
机器学习系列(3) 决策树
决策树原理详解
一、 什么是决策树
决策树是一种监督学习方法,能够从一些列有特征和标签的数据中总结出决策规则,以解决分类和回归问题。在决策树的决策过程中,一直对记录的特征进行提问。最初的问题所在的地方叫做根节点,在得到结论前的每一个问题都是中间节点。得到的每一个结论都叫做叶子节点。
二、 决策树的运算步骤
-
步骤一:将所有的特征看成是一个一个的节点
-
步骤二:基于ID3算法,C4.5算法和CART算法遍历当前的每一个特征,找到最优的划分节点
-
步骤三:进行递归,找到每一层的最优节点
-
步骤四:当每个子节点只有一种类型或者当前节点中记录数小于某个阈值,同时迭代次数达到给定值时停止。
三、决策树构建算法
3.1 ID3算法(信息增益)
信息熵
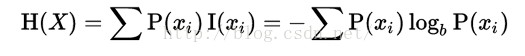
一个变量的不确定性越大,熵值也越大
信心增益(ID3)
将样本中的所有属性分割开,分别计算熵值,信息增益就是信息熵减去下一层属性的信息熵
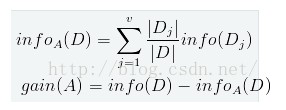
例题
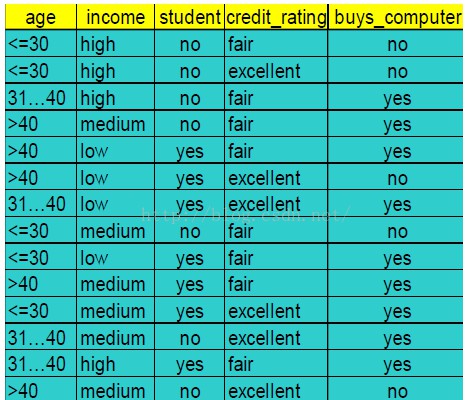
假设我们有以下数据,买电脑的人和不买电脑的人。可以看出,在此数据中,总数据14人,购买电脑的有8人,不买电脑的人有5人,因此info(D)的计算方式
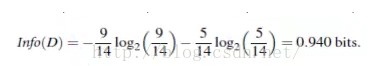
然后计算下age属性的信息熵, <35的5人, 买的2人,不买的3人;31-40的4人,买的4人,不买的0人;>40的5人,买的3人,不买的2人
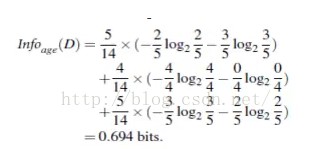
因此信息增益比Gain(age) = 0.940 - 0.694 = 0.246
再对比其余属性的信息增益 Gain(income) = 0.029, Gain(student)= 0.12,因此可以看出,age属性的信息增益最大,因此选择age的节点为根节点,其余的计算方法也相同。
3.2 C4.5算法
ID3算法存在一个问题,就是偏向于多值属性,例如存在唯一标识属性ID,ID3算法则会选择他作为分裂属性,这样对分类毫无作用,C4.5算法使用信息增益率进行划分
分裂信息

信息增益率
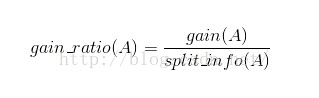
例题
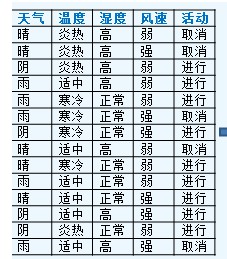
-
计算类别信息熵
类别信息熵表示的是所有样本中各类别出现的不确定性之和,根据熵的概念,熵越大,不确定性越大,把事情搞清楚所需要的信息量也越多。
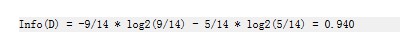
-
计算每个属性的信息熵
每个属性的信息熵相当于一种条件熵。他表示在某种属性条件下,各种类别出现的不确定性之和。属性的信息熵越大,表示属性中拥有的样本类别越不纯
3.计算信息增益

-
计算分裂信息度量

-
计算信息增益率 IGR = Gain/H
IGR(天气) = info(天气) / H(天气)
天气的信息增益率最高,选择天气作为分列属性
3.3 Cart算法(Gini)

