哈夫曼
学号 2019-2020-20182321 《数据结构与面向对象程序设计》哈夫曼算法
实践过程
构建哈夫曼树
1.将所有带权值的结点按权值从小到大排列(这里的权值我们用每个字符出现的概率来代替);
2.依次选取权值最小的结点放在树的底部,权值小的在左边(取出的结点相当于从这些结点的集合中剔除);
3.生成一个新节点作为这两个结点的父节点,且父节点的权值等于这两个结点权值之和,然后要把这个新结点放回我们需要构成树的结点中,继续进行排序;
4.重复上述2、3步骤,直至全部节点形成一棵树,此树便是哈夫曼树,最后生成的结点即为根节点。这样构成的哈夫曼树,所有的存储有信息的结点都在叶子结点上。

核心代码如下
Node createTree(List<Node> nodes) {
// 只要nodes数组中还有2个以上的节点
while (nodes.size() > 1) {
quickSort(nodes);
//获取权值最小的两个节点
Node left = nodes.get(nodes.size() - 1);
Node right = nodes.get(nodes.size() - 2);
//生成新节点,新节点的权值为两个子节点的权值之和
Node parent = new Node(null, left.weight + right.weight);
//让新节点作为两个权值最小节点的父节点
parent.leftChild = left;
parent.rightChild = right;
//删除权值最小的两个节点
nodes.remove(nodes.size() - 1);
nodes.remove(nodes.size() - 1);
//将新节点加入到集合中
nodes.add(parent);
}
return nodes.get(0);
给每个字母编码
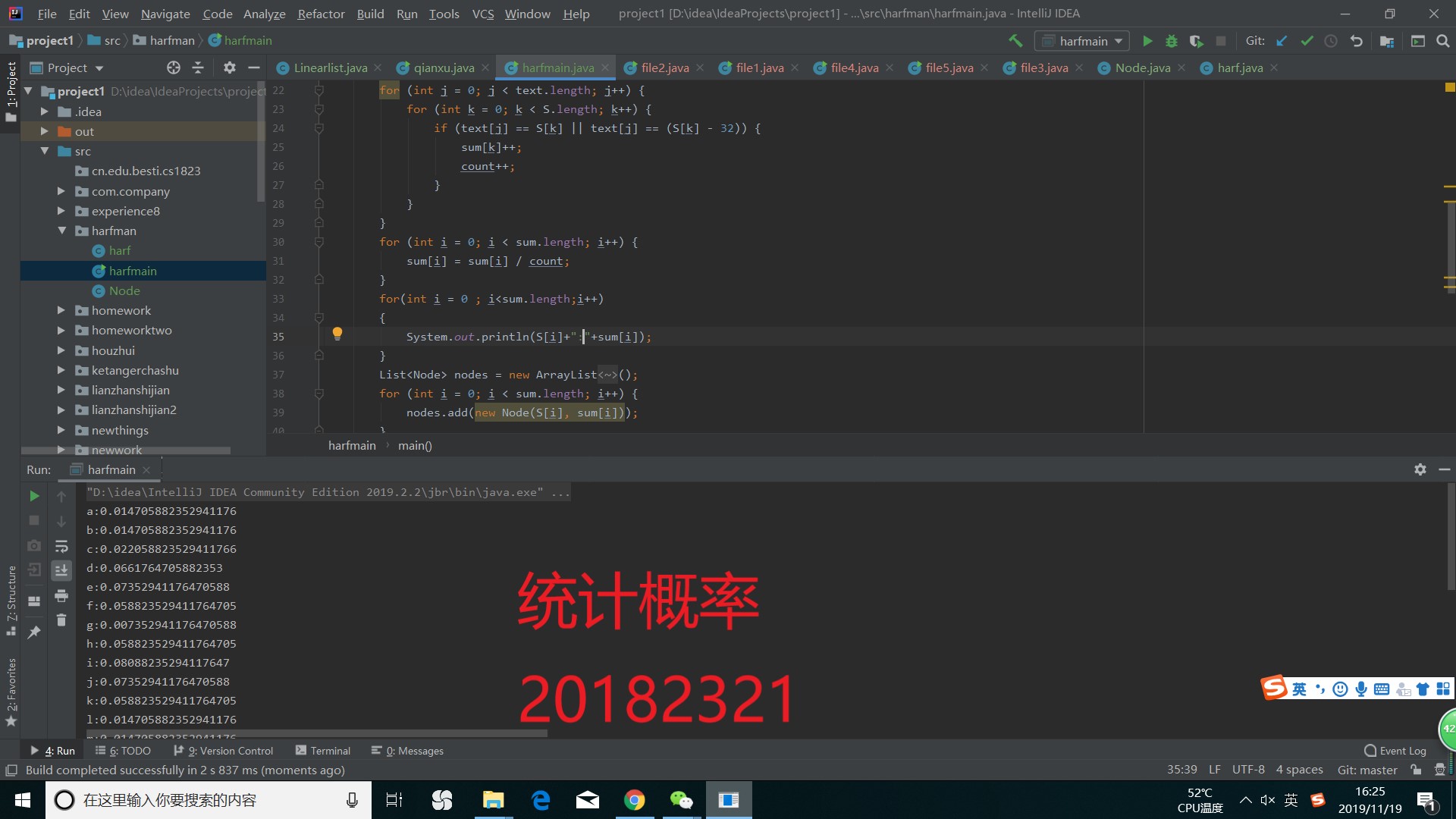
构造成哈夫曼树之后,从根节点出发,左子树为0,右子树为1,将0,1串联在一起,直到叶子节点为止,这个就是字母的编码。再将编码写进我们节点中的code量里。
如下图

核心代码如下
节点类
public class Node<E> {
E data;
public String code = "";
double weight;
Node leftChild;
Node rightChild;
public Node(E data, double weight) {
super();
this.data = data;
this.weight = weight;
}
}
public void setCode(Node root) {
if (root.leftChild != null) {
root.leftChild.code = root.code + "0";
