
python — 线程
1.线程基础知识
1.1 进程与线程的区别
-
进程:
- 创建进程 时间开销大
- 销毁进程 时间开销大
- 进程之间切换 时间开销大
-
线程:
-
线程是进程中的一部分(不能脱离进程存在),每一个进程中至少有一个线程。
-
开销:
线程的创建,也需要一些开销(一个存储局部变量(临时变量)的结构,记录状态)
线程的创建、销毁、切换开销远远小于进程——开销小
-
进程是计算机中最小的资源分配单位(进程是负责圈资源)
线程是计算机中能被CPU调度的最小单位(线程是负责执行具体代码的)
线程是由 操作系统 调度,由操作系统负责切换的。
python中的线程比较特殊,所以进程也有可能被用到
注意:一般不建议开起多个进程,但一个进程可以开起多个线程,来减小开销。
特点:
- 进程 :数据隔离 开销大 同时执行几段代码
- 线程 :数据共享 开销小 同时执行几段代码
1.2 线程的理论
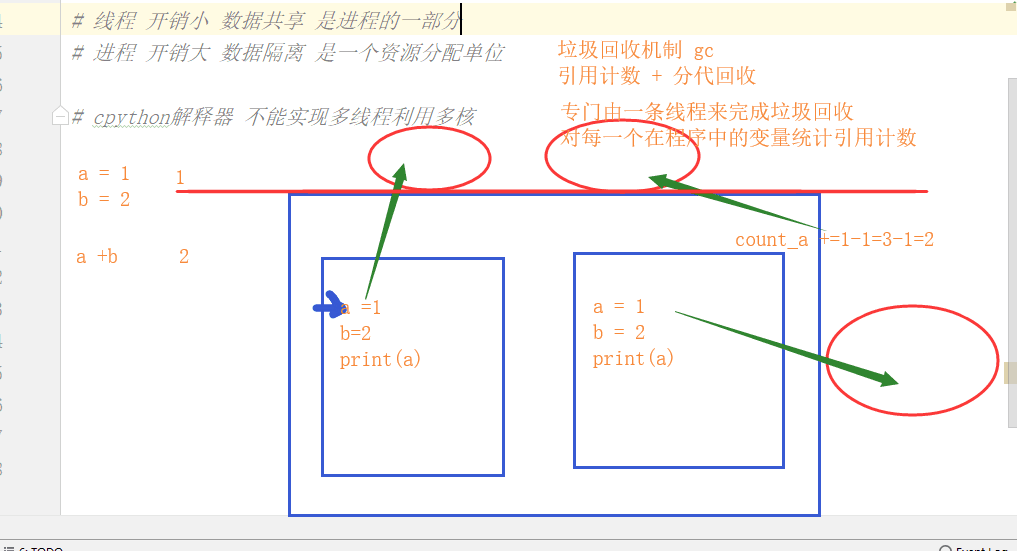
cpython解释器 — 不能实现多线程利用多核
python中垃圾回收机制 gc :引用计数 + 分代回收
专门有一条线程来完成垃圾回收,对每一个在程序中的变量统计引用计数
锁 :GIL 全局解释器锁
- 保证了整个python程序中,只能有一个线程被CPU执行
只能有一个线程被CPU执行原因:
- cpython解释器中特殊的垃圾回收机制
GIL锁导致了线程不能并行,但可以并发,所以使用多线程并不影响高io型的操作,只会对高计算型的程序有效率上的影响。
遇到高计算可以采用的方式:
- 多进程 + 多线程
- 分布式
cpython / pypy(pypython) 有垃圾回收机制,只能有一个线程被CPU执行,所以有全局解释器锁
jpython / iron python 没有垃圾回收机制,可以有多个线程被CPU执行,所以没有全局解释器锁
web框架 几乎都是多线程
总结:什么是GIL?
