40/236 |
-
计划学习时间:10小时
-
实际学习时间:40小时
-
改进情况:
(有空多看看现代软件工程 课件
软件工程师能力自我评价表)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号