setCode(root.leftChild);
}
if (root.rightChild != null) {
root.rightChild.code = root.code + "1";
setCode(root.rightChild);
}
}
运行结果如图
给文件加密编码
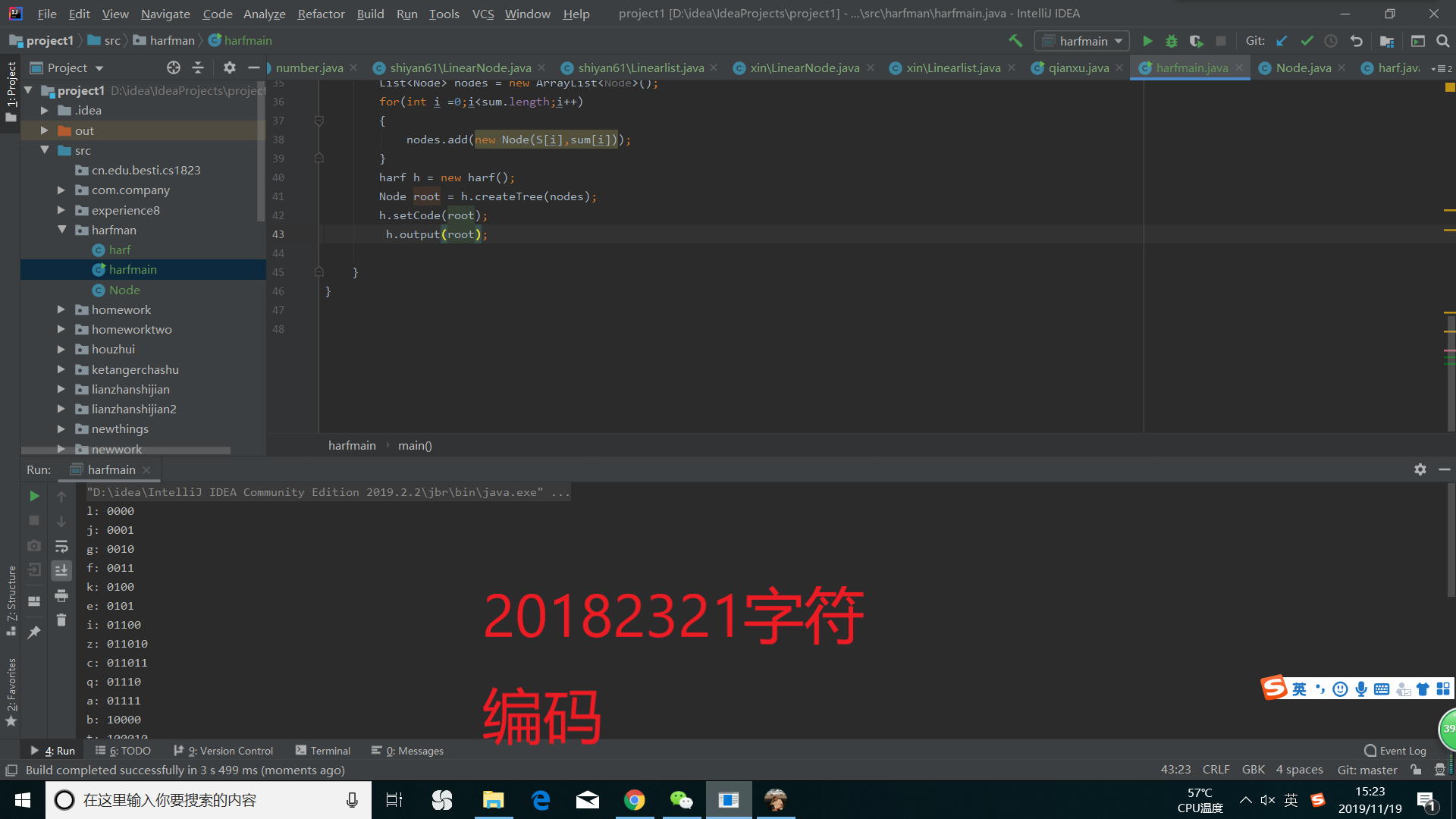
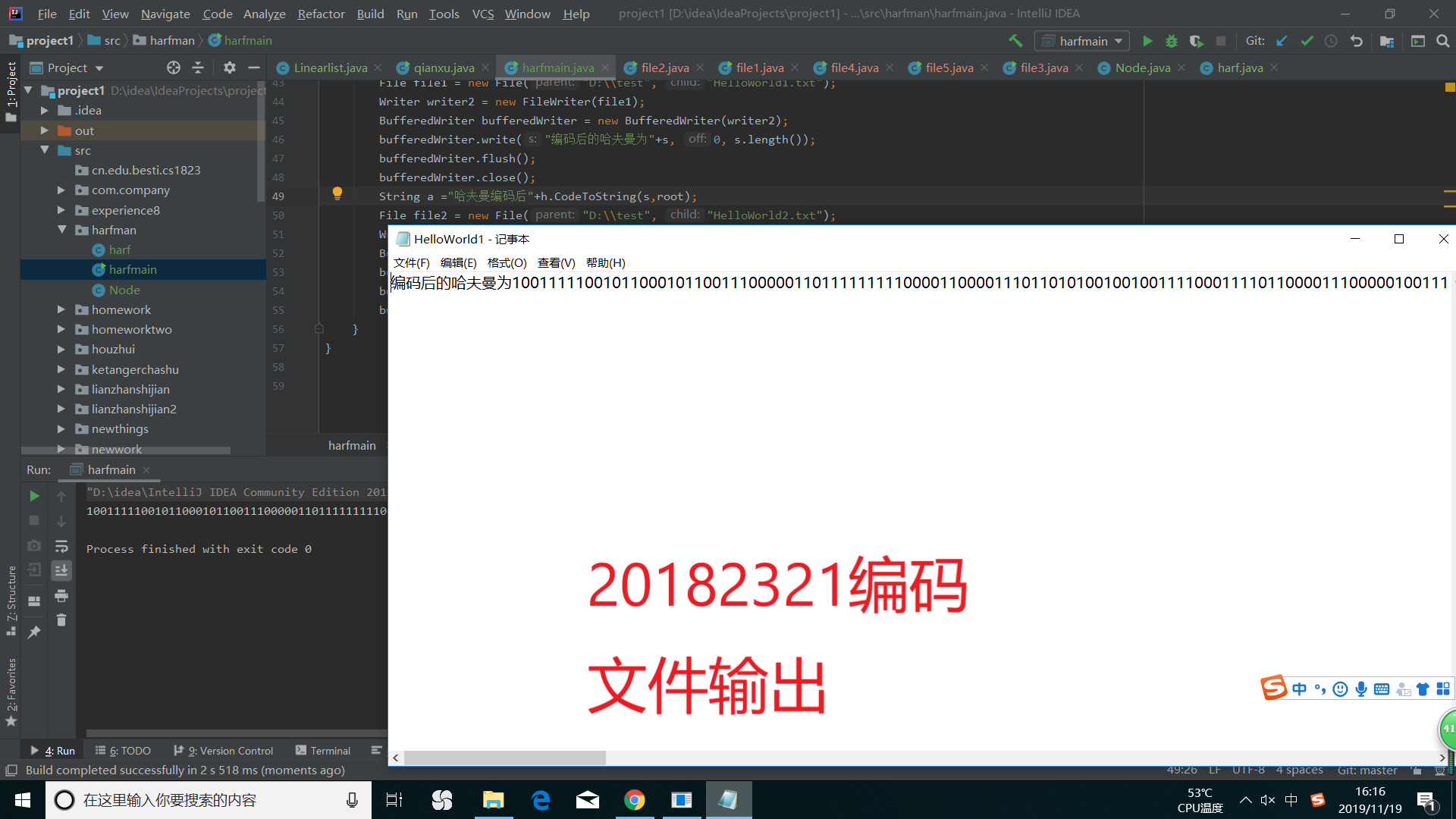
我们按字符读取文件里面的内容后,再转换成字符串,一个一个的放进哈夫曼树里进行差找,相对应的字符(即找到相对应的叶子节点),将叶子节点的code变量(即单个字符的编码),放入输出的字符串中,最后输出。
核心代码如下
private String hfmCodeStr = "";// 哈夫曼编码连接成的字符串
/**
* 编码
*/
public String toHufmCode(String str,Node root) {
for (int i = 0; i < str.length(); i++) {
char c = str.charAt(i) ;
search(root, c);
}
return hfmCodeStr;
}
private void search(Node root, char c) {
if (root.leftChild == null && root.rightChild == null) {
