Pytorch 之损失函数
1. torch.nn.MSELoss
均方损失函数,一般损失函数都是计算一个 batch 数据总的损失,而不是计算单个样本的损失。
$$L = (x - y)^{2}$$
这里 $L, x, y$ 的维度是一样的,可以是向量或者矩阵(有多个样本组合),这里的平方是针对 Tensor 的每个元素,即 $(x-y)**2$ 或 $torch.pow(x-y, 2)$。
函数原型如下:
"""
该函数返回的是一个 python 类对象
reduce = False,损失函数返回的是向量形式的 loss,这种情况下参数 size_average 失效。
reduce = True, 损失函数返回的是标量形式的 loss,这种情况下:
1)当 size_average = True 时,返回 loss.mean(),即所有向量元素求和后再除以向量长度
2)当 size_average = False 时,返回 loss.sum(),即所有向量元素只求和
默认情况下:两个参数都为 True。
"""
CLASS torch.nn.MSELoss(size_average=True, reduce=True)
举个例子:
import torch loss = torch.nn.MSELoss() # 默认输出标量并求均值 input = torch.randn(3, 5, requires_grad=True) target = torch.randn(3, 5) output = loss(input, target) output.backward() print(output) """ tensor(2.4015, grad_fn=<MseLossBackward>) """
2. torch.nn.BCELoss
它适用于二分类问题,且神经网络的输出是一个概率分布,一般输出层的激活函数是 $Sigmod$ 函数,因为只有两类,所以输出没
必要归一化,直接就是一个概率分布。那么这个损失函数可以用来计算目标值和预测值之间的二进制交叉熵损失函数,一般损失函
数都是计算一个 batch 数据总的损失,而不是计算单个样本的损失。一个 batch 数据的损失为
$$L_{batch} = -w \cdot \big [\; y \ln \hat{y} + (1 - y)\ln (1 - \hat{y}) \;\big]$$
这里 $L, y, \hat{y}$ 的维度是一样的,可以是向量或者矩阵(由多个样本组合),这里的 $\ln$ 是针对 Tensor 的每个元素。
既然是计算两个分布(一个分布是我们用来近似的模型,另一个是真实分布)之间的交叉熵,那么每个样本对应的分布是什么?
只考虑一个样本,那么它其实就是一个 $0-1$ 分布,即每一个 $x$,都会对应一个类别 $y$,$y$ 要么等于 $0$,要么等于 $1$。
1)如果 $y = 0$,那么这个样本 $x$ 对应的 $0-1$ 分布(真实分布)为
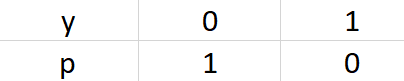
2)如果 $y = 1$,那么这个样本 $x$ 对应的 $0-1$ 分布(真实分布)为

如果上面的内容不理解,可先去阅读下博客:KL 散度和交叉熵。
注意输出标签不一定是 $0$ 和 $1$,但概率一定是 $0,1$ 且只有一项,其它项都是 $0$,如果标签比如是 $3,4$,是不能直接代入 BCELoss 的,
因为这里标签为 $0,1$ 正好等于概率,所以才直接代入的。当输出标签为 $0,1$ 时,无论哪种情况,每个样本对应的交叉熵为:
$$L_{one} = - \big [\; y \ln \hat{y} + (1 - y)\ln (1 - \hat{y}) \;\big]$$
函数原型如下:
"""
weight 必须和 target 的 shape 一致
reduce = False,损失函数返回的是向量形式的 loss,这种情况下参数 size_average 失效。
reduce = True, 损失函数返回的是标量形式的 loss,这种情况下:
1)当 size_average = True 时,返回 loss.mean(),即所有向量元素求和后再除以向量长度,这种情况就是交叉熵
2)当 size_average = False 时,返回 loss.sum(),即所有向量元素只求和,这种情况就是极大似然估计
默认情况下:weight 为 None, size_average 和 reduce 为 True。
"""
CLASS torch.nn.BCELoss(weight = None, size_average=True, reduce=True)
举个例子:
import torch S = torch.nn.Sigmoid() loss = torch.nn.BCELoss() input = torch.randn(3, requires_grad=True) target = torch.empty(3).random_(2) output = loss(S(input), target) print(output) """ tensor(0.7957, grad_fn=<BinaryCrossEntropyBackward>) """
3. torch.nn.CrossEntropyLoss
这个和 BCELoss 其实是一样的,只不过 BCELoss 算的是二类,而 CrossEntropyLoss 算的是多类,比如输出类别 $0,1,2,3,4,5,6,7,8,9$ 共 $10$
个类别,每个样本喂给神经网络,一定只会输出一个类别。举个例子,一个输入对应的输出类别为 $3$,那么它对应的分布长成这样:
![]()
这个样本输出类别为 $3$,意味着 $P(y = 3) = 1$,其它概率都是 $0$,那么可以计算这个样本的交叉熵损失为:
$$L_{one} = - \big [ \; 0 \cdot \ln \hat{y}_{0} + 0 \cdot \ln \hat{y}_{1} + 0 \cdot \ln \hat{y}_{2} +
1 \cdot \ln \hat{y}_{3} + 0 \cdot \ln \hat{y}_{4} \\
+ 0 \cdot \ln \hat{y}_{5} + 0 \cdot \ln \hat{y}_{6} + 0 \cdot \ln \hat{y}_{7} + 0 \cdot \ln \hat{y}_{8} + 0 \cdot \ln \hat{y}_{9}\; \big]$$
当使用 CrossEntropyLoss 损失函数的时候,神经网络的输出就不用再接 $softmax$ 层了,因为这个损失函数内部会做这个归一化,同时它还会根据
对应的输出标签 $y$ 生成 $one-hot$ 向量。如下图所示:
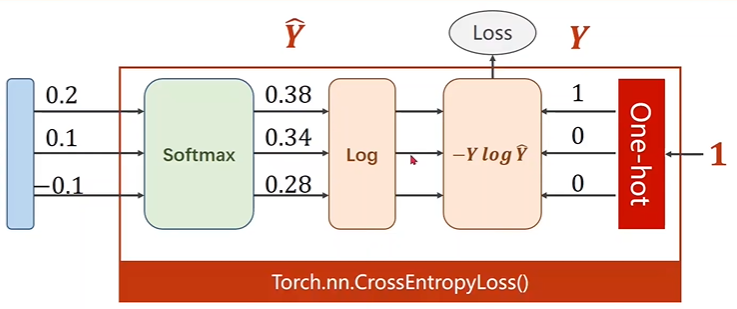
左边输入的是不带激活函数的神经网络的输出,右边输入的是该样本的标签,比如标签 $3$,那么会生成 $one-hot$ 向量 $(0,0,0,1,0,0,0,0,0,0)$。
上面只是个示意图,并不对应。生成的 $one-hot$ 向量其实就是该样本分布的真实概率。
""" weight(Tensor, optional) - 每个类别对应的权重,默认是值为 1 的 Tensor size_average(bool, optional) - 默认为 True, reduce = True 时忽略该参数。 size_average = True: 则 losses 在 minibatch 结合 weight 求平均 size_average = False: 则 losses 在 minibatch 只求相加和 ignore_index: 不知道干啥用 reduce: 默认为 True, 为 False 则返回 loss 向量,不求和 """ class torch.nn.CrossEntropyLoss(weight=None, size_average=True, ignore_index=-100, reduce=True)
举个例子:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号