

day6——Python数据类型
e)列表,列表用[]表示
在Python中,最基本的数据结构是序列(sequence)。序列中的每个元素被分配一个序号——即元素的位置,也称为索引。第一个索引是 0,第二个则是 1,以此类推。序列中的最后一个元素标记为 -1,倒数第二个元素为 -2,依次类推。 列表是由序列特定顺序排列的元素组成的,可以是字符串、数字、字典等,它们的元素可以有很多个。
Python包含 6 中内建的序列,包括列表、元组、字符串、Unicode字符串、buffer对象和xrange对象。列表和元组的主要区别在于,列表可以修改,元组则不能。
所有序列类型都可以进行某些特定的操作。这些操作包括:索引(indexing)、分片(sliceing)、加(adding)、乘(multiplying)以及检查某个元素是否属于序列的成员(成员资格)。除此之外,Python还有计算序列长度、找出最大元素和最小元素的内建函数。
str1 = 'dsfjasdfalsdf'
print(list(str1)) #每个元素都是字符
print(type(str1))
a = ['a','b','c',123]
print(a)
print (type(a)) #查看类型为list类型
print(dir(a)) #查看a属性的方法
返回结果为:

方法:['append', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort']
append:用于在列表list的末尾追加新的元素(对象)。
语法:""" L.append(object) -- append object to end """
print(a)
a.append('hello')
print(a)
返回结果为:

index:检测字符串中是否包含子字符串 str ,如果指定 start(开始) 和 stop(结束) 范围,则检查是否包含在指定范围内,该方法与 python find()方法一样,只不过如果str不在 string中会报一个异常,查找字符所在的下标位置。
语法:L.index(value, [start, [stop]]) -> integer -- return first index of value.
参数:str -- 指定检索的字符串
start -- 开始索引,默认为0。
stop -- 结束索引,默认为字符串的长度。
print(a)
print(a.index('abc'))
返回结果为:

insert:用于将指定对象插入列表的指定位置。
语法:L.insert(index, object) -- insert object before index
a.insert(0,'yjb') #在0下标的位置插入yjb
print(a)
a.insert(3,'adasdfdasf')
print(a)
返回结果为:

pop:用于移除列表中的一个元素(默认最后一个元素),并且返回该元素的值。
语法:L.pop([index]) -> item -- remove and return item at index (default last).
print(a)
print(a.pop()) #删除末位list元素
print(a)
返回结果为:
remove:用于移除列表list中某个值的第一个匹配项。
语法:L.remove(value) -- remove first occurrence of value.
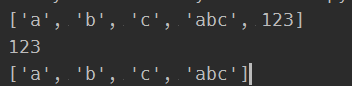
print(a)
a.remove('abc')
print(a)
返回结果为:
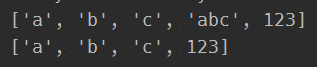
print(a)
a.remove('abc')
print(a)
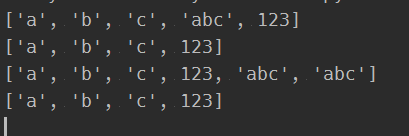
a.append('abc')
a.append('abc')
print(a)
a.remove('abc')
a.remove('abc') #如果要删除多个一样的元素,需要写多个删除
print(a)
返回结果为:
sort:用于对原列表进行排序,如果指定参数,则使用比较函数指定的比较函数(可以定义自己的比较函数)。
语法:L.sort(cmp=None, key=None, reverse=False) -- stable sort *IN PLACE*;
print(a)
a.sort() #正序排序
print(a)
返回结果为:

reverse:用于反向列表中元素。list反序(降序)
语法:L.reverse() -- reverse *IN PLACE*
print(a)
a.reverse() #反序排序
print(a)
返回结果为:

列表切片:
字符串、列表、元组在Python中都符合“序列”这一特征,只要符合这一特征的变量我们都可以用切片(slice)去存取它们的任意部分。我们可以把序列想像成一个队列,我们可能需要前面三位、后面三位、或从第三位后的四位、或隔一个取一个等,我们用切片操作符来实现上述要求
切片操作符在Python中的原型是:
[start:stop:step]
即:[开始索引:结束索引:步长值]
开始索引:同其它语言一样,从0开始,序列从左向右方向中,第一值的索引为0,最后一个为-1
结束索引:切片操作符将取到该索引为止,不包含该索引的值
步长值:默认是一个接着一个切取,如果为2,则表示进行隔一取一操作,步长值为正时表示从左向右取,如果为负,则表示从右向左取,步长值不能为0
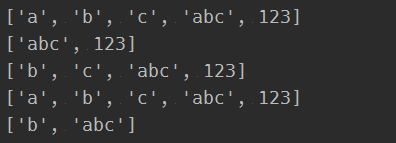
print(a)
print(a[3:])
print(a[1:5])
#下标从1打印到5,注意,切片的时候,取的最后一位数字-1
print(a)
print(a[1:5:2]) #隔几个取,默认隔1个
返回结果为:
e)元组
tuple(元组)就是不可变的list,但是tuple还是和list有些差别
1.Tuple的定义形式
tuple唯一和list定义的区别就是[]变成了(),其他没有什么变化,tuple不能增加和减少里面的元素(不可增加或删除里面的元素),它本身自己的方法很少,只有count和index两个方法,其他的list方法都不可用
str1='abcdefg'
print(tuple(str1))
print(type(tuple(str1)))
返回结果为:

