Towards a Human-like Open-Domain Chatbot
论文地址:https://arxiv.org/pdf/2001.09977.pdf
模型
Meena的seq2seq模型是基于Evolved Transformer来搭建的。
Transformer包含一个Encoder和一个Decoder,每个Encoder由若干个结构相同的Encoder-block串联而成,同样每个Decoder也由
若干个结构相同的Decoder-block串联而成,每个block的参数由训练得到,模型一经设置整个结构就固定了。
Evolved Transformer的模型结构是在给定的搜索空间中搜索出来的,当然它肯定能搜索出最初的Transformer结构。
Evolved Transformer也包含一个Encoder和一个Decoder,这里引入了一个cell的概念,每个Encoder由若干个结构相同的Encoder-cell串联
而成,同样每个Decoder也由若干个结构相同的Decoder-cell串联而成。
每个Encoder-cell由 6 个block并行组成,每个block相互独立,每个block内部都有两个branch。
每个Decoder-cell由 8 个block并行组成,每个block相互独立,每个block内部都有两个branch。
cell结构如下:
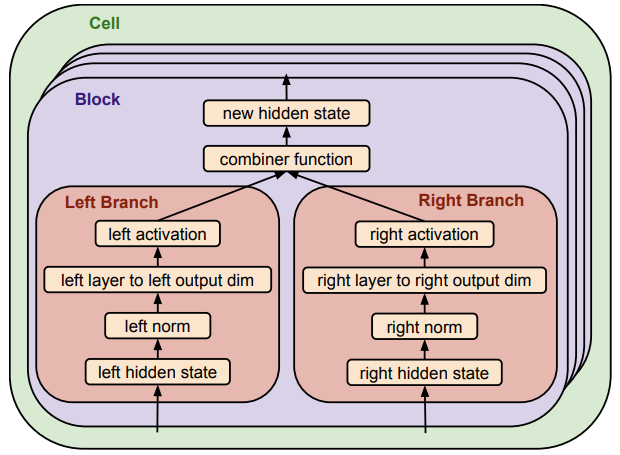
branch的搜索空间:
- Input:branch可以从输入池中选择一个隐藏状态作为当前分支的输入。属于 cell 第i个 block 的 branch 只能从[0, i)个隐藏状态中进行选择。
-
Normalization:归一化项提供了两个选项, [LAYER NORMALIZATION, NONE]
-
Layer:构造一个神经网络层,提供的选项包括:
-
标准卷积
-
深度可分离卷积
-
LIGHTWEIGHT 卷积
-
n头注意力层
-
GATED LINEAR UNIT
-
ATTEND TO ENCODER(decoder专用)
-
无操作
-
Dead Branch,切断输出
-
Relative Output Dimension:决定神经网络层输出的维度。
-
Activation:搜索中激活函数的选项有[SWISH, RELU, LEAKY RELU, NON]
-
Combiner Function:表征的是左枝和右枝的结合方式,包括{ADDITION、CONCATENATION、MULTIPLICATION}。如果左右枝最终输出形状不同,
则需要使用padding进行填充。短的向量向长的向量对齐,当使用加法进行结合时使用0填充,当使用乘法进行结合时使用1填充。
-
Number of cells:纵向repeat的cell的数量,搜索范围是[1,6]
Evolved Transformer在341GB的数据上训练了一个月,得到最好的模型,训练完成后一个cell就仅包含一个block了,Meena的Encoder端使用了
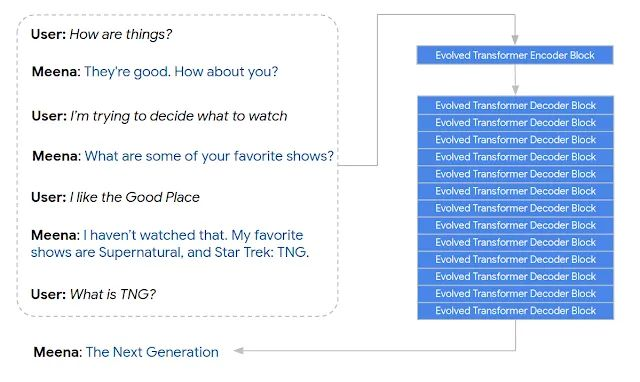
1个cell/block,Decoder端使用了13个cell/block,隐含层大小是2560,注意力头数为32,baseline模型参数为2.6B。
Encoder的输入由6个历史对话语句+1个当前输入语句拼接而成。
数据集
评测方法
Meena的自动评估方法也是使用的Perplexity(PPL):
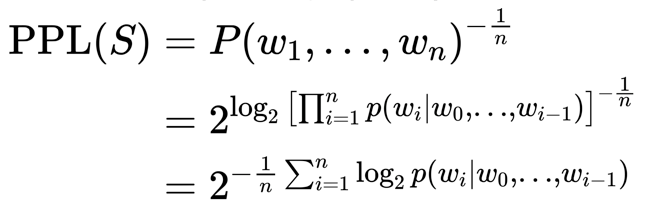
一般用自然对数,由公式可知,句子概率越大,语言模型越好,迷惑度越小。
Meena定义了一种新的人为评估方法,叫Sensibleness and Specficity Average(SSA),它是以下两个值的平均值:
- Sensibleness:回复合理;符合逻辑、保持一致性;
- Specficity:回复具体,有内容。
评估时针对一个session里机器人的每个回复先问此回复是否合理,合理的话再问回复是否具体。
论文首先验证了SSA和人对机器人的喜好程度是正相关的,也就是真的可以用SSA评价一个聊天机器人的好坏。
下图中最右边的点对应的是人,其他的点对应不同的机器人。

