mysql中的并列/非并列排名:rank() over() 、dense_rank() over()以及 row_number() over()
前言:使用sql查询数据的时候,我们有时候需要根据具体的字段值进行排名,下面使用几个栗子来说明rank在sql中的作用
下面用到的表名:user_visit_stats 主要字段包括:用户id(uid),部门名称(dept_name),访问次数(visit_count)
1、格式:rank() over(order by [列名])
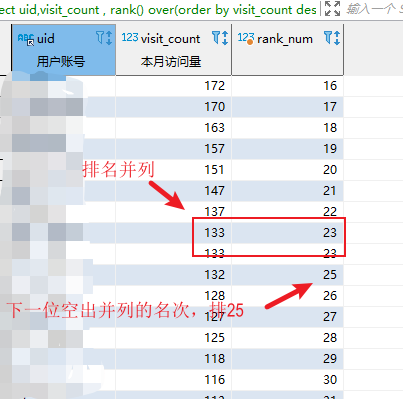
根据访问量降序排名,访问量相同时 排名并列 ,下一位需要空出并列的名次
select uid,visit_count , rank() over(order by visit_count desc ) as rank_num from user_visit_stats
执行结果:
2、格式 rank() over(partition by [列名] order by [列名])
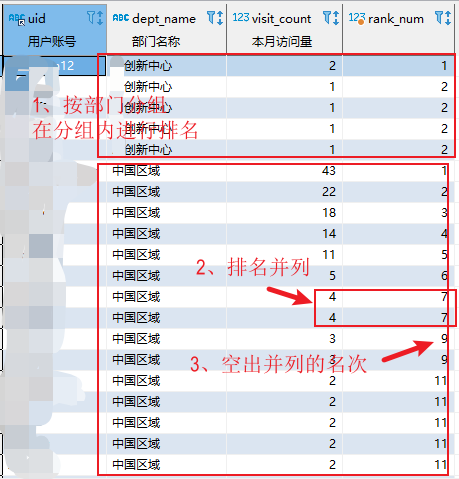
按照部门分组,再在分组中按照访问量降序排名,访问量相同时并列排名,下一位需要空出并列的名次
select uid,dept_name ,visit_count , rank() over(partition by dept_name order by visit_count desc) as rank_num from user_visit_stats where dept_name is not null and dept_name <> ""
执行结果:
3、格式:dense_rank() over(order by [列名])
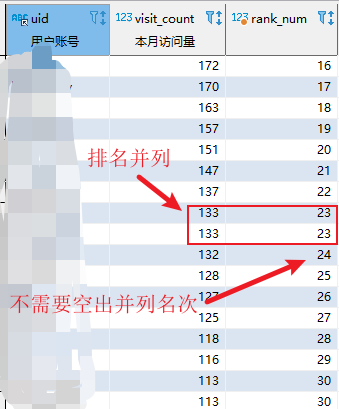
根据访问量降序排名,访问量相同时排名并列,下一位不需要空出并列的名词
select uid,visit_count, dense_rank() over(order by visit_count desc) as rank_num from user_visit_stats
执行结果:
4、格式:row_number() over(order by [列名])
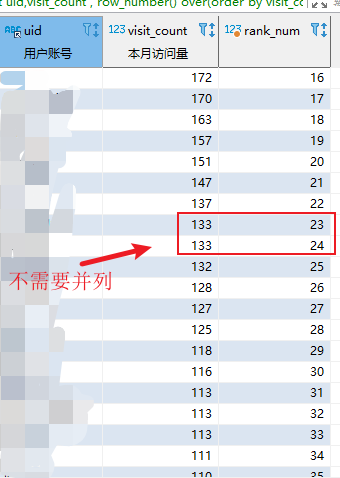
根据访问量排名降序排名,访问量相同时 不需要并列,一直排下去
select uid,visit_count , row_number() over(order by visit_count desc) as rank_num from user_visit_stats
执行结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号