2.Tuple单个元素需要注意:
Tuple在表示单个元素的时候,元素后面要加逗号,否则Python解析器不会识别为tuple类型
m=('abcd')
print(type(m))
n=('abc',)
x=(123,)
print(type(n))
print(type(x))
打印结果为:
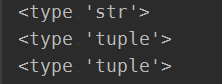
3.Tuple的方法:
x=(123,)
#tuple的方法
print(dir(x))
count:统计某个元素的个数
tu1=('a','b','c','a','d','a','c')
print(tu1.count('a'))
返回结果为:
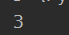
indext:返回某个元素的下标
tu1=('a','b','c','a','d','a','c')
print(tu1.index('d'))
打印结果为:

print(tu1.index('h'))
如果某个元素不存在,则直接报错

e)字典
字典是以key:value的形式,字典是另一种可变容器模型,且可存储任意类型对象
字典的每个键值(key=>value)对 用冒号(:)分割,每个对 之间用逗号(,)分割,整个字典包括在花括号{}中,字典赋值有三种方式:
1.字典赋值方式一:
k = {'name':'YJB','age':20,'sex':'man'}
print(k)
print(type(k))
返回结果为:

2.字典赋值方式二:
#list('abcdefg') 这是列表, tuple('hijkml') 这是元组形式,字典也可以直接用dict表示
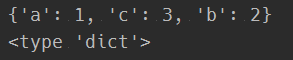
k1 = dict(a=1,b=2,c=3)
print(k1)
print(type(k1))
打印结果为:
3.字典赋值方式三(这种方法不常用):列表里面是元组的方式
d = dict([('name','YJB'),('age',28)]) #这里面是一个列表,先外面是一个dict函数,里面是一个列表 ,列表里面是两个元组,
print(d)
打印结果为:

字典常用的方法:
print(dir(d))
clear:清除字典里面的元素,不常用
print(k1)
k1.clear()
print(k1)
打印结果为:

get:获取Key值的Vlue
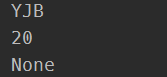
print(k.get('name'))
print(k.get('age'))
print(k.get('ab'))#如果里面没有的话会返回一个空值
打印结果为:
setdefault:跟get一样也是为了获取键值,当去获取值时,如果有值则会去获取本身的值,如果key没有值则可以设置(增加)一个默认值
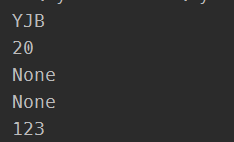
print(k.setdefault('name'))
print(k.setdefault('age'))
print(k.setdefault('ab'))
print(k.setdefault('ab','@@@'))
print(k.setdefault('abc','123'))
打印结果为:
keys:列出所有的key值
print(k)
print(k.keys())
打印结果为:

iterkeys:跟keys相关,这是一个对象,后面会讲
print(k.iterkeys())
打印结果为:

values:只把key的值给打印出来
print(k.values())
打印结果为:

iteritems:得到的也是一个对象,然后怎么取得或者获得这个对象呢?当你用到的时候一一取出来的时候才会显示,不取会搞成对象,取一次用一次,会用到for循环。如果光打印出k.iteritems()的话,
print(k.iteritems())
for k,v in k.iteritems():
print(k,v)
打印结果为:

print(k.iteritems()) #这是一个对象,推荐用这个,取一次用一次,如果要得到所有的键值,如果把所有的键值都给取出来后都是放到内存中去的,所以取一次用一次
print(k.items()) #搞出来之后这是一个列表,列表里面每个小元素是元组
for x, y in k.iteritems():
print(x, y)
打印结果为:

pop:删除指定的key值(不能放value值,否则会报错,只能写Key)
print(k)
k.pop('name')
print(k)
打印结果为:

fromkeys:从一个列表中获得Key
#有一个需要,把l的值当成m的字典
l = ['a','b','c','d']
m = {}
#n=m.fromkeys(l,123) #赋值所有的一个默认值为123
n=dict.fromkeys(l,124)#上面也可以这么写也是成立的
print(n)
打印结果为:

zip:zip是一个涵数,把两个列表进行叠加合并成一个字典(偶然会用),
#如果有两个字典的话,把l1当成key,把l2当成value
h1 = ['a','b','c','d']
g2 = [1,2,3,4]
dict_test = zip(h1,g2)
print(dict_test)
打印结果为:

update:合并字典
#如果有两个字典的话,把l1当成key,把l2当成value
h1 = ['a','b','c','d']
g2 = [1,2,3,4]
k = {'name':'YJB','age':20,'sex':'man'}
dict_test = dict(zip(h1,g2))
print(dict_test)
print(k)
#把上面第一个字典增加到第二个字典里面去,进行合并,把两个字典进行叠加
dict_test.update(k)
print(dict_test)
打印结果为:

soft:对字典进行排序
按Ctrl键单击可以查看这个涵数是怎么写的
#对字典进行排序soft,下例是按照value进行排序的
mm = dict(a=1,b=10,c=3,d=9)
print(mm)
print sorted(mm.iteritems(),key = lambda d:d[1],reverse = True) #lambda是一个匿名涵数,d是一个参数
print sorted(mm.iteritems(),key = lambda d:d[1],reverse = False)
打印结果为:

