
ADA 95教程 高级特性 动态分配
虽然这一章的标题是“动态分配”,但标题可能更适合“使用链表排序”,因为这是我们实际要做的。本章包含示例程序,这些程序将说明如何生成具有动态分配的条目的链表。它旨在说明如何以有意义的方式将几种编程技术组合在一起。它还将指导您动态分配和解除分配技术。
动态解除分配
本章讨论的最重要的主题之一是动态解除分配。在动态分配和使用变量之后,可以释放它们,从而允许回收内存空间供其他变量重用。Ada使用了两种技术,一种是垃圾回收,另一种是未经检查的释放。在这一章中,我们将对这两个问题进行详细的讨论。
简单的链表
Example program ------> e_c25_p1.ada
-- Chapter 25 - Program 1
with Ada.Text_IO, Ada.Integer_Text_IO;
use Ada.Text_IO, Ada.Integer_Text_IO;
procedure LinkList is
Data_String : constant STRING := "This tests ADA";
type CHAR_REC; -- Incomplete declaration
type CHAR_REC_POINT is access CHAR_REC;
type CHAR_REC is -- Complete declaration
record
One_Letter : CHARACTER;
Next_Rec : CHAR_REC_POINT;
end record;
Start : CHAR_REC_POINT; -- Always points to start of list
Last : CHAR_REC_POINT; -- Points to the end of the list
procedure Traverse_List(Starting_Point : CHAR_REC_POINT) is
Temp : CHAR_REC_POINT; -- Moves through the list
begin
Put("In traverse routine. --->");
Temp := Starting_Point;
if Temp = null then
Put("No data in list.");
else
loop
Put(Temp.One_Letter);
Temp := Temp.Next_Rec;
if Temp = null then exit; end if;
end loop;
end if;
New_Line;
end Traverse_List;
procedure Store_Character(In_Char : CHARACTER) is
Temp : CHAR_REC_POINT;
begin
Temp := new CHAR_REC;
Temp.One_Letter := In_Char; -- New record is now defined
-- The system sets Next_Rec
-- to the value of null
if Start = null then
Start := Temp;
Last := Temp;
else
Last.Next_Rec := Temp;
Last := Temp;
end if;
Traverse_List(Start);
end Store_Character;
begin
-- Store the characters in Data_String in a linked list
for Index in Data_String'RANGE loop
Store_Character(Data_String(Index));
end loop;
-- Traverse the final list
New_Line;
Put_Line("Now for the final traversal.");
Traverse_List(Start);
-- Free the entire list now
loop
exit when Start = null;
Last := Start.Next_Rec;
Start.Next_Rec := null;
Start := Last;
end loop;
end LinkList;
-- Result of execution
-- In traverse routine. --->T
-- In traverse routine. --->Th
-- In traverse routine. --->Thi
-- In traverse routine. --->This
-- In traverse routine. --->This
-- In traverse routine. --->This t
-- In traverse routine. --->This te
-- In traverse routine. --->This tes
-- In traverse routine. --->This test
-- In traverse routine. --->This tests
-- In traverse routine. --->This tests
-- In traverse routine. --->This tests A
-- In traverse routine. --->This tests AD
-- In traverse routine. --->This tests ADA
--
-- Now for the final traversal.
