

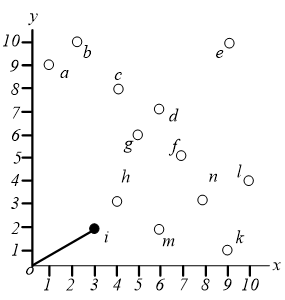
Skyline查询
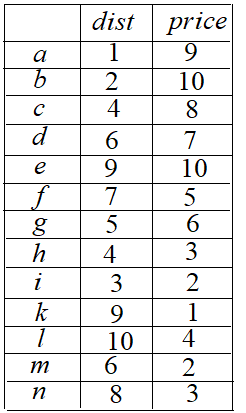
假设一个数据库存储每个酒店的以下信息:它的价格(夜间价格)、离海滩的距离。用户希望检索“最佳”酒店,如何比较两个酒店的质量呢?
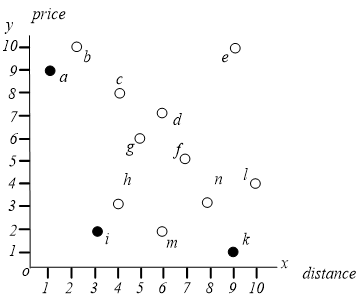
比 好吗?是的, 酒店比 酒店更便宜,而且离海滩更近,我们说 支配 。
是不是比 好呢?它们是不可比的。一些用户可能更喜欢 (因为它离海滩更近),而另一些用户可能更喜欢 (因为它更便宜)。
skyline 包含了所有不受其它酒店支配的酒店。skyline = ,而非 skyline 酒店在大多数情况下不会被用户考虑。
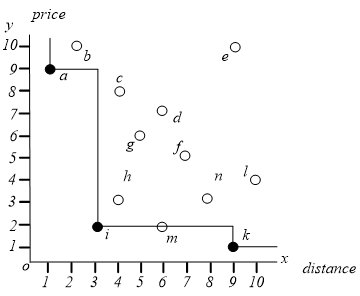
skyline 查询算法用到了两个重要的性质:
1)支配传递性:如果 支配 , 支配 ,那么我们就有 支配 。
2)如果一个点不能支配另一个点,那么反之亦然。
1. Block Nested Loop (BNL)
这个是最基本的查询算法,通过暴力搜索,判断每个酒店是否有被其他酒店支配,平方时间复杂度。
2. Sort First Skyline (SFS)
SFS是一种改进的BNL。首先根据(单调)偏好函数对整个数据集按某个维度进行排序。然后按 BNL 算法计算。
3. SCAN 扫描算法
顺序扫描表格,扫描过程中维护可能成为 skyline 点的列表,假设内存允许在 List 中最多保留 个条目。
首先初始化 List,即将 加入 List —— List = ,接下来顺序扫描表格中的其它点,做如下两个判断:
a. 当前扫描到的点是否被 List 内的点所支配,如果没有被支配则执行步骤 ;否则将该点舍弃,然后扫描下一个点。
b. 当前扫描到的点是否支配 List 内的点,如果是则删除 List 内所有被当前点支配的点,然后执行步骤 。
c. 判断 List 内的元素是否达到元素上限,如果没有,则将该点加入 List,否则将该点写入磁盘,并对当前 List 内的点做标记,只有第一次
溢出时做标记,表示当前了 List 内的点和磁盘上的点互不支配。
以上面酒店为例,它的 SACN 扫描算法过程如下:
1)因为 支配 ,所以丢弃 ,被舍弃的点不会成为 skyline 点,如果 会支配其它的点,那么这个点必然也被 支配。
2)因为 不被 List 里面的点支配,也不支配 List 里的点,所以 加入 List —— List = 。
4)因为 不被 List 里面的点支配,也不支配 List 里的点,所以 加入 List —— List = 。
5)因为 支配 ,所以丢弃 。
6) 应该加入 List,但 List 已经满了,所以将 写入磁盘文件,并标记所有当时在 List中的点 —— List = , File = 。
7)因为 支配 List 里面的 ,所以用 替换 —— List = , File = , 是没有标记的。
8)因为 支配 List 中的 ,所以用 替换 —— List = , File =
....
