

RNN 网络中文本的 pack 和 pad 操作
RNN 模型一般设定固定的文本长度(text sequence length,可理解为文本序列在时间维度上的步数 time step),以保证网络输出
层数据维度的一致性。但在训练和测试时,难以保证输入文本长度的一致性,因此常常需要截断操作(即将超过预设长度的文本截断)
和 pad 操作(即对不足预设长度的文本进行补 0 填充)。
Pytorch 中,在文本数据的 transfrom 以及 RNN 网络的输入阶段,均充分考虑了 pad 操作。其主要体现在:
(1)RNN、LSTM 和 GRU 等网络的输入数据均可为 PackedSequence 类型数据;
(2)可通过 pad_sequence、pack_sequence、pack_padded_sequence 和 pad_packed_sequence 等操作,实现 pad 和 pack 操作。
1. pack_sequence
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | import torchfrom torch.nn.utils.rnn import pack_sequence, pad_sequence, pad_packed_sequence, pack_padded_sequencetext1 = torch.tensor([1,2,3,4]) # 可视为有 4 个文字的样本text2 = torch.tensor([5,6,7]) # 可视为有 3 个文字的样本text3 = torch.tensor([8,9]) # 可视为有 2 个文字的样本sequences = [text1, text2, text3] # 三个文本序列拼接x = pack_sequence(sequences)print(x)"""PackedSequence(data=tensor([1, 5, 8, 2, 6, 9, 3, 7, 4]), batch_sizes=tensor([3, 3, 2, 1]), sorted_indices=None, unsorted_indices=None)""" |
输入数据是由 tensor 列表,每个 tensor 表示一个序列数据。pack 后的返回值包括两数据。一类为 data,即压缩后的数据;
而另一类 batch_sizes 表示每个时间步 batch 中包含的样本量。
值的注意的是,sequences 列表内的各元素长度必须按照降序排列,也就是越长的文本应放在前面,输入的 Batch * Sequence 矩阵为上三角阵。
前文提到的 RNN 网络中可以接收的 Input 数据可以为 PackedSequence 类型数据,即是类似于这里的返回值。