-- In traverse routine. --->This tests ADA
名为e_c25_p1.ada的程序包含生成和遍历链表所需的所有逻辑。我们将详细介绍如何构建和使用链表。
对于链表,我们首先需要的是一个记录类型,它包含一个访问变量,该变量可以访问自身。第9行是一个不完整的记录定义,它允许我们在第11行中定义访问类型。在定义了访问类型之后,我们可以完成第13行到第17行中的记录定义,其中包括对访问类型的引用。因此,记录类型包含对自身的引用。第9行更恰当地称为类型规范,第13到17行称为类型主体。请注意,不完整的类型定义只能用于声明访问类型。
我们在第19行和第20行中声明了两个额外的访问变量,以及两个用于生成和遍历列表的过程,我们将很快看到。请注意,所有这些都包含在主程序的声明部分中。
程序本身,从第56行开始,以一个for循环开始,该循环覆盖了前面定义的名为Data_string的字符串变量的范围,该字符串的每个字符依次被赋予过程Store_character。这个过程的作用还有待我们去发现。
存储字符的过程
我们以单个字符进入这个过程,并希望以某种方式将其存储起来以供以后使用。我们使用一个名为Temp的局部变量,它是记录类型的访问变量,并使用它为第42行中的记录类型CHAR_REC的变量动态分配存储,然后将调用程序的单字符输入分配给名为One_Letter的字段。这个记录名为Next_Rec的字段是一个访问类型变量,根据Ada的定义,生成时系统会将其设置为null。图25-1是记录变量、第19行和第20行中定义的两个访问类型变量Start和Last以及本地访问变量Temp的图形表示。现在我们需要将新记录插入到我们的链表中,但是有一种不同的方法,这取决于它是第一个记录还是一个附加记录。
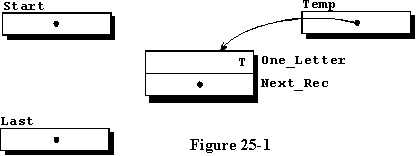
第一个记录
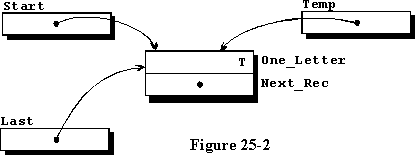
如果它是第一条记录,或者如果这是第一次调用此过程,则访问变量Start的值将为null,因为系统在详细说明时为其分配了null值。我们可以测试这个值,如果它为null,我们将新记录的访问变量的值赋给访问变量Start和 Last。我们已经生成了图25-2所示的数据,我们将很快看到如何使用这些数据。
附加记录
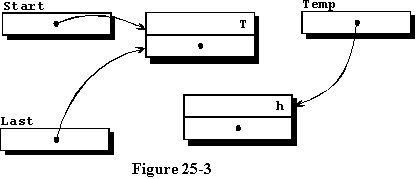
如果我们发现Start的值不为null,表示它已经被分配访问另一条记录,那么我们需要将新记录添加到列表的末尾。如果这是我们第二次进入这个过程,我们就得到了如图25-3所示的数据,其中包括先前输入的单个记录,以及仍然与第一个记录解除关联但由名为Temp的访问变量访问的新记录。
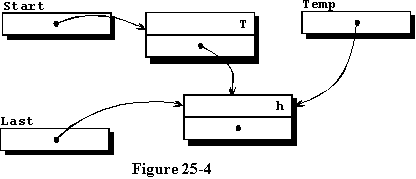
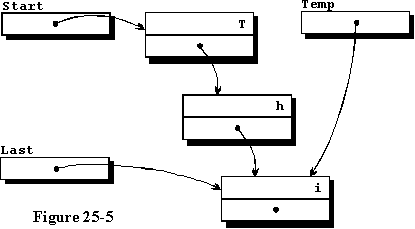
我们将新记录添加到第50行和第51行的列表末尾,结果列表如图25-4所示。第50行使第一条记录中的access变量访问新记录,第51行使变量Last引用新记录,该记录现在是列表的末尾。在输入第三个元素并将其添加到列表的末尾之后,我们得到了如图25-5所示的数据结构。对于本例,将不绘制更多的元素,但学生可以绘制一些额外的图表。
遍历列表
每次向列表中添加字符时,都会调用Traverse_List 过程,该过程从输入访问点Start ,在此程序中开始,并列出列表中当前的所有字符。它通过使用自己的本地访问变量Temp来实现这一点,Temp最初被分配给列表中第一条记录的地址。它首先检查列表是否为空,如果为空,则进入一个循环,在该循环中输出每个记录中的字符,直到在其名为Next_Rec的访问变量字段(即访问指针)中找到一个值为null的记录。变量Temp通过第32行中的赋值在列表中工作,在第32行中,每次通过循环时,Temp都从下一个记录中被赋值访问变量的值。
由于每次将字符输入列表时都会遍历该列表,因此每次添加字符并遍历更新的列表时,输出的字符列表将增加一个字符。
我们在第65行再次遍历列表,然后一次释放整个列表的一个元素。您会注意到,我们实际上并没有释放释放的元素,我们只为访问变量赋值null。我们将依靠垃圾收集器来为我们进行释放。
有关垃圾收集的详细信息
我们在本教程的第13章中提到了垃圾收集,但是关于这个主题还有更多的内容需要讨论。Ada编译器可能包含一个垃圾收集功能,它会偶尔搜索访问变量和存储池,以查看存储池中是否有任何位置未被访问变量访问。如果它找到任何位置,它会将这些位置返回到空闲列表中,以便它们可以再次分配。这样,任何由于错误编程或故意清除访问变量而丢失的内存都将自动恢复,并可作为动态变量重用。但是请注意,垃圾收集器的实现在Ada编译器中是可选的。检查您的文档,看看编译器中是否有垃圾收集器。
使用垃圾收集器