9)因为 支配 ,所以用 替换 —— List = , File =
10)List = , File =
11) 均被舍弃。
12)List 中有标记的点就是 skyline 点,然后还要针对 file 再做一遍 SCAN。
13)结果 。
4. Divide and Conquer (D&C)
把点分成几组,使得每组的数据都能够放进内存。分别处理这些组,然后合并它们的结果。 内的点直接成为 skyline, 内的点
直接舍去,因为它们显然会被 内的点支配,然后用 内的点来消除 和 中的非 skyline 点。

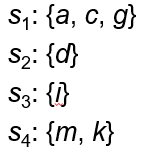
5. Nearest Neighbor (NN)
通过 树的 算法来找 Skyline 点。
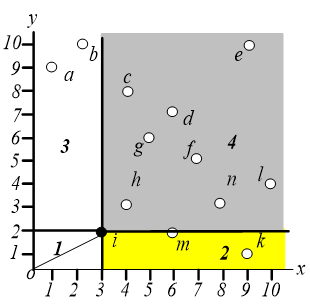
首先找到数据空间中距离原点最近的一个点,一般来说,任何距离指标都可以。这样我们就可以找到点 ,这个点必然是一个 skyline 点。
对于点 ,我们不需要考虑阴影区域中的那些点。区域 也不需要考虑。事实上,在这个地区是没有意义的。区域 和区域 必须进一步探索。
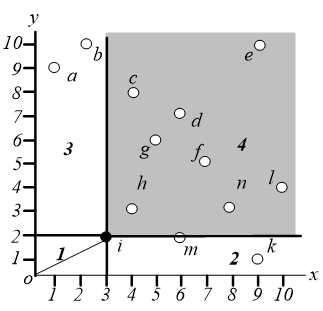
在区域 中执行相同的操作,即找距离原点最近的点,这样就可以找到点 ,如下图,同样地,我们只需要关心区域 和 。
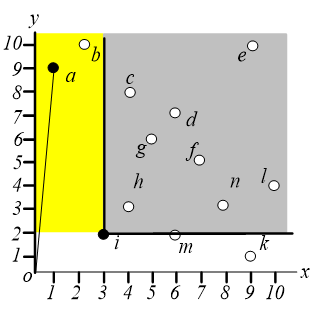
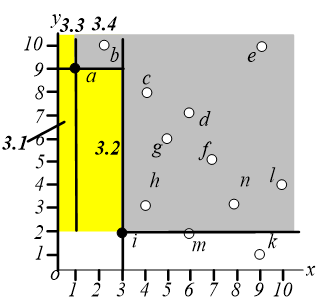
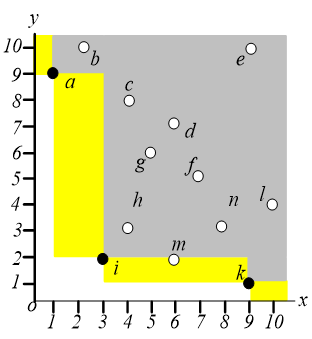
在区域 中搜索离原点最近的点,可以找到 点。
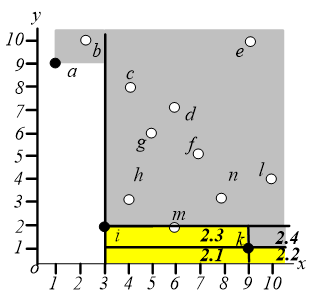
这个算法会经过 次有效的 查询和 次空查询。一般来说,如果 skyline 有 个点,那么 执行 次有用的 查询和 次空查询。
6. Branch and Bound Skyline (BBS)
基于best-first NN算法实现。首先建立 树。
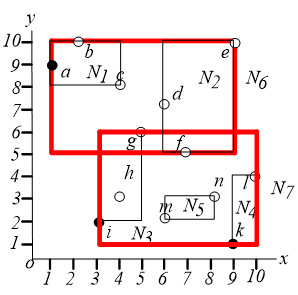
