
ADA 95教程 高级特性 硬件相关的特性
在本章中,我们将介绍一些Ada可用的构造,这些构造使您能够遇到真正的麻烦,因为我们将使用Ada的低级特性。低级功能是那些允许我们深入了解计算机内部工作的功能,但是我们将能够通过使用相当高级的Ada抽象来了解它们。
压倒一切的编译器默认值
通常,编译器会为我们做出许多关于如何存储数据,以及如何操作数据的决定。偶尔,我们希望告诉编译器,我们不满意它默认的方式,我们希望它使用不同的表示方式。本章讨论的主题将使我们能够告诉编译器如何将某些东西映射到底层硬件上。我们可以控制编译器如何在机器中表示某些东西,但我们也可能使生成的程序不可移植。这可能导致许多问题,如果我们希望将我们的程序转移到另一台计算机。此外,我们可能会影响结果代码的大小或速度,因为编译器编写者将使用某种表示数据的方法,因为它会在特定的目标机器上带来某种形式的节省。
谨慎使用表示子句
一般来说,本章将讨论的表示子句的使用,如果要使用的话,应该尽量少用。在任何情况下,最好推迟使用这些结构,直到程序开发得相当好,因为整个程序的正确操作远比生成紧凑高效的代码重要。在程序被调试并按预期运行之后,回过头来调整最常用代码段的大小和速度通常是一件很简单的事情。您可能会发现,在使程序在宏观意义上工作之后,它已经足够快,足够紧凑,没有必要求助于这些技术。
所有这些词都告诉您不要使用这些编程技术,现在我们将看看如何使用其中一些技术。但是请记住,当您使用这些Ada结构时,您可能会失去将程序移植到另一个实现的能力。您还将发现本章中的示例程序是那些最可能导致编译器问题的程序。
所需的包名为System
根据Ada 95参考手册(ARM),你的编译器必须有一个名为System的标准包,必须在你的编译器提供的文档附件M中定义。ARM的第13.7节包含了一个最小的项目列表,必须在系统的包规范中为你定义。花几分钟时间研究编译器文档中名为System的包的定义和ARM中列出的必需项将是有益的。您将发现在那里定义了几个常量,您在本教程中一直在使用它们,现在您知道它们来自哪里了。
有什么表示控制?
当我们试图控制数据的表示和它的存储方式时,我们实际上是在告诉Ada编译器如何定义类型。更确切地说,我们是在告诉编译器如何修改其存储特定类型的默认方法,包括我们希望它更改哪些参数,以及将它们更改为什么。
Ada类型有四个不同的区域可以用表示子句指定,我们将依次查看每个区域。它们没有按特定的顺序排列如下。
Length specification 长度规格 Record type representation 记录类型表示 Enumeration type representation 枚举类型表示 Address specification 地址规范
您将注意到,在每个示例中,我们将首先声明基本类型,然后告诉Ada编译器我们希望修改哪些参数以满足我们的目的,最后我们将声明修改后类型的对象。我们将在下面的一些示例程序中再次提到这个顺序。
长度规格
Example program ------> e_c32_p1.ada
-- Chapter 32 - Program 1
with Ada.Text_IO, Ada.Integer_Text_IO;
use Ada.Text_IO, Ada.Integer_Text_IO;
procedure SmallInt is
BITS : constant := 1;
type SMALL_INTEGER is new INTEGER range -25..120;
for SMALL_INTEGER'SIZE use 8*BITS;
type BIG_ARRAY is array(1..1000) of SMALL_INTEGER;
Number : SMALL_INTEGER := 27;
Big_List : BIG_ARRAY;
begin
Put("The type SMALL_INTEGER uses ");
Put(INTEGER(SMALL_INTEGER'SIZE), 5);
Put(" bits of memory.");
New_Line;
Put("The type BIG_ARRAY uses ");
Put(INTEGER(BIG_ARRAY'SIZE), 5);
Put(" bits of memory.");
New_Line;
end SmallInt;
-- Result of execution (as written)
-- The type SMALL_INTEGER uses 8 bits of memory.
-- The type BIG_ARRAY uses 8000 bits of memory.
-- Result of execution (with line 9 commented out)
-- The type SMALL_INTEGER uses 32 bits of memory.
-- The type BIG_ARRAY uses 32000 bits of memory.