if (c == (char)root.data) {
hfmCodeStr += root.code; // 找到字符,将其哈夫曼编码拼接到最终返回二进制字符串的后面
}
}
if (root.leftChild != null) {
search(root.leftChild, c);
}
if (root.rightChild != null) {
search(root.rightChild, c);
}
}
运行成功后截图
给文件解密
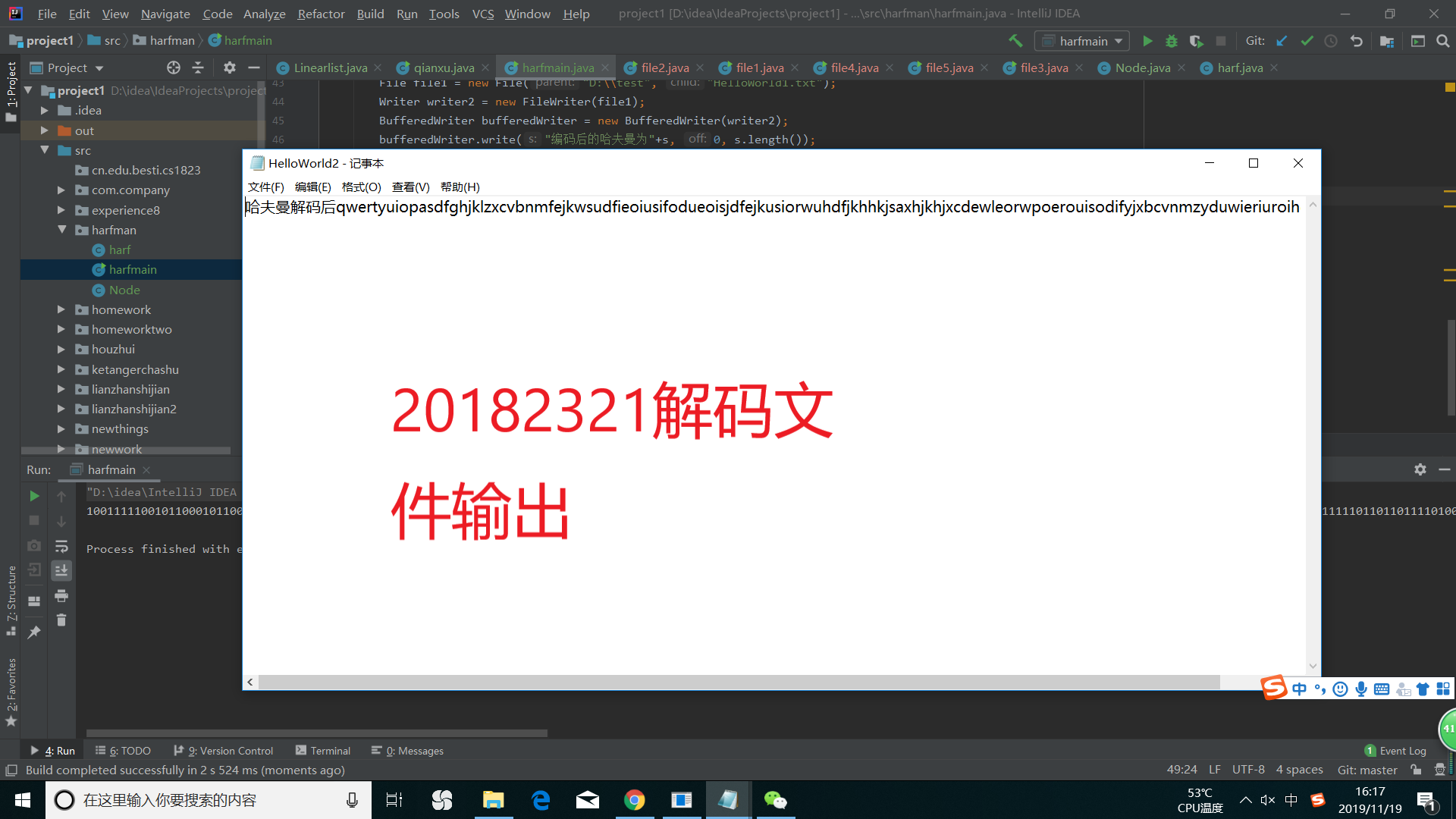
解密的话就不用读取文件了,将之前的加密的字符串拿来,这时候我们设置两个指针,一个start,一个end,表示一个哈夫曼码的长度,比如哈夫曼编码为1001,我初始start为0,end为1,截取1001的前两位,即10,然后查找字母表,看看有没有编码为10的字母,如果没有,那end++,查找有没有编码为100的字母,如果还没有,再end++,找到了1001的字母为a(假设),接着就输出字符a,然后把start指针指向end指针的位置,再重复前面的步骤来进行解码,核心代码如下:
String result="";
boolean target = false; // 解码标记
public String CodeToString(String codeStr,Node root) {
int start = 0;
int end = 1;
while(end <= codeStr.length()){
target = false;
String s = codeStr.substring(start, end);
matchCode(root, s); // 解码
// 每解码一个字符,start向后移
if(target){
start = end;
}
end++;
}
return result;
}
private void matchCode(Node root, String code){
if (root.leftChild == null && root.rightChild == null) {
if (code.equals(root.code)) {
result += root.data; // 找到对应的字符,拼接到解码字符穿后
target = true; // 标志置为true
}
}
if (root.leftChild != null) {
matchCode(root.leftChild, code);
}
if (root.rightChild != null) {
matchCode(root.rightChild, code);
}
}
运行结果如下

 浙公网安备 33010602011771号
浙公网安备 33010602011771号