在第68到73行中,我们执行一个遍历链表的循环,并为所有访问变量赋值null。如果有垃圾收集器,它最终会找到存储池中不再有访问变量访问的位置,并将这些位置返回到可用内存的可用池中。我们之所以使用finally这个词,是因为没有预定义的发生时间,而是由编译器编写者决定。在本章后面将对这个主题作更多的介绍。
如果您的编译器没有垃圾收集器,则当您完成程序执行时,操作系统将回收丢失的内存,因此实际上不会丢失内存。
如果动态分配失败怎么办?
如本教程前面所述,如果没有足够的内存来提供请求的内存块,则会引发异常Storage_Error 。然后由您来处理异常,并提供一种优雅的方法来处理这个问题。您可能需要向用户建议一种恢复方法。
编译并执行此程序,观察输出,如果您不完全了解其操作,则返回到附加研究。为了理解下一个程序,你需要很好地掌握这个程序,所以当你准备好了,我们将继续使用一个链表,这个链表有点复杂,因为它可以用来按字母顺序排列字符数组。
按字母顺序排列的链表
Example program ------> e_c25_p2.ada
-- Chapter 25 - Program 2
with Ada.Text_IO, Ada.Integer_Text_IO, Unchecked_Deallocation;
use Ada.Text_IO, Ada.Integer_Text_IO;
procedure SortList is
Data_String : constant STRING := "This tests ADA";
type CHAR_REC; -- Incomplete declaration
type CHAR_REC_POINT is access CHAR_REC;
type CHAR_REC is -- Complete declaration
record
One_Letter : CHARACTER;
Next_Rec : CHAR_REC_POINT;
end record;
Start : CHAR_REC_POINT; -- Always points to start of list
Last : CHAR_REC_POINT; -- Points to the end of the list
procedure Free is new Unchecked_Deallocation(CHAR_REC,
CHAR_REC_POINT);
pragma Controlled(CHAR_REC_POINT);
procedure Traverse_List(Starting_Point : CHAR_REC_POINT) is
Temp : CHAR_REC_POINT; -- Moves through the list
begin
Put("In traverse routine. --->");
Temp := Starting_Point;
if Temp = null then
Put("No data in list.");
else
loop
Put(Temp.One_Letter);
Temp := Temp.Next_Rec;
if Temp = null then exit; end if;
end loop;
end if;
New_Line;
end Traverse_List;
procedure Store_Character(In_Char : CHARACTER) is
Temp : CHAR_REC_POINT; -- Moves through the list
procedure Locate_And_Store is
Search : CHAR_REC_POINT;
Prior : CHAR_REC_POINT;
begin
Search := Start;
while In_Char > Search.One_Letter loop
Prior := Search;
Search := Search.Next_Rec;
if Search = null then exit; end if;
end loop;
if Search = Start then -- New character at head of list
Temp.Next_Rec := Start;
Start := Temp;
elsif Search = null then -- New character at tail of list
Last.Next_Rec := Temp;
Last := Temp;
else -- New character within list
Temp.Next_Rec := Search;
Prior.Next_Rec := Temp;
end if;
end Locate_And_Store;
begin
Temp := new CHAR_REC;
Temp.One_Letter := In_Char; -- New record is now defined
-- The system sets Next_Rec
-- to the value of null
if Start = null then
