循环神经网络(RNN)
DNN 以及 CNN 的模型和前向反向传播算法,这些算法都是前向反馈的,模型的输出和模型本身没有关联关系。
循环神经网络(Recurrent Neural Network)指一个随着时间的推移,重复发生的结构。它能够实现某种“记忆功能”,是进行时间序列分析时最好的选择。
RNN 模型如下:
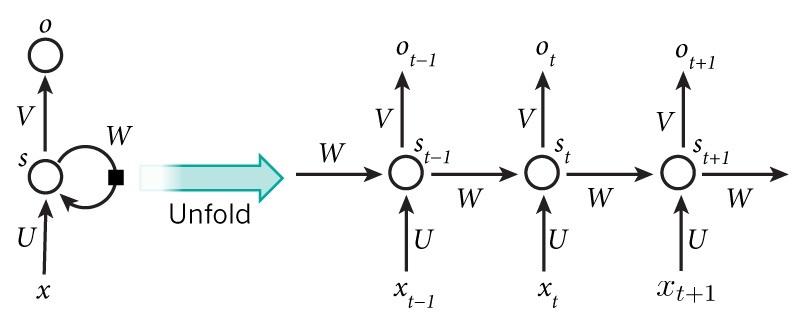
这个网络在 $t$ 时刻接收到输入 $x_t$ 之后,隐藏层的值是 $s_t$,输出值是 $o_t$。关键一点是 $s_t$ 的值不仅仅取决于 $x_t$,还取决于 $s_{t-1}$。
$U,W,V$ 这三个矩阵是我们的模型的线性关系参数,它在整个 RNN 网络中是共享的,这点和 DNN 很不相同。 也正因为是共享了,它体现
了 RNN 的模型的“循环反馈”的思想。
RNN 神经网络是定义在全连接神经网络上的,上图右侧每个圆代表 RNN Cell,里面的结构就是全连接神经网络,虽然画出了三个圆,但是其
实都是同一个网络,即同一个 Cell,这体现了参数共享。假设输入层有 $i$ 个神经元,隐藏层有 $h$ 个神经元,则 RNN Cell 的内部进行的运算为:
$$h^{(t)} = \sigma(z^{(t)}) = \sigma(U_{h \times i} \; x^{(t)} + W_{h \times h} \; h^{(t-1)} + b)$$
$h^{(t)}$ 就是图中的 $s^{(t)}$,$\sigma$ 为 RNN 的激活函数,一般为 tanh, b 为线性关系的偏置。
隐藏层到输出层的表达式比较简单:
$$o^{(t)} = Vh^{(t)} + c$$
$$\hat{y}^{(t)} = \sigma(o^{(t)})$$
通常由于 RNN 是识别类的分类模型,所以输出层的激活函数一般是 softmax。
将输入层到隐藏层之间的线性运算做个变形:
$$z^{(t)} = U_{h \times i} \; x^{(t)} + W_{h \times h} \; h^{(t-1)} + b \\
= \begin{bmatrix}
U_{h \times i} & W_{h \times h}
\end{bmatrix}\begin{bmatrix}
x^{(t)} \\
h^{(t-1)}
\end{bmatrix} + b$$
可以发现,RNN Cell 用一个线性层就可以实现了,它的输入神经元有 $h + i$ 个,输出神经元有 $h$ 个。如下图所示:
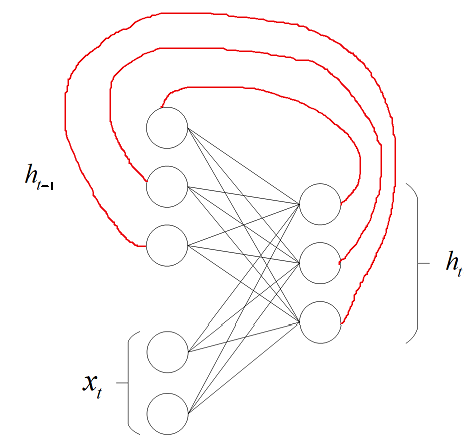
上图是 RNN 最简单的一个 Cell,它只有一个隐藏层,其中输入由 $x_t$ 和 $h_{t-1}$ 组成,网络结构上仍属于全连接神经网络。
那如何定义多隐藏层的循环神经网络呢?