- 全局解释器锁
- 由Cpython解释器提供的
- 导致了一个进程中多个线程同一时刻只能有一个线程访问CPU
2 Thread 类
multiprocessing 是完全仿照这threading的类写的
创建线程有两种方式:面向函数、面向对象
线程中的几个方法:
2.1 启动线程 start
不需要写if __name__ = '__main__':
1.使用面向函数的方式启动线程
# 开启一个子线程
import os
import time
from threading import Thread
def func():
print('start son thread')
time.sleep(1)
print('end son thread',os.getpid())
Thread(target=func).start()
print('start',os.getpid())
time.sleep(0.5)
print('end',os.getpid())
# 开启多个子线程
def func(i):
print('start son thread',i)
time.sleep(1)
print('end son thread',i,os.getpid())
for i in range(10):
Thread(target=func,args=(i,)).start()
print('main')
2.使用面向对象的方式启动线程
class MyThread(Thread):
def __init__(self,i):
self.i = i
super().__init__()
def run(self):
print('start',self.i,self.ident)
time.sleep(1)
print('end',self.i)
for i in range(10):
t = MyThread(i)
t.start()
print(t.ident)
t.ident 线程的id
2.2 结束进程 join
主线程什么时候结束?
- 主线程等待所有子线程结束之后才结束
- 主线程如果结束了,主进程也就结束了
join方法 阻塞 直到子线程执行结束
def func(i):
print('start son thread',i)
time.sleep(1)
print('end son thread',i,os.getpid())
t_l = []
for i in range(10):
t = Thread(target=func,args=(i,))
t.start()
t_l.append(t)
for t in t_l:t.join()
print('子线程执行完毕')
注意:
- terminate 结束进程
- 在线程中不能从主线程结束一个子线程
2.3 守护线程
t.daemon = True
守护线程一直等到所有的非守护线程都结束之后才结束
除了守护了主线程的代码之外也会守护子线程
非守护线程不结束,主线程也不结束;主线程结束了,主进程也结束。
结束顺序 :非守护线程结束 -->主线程结束-->主进程结束--> 守护线程也结束
import time
from threading import Thread
def son1():
while True:
time.sleep(0.5)
print('in son1')
def son2():
for i in range(5):
time.sleep(1)
print('in son2')
t =Thread(target=son1)
t.daemon = True
t.start()
Thread(target=son2).start()
time.sleep(3)
2.4 threading模块的函数
线程里的一些其他方法:
current_thread 在哪个线程中被调用,就返回当前线程的对象
活着的线程,包括主线程:
- enumerate 返回当前活着的线程的对象列表
- active_count 返回当前或者的线程的个数
from threading import current_thread,enumerate,active_count
def func(i):
t = current_thread()
print('start son thread',i,t.ident)
time.sleep(1)
print('end son thread',i,os.getpid())
t = Thread(target=func,args=(1,))
t.start()
print(t.ident)
print(current_thread().ident) # 水性杨花 在哪一个线程里,current_thread()得到的就是这个当前线程的信息
print(enumerate())
print(active_count()) # =====len(enumerate())
2.5 测试
1.进程和线程的效率都差,但线程的开启、关闭、切换效率比进程的更高。
def func(a,b):
c = a+b
import time
from multiprocessing import Process
from threading import Thread
if __name__ == '__main__':
start = time.time()
p_l = []
for i in range(500):
p = Process(target=func,args=(i,i*2))
p.start()
p_l.append(p)
for p in p_l:p.join()
print('process :',time.time() - start)
start = time.time()
p_l = []
for i in range(500):
p = Thread(target=func, args=(i, i * 2))
p.start()
p_l.append(p)
for p in p_l: p.join()
print('thread :',time.time() - start)
# process : 11.76159143447876
# thread : 0.12466692924499512
2.线程的数据共享的效果
from threading import Thread
n = 100
def func():
global n # 不要在子线程里随便修改全局变量
n-=1
t_l = []
for i in range(100):
t = Thread(target=func)
t_l.append(t)
t.start()
for t in t_l:t.join()
print(n)
注意: 不要在子线程里随便修改全局变量
3 锁
线程中是不是会产生数据不安全?