长度规范用于声明可以使用多少位来存储某种类型的数据。这个表示子句在名为SMe_c06_p1的示例程序中进行了说明。艾达,你现在应该检查一下。
这个程序中唯一特别有趣的代码在第7行到第10行中。首先,我们定义了一个名为BITS的值为1的常量,以便以后使用。接下来,我们声明一个派生类型,它涵盖了从-25到120的范围,这个范围小到只需要8位就可以表示。因为我们想声明一个相当大的这种类型的数组,我们怀疑,编译器会将32位的完整单词分配给每个变量的类型,我们告诉编译器,我们希望它只使用8位存储这种类型的一个变量。第9行是执行此操作的表示子句。它以保留字for开始,后面是带勾的类型和字SIZE。它看起来像一个属性,这就是它,因为我们告诉编译器,我们希望名为SIZE的属性的值为8。
这个常数的用法现在应该很清楚了。它让这个表达非常清楚,因为当你读这个表达的时候,它就告诉你它在做什么。我们告诉编译器使用8位作为这种类型的大小。您不应该担心使用这个结构会降低程序的速度,因为它不会。这个常量只会计算一次,而且是在编译时,而不是在程序执行时。
你的编译器可能不喜欢这个子句
ARM不要求Ada编译器实现每个表示子句。由于这个原因,即使您有一个经过验证的Ada编译器,它也可能不会实现第9行。如果没有,它将在编译期间给你一条消息,说它不能处理这个表示子句,将无法给你一个对象模块。您将被要求删除有问题的表示子句并重新编译程序。如果编译器接受它,那么当您执行此程序时,您将看到类型SMALL_INTEGER只需要8位存储空间。在成功编译并运行程序之后,注释掉第9行,然后编译并再次执行它。您可能会发现编译器需要超过8位来存储这种类型的数据。如果编译器不能处理第9行,则注释掉它,编译并执行结果程序。
记住,在本章开始的时候我们说过,在本教程的所有程序中,本章将包含那些最可能在编译器中出现问题的程序。这就是为什么很多程序不能从一个编译器移植到另一个编译器的原因。用于测试这些示例程序的五个编译器中只有三个实现了这个特定的子句。
storage_size表示子句
另一个与SIZE非常相似的表示子句是STORAGE_SIZE。它用于告诉编译器使用多少存储单元来存储访问类型变量或任务类型变量。ARM对于什么是存储单元并不是很具体,所以它必须由编译器来定义。因为它没有很好地定义,因此对于每个编译器来说都是不同的,解释可能比简单地不去解释它更令人困惑。你将被留下独自研究它,记住它是类似于大小。至此,您已经学习了所有的Ada,您应该能够轻松地理解编译器文档中关于这个主题的注释。
记录类型表示
Example program ------> e_c32_p2.ada
-- Chapter 32 - Program 2
with Ada.Text_IO, Ada.Integer_Text_IO, Unchecked_Conversion;
use Ada.Text_IO, Ada.Integer_Text_IO;
procedure BitField is
type BITS is record
Lower : INTEGER range 0..3;
Middle : INTEGER range 0..1;
High : INTEGER range 0..3;
end record;
for BITS use record
Lower at 0 range 0..1;
Middle at 0 range 2..2;
High at 0 range 3..4;
end record;
BitData : BITS;
IntData : INTEGER;
function Switch_To_Bits is new Unchecked_Conversion(
Source => INTEGER,
Target => BITS);
begin
BitData.Lower := 2;
BitData.High := 3;
BitData.Middle := 0;
for Index in 1..18 loop
IntData := Index + 5;
BitData := Switch_To_Bits(IntData);
Put("IntData =");
Put(IntData, 4);
Put(" BitData =");
Put(INTEGER(BitData.High), 3);
Put(INTEGER(BitData.Middle), 3);
Put(INTEGER(BitData.Lower), 3);
New_Line;
end loop;
end BitField;
-- Result of Execution
-- IntData = 6 BitData = 0 1 2
-- IntData = 7 BitData = 0 1 3
-- IntData = 8 BitData = 1 0 0
-- IntData = 9 BitData = 1 0 1
-- IntData = 10 BitData = 1 0 2
-- IntData = 11 BitData = 1 0 3
-- IntData = 12 BitData = 1 1 0
-- IntData = 13 BitData = 1 1 1
-- IntData = 14 BitData = 1 1 2
-- IntData = 15 BitData = 1 1 3
-- IntData = 16 BitData = 2 0 0
-- IntData = 17 BitData = 2 0 1
-- IntData = 18 BitData = 2 0 2
-- IntData = 19 BitData = 2 0 3
-- IntData = 20 BitData = 2 1 0
-- IntData = 21 BitData = 2 1 1
-- IntData = 22 BitData = 2 1 2
-- IntData = 23 BitData = 2 1 3
检查名为e_c32_p2的程序。Ada是另外两个低级结构的例子,记录类型表示和未检查的转换。我们将从记录类型表示开始。
首先,我们声明一个名为BITS的记录类型,它有三个范围极其有限的字段,因为我们只希望在每个字段中存储一个或两个位。由于范围有限,我们希望指示编译器将单个变量存储在非常小的内存单元中,此外,我们希望编译器将所有三个字段存储在一个单词中。在第13行到第17行中,我们为编译器提供了这三个字段所需的模式。它看起来非常像一个记录,除了用保留字for和use代替type,并且在记录类型定义中。记住,我们正在修改已经声明的类型,以告诉编译器如何实际实现它。
每个字段也略有不同,因为在所有三种情况下都使用保留字at后跟数字0。这告诉系统将这个变量存储在从第一个单词开始的偏移量为0的单词中,或者换句话说,我们告诉编译器将这个变量放在记录的第一个单词中。此外,在保留的单词范围之后,还有另一个定义的范围,它告诉编译器将这些单词存储在哪个位中。因此,名为Lower的变量将存储在第一个单词中,并占据该单词的位0和位1。命名为Middle的变量也将存储在第一个单词中,并占据该单词的位2。命名为High的变量将占据同一个单词的位3和位4。
比特位是什么意思?
