Pytorch 神经网络模块之 Linear Layers
1. torch.nn.Linear
PyTorch 中的 nn.linear() 是用于设置网络中的全连接层的,需要注意的是全连接层的输入与输出都是二维张量,一般形状为 [batch_size, size]。
""" in_features: 指的是输入矩阵的列数,即输入二维张量形状 [batch_size, input_size] 中的 input_size,代表每个样本 x 的特征数,也是输入层神经元的个数 out_features: 指的是输出矩阵的列数,即输出二维张量形状 [batch_size,output_size] 中的 output_size,代表每个样本输出 y 的特征数,也是输出层神经元的个数 bias: 如果为 True,则网络的输出需要再加上一个偏置向量,维度为 output_size """ class torch.nn.Linear(in_features,out_features,bias=True)
这个网络所作的变换为:
$$Y = XA^{T} + b$$
这里的 $X$ 是一个矩阵,而不是向量,一般将一个 batch 中的样本组成一个输入矩阵,矩阵 $X$ 的每一行代表一个输入样本,举个例子:

输入是一个形状为 $(4, 6)$ 的矩阵,也就是说这个矩阵由 $4$ 个样本组成,每个样本有 $6$ 个维度的特征,$W^{T}$ 是全连接层的权重矩阵,
形状为 $(6, 10)$,也就是说,每个输入样本($X$ 的每一行)在这个矩阵的作用下,输出维度变为 $10$(向量),即输入层有 $6$ 个神经元,输
出层有 $10$ 个神经元,$b$ 是个偏置向量,它的维度等于输出神经元的个数 $10$,但是 $XW^{T}$ 的输出是一个 $4 \times 10$ 的矩阵,它是
没办法和一个向量相加的,所以这就利用到了 Tensor 的广播机制,形状 $(4,10)$ 和形状 $(10)$ 由于缺失可以触发广播机制(该博客底部) ,
即最终执行的操作为:
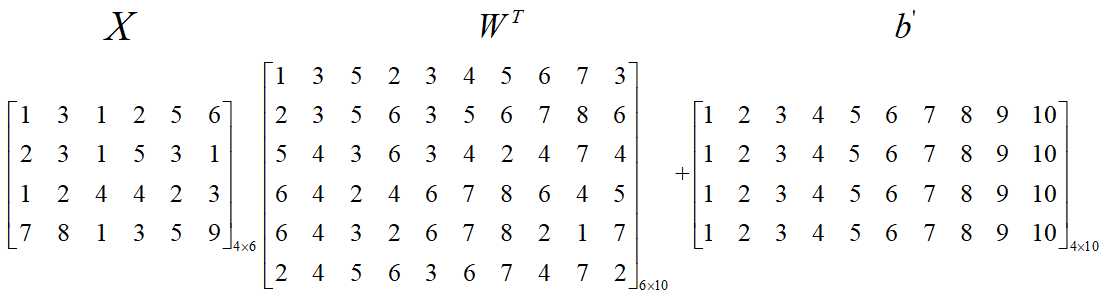
矩阵 $Y$ 的每一行就是每个样本对应的神经网络的输出,一共 $4$ 个样本,所以矩阵 $Y$ 的形状为 $(4,10)$。
import torch
X = torch.randn(128, 20) # 输入的维度是(128,20)
model = torch.nn.Linear(20, 30) # 20,30 是指维度
Y = model(X)
print('model.weight.shape: ', model.weight.shape) # 矩阵
print('model.bias.shape: ', model.bias.shape) # 向量
print('output.shape: ', Y.shape) # 矩阵
# 等价于下面的
ans = torch.mm(X, model.weight.t()) + m.bias # Y = XW.T + b
print('ans.shape: ', ans.shape)
"""
model.weight.shape: torch.Size([30, 20])
model.bias.shape: torch.Size([30])
output.shape: torch.Size([128, 30])
ans.shape: torch.Size([128, 30])
"""

 浙公网安备 33010602011771号
浙公网安备 33010602011771号