即便是线程,即便有GIL,也会出现数据不安全的问题。不安全问题存在于以下几种场景:
- 1.操作的是全局变量
- 2.做以下操作:
- += -= *= /+ 先计算再赋值才容易出现数据不安全的问题
- 包括 lst[0] += 1 dic['key']-=1
- 3.多个线程对同一个文件进行写操作
a = 0
def func():
global a
a += 1
import dis
dis.dis(func)
a = 0
def add_f():
global a
for i in range(200000):
a += 1
def sub_f():
global a
for i in range(200000):
a -= 1
from threading import Thread
t1 = Thread(target=add_f)
t1.start()
t2 = Thread(target=sub_f)
t2.start()
t1.join()
t2.join()
print(a)
a = 0
def func():
global a
a -= 1
import dis
dis.dis(func)
加锁会影响程序的执行效率,但是保证了数据的安全。
a = 0
def add_f(lock):
global a
for i in range(200000):
with lock:
a += 1
def sub_f(lock):
global a
for i in range(200000):
with lock:
a -= 1
from threading import Thread,Lock
lock = Lock()
t1 = Thread(target=add_f,args=(lock,))
t1.start()
t2 = Thread(target=sub_f,args=(lock,))
t2.start()
t1.join()
t2.join()
print(a)
线程的锁分为:递归锁 、互斥锁
3.1 互斥锁
互斥锁:在同一个线程中,同一把锁不能连续acquire多次,开销小,产生死锁的几率大。
同一把锁acquire一次就要release一次
from threading import Lock
lock = Lock()
lock.acquire()
print('*'*20)
lock.release()
lock.acquire()
print('-'*20)
lock.release()
两把锁可以同时acquire,如
from threading import Lock
lock1 = Lock()
lock2 = Lock()
lock1.acquire()
print('*'*20)
lock2.acquire()
print('-'*20)
lock1.release()
lock2.release()
3.2 递归锁
递归锁:在一个线程中,同一把锁可以连续多次acquire不会死锁,但acquire多少次就需要release多少次,开销大,一把锁永远不死锁。
from threading import RLock
rlock = RLock()
rlock.acquire()
print('*'*20)
rlock.acquire()
print('-'*20)
rlock.acquire()
print('*'*20)
优点:在同一个线程中多次acquire也不会发生阻塞
缺点:占用了更多资源
3.3 单例模式(多线程)
import time
from threading import Lock
class A:
__instance = None
lock = Lock()
def __new__(cls, *args, **kwargs):
with cls.lock:
if not cls.__instance:
time.sleep(0.1)
cls.__instance = super().__new__(cls)
return cls.__instance
def __init__(self,name,age):
self.name = name
self.age = age
def func():
a = A('alex', 84)
print(a)
from threading import Thread
for i in range(10):
t = Thread(target=func)
t.start()
3.4 死锁现象
<1.> 死锁现象
在某一些线程中,出现陷入阻塞并且永远无法结束阻塞的情况就是死锁现象。
<2.> 死锁现象是怎么发生的?
- 1.有多把锁(一把以上)
- 2.多把锁交替使用
- 3.互斥锁在一个线程中连续acquire
import time
from threading import Thread,Lock
noodle_lock = Lock()
fork_lock = Lock()
def eat1(name,noodle_lock,fork_lock):
noodle_lock.acquire()
print('%s抢到面了'%name)
fork_lock.acquire()
print('%s抢到叉子了' % name)
print('%s吃了一口面'%name)
time.sleep(0.1)
fork_lock.release()
print('%s放下叉子了' % name)
noodle_lock.release()
print('%s放下面了' % name)
def eat2(name,noodle_lock,fork_lock):
fork_lock.acquire()
print('%s抢到叉子了' % name)
noodle_lock.acquire()
print('%s抢到面了'%name)
print('%s吃了一口面'%name)
time.sleep(0.1)
noodle_lock.release()
print('%s放下面了' % name)
fork_lock.release()
print('%s放下叉子了' % name)
lst = ['alex','wusir','taibai','yuan']
Thread(target=eat1,args=(lst[0],noodle_lock,fork_lock)).start()
Thread(target=eat2,args=(lst[1],noodle_lock,fork_lock)).start()
Thread(target=eat1,args=(lst[2],noodle_lock,fork_lock)).start()
Thread(target=eat2,args=(lst[3],noodle_lock,fork_lock)).start()
❤️.> 如何解决死锁现象?