到这里,您可能想知道位位置0是什么。是最不重要的位还是最重要的位?这个问题完全取决于编译器的作者,您必须查阅文档以获得这个问题的答案,以及几乎任何关于这个新构造的问题。图32-1显示了一种可能的结果位模式。编译器的实际位模式可能完全不同。
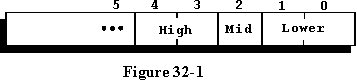
在大多数微型计算机和几乎所有小型计算机上,INTEGER类型变量由一个32位数字组成,但即使是这样,也要由实现者以他想要的任何方式来定义。因为32位对于INTEGER类型变量和单个单词来说是相当标准的,所以记录的各个字段被声明为一个单词,以说明Ada中的下一个低级编程构造。如果你的编译器特别聪明,你可以通过告诉编译器将整个记录压缩到5位来继续打包,因为这是实际存储数据所需要的全部。这将使用SIZE表示子句以类似于上一个示例程序的方式完成。
修改是有限度的
在声明了类型,然后修改它以适应我们的目的之后,我们在第19行声明一个新类型的变量,这将冻结类型并阻止任何进一步的类型修改。请注意,在声明了该类型的变量后,试图进一步修改该类型将是一个错误。这是因为它允许声明新修改的类型的另一个变量,该变量实际上不同于第一个变量的类型。
如果在它们的表示子句中添加了带有at 1的额外字段,它们将被放在距离记录开始1的偏移量的单词中。这当然是第二个词。您可以看到,可以非常仔细地控制数据存储在这种数据类型的记录中的位置和方式。
一个问题产生者,小心使用
在第22行中,我们实例化了名为Unchecked_Conversion的泛型函数的一个副本,以说明它的用法。这是一个可以给你带来麻烦的函数,但是如果你需要它的功能,它可以节省你的时间。在这种情况下,Switch_To_Bits将使用一个INTEGER作为其源,并将一个类型为BITS的记录作为结果或目标。使用INTEGER类型变量作为参数调用函数将改变变量的类型,并使用新类型返回相同的值。在本例中,由于单个位被打包到单个单词中,INTEGER类型变量中的数据实际上被分割为记录的三个字段。原始数据以及三个字段将显示一个小范围的值。在这种情况下,系统将整数变量中的复合数据解压缩到相应的字段中。
注意,第34行可以使用名为index的循环索引作为实际参数,因为在Ada中在调用中使用universal_integer是合法的。
使用未检查类型转换的唯一实际要求是,这两种结构具有相同数量的程序单元或位。C程序员将认出这是联合,而Pascal程序员应该看到这与使用变量记录进行类型转换是相同的。
一定要编译并运行这个程序,看看它是否真的做了它应该做的事情。您的编译器可能不会实现这些特性的一部分或全部,在这种情况下,您只能研究示例程序最后给出的执行结果。我们在本章的开头说过,有一些事情你可能不能做。被测试的五个编译器中只有两个完整地编译了这个程序,并且只有一个以图32-1所示的模式存储位。注意,Unchecked_Conversion不是可选的,而是必需的,作者测试的所有五个编译器都正确地编译了它。
pragma命名为pack
Example program ------> e_c32_p3.ada
-- Chapter 32 - Program 3
with Ada.Text_IO, Ada.Integer_Text_IO;
use Ada.Text_IO, Ada.Integer_Text_IO;
procedure PackItIn is
type LITTLE1 is range 1..57;
type LITTLE_REC1 is
record
A, B, C : LITTLE1;
end record;
type LIST1 is array(1..5) of LITTLE_REC1;
type LITTLE2 is range 1..57;
type LITTLE_REC2 is
record
A, B, C : LITTLE2;
end record;
pragma PACK(LITTLE_REC2);
type LIST2 is array(1..5) of LITTLE_REC2;
pragma PACK(LIST2);
type LITTLE3 is range 1..57;
for LITTLE3'SIZE use 8;
type LITTLE_REC3 is
record
A, B, C : LITTLE3;
end record;
pragma PACK(LITTLE_REC3);
type LIST3 is array(1..5) of LITTLE_REC3;
pragma PACK(LIST3);
begin
Put("Type LITTLE1 uses ");
Put(LITTLE1'SIZE, 5);
Put_Line(" bits for its representation.");
Put("Type LITTLE_REC1 uses ");
Put(LITTLE_REC1'SIZE, 5);
Put_Line(" bits for its representation.");
Put("Type LIST1 uses ");
Put(LIST1'SIZE, 5);
Put_Line(" bits for its representation.");
Put("Type LITTLE2 uses ");