Start := Temp;
Last := Temp;
else
Locate_And_Store;
end if;
Traverse_List(Start);
end Store_Character;
begin
-- Store the characters in Data_String in a linked list
for Index in Data_String'RANGE loop
Store_Character(Data_String(Index));
end loop;
-- Traverse the final list
New_Line;
Put_Line("Now for the final traversal.");
Traverse_List(Start);
-- Deallocate the list now
loop
exit when Start = null;
Last := Start.Next_Rec;
Free(Start);
Start := Last;
end loop;
end SortList;
-- Result of execution
--
-- In traverse routine. --->T
-- In traverse routine. --->Th
-- In traverse routine. --->Thi
-- In traverse routine. --->This
-- In traverse routine. ---> This
-- In traverse routine. ---> Thist
-- In traverse routine. ---> Tehist
-- In traverse routine. ---> Tehisst
-- In traverse routine. ---> Tehisstt
-- In traverse routine. ---> Tehissstt
-- In traverse routine. ---> Tehissstt
-- In traverse routine. ---> ATehissstt
-- In traverse routine. ---> ADTehissstt
-- In traverse routine. ---> AADTehissstt
--
-- Now for the final traversal.
-- In traverse routine. ---> AADTehissstt
下一个示例程序名为e_c25_p2.ada,它使用不同的存储技术生成按字母顺序排序的列表。这个程序与上一个程序相同,只是Store_Character 的过程不同。
在这个程序中,如果它是第一个字符输入,那么Store_Character过程的工作原理与最后一个相同,您可以通过检查第74行到第77行看到这一点。但是,如果它是一个额外的输入,我们将调用名为Locate_And_Store嵌入式过程。此过程搜索现有列表,查找列表中按字母顺序排列的不小于新字符的第一个字符。找到该字符后,搜索将终止,并且必须在找到的字符之前将新字符插入到列表中。这是通过移动访问变量而不是移动实际变量来实现的。如果必须将新字符添加到列表的起始点,则必须以特殊方式对其进行处理,如果必须将其作为最后一个元素,则还需要对其进行特殊处理。
向列表中添加元素
图25-6说明了将第四个元素添加到三元素列表中时的数据状态。
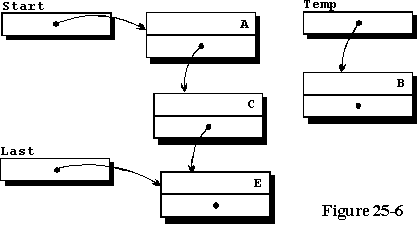
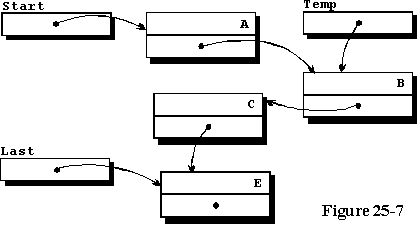
三元素列表与上一个示例程序中描述的列表相同,Temp正在访问要按字母顺序插入的新元素。程序的第64行和第65行更改访问变量以进行插入,图25-7说明了更改访问变量以实现该目标的结果。注意,这里使用的字符数据与程序中使用的数据不同,但是出于说明目的不同。将新记录添加到列表开头以及将其添加到列表结尾的情况将不会以图形方式显示,而是留给学生绘制图表。
有关取消分配的详细信息
在第13章中,我们首先提到了编译器提供的名为Unchecked_Deallocation的泛型过程,并说明了如何在那里的示例程序中使用它。因为它可以用于任何动态分配的数据,所以它也可以用于这些程序。为了使用它,您必须首先在with子句中提到名称,就像在本程序的第2行中所做的那样,以使其可用。因为它是一个通用过程,所以在使用之前必须实例化它。第22行是过程的实例化,在这里它被命名为Free。Pascal和C都有一个名为Free的deallocator,由于其他语言的原因,Free在Ada中已经成为相当标准的名称。为了便于与其他Ada程序员交流,我们鼓励您使用Free这个名称。如果它遵守命名标识符的规则,将它命名为任何其他名称都是完全合法的。
如何使用未经检查的取消分配