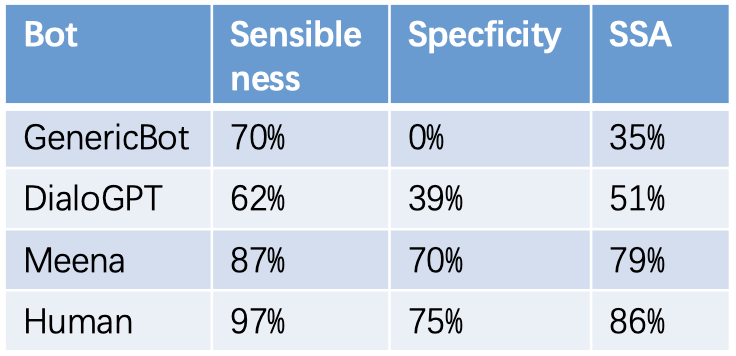
以下表格中给出了上图中部分机器人的具体数值。GenericBot 是作者创建的一个基准机器人,它对所有问句都回答 “I don’t know”,
对所有陈述句都回答 “ok”。可见SSA的定义还是比较合理的。
接着,作者验证了SSA与PPL是高度负相关的,即PPL越低,SSA就越高。这样以后评价机器人好坏就不用费力做人为评估了,只要看PPL就行了。
当然,这个结论有人是不认同的,存在PPL低的机器人反而比PPL高的机器人效果更差的情况。下图给出了不同机器人对应的SSA,可见Meena大
模型达到了79%,已经接近人类的86%了。而微软小冰的SSA值居然是最低的。

SSA指标有两种模式:
- static: 在预设好的multi-turn context下生成回答。
创建了一个1477个对话上下文,每个上下文有1到3轮对话。这个数据集被称为Mini-Turing Benchmark(MTB)。
一个例子如下:
A: do you like movies? B: Yeah, I like sci-fi mostly. A: Really? which one is your favourite? B: [answer eg] I love Back to the Future.
在用这个数据集评估的时候,会把上面例子中的头三句话作为上下文发给模型,模型给出回答。然后将上下文和回答发给评估者去做评估。
- interactive: 和chatbot自由聊天。
静态模式很适合用来评估模型,但是可能会有bias,毕竟评估数据集不大。为了解决这个问题,提出了一种更灵活的方式,让测试者和
chatbot自由交谈,从chatbot说hi开始进行对话。对话至少7轮,最多14轮。收集100个这样的对话进行SSA评估,即至少700个样本。
作者在实验中发现BLEU指标和人类评估的结果相关性很差,不过BLEU在大多的对话生成工作中都作为一个自动化指标。
在自然语言处理中的机器翻译任务中, BLEU非常常见, 它是用于评估模型生成的句子(candidate)和实际句子(reference)的差异的指标.
它的取值范围在0.0到1.0之间, 如果两个句子完美匹配(perfect match), 那么BLEU是1.0, 反之, 如果两个句子完美不匹配(perfect mismatch),
那么BLEU为0.0。首先给出两个句子计算 n-gram 精确度的公式:

神经网络生成的句子是 candidate,给定的标准译文是 reference。
对于分子:
1)第一个求和符号统计的是所有的 candidate,因为计算时可能有多个句子,
2)第二个求和符号统计的是一条 candidate 中所有的 n−gram,而 表示某一个 n−gram 在 reference 中的个数。
所以整个分子就是在给定的 candidate 中有多少个 n-gram 词语出现在 reference 中。
对于分母:前两个求和符号和分子中的含义一样,Count(n-gram') 表示 n−gram′在 candidate 中的个数。
故分母是获得所有的 candidate 中 n-gram 的个数。
累积 N-Gram 得分指的是为各个 gram 对应的权重加权, 来计算得到一个加权几何平均(weighted geometric mean). 默认情况下,
sentence_bleu()和corpus_bleu()都是计算累积的 4-gram BLEU 分数的, 也称之为BLEU-4.

- BLEU 需要计算译文 1-gram,2-gram,...,N-gram 的精确率,一般 N 设置为 4 即可,公式中的 Pn 指 n-gram 的精确率。
- Wn 指 n-gram 的权重,一般设为均匀权重,即对于任意 n 都有 Wn = 1/N。
- BP 是惩罚因子,如果译文的长度小于最短的参考译文,则 BP 小于 1。
- BLEU 的 1-gram 精确率表示译文忠于原文的程度,而其他 n-gram 表示翻译的流畅程度。
一个nltk的参考代码:
from nltk.translate.bleu_score import sentence_bleu reference = [['this', 'is', 'small', 'test']] candidate = ['this', 'is', 'a', 'test'] score = sentence_bleu(reference, candidate) print(score) score = sentence_bleu(reference, candidate, weights=(0.25, 0.25, 0.25, 0.25)) print(score)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号