Put(LITTLE2'SIZE, 5);
Put_Line(" bits for its representation.");
Put("Type LITTLE_REC2 uses ");
Put(LITTLE_REC2'SIZE, 5);
Put_Line(" bits for its representation.");
Put("Type LIST2 uses ");
Put(LIST2'SIZE, 5);
Put_Line(" bits for its representation.");
Put("Type LITTLE3 uses ");
Put(LITTLE3'SIZE, 5);
Put_Line(" bits for its representation.");
Put("Type LITTLE_REC3 uses ");
Put(LITTLE_REC3'SIZE, 5);
Put_Line(" bits for its representation.");
Put("Type LIST3 uses ");
Put(LIST3'SIZE, 5);
Put_Line(" bits for its representation.");
end PackItIn;
-- Result of execution, Compiler 1. (Did not support Line 28)
-- Type LITTLE1 uses 16 bits for its representation.
-- Type LITTLE_REC1 uses 48 bits for its representation.
-- Type LIST1 uses 240 bits for its representation.
-- Type LITTLE2 uses 16 bits for its representation.
-- Type LITTLE_REC2 uses 32 bits for its representation.
-- Type LIST2 uses 160 bits for its representation.
-- Type LITTLE3 uses 16 bits for its representation.
-- Type LITTLE_REC3 uses 32 bits for its representation.
-- Type LIST3 uses 160 bits for its representation.
-- Result of execution, Compiler 2. (Did support Line 28)
-- Type LITTLE1 uses 6 bits for its representation.
-- Type LITTLE_REC1 uses 24 bits for its representation.
-- Type LIST1 uses 120 bits for its representation.
-- Type LITTLE2 uses 6 bits for its representation.
-- Type LITTLE_REC2 uses 22 bits for its representation.
-- Type LIST2 uses 120 bits for its representation.
-- Type LITTLE3 uses 8 bits for its representation.
-- Type LITTLE_REC3 uses 24 bits for its representation.
-- Type LIST3 uses 120 bits for its representation.
检查名为e_c32_p3的程序。ada作为一个名为PACK的pragma的使用示例。这是给编译器的一条指令,让它尽可能紧密地打包数据,而不考虑结果程序执行所需的时间。这里给出了三个包装的例子,每一个都产生了更紧密的复合材料类型。
正常包装密度
第7行包含一种类型的声明,它只需要存储6位,但是在大多数实现中可能会使用一个32位的完整字。第9行到第12行声明了一个记录,由于某些编译器中的对齐要求,该记录可能需要4个单词,而第14行由于对齐方面的考虑,甚至可能浪费更多的单词。第40行到第50行用于输出这三种类型的大小以供研究。给出了在IBM-PC型微型计算机上运行的两个用于MS-DOS的Ada编译器的结果。
有些包装发生了
在第16行中,相同的类型以不同的名称重复出现,并在第18行到第22行的记录中使用,其中使用pragma PACK打包。请注意,包装只发生在记录级别,而不是在较低的级别,这被认为是默认的包装密度。在第24行和第25行中,用pragma PACK声明了相同的数组,在这个级别上再次使用,以获得比上一个示例更好的打包密度。执行的结果表明,编译器2在打包方面比编译器1做得好一些。
更高的存储密度
第27到37行说明了一个更高的打包密度,因为第28行中的表示子句指示编译器只对用作复合类型中的元素的类型使用8位。在这种情况下,两个编译器都不支持表示子句,所以必须注释掉第28行,这样就不会产生额外的填充密度。
哪种编译器是最好的?