-
1.递归锁 —— 将多把互斥锁变成了一把递归锁
递归锁本质:只有一把锁
优点:快速解决问题
缺点:效率差
***递归锁也会发生死锁现象,多把锁交替使用的时候
-
2.优化代码逻辑
优点:
- 可以使用互斥锁解决问题
- 效率相对好
缺点:
- 解决问题的效率相对低(解决问题慢)
# 递归锁解决死锁问题
import time
from threading import RLock,Thread
# noodle_lock = RLock()
# fork_lock = RLock() # 错误写法
noodle_lock = fork_lock = RLock()
print(noodle_lock,fork_lock)
def eat1(name,noodle_lock,fork_lock):
noodle_lock.acquire()
print('%s抢到面了'%name)
fork_lock.acquire()
print('%s抢到叉子了' % name)
print('%s吃了一口面'%name)
time.sleep(0.1)
fork_lock.release()
print('%s放下叉子了' % name)
noodle_lock.release()
print('%s放下面了' % name)
def eat2(name,noodle_lock,fork_lock):
fork_lock.acquire()
print('%s抢到叉子了' % name)
noodle_lock.acquire()
print('%s抢到面了'%name)
print('%s吃了一口面'%name)
time.sleep(0.1)
noodle_lock.release()
print('%s放下面了' % name)
fork_lock.release()
print('%s放下叉子了' % name)
lst = ['alex','wusir','taibai','yuan']
Thread(target=eat1,args=(lst[0],noodle_lock,fork_lock)).start()
Thread(target=eat2,args=(lst[1],noodle_lock,fork_lock)).start()
Thread(target=eat1,args=(lst[2],noodle_lock,fork_lock)).start()
Thread(target=eat2,args=(lst[3],noodle_lock,fork_lock)).start()
# 互斥锁解决死锁问题
import time
from threading import Lock,Thread
lock = Lock()
def eat1(name,noodle_lock,fork_lock):
lock.acquire()
print('%s抢到面了'%name)
print('%s抢到叉子了' % name)
print('%s吃了一口面'%name)
time.sleep(0.1)
print('%s放下叉子了' % name)
print('%s放下面了' % name)
lock.release()
def eat2(name,noodle_lock,fork_lock):
lock.acquire()
print('%s抢到叉子了' % name)
print('%s抢到面了'%name)
print('%s吃了一口面'%name)
time.sleep(0.1)
print('%s放下面了' % name)
print('%s放下叉子了' % name)
lock.release()
lst = ['alex','wusir','taibai','yuan']
Thread(target=eat1,args=(lst[0],noodle_lock,fork_lock)).start()
Thread(target=eat2,args=(lst[1],noodle_lock,fork_lock)).start()
Thread(target=eat1,args=(lst[2],noodle_lock,fork_lock)).start()
Thread(target=eat2,args=(lst[3],noodle_lock,fork_lock)).start()
<4.> 如何避免死锁?
在一个线程中只有一把锁,并且每一次acquire之后都要release
4 队列
线程之间的通信——线程是安全的
1.先进先出队列
写一个server,所有的用户的请求放在队列里——先来先服务的思想
import queue
from queue import Queue # 先进先出队列
q = Queue(3)
q.put(0)
q.put(1)
q.put(2)
print('22222')
print(q.get())
print(q.get())
print(q.get())
2.后进先出队列
与算法相关的(如:递归)
from queue import LifoQueue # 后进先出队列
# last in first out 栈
lfq = LifoQueue(4)
lfq.put(1)
lfq.put(3)
lfq.put(2)
print(lfq.get())
print(lfq.get())
print(lfq.get())
3.优先级队列
优先级队列的好处:
-
(可以做)自动的排序
-
抢票的用户级别
如:vip用户在1000-10000之间,普通用户是10001-……,只要是在VIP之间的数就会比普通用户的数优先服务
-
告警级别
from queue import PriorityQueue
pq = PriorityQueue()
pq.put((10,'alex'))
pq.put((6,'wusir'))
pq.put((20,'yuan'))
print(pq.get())
print(pq.get())
print(pq.get())