当您使用Unchecked_Deallocation过程时,实际上是您自己负责管理存储池,并且您必须告诉系统您将负责垃圾收集,而它不必关心它自己。您可以使用名为CONTROLLED的pragma来实现这一点,如第25行所示。这告诉系统您将负责管理存储池中动态分配给CHAR_REC_POINT类型的任何访问变量的所有区域。系统不会尝试对此类型执行任何垃圾收集,但会假定您正在处理内存管理。
您可能认为让系统维护存储池并自动执行垃圾收集是一个好主意,但这可能是一个真正的问题,在我们了解什么是垃圾收集以及如何实现垃圾收集之后,这一点就很明显了。
垃圾回收是如何实现的?
对于垃圾收集的实现频率没有预定义的方法,因此每个编译器编写者都有自己的定义方法。最常用的方法之一是等待存储池用完,然后搜索所有访问变量和所有存储池区域,以查找所有未引用的区域。然后,这些区域被返回到空闲列表,程序继续执行。最大的问题是,在Ada程序基本停止的这段时间内,可能需要整整一秒钟的执行时间才能完成。这在实时系统中是不可接受的,因为它可能发生在非常不合时宜的时间,例如747飞机最后进近国际机场时。在这种情况下,最好使用名为CONTROLLED的pragma来告诉系统忽略垃圾收集,并像我们在本程序中所做的那样自己管理存储池。
取消分配列表
第95行到第100行中的循环将遍历该列表,并将所有分配的数据返回到存储池,在那里可以立即重用。有观察力的学生会注意到,在释放特定记录之前,每个记录中的access变量都被复制到名为Last的变量中。
编译并执行这个程序,这样您就可以看到它确实按字母顺序对输入字符进行排序。您应该清楚地看到,这种对单个字符进行排序的非常简单的情况在现实世界中并不太有用,但是对包含23个字段(按姓氏、名、zipcode和出生地)的大型记录列表进行排序可能是一项相当大的任务,但也可能导致一个非常有用的程序。请记住,在这个程序中,我们只是更改访问变量,而不是移动数据,因此在大型数据库中使用此技术的效率将非常高。
二叉树排序程序
Example program ------> e_c25_p3.ada
-- Chapter 25 - Program 3
with Ada.Text_IO, Unchecked_Deallocation;
use Ada.Text_IO;
procedure BTree is
Test_String : constant STRING := "DBCGIF";
Data_String : constant STRING := "This tests ADA";
type B_TREE_NODE; -- Incomplete declaration
type NODE_POINT is access B_TREE_NODE;
type B_TREE_NODE is -- Complete declaration
record
One_Letter : CHARACTER;
Left : NODE_POINT;
Right : NODE_POINT;
end record;
procedure Free is new Unchecked_Deallocation(B_TREE_NODE,
NODE_POINT);
pragma Controlled(NODE_POINT);
Root : NODE_POINT; -- Always points to the root of the tree
procedure Traverse_List(Start_Node : NODE_POINT) is
begin
if Start_Node.Left /= null then
Traverse_List(Start_Node.Left);
end if;
Put(Start_Node.One_Letter);
if Start_Node.Right /= null then
Traverse_List(Start_Node.Right);
end if;
end Traverse_List;
procedure Store_Character(In_Char : CHARACTER) is
Temp : NODE_POINT;
procedure Locate_And_Store(Begin_Node : in out NODE_POINT) is
begin
if In_Char < Begin_Node.One_Letter then
if Begin_Node.Left = null then
Begin_Node.Left := Temp;
else
Locate_And_Store(Begin_Node.Left);
end if;
else
if Begin_Node.Right = null then
Begin_Node.Right := Temp;
else
Locate_And_Store(Begin_Node.Right);
end if;
end if;
end Locate_And_Store;
begin
Temp := new B_TREE_NODE;
Temp.One_Letter := In_Char; -- New record is now defined