例子 Gini系数越大,数据的不确定性也月抵达。Gini越小,数据的不确定性越低。G为0,数据集中的所有样本都是同一类别。
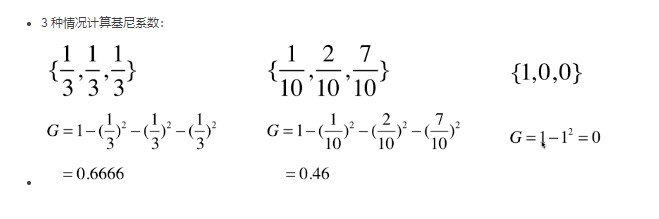
2 剪枝
1.限制决策树的最大深度,超过设定深度的全部剪掉 max_depth
- 一个节点分支后的每个子节点必须包含 min_samples_leaf个训练样本,否则就无法分支。或者分支会朝着满足每个子节点必须包含min_samples_leaf个样本的方向去发生。
3 优缺点
优点:
- 数据处理要求低,不需要归一化
- 对缺失值不敏感
- 效率高,在短时间内可能得到比较好的结果
缺点:
- 对连续性的字段比较难以预测
- 对有时间序列的数据,需要做很多处理
- 处理特征关联性强的数据表现的不是很好
四、 sklearn 调参
1. 导入相关库和数据集
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt
from sklearn.model_selection import GridSearchCV
data = pd.read_csv('data.csv', index_col=0)
data.columns
data.head()
2. 数据与处理
# 对数据集进行预处理
data.drop(['Cabin', 'Name', 'Ticket'], inplace=True, axis=1)
data['Age'] = data['Age'].fillna(data['Age'].mean())
data = data.dropna()
# 将二分类数据转换为0,1
data['Sex'] = (data['Sex'] == 'male').astype('int')
# 将三分类变量转化为数值型变量
labels = data["Embarked"].unique().tolist()
data['Embarked'] = data['Embarked'].apply(lambda x: labels.index(x))
3. 提取标签和特征军阵,分测试集和训练集
X = data.iloc[:, data.columns != "Survived"]
y = data.iloc[:, data.columns == "Survived"]
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
# 修正测试集和训练集的索引顺序
for i in [x_train, x_test, y_train, y_test]:
i.index = range(i.shape[0])
4. 建模调参阶段
# 导入数据,粗略查看一下结果
clf = DecisionTreeClassifier(random_state=25)
clf = clf.fit(x_train, y_train)
score_ = clf.score(x_test, y_test)
print(f"score:{score_}")
score = cross_val_score(clf, X, y, cv=10).mean()
print(f"cross_val_score:{score}")
score:0.7790262172284644 cross_val_score:0.7739274770173645
# 在不同的max_depth中观察模型的拟合状况
tr = []
te = []
for i in range(10):
clf = DecisionTreeClassifier(random_state= 25,
max_depth = i + 1,
criterion = "entropy"
)
clf = clf.fit(x_train, y_train)
score_tr = clf.score(x_train, y_train)
score_te = cross_val_score(clf, X, y, cv=10).mean()
tr.append(score_tr)
te.append(score_te)
print(max(te))
plt.plot(range(1, 11), tr, color="red", label="train")
plt.plot(range(1, 11), te, color="blue", label= "test")
plt.xticks(range(1, 11))
plt.legend()
plt.show()
# 使用网格搜索进行调参
from sklearn.model_selection import GridSearchCV
import numpy as np
gini_thresholds = np.linspace(0, 0.5, 20)
parameters ={
"splitter":("best", "random"),
"criterion":("gini","entropy"),
"max_depth":[*range(1, 10)],
"min_samples_leaf":[*range(1, 50, 5)],
"min_impurity_decrease":[*np.linspace(0, 0.5, 20)]
}
clf = DecisionTreeClassifier(random_state=25)
GS = GridSearchCV(clf, parameters, cv=10)
GS.fit(x_train, y_train)
print(GS.best_params_)
GS.best_score_
{'criterion': 'entropy', 'max_depth': 4, 'min_impurity_decrease': 0.0, 'min_samples_leaf': 1, 'splitter': 'best'}
Out[32]:
0.823151125401929