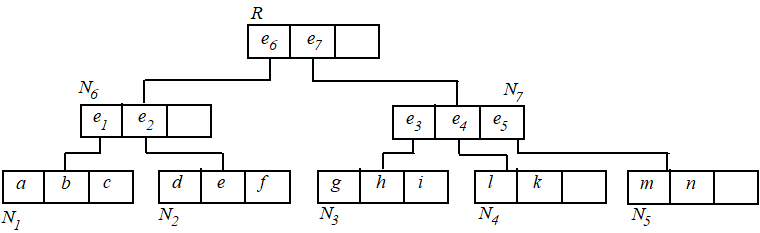
从根节点开始,算法过程如下:
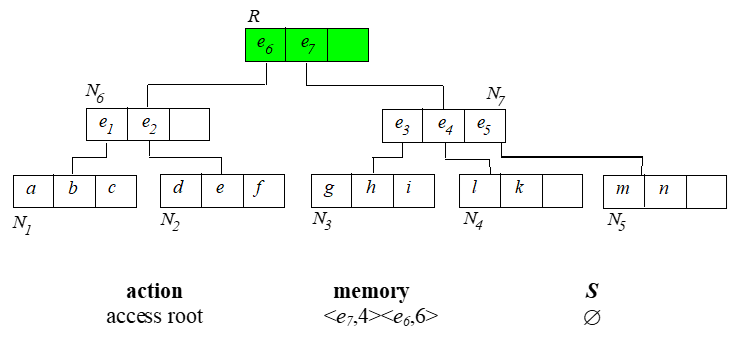
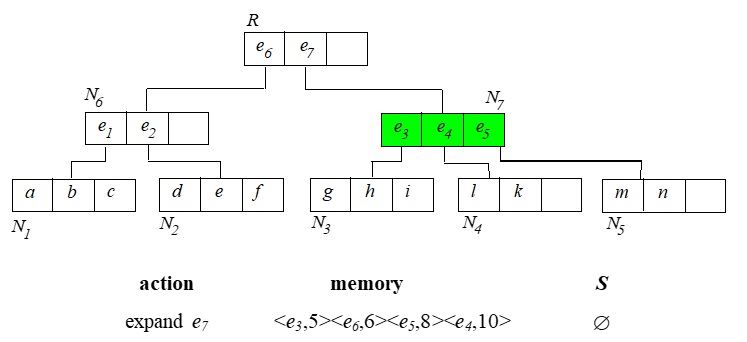
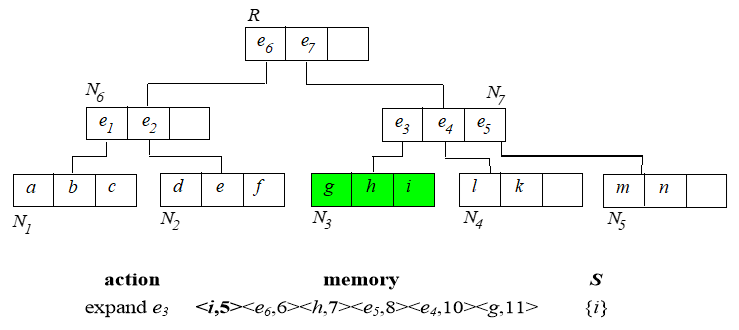
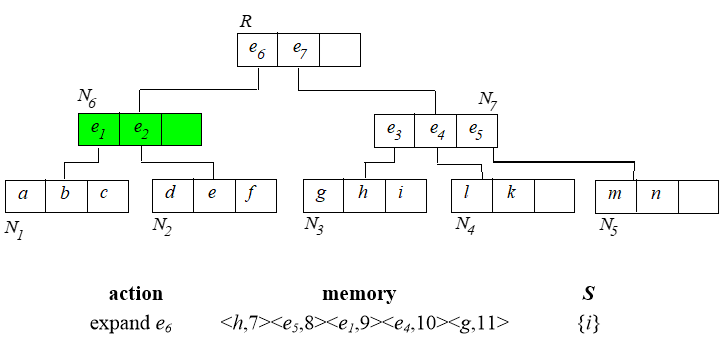
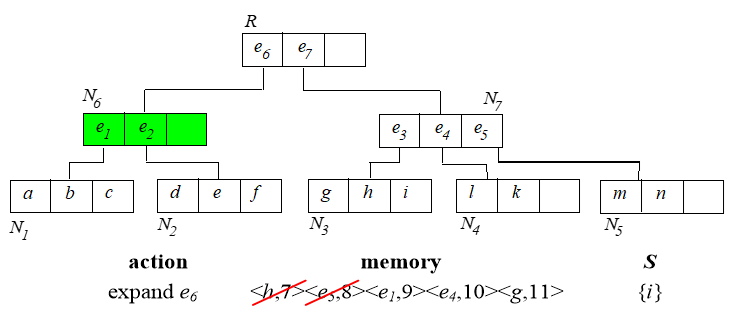
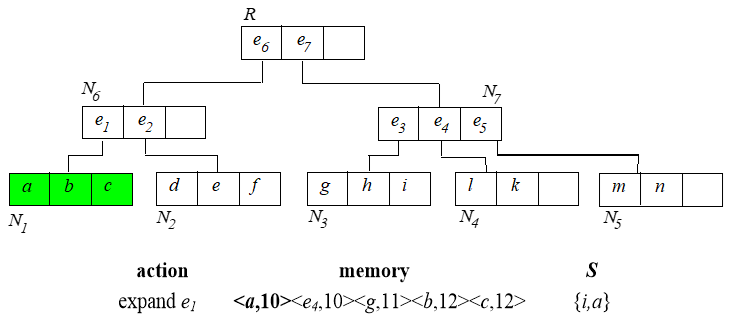
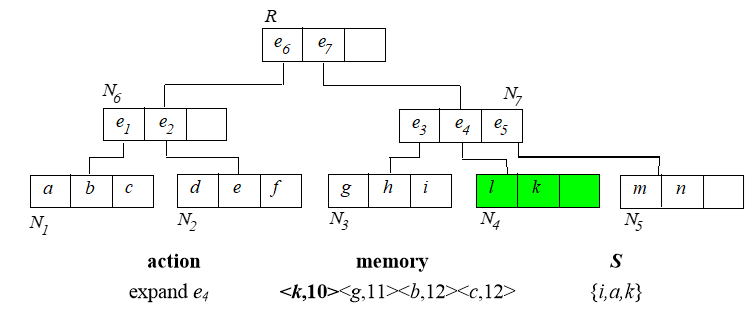
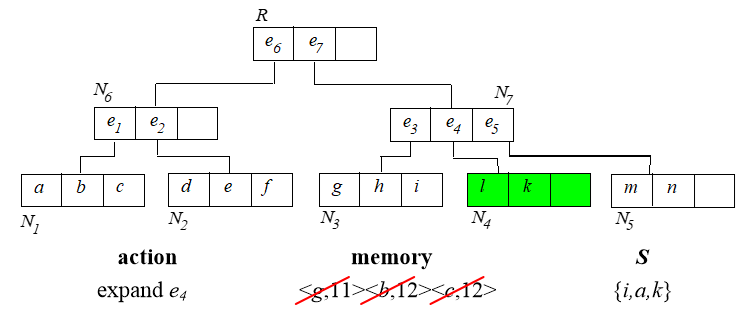
已经找到的 skyline 需要用来淘汰内存中排序的那些点。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架