-- The system sets Next_Rec
-- to the value of null
if Root = null then
Root := Temp;
else
Locate_And_Store(Root);
end if;
Put("Ready to traverse list. --->");
Traverse_List(Root);
New_Line;
end Store_Character;
begin
-- Store the characters in Data_String in a Binary Tree
for Index in Data_String'RANGE loop
Store_Character(Data_String(Index));
end loop;
-- Traverse the list
New_Line;
Put_Line("Now for the final traversal of Data_String.");
Put("Ready to traverse list. --->");
Traverse_List(Root);
New_Line(2);
Root := null; -- Needed to clear out the last tree
-- Store the characters in Test_String in a Binary Tree
for Index in Test_String'RANGE loop
Store_Character(Test_String(Index));
end loop;
-- Traverse the list
New_Line;
Put_Line("Now for the final traversal of Test_String.");
Put("Ready to traverse list. --->");
Traverse_List(Root);
New_Line;
-- Now deallocate the tree
declare
procedure Free_Up(Current_Node : in out NODE_POINT) is
begin
if Current_Node.Left /= null then
Free_Up(Current_Node.Left);
end if;
if Current_Node.Right /= null then
Free_Up(Current_Node.Right);
end if;
Free(Current_Node);
end Free_Up;
begin
if Root /= null then
Free_Up(Root);
end if;
end;
end BTree;
-- Result of execution
--
-- Ready to traverse list. --->T
-- Ready to traverse list. --->Th
-- Ready to traverse list. --->Thi
-- Ready to traverse list. --->This
-- Ready to traverse list. ---> This
-- Ready to traverse list. ---> Thist
-- Ready to traverse list. ---> Tehist
-- Ready to traverse list. ---> Tehisst
-- Ready to traverse list. ---> Tehisstt
-- Ready to traverse list. ---> Tehissstt
-- Ready to traverse list. ---> Tehissstt
-- Ready to traverse list. ---> ATehissstt
-- Ready to traverse list. ---> ADTehissstt
-- Ready to traverse list. ---> AADTehissstt
--
-- Now for the final traversal of Data_String.
-- Ready to traverse list. ---> AADTehissstt
-- Ready to traverse list. --->D
-- Ready to traverse list. --->BD
-- Ready to traverse list. --->BCD
-- Ready to traverse list. --->BCDG
-- Ready to traverse list. --->BCDGI
-- Ready to traverse list. --->BCDFGI
-- Now for the final traversal of Test_String.