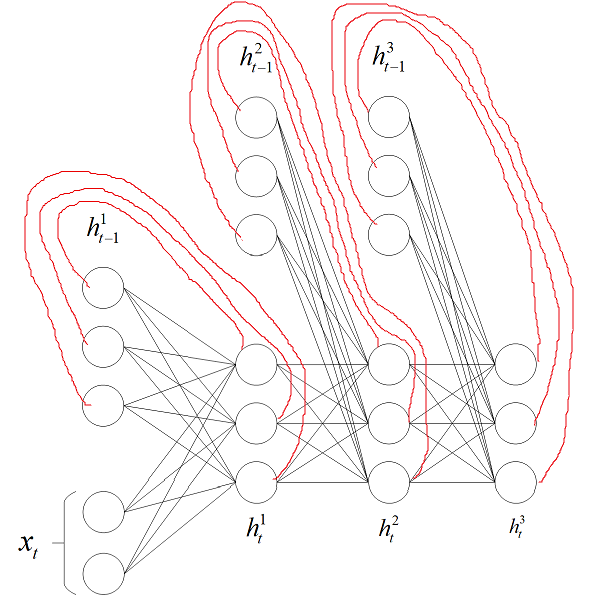
上面两个图的最后一个隐藏层都需要再接一个输出层,这里没有画出来。下面推导一下 RNN 的反向传播算法。
BTPP 算法将第 $l$ 层 $t$ 时刻的误差项 $\delta_t^l$ 值沿两个方向传播,一个方向是其传递到上一层网络,得到 $\delta_t^{l-1}$,这部分只和权重矩阵 $U$ 有关;
另一个是方向是将其沿时间线 $t-1, t-2,...,1$ 传递到初始时刻,得到 $\delta_{t-1}^l\;,\delta_{t-2}^l \;,...,\delta_{1}^l$,这部分只和权重矩阵 $W$ 有关。
对于 RNN,由于我们在序列的每个时刻都有损失函数,因此最终的损失 $L$ 为:
$$L = \sum\limits_{t=1}^{T}L_t$$
这个反向传播过程其实很简单,重点是观察反向传播路径,发现有两条,以下图为例:

我们要求误差函数 $L$ 对 $h_1^2$ 的偏导数,可以发现反向传播由两条路径,一条来自 $L_1$,另一条来自 $L_2$,所以将连个路径的偏导数分别求出来,
然后相加就可以了,每个路径的偏导数求法就和 DNN 完全一样。设
$$\frac{\partial L}{\partial h_2^3} = \delta_2^3 \\
\frac{\partial L}{\partial h_1^3} = \delta_1^3$$
可得
$$\delta_1^2 = W^{T}diag(\sigma^{'}(z_2^3))\delta_2^3 + U^{T}diag(\sigma^{'}(z_1^3))\delta_1^3$$
如何对矩阵 $U$ 求导呢?可以发现有很多路径可以到达 $U$,只需要一条一条的求,然后求和就可以了。最后求导结果为
$$\frac{\partial L}{\partial U} = \delta_1^3 \left (h_1^2 \right )^{T} + \delta_2^3 \left (h_2^2 \right )^{T} + \cdots + \delta_N^3 \left (h_N^2 \right )^{T} \\
= \sum_{t=1}^{N}\delta_t^3 \left (h_t^2 \right )^{T}$$
下面举个例子,训练如下模型:
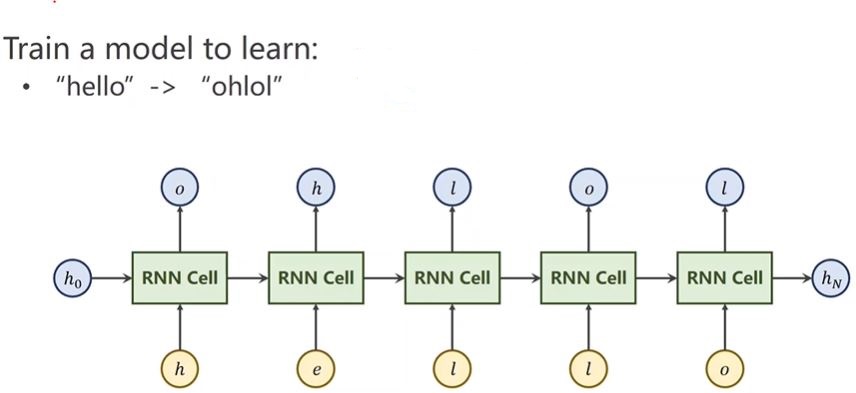
import torch
input_size = 4
hidden_size = 4
batch_size = 1
idx2char = ['e', 'h', 'l', 'o']
one_hot_lookup = [[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]]
x_data = [1, 2, 2, 2, 3]
y_data = [3, 1, 2, 3, 2]
x_one_hot = [one_hot_lookup[x] for x in x_data] # 查询字典生成独热向量
inputs = torch.Tensor(x_one_hot).view(-1, batch_size, input_size)
labels = torch.LongTensor(y_data).view(-1, 1)
class Model(torch.nn.Module):
def __init__(self, input_size, hidden_size, batch_size):
super(Model,self).__init__()
self.batch_size = batch_size
self.input_size = input_size
self.hidden_size = hidden_size
self.rnncell = torch.nn.RNNCell(input_size=self.input_size, hidden_size=self.hidden_size)
def forward(self, input, hidden):
hidden=self.rnncell(input, hidden)
return hidden
def init_hidden(self):
return torch.zeros(self.batch_size, self.hidden_size)
net = Model(input_size, hidden_size, batch_size)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(),lr=0.1)
for epoch in range(15):
loss = 0
optimizer.zero_grad() # 每一轮训练先把优化器的梯度清零
hidden = net.init_hidden()
print('Predicted string:',end='')
for input, label in zip(inputs, labels):
hidde n= net(input,hidden)
loss+ = criterion(hidden,label)
_, idx = hidden.max(dim=1)
print(idx2char[idx.item()], end='')
loss.backward()
# loss.backward(retain_graph=True)
optimizer.step()
print(',Epoch [%d/15] loss=%.4f' % (epoch + 1, loss.item())

 浙公网安备 33010602011771号
浙公网安备 33010602011771号