2. pad_sequence
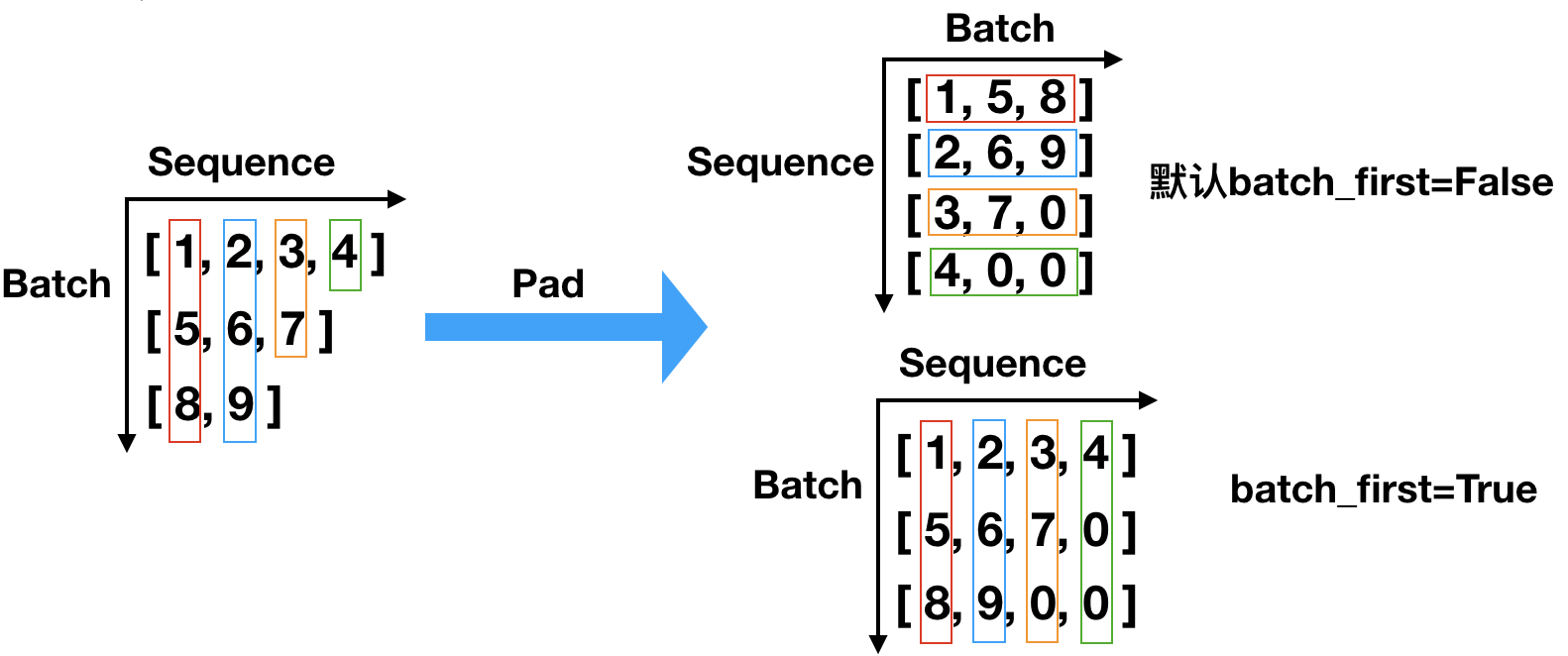
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | import torchfrom torch.nn.utils.rnn import pack_sequence, pad_sequence, pad_packed_sequence, pack_padded_sequencetext1 = torch.tensor([1,2,3,4]) # 可视为有 4 个文字的样本text2 = torch.tensor([5,6,7]) # 可视为有 3 个文字的样本text3 = torch.tensor([8,9]) # 可视为有 2 个文字的样本sequences = [text1, text2, text3] # 三个文本序列拼接x = pad_sequence(sequences)print(x)"""tensor([[1, 5, 8], [2, 6, 9], [3, 7, 0], [4, 0, 0]])""" |
pad 操作即是将不同长度的文本序列进行对齐的填充过程。默认情况下,参数 batch_first=False,这里指定的是输出数据的形状,
有些函数的这个参数是用来指明输入数据的形状,注意区分。pad_sequence 输入数据的形状和 pack_sequence 是一样的。
与 pack 操作不同,pad 操作对于 sequences 列表内的各元素长度顺序并无要求。
观察上述 pack 和 pad 操作,返回结果均倾向于按照序列 sequece 的顺序进行输出,而将 batch 的输出顺序后置,其实这是 pytorch 中
整个 RNN 网络的统一推荐用法,观察 RNN、LSTM 和 GRU 等网络架构,参数 batch_first 的默认值均为 False!
3. pack_paded_sequence
顾名思义,这个函数的输入是 pad_sequence 函数的输出,也就是填充后的数据。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | import torchfrom torch.nn.utils.rnn import pack_sequence, pad_sequence, pad_packed_sequence, pack_padded_sequencetext1 = torch.tensor([1,2,3,4]) # 可视为有 4 个文字的样本text2 = torch.tensor([5,6,7]) # 可视为有 3 个文字的样本text3 = torch.tensor([8,9]) # 可视为有 2 个文字的样本sequences = [text1, text2, text3] # 三个文本序列拼接x = pad_sequence(sequences, batch_first=True) # batch_first 指定输出数据的形状print(x)y = pack_padded_sequence(x, lengths=[4,3,2], batch_first=True) # batch_first 指明输入数据的形状print(y)"""tensor([[1, 2, 3, 4], [5, 6, 7, 0], [8, 9, 0, 0]])PackedSequence(data=tensor([1, 5, 8, 2, 6, 9, 3, 7, 4]), batch_sizes=tensor([3, 3, 2, 1]), sorted_indices=None, unsorted_indices=None)""" |
pack_padded_sequence 函数的作用过程可分解为如下步骤:
(1)接收一个 padded_sequence 数据;
(2)根据 batch_first 参数明确该数据的布局(默认为 batch_first=False);
(3)根据 lengths 参数明确 batch 内各样本的时间步长,选择数据;注意列表内的元素必须为降序。
(4)将上述数据按照时间维度进行压缩,得到目标的 PackedSequence 类型数据。
4. pad_packed_sequence
pad_packed_sequence 函数即为 pack_padded_sequence 的逆操作,其在参数设定时也许注意通过 batch_first 控制返回值的维度顺序,
同时可通过设置 total_lengths 来控制 pad 后的总步长(该值必须不小于输入 PackedSequence 数据的步长数)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | import torchfrom torch.nn.utils.rnn import pack_sequence, pad_sequence, pad_packed_sequence, pack_padded_sequencetext1 = torch.tensor([1,2,3,4]) # 可视为有 4 个文字的样本text2 = torch.tensor([5,6,7]) # 可视为有 3 个文字的样本text3 = torch.tensor([8,9]) # 可视为有 2 个文字的样本sequences = [text1, text2, text3] # 三个文本序列拼接x = pack_sequence(sequences)print(x)y = pad_packed_sequence(x, total_length=5, batch_first=True)print(y)"""PackedSequence(data=tensor([1, 5, 8, 2, 6, 9, 3, 7, 4]), batch_sizes=tensor([3, 3, 2, 1]), sorted_indices=None, unsorted_indices=None)(tensor([[1, 2, 3, 4, 0], [5, 6, 7, 0, 0], [8, 9, 0, 0, 0]]), tensor([4, 3, 2]))""" |


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架