-- Ready to traverse list. --->BCDFGI
名为e_c25_p3.ada的示例文件说明了如何使用动态分配和递归来执行排序函数。它使用了字母排序的二叉树方法,这在沃思的书“算法+数据结构=程序”中有详细的定义。这里将简要定义该方法。
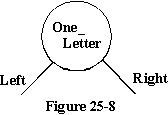
排序元素如图25-8所示,其中一个节点由圆内存储的数据和两个指针组成,每个指针指向其他节点或空值。这些节点中的每一个都必须有指向它的东西才能使整个系统变得有用,我们需要一些额外的指针来通过最终的整体结构找到我们的方向。
节点的定义包含在程序的第14行到第19行中,在这里我们定义了节点的类型,其中有两个访问变量指向它自己的类型。您将看到,我们有一个名为Left的访问变量和另一个名为Right的访问变量,它们对应于图25-8中节点底部的两个分支。节点本身包含的数据可以是任意多个不同的变量,包括数组和记录,但为了便于说明,只包含一个字符。
造树
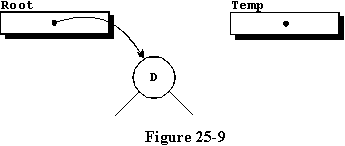
主程序从第74行开始,循环调用过程Store_Character一次,输入字符串中的每个字符命名为Data_string。我们在第82行再次遍历列表,并将null值赋给根。下面的操作说明将使用Test_String作为字符串示例。第一次调用Store_Character时,使用字符“D”,我们分配一个新记录,将“D”存储在其中,由于Root等于null,我们执行第65行来分配名为Root的访问变量,以指向新记录,结果出现如图25-9所示的状态。
下一次调用Store_Character时,这次使用字符“B”,我们分配一个新记录,将“B”存储在其中,由于Root不再等于null,我们从第67行调用Locate_and_Store过程,告诉它从Root开始。Locate_And_Store 过程是递归的,依次调用自身,直到成功存储字符为止。第一次调用时,输入字符小于输入节点上存储的字符“D”,因此选择左分支,并执行第45到49行中的语句。在这种特殊情况下,左分支是空的,因此它被分配了输入记录的地址,从而得到图25-10中的状态。这棵树开始成形了。
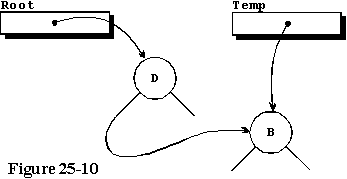
第三个字符
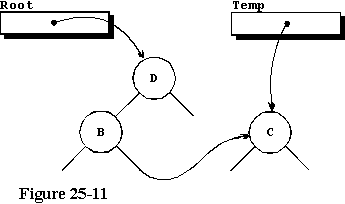
下一个字符被发送到Store_character,这次是一个“C”,导致另一个Locate_And_Store的调用。在这个逻辑过程中,由于输入字符少于根节点上的字符,因此我们选择左分支并从第48行递归调用Locate_And_Store。在这个递归调用中,我们告诉它使用存储在当前节点左侧分支中的节点。在下一个过程调用中,我们发现“C”不小于存储在那里的“B”,并且我们发现这个节点的右分支为null,因此我们可以将新节点存储在那里。我们的树现在看起来如图25-11所示。
继续浏览输入流的其余字符,我们最终得到了如图25-12所示的结构,其中存储了所有6个字符。
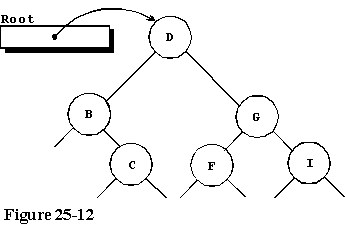
遍历B树
遍历树与构建树基本相同,只是我们不需要测试输入数据的相等性,只需测试每个节点的左访问值和右访问值。如果access值不等于null,那么access变量指向一个子树,我们递归到该子树并检查它的每个子树。通过一点研究,您应该能够在树中追踪您的路径,以查看我们实际上按照构建树的方式对输入字符进行字母排序,然后遍历它进行输出。
解除分配树
我们再次使用Unchecked_Deallocation 和 pragma CONTROLLED来显式地释放树。我们以类似于打印字符的方式遍历树来实现这一点。但是要记住的一点是,只有在选中两个子树之后才能释放节点,因为一旦释放节点,其子树就不再可用。
编程练习
在示例程序e_c25_p1.ada中使用Unchecked_Deallocation来释放列表(Solution)
将一个名为Character_Count的整型变量添加到e_c25_p3.ada中名为B_TREE_NODE的记录中。生成树时,将当前字符计数存储在此变量中。当字符串完成时,输出排序后的字符列表及其在字符串中的位置。(Solution)
B is character 2 in the string. C is character 3 in the string. D is character 1 in the string. F is character 6 in the string. G is character 4 in the string. I is character 5 in the string.
---------------------------------------------------------------------------------------------------------------------------
原英文版出处:https://perso.telecom-paristech.fr/pautet/Ada95/a95list.htm
翻译(百度):博客园 一个默默的 *** 的人