仅仅因为一个编译器做了更好的打包工作,并不意味着它在两个比较的编译器之间是最好的。在执行代码时需要付出一些代价,因为数据字段与“正常”或未打包的数据字段的位置并不完全相同。高效地打包代码的编译器在执行以这种方式存储数据的程序时,可能要花费相当长的时间。要记住的重要一点是,尽管这两个编译器都经过了验证,但它们处理类型的方式略有不同。
请记住,名为PACK的pragma只在提到它的级别打包数据。它不会在较低的级别打包数据,除非在那里也提到了它。5个编译器中有3个能够完全正确地编译这个程序,除了第28行。
这是一个示例程序,您应该明确地编译和执行,而不依赖于执行的结果。您的输出可能与上述两个结果中的任何一个有显著不同。
枚举类型表示
Example program ------> e_c32_p4.ada
-- Chapter 32 - Program 4
with Ada.Text_IO, Ada.Integer_Text_IO;
use Ada.Text_IO, ada.Integer_Text_IO;
procedure EnumRep is
type MOTION is (STOPPED, NORTH, EAST, SOUTH, WEST);
for MOTION use (STOPPED => 0,
NORTH => 1,
EAST => 2,
SOUTH => 4,
WEST => 8);
Robot_Direction : MOTION := STOPPED;
begin
Robot_Direction := MOTION'LAST; -- WEST
Robot_Direction := MOTION'PRED(Robot_Direction); -- SOUTH
end EnumRep;
-- Result of execution
-- (There is no output from this program)
示例程序名为e_c32_p4。Ada演示了如何使用与枚举类型变量一起使用的表示子句来定义枚举值的值。
在本例中,我们声明了一个名为MOTION的类型,用于某种机器人,我们希望在该类型中指示机器人向四个方向中的任何一个移动或停止。零表示停止状态,四个方向实际上是二进制代码的四个不同位。假设每个方向有不同的继电器或电子开关,我们可以输出一个电场来控制四个继电器或开关。重要的是,枚举值是我们希望输出的模式,因此可以直接输出它。
枚举类型将以与任何其他枚举类型完全相同的方式工作。您可以使用PRED、SUCC、VAL或POS,它们的工作方式与按顺序声明的相同。我们只改变了枚举类型的基础表示。这些值必须按升序声明,否则将发出编译错误。
请确保编译并执行此程序,以确定您的编译器可以接受它。枚举表示子句在五个编译器中有三个可用。
地址规范
地址规范的使用方式非常模糊,甚至很难说明它在通用程序中的使用,因此没有提供程序。其使用的一般形式在下面的两行中给出,这两行表示程序的一个片段。
Robot_Port : MOTION; -- The port to control -- direction for Robot_Port use at 16#0175#; -- Absolute address of -- the robot hardware
该序列的第一行声明一个名为Robot_Port的变量为MOTION类型,该类型在示例程序e_c32_p4.ada中声明。您应该还记得,这种类型是用来控制机器人的方向的。第二行告诉Ada编译器,这个变量必须被赋值为绝对地址0175(十六进制),因为这是控制机器人方向的输出端口所在的位置。保留字for和use at告诉编译器在哪里找到这个特定的变量。
现在应该很明显了,为什么编写一个通用程序来说明这个概念是不实际的。在每台计算机上,可用端口的位置将是不同的,并且在分段内存或具有某种内存管理方案的情况下,寻址整个内存空间的方法可能相当复杂。请参考编译器附带的文档,以找到编译器用于寻址绝对内存位置的方法。按照ARM的要求,它将列在你们文件的附件M中。
UNCHECKED_DEALLOCATION
这也是一个非常低级的例程,这里提到它是为了完整。在本教程之前的第13章和第25章中已经说明了它的用法,其中它用于释放已动态分配的空间。
编程练习
1.使用Unchecked_Conversion编写一个程序,将INTEGER类型变量转换为一个CHARACTER数组,长度为表示系统上的INTEGER所需的长度,可能是两个或四个元素。使用ORD属性将CHARACTER类型数据转换为数值,并在监视器上显示组件的数值。这将标识INTEGER和CHARACTER类型的底层表示。(Solution)
2.重复练习1将FLOAT类型转换为CHARACTER数组。(Solution)
---------------------------------------------------------------------------------------------------------------------------
原英文版出处:https://perso.telecom-paristech.fr/pautet/Ada95/a95list.htm
翻译(百度):博客园 一个默默的 *** 的人

